更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
文章主要介绍了火山引擎湖仓一体分析服务 LAS Spark(下文以 LAS Spark 指代)在 TPC-DS 上的性能突破与优化策略。TPC-DS 是一个模拟复杂数据仓库环境的测试基准,LAS Spark 通过采用规则优化、缓存优化和运行时优化三类优化策略,实现了超越社区版本的巨大性能提升,且已在内部生产环境得到验证。文末更有专属彩蛋,新人优惠购福利,等着你来解锁!
本篇文章提纲如下:
- TPC-DS 简介
- 性能表现
- 自研优化策略
- 总结
TPC-DS 简介
针对数据库不同的使用场景 TPC 组织发布了多项测试标准。
TPC-DS 采用星型、雪花型等多维数据模式。它包含 7 张事实表,17 张纬度表,平均每张表含有 18 列。其工作负载包含 99 个 SQL 查询,覆盖 SQL 99 和 2003 的核心部分以及 OLAP。这个测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用,测试用的数据和值有倾斜,与真实数据一致。可以说 TPC-DS 是一个与真实场景非常接近的测试集,难度较大,覆盖场景广,能有效反应不同业务的需求。
TPC-DS 的这个特点与大数据的分析挖掘应用非常类似。Hadoop 等大数据分析技术也是对海量数据进行大规模的数据分析和深度挖掘,也包含交互式联机查询和统计报表类应用,同时大数据的数据质量较低,数据分布真实而不均匀。因此 TPC-DS 成为客观衡量多个不同 Hadoop 版本以及 SQL on Hadoop 技术的最佳测试集。这个基准测试有以下几个主要特点:
- 一共 99 个测试案例,遵循 SQL 99 和 SQL 2003 的语法标准,SQL 案例比较复杂
- 分析的数据量大,并且测试案例是在回答真实的商业问题
- 测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘型等)
- 几乎所有的测试案例都有很高的 IO 负载和 CPU 计算需求
TPC-DS 数据集的业务模型丰富,在 TPC-DS 数据集上测试 Spark 并验证优化性能,能对 LAS 环境的多个业务方作业带来性能提升。
LAS Spark 在 TPC-DS 测试集的性能表现
我们对比了火山引擎 LAS Spark 3.0 于社区 3.0 版本在 TPC-DS 上的性能表现。
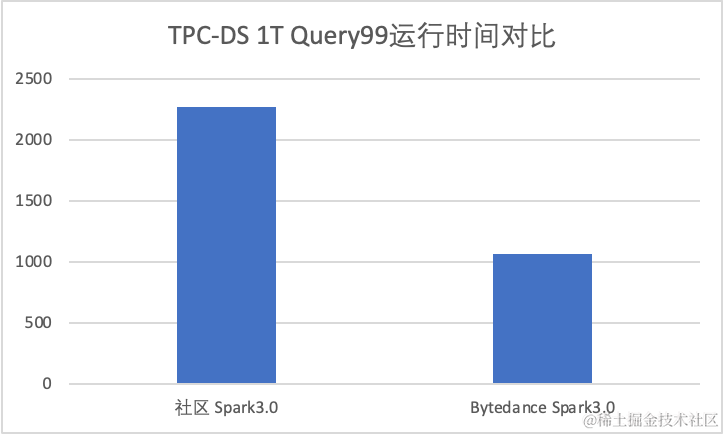
- Spark 3.0 TPC -DS 1T 数据集
