文章目录
- 0、demo模块创建
- 1、批处理有界流
- 2、流处理有界流
- 3、流处理无界流
- 4、The generic type parameters of 'Collector' are missing
0、demo模块创建
创建个纯Maven工程来做演示,引入Flink的依赖:(注意不同本版需要导入的依赖不一样,这里是1.17版本)
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<!--Flink核心依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!--Flink客户端-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
下面写Demo,演示用Flink提供的API统计txt文件里每个单词出现的频次,测试文件位置project目录/input/words.txt,文件内容:
hello flink
hello world
hello java
1、批处理有界流
基本步骤:
- 创建执行环境
- 读取数据
- 处理数据
- 输出
处理数据,包括把从文本读取的每一行String按空格切分成单词 ⇒ 转换二元组(word,1) ⇒ 按二元组的第一个词来分组 ⇒ 按二元组的第二个词来聚合(如求和)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本),获得数据源对象
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式(调用数据源对象的flatMap方法)
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
//按照空格切分单词
String[] words = line.split(" ");
//将每个单词转为二元组Tuple2
for (String word : words) {
Tuple2<String,Long> wordTuple2 = Tuple2.of(word,1L);
//使用采集器向下游发送数据,这里将转成二元组的数据继续向下发
out.collect(wordTuple2);
}
}
});
// 4. 此时数据已经变成了(word,1)格式,下面按照 word 进行分组
//按二元组的第一个元素(索引为0)来分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计(按二元组的第二个元素来聚合,第二个元素索引为1)
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果到控制台
sum.print();
}
}
//Ctrl+P看下方法的传参提示
FlatMapFunction接口的泛型,第一个为输入Flink的数据类型,第二个为你从Flink输出的类型,也就是你想转换成的类型。比如上面需要把从文本读取的String,分割后转为(word,1)的形式,即String转二元组
Tuple2<String, Long>,那就是FlatMapFunction<String, Tuple2<String, Long>>
flatMap方法的形参是一个FlatMapFunction类型的对象,FlatMapFunction是一个接口,new接口的对象得实现它的方法flatMap,该方法两个形参,第一个即进入Flink的源数据,demo中是String,第二个参数是Collector类型的收集器,向下游发送数据
//复习:这种直接用匿名内部类来new接口的对象的方式下面用的很多,复习下
//有一个接口A,里面有抽象方法a()
interface A{
void a();
}
//此时new A的对象,可以先写一个它的实现类AImpl,再重写接口的抽象方法,然后A a = new AImpl();
class AImpl implements A{
@Overrdie
void a(){
}
}
A a = new AImpl();
//但这样写很繁琐,直接匿名内部类:
new A(){
@Overrdie
void a(){
}
}
运行结果:
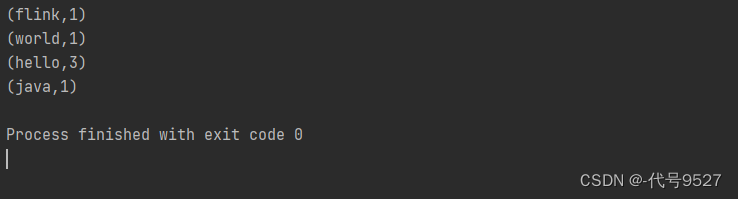
注意,以上的实现是基于DataSet API,即批处理,而Flink是流批统一的处理架构,Flink 1.12开始,官方推荐的做法是直接使用DataStream API,DataStream API更加强大,可以直接处理批处理和流处理的所有场景。该API下,想进行批处理,可:
//在提交任务时通过将执行模式设为BATCH来进行批处理
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
上面的DataSet API仅做个演示,以后不用这种API。
2、流处理有界流
继续读words.txt,统计单词频次,这次用流处理:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineStream = env.readTextFile("input/words.txt");
// 3. 转换、分组、求和,得到统计结果
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}
}).keyBy(data -> data.f0) //分组 ,类比Person -> Person.age,fo是二元组类的一个属性名
.sum(1); //聚合,链式编程
// 4. 打印
sum.print();