TPC-DS 1T 的性能对比中,火山引擎 LAS Spark 3.0 达到了社区 3.0 性能的 2.1x。
- Spark 3.2 TPC -DS 1T 数据集
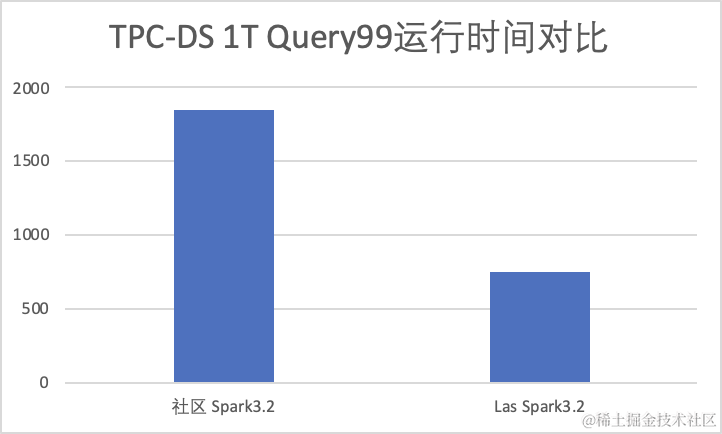
TPC-DS 1T 的性能对比中,火山引擎 LAS Spark 3.2 达到了社区 3.2 性能的 2.5x。
LAS Spark 团队自研优化
火山引擎 LAS Spark 相比社区有较大的性能提升,这些性能提升一部分来源于厂内已有的性能优化,例如AdaptiveShuffledHashJoin、AdaptiveFileSplit 等;还有一部分来源于对 TPC-DS 数据集的研究和挖掘。在对 TPC-DS 的 workload 的测试和研究中,Spark SQL 团队发现了一些潜在的性能优化点。
火山引擎 LAS Spark 在 TPC-DS 数据集上的性能优化可以分为三种类型,分别是规则优化、缓存优化和运行时优化,下面我们将分别介绍这三类优化,以及具体的优化策略。
3.1 规则优化
规则优化,指的是在 Spark Optimizer 阶段增加了一些规则来优化逻辑计划。我们常说的谓词下推优化就是 Optimizer 阶段的一条优化规则。
3.1.1 Fast Decimal
Decimal 的计算比较耗时,在一些情况下可以把 Decimal 类型先转成 Long 计算,然后再恢复成 Decimal。Spark 现有的优化规则 DecimalAggregates 就是做这样的优化。
DecimalAggregates 针对 window/agg 的聚合函数是对 decimal 的 sum/agg 的场景做了如下优化
Sum(e) => MakeDecimal(Sum(UnScaledValue(e)))
Avg(e) => CastToDecimal(Avg(UnScaledValue(e)))
但是当前这个优化规则还不足够,我们在此基础上做了更多的优化:
- 根据统计信息覆盖更多场景
当前判断能否把 decimal 转成 Long 是根据 hive schema 里定义的 decimal 类型,但是如果我们已经有了每列的统计信息(最大最小值),我们可以进一步把这个 decimal 的 precision 缩小,进而可以覆盖更多 case。
比如,tpc-ds 里 store_returns 的 sr_fee 的schema 定义是 Decimal(7,2),但是通过 analyze table 之后可以知道,这个列的最大值是 100,那我们就可以把这个 schema 变成 Decimal(5,2)。
-
DecimalAggregates 规则的更优实现