// 5. 执行,因为是流,要手动触发开始执行
env.execute();
}
}
注意流处理下的分组用的keyBy方法,该方法的传参是一个KeySelector接口类型,接口中有一个getKey方法,给我们定义如何从数据中提取到分组的字段。根据源码中getKey的返回类型和形参类型分析,可以得出结论:KeySelector接口上的泛型,第一个是数据类型,从哪个类型的数据中提取分组的字段key,第二个泛型则是分组的时候,分组的字段类型是啥。
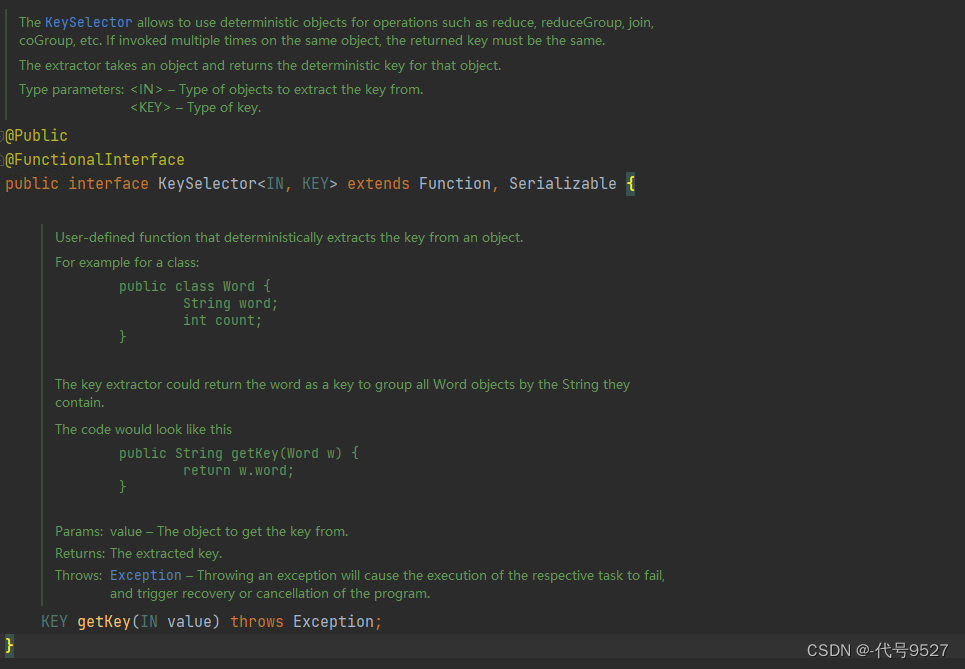
因为该接口有@FunctionalInterface注解标识,即是可以用Lambda表达式,上面代码中就是Lambad的写法,展开就是这样:
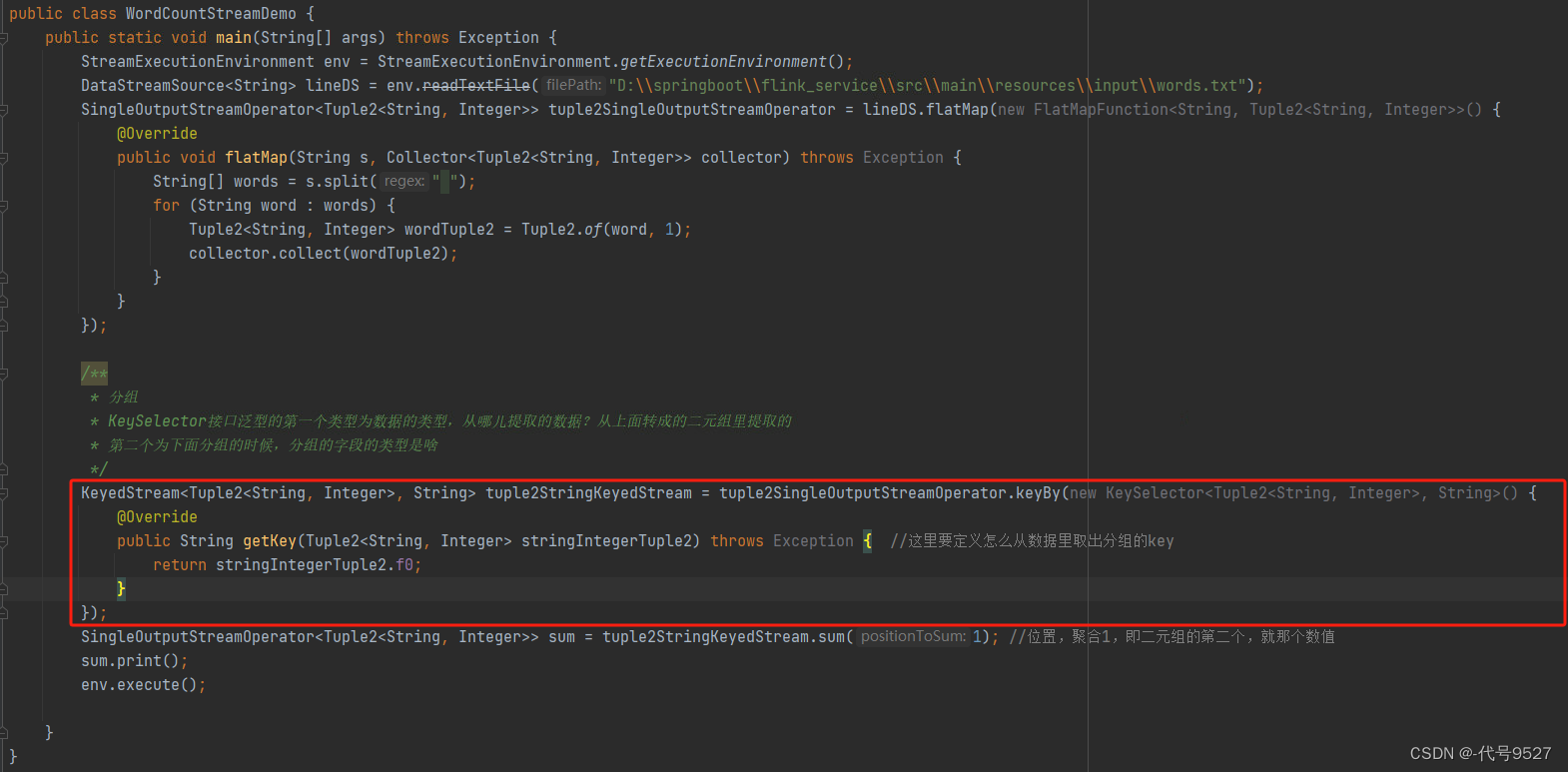
可以看出,写Lambda省事,KeySelector的泛型也不用分析了,运行下:
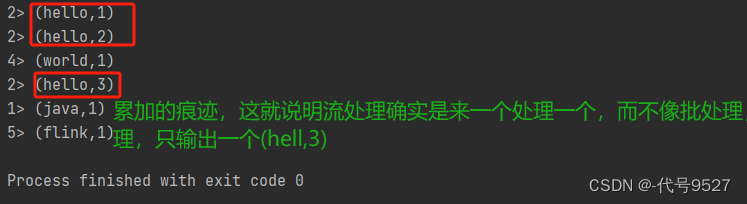
和批处理相比,流处理的代码:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment
- 转换处理之后,得到的数据对象类型不同,流处理为DataStreamSource
- 流处理分组操作调用的是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么
- 流处理代码末尾需要多调用env的execute方法,开始执行任务
3、流处理无界流
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要持续地处理捕获的数据。下面监听一台Linux主机的socket端口,然后向该端口不断的发送数据,模拟一个无界流的数据源。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流:选择socket方法,传入发送端主机名、9527表示端口号
DataStreamSource<String> lineStream = env.socketTextStream(10.6.134.81, 9527);
// 3. 转换、分组、求和,得到统计结果
//这里用匿名内部类写FlatMapFunction接口的对象
//形参列表拿过来,加一个箭头,后面{}里写逻辑,很像映射
SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG)) //消除Java泛型擦除的问题,注意这个Type类是Flink包下的
.keyBy(data -> data.f0) //分组
.sum(1); //聚合
// 4. 打印
sum.print();
// 5. 执行
env.execute();
}
}
启动程序前,先去Linux主机启动监听:
# 监听9527端口,l即保持连接
nc -lk 9527
Linux里你可能遇到的坑一:
# 安装
yum install -y netcat
# 或者
yum install -y nc
坑二:启动Flink程序后超时连接异常
# 原因:你代码里写的那个端口未开放出来
systemctl status firewalld # 应该是开着的active状态
# systemctl start firewalld
firewall-cmd --add-port 9527/tcp --permanent
firewall-cmd --reload
# 再看下,你的端口应该出来了
firewall-cmd --list-ports
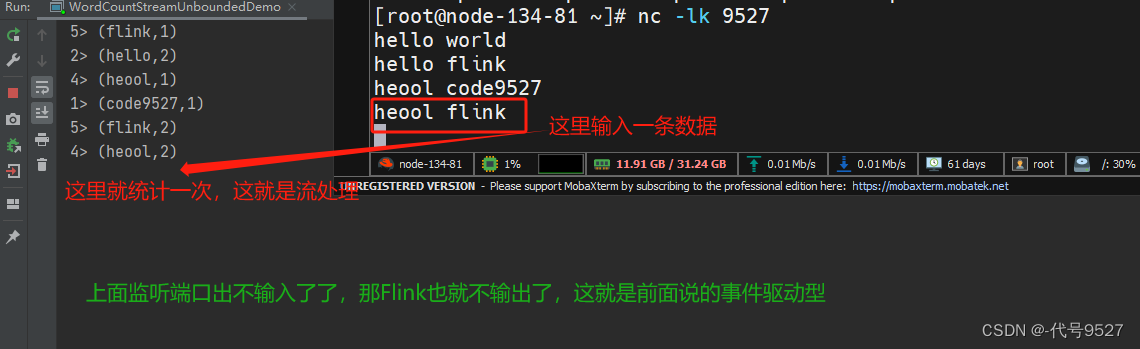
此时启动Flink程序,可以发现程序启动之后没有任何输出、也不会退出。这是正常的,因为Flink的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。向Linux主机输入hello flink,Flink程序中输出:
3> (flink,1)
5> (hello,1)
再输入hello world,Flink程序中输出:
2> (world,1)
5> (hello,2)
开两个窗口,体验一下流的概念,来一个处理一个,不像批处理,程序直接就执行结束exit code 0 了
4、The generic type parameters of ‘Collector’ are missing
Flink还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于Java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提取的信息是不够精细的——只告诉Flink当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
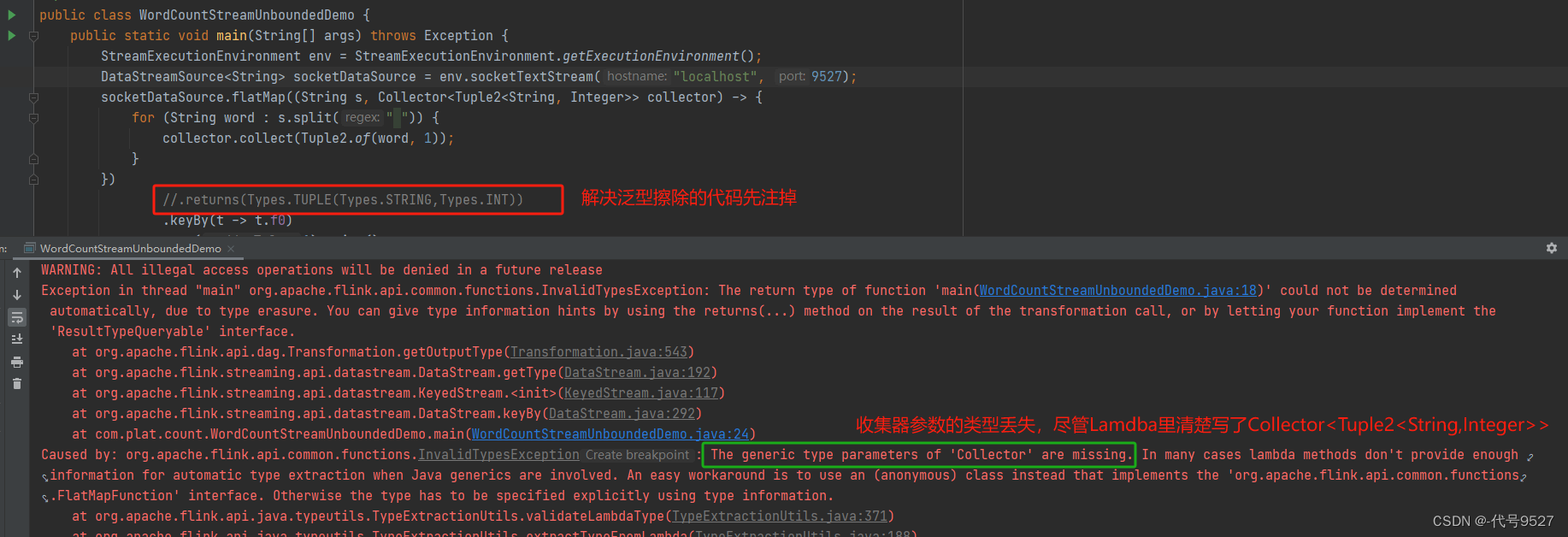
上面flatMap里传入的Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
(Types.TUPLE(Types.STRING, Types.Integer)
//即二元组的第一个元素类型为String,第二个元素为Integer
//注意Types类是Flink包下的





![[CISCN 2019初赛]Love Math - RCE(异或绕过)](https://img-blog.csdnimg.cn/8bbd59700b63463a9b931699b17484c1.png#pic_center)