a. 当前的规则是对 Sum 最外层的表达式把 Decimal 转成了 Long,比如对于 TPCDS Query4 来说,里面有一个 sum 如下
sum((ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price)/2) year_total
当前规则下, 生成的 plan 是
MakeDecimal(Sum(UnScaledValue((ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price)/2)))
其中标黄色的部分是按 decimal 计算的,在做 sum 之前转成了 Long。显然这里更高效的做法是
MakeDecimal(Sum((UnScaledValue(ss_ext_list_price)-UnScaledValue(ss_ext_wholesale_cost)-UnScaledValue(ss_ext_discount_amt)+UnScaledValue(ss_ext_sales_price))/2))
除此之外,对于 Sort,并且里面有 Decimal 类型,我们可以直接改成通过 unscaled long 排序;对于两个 Decimal 进行 BinaryComparison,如果他们的 precision 和 scale 都相同,那也可以通过unscaled long 进行对比等等。
Fast Decimal 的中心思想就是避免 Decimal 的计算,尽可能把 Decimal 类型先转成 Long 计算,以达到加速计算的效果。
3.1.2 Push Order Limit Through Agg
对于下面的 AGG + ORDER + Limit 场景的 在 TPC-DS 中比较常见(例如 Query3,Query 7 Query8 等), 可以将 Ordered Limit 限制下推到 Aggregation 中:
select a, b, c, agg_f0, agg_f1, agg_f2
from t
group by a, b, c
order by c, b, [agg_f0]...
limit 100
-- 限制条件: order by 的前缀字段需要是 group by 字段的子集.
一般来讲, 上述的 Query 会生成 Agg + Sort + Limit 算子,其中 Sort + Limit 算子会被优化成 TopK, 也即 Agg + TopK. 其中 Agg 算子不会感知到任何 limit 或者 order 信息. 但仔细观察上述查询特征, order by 中的最前面几个字段是 group by 字段的子集, 这些字段在Partial 聚合过程已经确定, 因此我们可以利用 Orderd Limit 信息, 在 Partitial 聚合阶段就应用这部分信息, 减少数据聚合. 也即:
input -> partial agg -> exchange -> final agg -> takeOrderedAndProject
-- 将会转换成
input -> partial agg(group key=c,b,a order key=c,b limit=100) -> exchange -> final agg -> takeOrderedAndProject
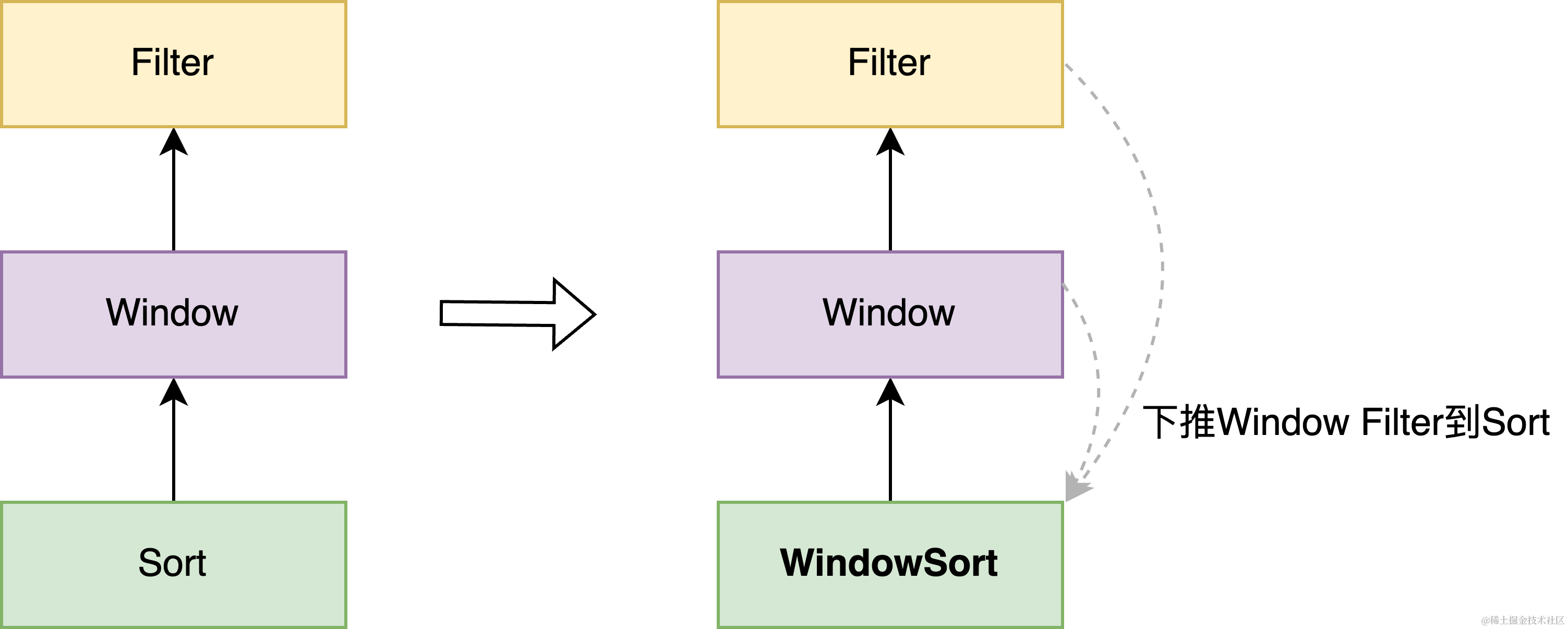
3.1.3 Window TopK
在对 Query 67 的分析中,我们发现耗时的瓶颈在于 window 内的 rank 计算。Spark 在执行 window 计算之前,为了保证一个 partition 内具有相同分区的字段的数据分布是连续的,会按照分区字段做一次 partition 内的局部排序. 但由于 Q67 中 window 的分区字段 i_category 的基数较少, 导致单个 task 数据较多,执行 Sort + Window 耗时很久。
由于 Query 67 中 window 计算后紧跟着过滤条件: rk <= 100, 对于这类的查询 pattern, 其实完全可以将 rk <= 100下推到 Sort,在 Sort 计算中完成 TopK 计算,这样能够大幅减少 Sort 的计算量以及 Window 的输入数据量。
3.1.4 Runtime Filter
Runtime Filter 是一种在数据库中广泛使用的一种优化技术,其基本原理是通过在 join 的 probe 端提前过滤掉那些不会命中 join 的输入数据来大幅减少 join 中的数据传输和计算,从而减少整体的执行时间。
- Dynamic Data Pruning
类似于社区的 Dynamic Partition Pruning,可以将 BroadcastHashJoin 的 broadcast 侧的数据一路下推,甚至可以下推到 scan 层。该优化能够在 Query 1,10,16 等生效。
- Dynamic BloomFilterJoin
对于 ShuffledJoin 算子,利用小表数据构造 BloomFilter,大表在 probe 之前会根据 bloomFilter 提前过滤,从而大幅降低少 join 中的数据传输和计算,从而减少整体的执行时间。Dynamic BloomFilter 相比 DDP 增加了构造 BloomFilter 的子查询,带来了一些 overhead,但从生效 Query(例如 Query24, 37, 50 等)的性能表现来看,Dynamic BloomFilterJoin 带来的收益更大。
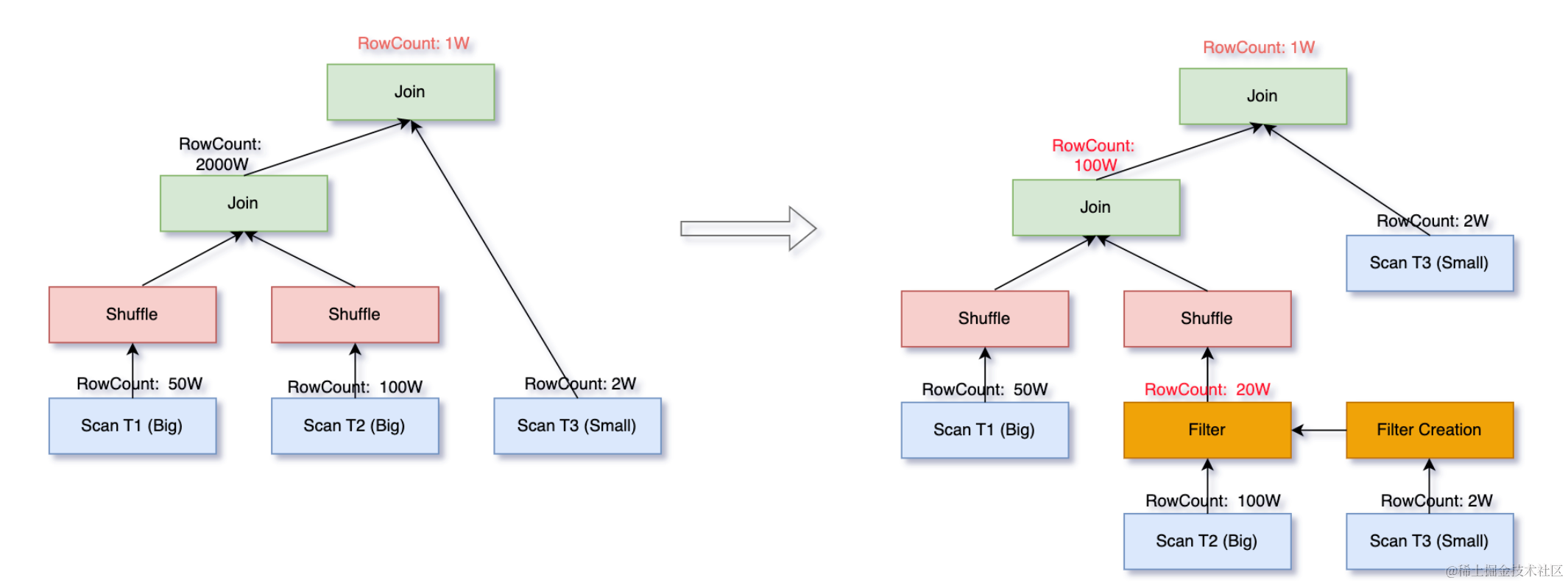
目前,社区 Spark 3.3 已支持 Runtime Filter,我们在此基础上拓展了 BloomFilter 命中的范围,并通过统计信息来预判过滤率,避免构建 BloomFilter 的开销大于过滤大表数据带来的收益。
此外,我们还实现了将 BloomFilter 下推到 scan 层,在 TPC-DS 10T 数据集上命中 Query 能减少 80% 以上的 scan 数据量。
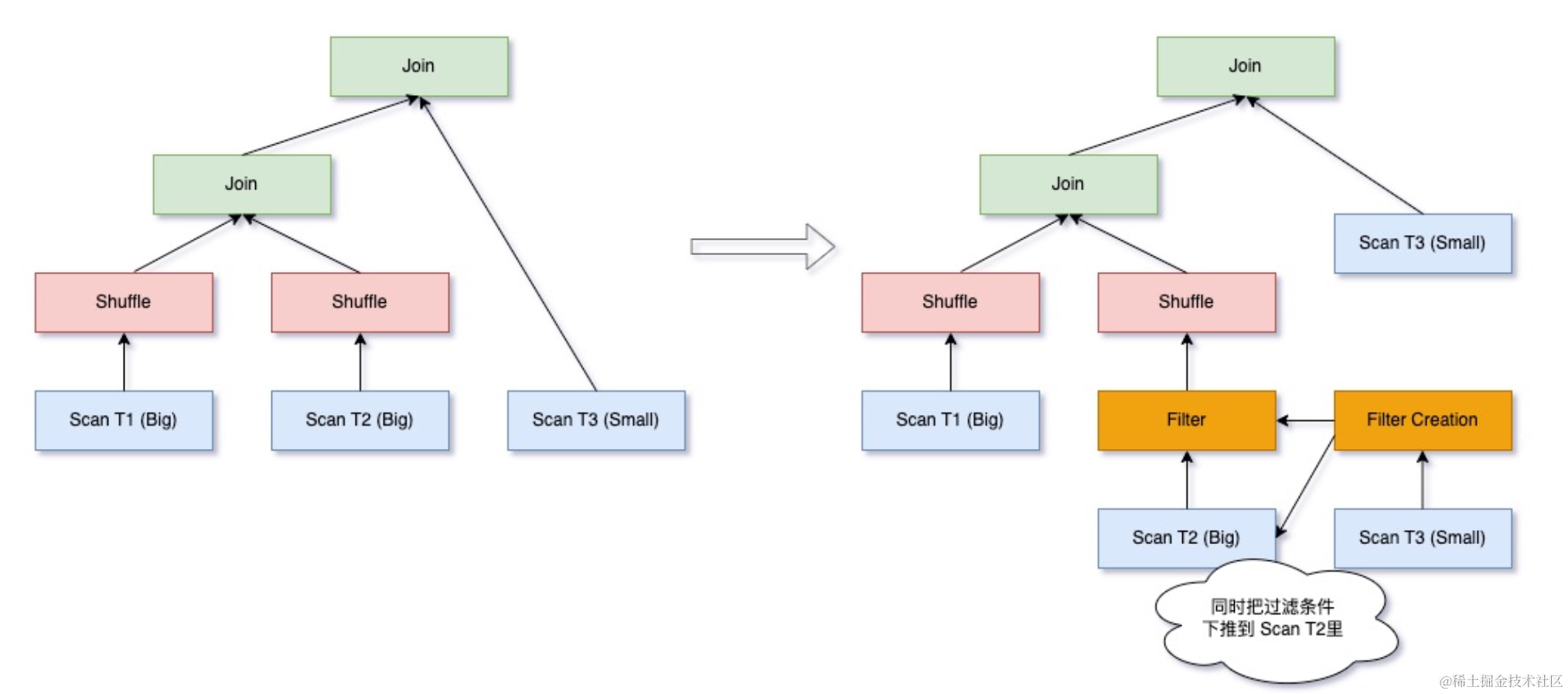
3.1.5 Eliminate Loose Exchange
如果一个查询中存在多个相邻的 Exchange,并且这些 Exchange 的 output partition 存在包含关系(例如 Query 4),用下层的 Exchange 替换上层的 Exchange,仍然能满足数据分布,可以节省一次 Exchange。
如下 SQL 所示,Join 左侧需要 Exchange(id11) 来使 Join key 满足分布,而左表子查询中因为 Group-by,需要通过 Exchange(id1, id2) 来使数据满足分布,此时可以使 Exchange(id11) 来替换 Exchange(id1, id2),节省掉 Join 左侧的 Exchange。
select *
from ( select id1 id11, sum(id2) sid2
from t1
group by id1, id2
having sid2 > 0
) tt1
inner join t2
on tt1.id11 = t2.id1
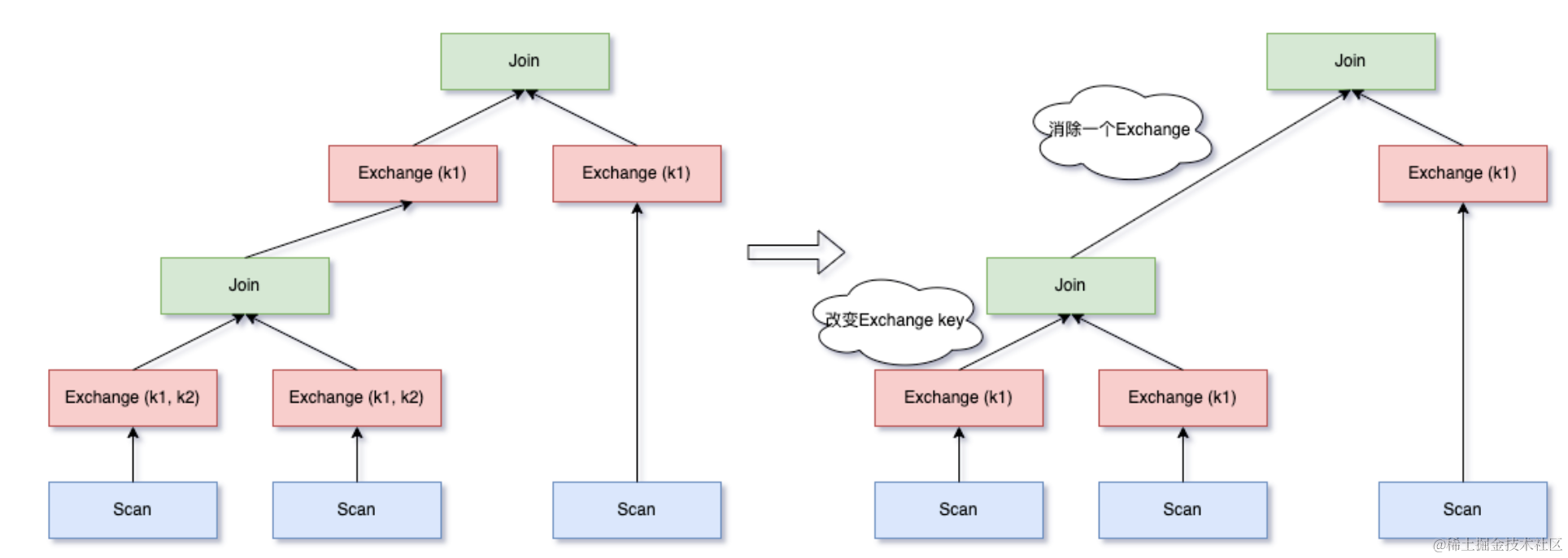
如果多个连续的 Exchange 并不存在包含的关系,但是 output partition 存在公共子集也能进行 Exchange 消除:
select t12.id1, t12.id2, t3.id3, t12.id4, t12.id5
from ( select t1.id1, t2.id2, t1.id3, t1.id4, t1.id5
from t1
inner join t2
on t1.id1 = t2.id1 and t1.id2 = t2.id2
) t12
inner join t3
on t12.id1 = t3.id1 and t12.id3 = t3.id3
Exchange(id1, id3) 本身并非 Exchange(id1, id2) 的子集,无法命中 Eliminate Exchange,但是二者存在公共子集,可以选择用 Exchange(id1) 代替 Exchange(id1, id3),进而消除 Exchange(id1, id2)。
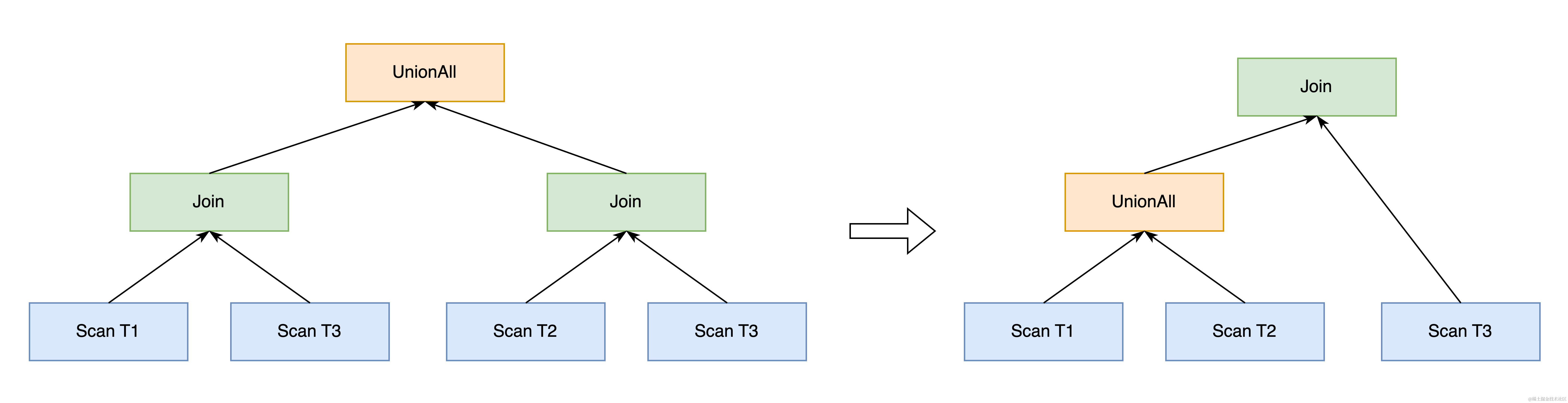
3.1.6 Push Union Through Join
UnionAll 和 Join 是 TPCDS 以及业务 SQL 中常见的算子,在视图 VIEW 中此二者的组合尤其常见。我们观察到,在 UnionAll 的子查询中,如果 Join 存在公共子表,可以调整 UnionAll 和 Join 的执行顺序,单独抽取出公共子表的部分,使其节省一次 scan,如下 SQL 所示。
select * from T1, T3
union all
select * from T2, T3
-- 将被转换为如下形式,节省一次T3表的scan
select * from
(
select * from T1
union all
select * from T2
) t, T3
3.1.7 Push Partial Aggregation Through Join
Join+Agg是 SQL 中常见的组合,并且开销往往较大。对于Join 之后再做 Aggregate 的情况,如果 Aggregate 的聚合率比较高,并且 Join 时需要先进行 Shuffle,可以先做聚合,减少参与 Shuffle 的数据量。
SELECT T1.id, SUM(T2.price)
FROM T1 INNER JOIN T2 ON T1.id = T2.id
GROUP BY T1.id
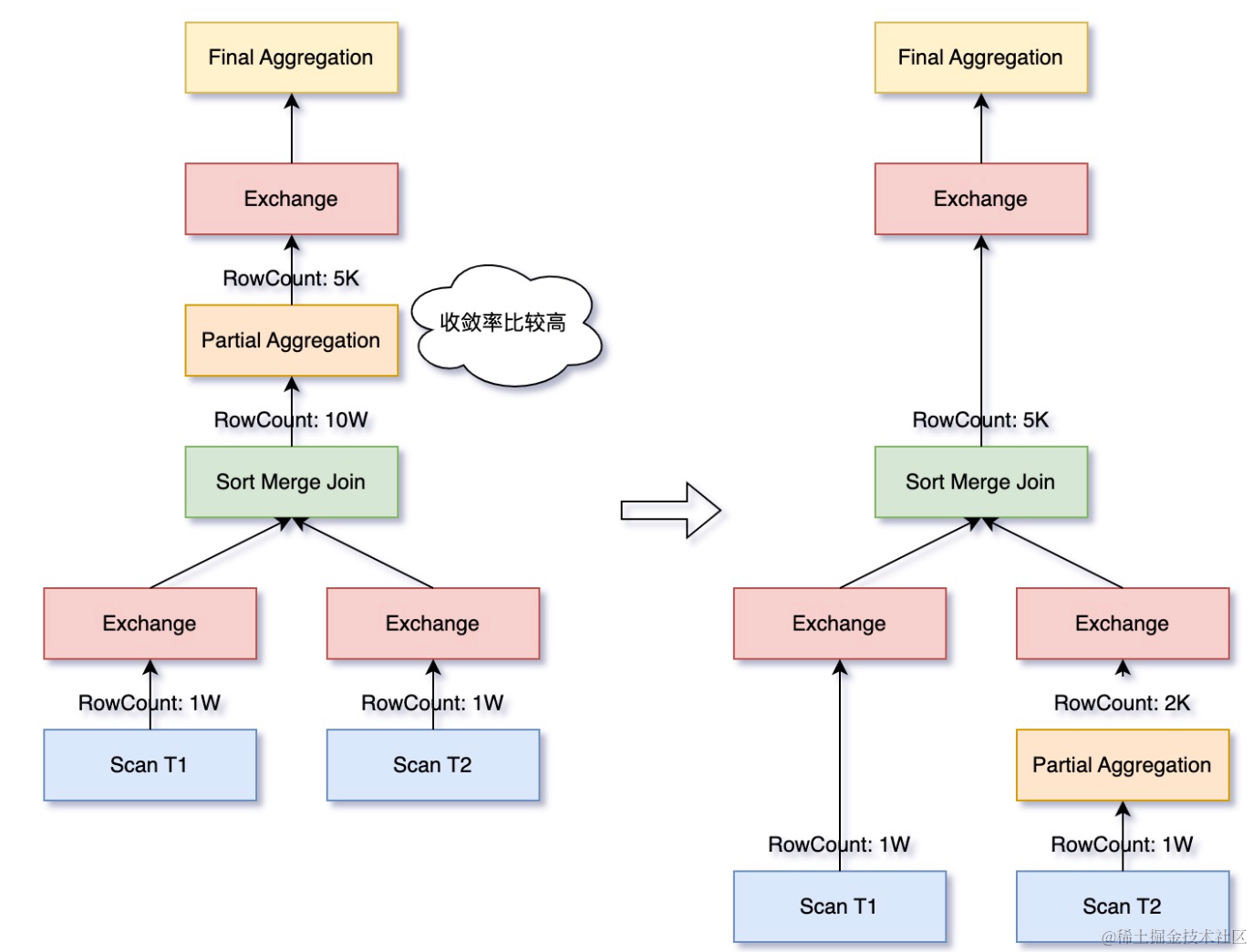
3.1.8 Adaptive Partial Aggregation
在 Spark 中会将 Agg 拆分为 partial 阶段 agg 和 final 阶段 agg 以减少聚合所需的 Shuffle 的数据量,但是在一些场景下,partial 阶段进行的 agg 并没有显著减少数据,反而带来额外的开销。因此,我们会在 Partial Agg 执行的时候统计聚合率,来决定是否动态地跳过 Partial Aggregation。
3.2 缓存优化
对于重复数据的多次读取的场景,缓存无疑是一大优化利器。我们在某些场景下,将元信息以及重复的子查询缓存起来,能够加速查询。
3.2.1 Filtered partitions cache
在进行 Plan 优化的过程中,存在多次对于元数据的访问,尤其是一个子查询在 Query 中被重复使用时(例如 Query 9),Spark 会对相同的表和分区过滤条件进行多次查询,元数据的访问时间往往会成为解析时间的瓶颈所在。基于此,我们对已经过滤的 partitions 进行缓存,如果再次查询相同的表和分区过滤条件,就能够命中缓存优化。
3.2.2 Parquet Meta Cache 和 Data Cache
对于热点数据,我们通过一些缓存策略提升了scan 阶段的整体运行效率:
- 通过对 scan 算子添加软亲和性调度,让相同的文件尽可能被同一个 executor 处理,使得在 TPC-DS 场景下,相同表多轮查询的情况下 scan 效率提高;
- 基于 Parquet 文件 footer 级别的内存缓存了文件的元数据,多次重复读取文件元数据,同时借助本地缓存降低与 HDFS 的远程读取轮次,在 TPC-DS 数据集中的数据请求量可以降低 60% 以上;
- 通过对 Hadoop 配置的可重用广播,避免不必要的重复性广播。
3.3 运行时优化
AQE(Adaptive Query Execution,AQE)是 Spark 3.0 在 SQL 模块引入的最重磅的优化。火山引擎 LAS Spark 团队也基于 AQE 做了一些相关优化,例如 SkewedJoin、自适应调整并发等。
3.3.1 Adaptive ShuffledHashJoin
相比于 SortMergeJoin, ShuffledHashJoin 由于减少了 Join 两次的 Sort 计算,有比较稳定的性能提升。但是由于 ShuffledHashJoin 需要在内存中将 buildSide 的所有数据构造成 hashRelation,因此对 buildSide 的大小有比较严格的限制,如果数据过大会导致构造 hashRelation 失败,从而导致作业失败,因为 ShuffledHashJoin 是默认不适用的。我们在 AQE 阶段,根据 shuffle 统计信息能够获取更准确的 join 两侧的数据信息,能够更加安全的将 SortMergeJoin 转换成 ShuffledHashJoin,从而提高 join 的性能。
该优化在 44 条有 join 计算的 Query (例如 Query1, 4, 5, 6 等)都生效并带来了性能提升。
3.3.2 自适应调整并发
Spark AQE 有个优化规则CoalesceShufflePartitions, 在每个 Stage 执行之前,根据 shuffle 统计信息,按照一定阈值(默认 64MB)合并小分区,从而减少资源浪费提高整体运行效率。这个在绝大部分情况下都是适用的。 但是在做 TPC-DS 优化分析时, 发现部分 Query(例如 Query 14, 23, 24 等)存在重计算的 stage,shuffle 合并反而降低了整体运行速度。
基于此,我们根据 stage 的运行复杂度和当前作业空闲的 executor 个数,动态调整阈值,从而提高整体端到端运行速度。比如 Stage 中存在 Agg 或者 Window 算子,我们就会提高该 Stage 的运行复杂度。
TPC-DS 测试集作为 TPC 组织推出的一个基于决策支持系统的测试基准,模拟了一个复杂的数据仓库环境,覆盖了多种业务领域,能够有效地测试和评估 OLAP 引擎在处理不同业务场景下的性能和效率,使得不同 OLAP 引擎之间的性能比较更加公平和可靠。
目前 LAS Spark 相比于社区版本在 TPC-DS 1T 数据集上的性能对比,在相同的硬件资源下, 3.0 版本达到了社区 3.0 版本性能的 2.1x,3.2 版本达到了社区 3.2 版本性能的 2.5x。
本文介绍了火山引擎 LAS Spark 团队针对 TPC-DS 数据集所做的性能优化工作,这些优化部分来源于日常的深入优化,部分来源于我们对 TPC-DS 数据集特征的研究和挖掘。由于 TPC-DS 毕竟无法覆盖所有的场景和 workload,所以 LAS Spark 团队自研的很多优化功能,例如物化列/视图、Bucket 优化、localSort、PushedLimit、MaterilizedCTE、Index 等诸多功能,在 TPC-DS 数据集不见得有十分明显的收益,我们会在后续合适的机会再为大家做专项展开。
本文所介绍的所有优化,均已在内部生产环境上线验证,并得到了可观的性能提升效果。例如 AdaptiveShuffledHashJoin 优化上线后,线上 80% 的 Join 算子由 SortMergeJoin 转成了 ShuffledHashJoin,作业端到端性能平均提升 9.6%;Dynamic DataPruning 和 BloomFilterJoin 优化上线后,日均覆盖 2w + 作业,平均性能提升 6.8%。
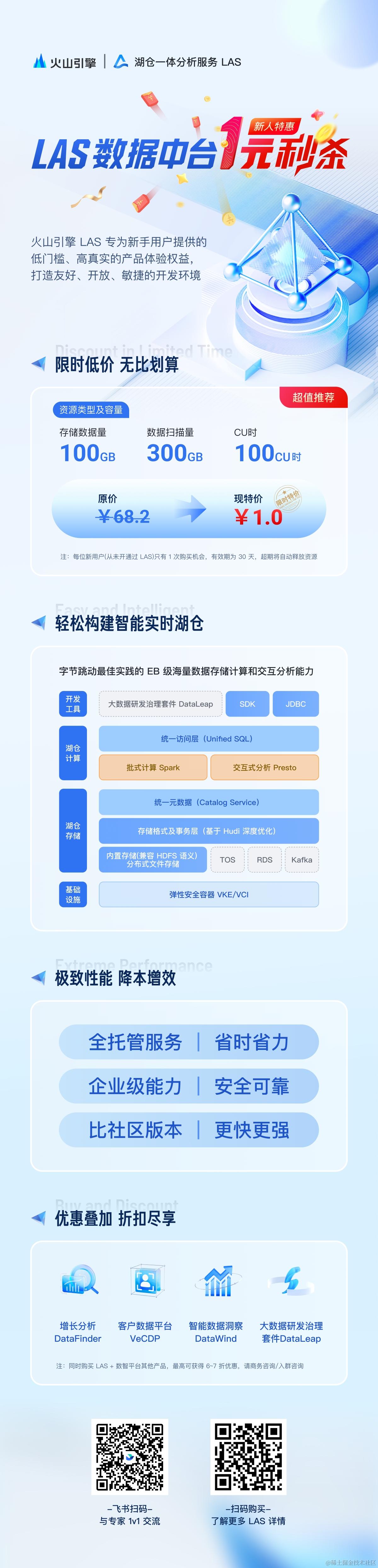
湖仓一体分析服务 LAS(Lakehouse Analytics Service)是面向湖仓一体架构的 Serverless 数据处理分析服务,提供字节跳动最佳实践的一站式 EB 级海量数据存储计算和交互分析能力,兼容 Spark、Presto 生态,帮助企业轻松构建智能实时湖仓。新人优惠来袭!赠送给所有新人用户的专属福利来啦, LAS 数据中台新人特惠 1 元 秒杀 活动最新上线!更有超多叠加优惠等你来抢! 感谢大家一直以来对我们的支持与厚爱,我们会一如既往地为您带来更好的内容。