Go 复合类型之切片类型

文章目录
- Go 复合类型之切片类型
- 一、引入
- 二、切片(Slice)概述
- 2.1 基本介绍
- 2.2 特点
- 2.3 切片与数组的区别
- 三、 切片声明与初始化
- 3.1 方式一:使用切片字面量初始化
- 3.2 方式二:使用`make`函数初始化
- 3.3 方式三:基于数组的切片化
- 四、切片的本质(底层实现原理)
- 五、切片的动态扩容
- 5.1 切片的动态扩容介绍
- 5.2 `append()` 方法为切片扩容添加元素(切片追加元素)
- 5.2 切片的扩容策略
- 六、获取切片的长度和容量
- 6.1 获取切片的长度
- 6.2 获取切片的容量
- 七、切片的常用操作
- 7.1 判断切片是否为空
- 7.2 从切片中删除元素
- 7.3 使用`copy()`函数复制切片
- 7.4 切片的赋值拷贝
- 7.5 切片遍历
- 7.5.1 使用`for`循环和索引遍历
- 7.5.2 使用`for range`遍历并忽略索引
- 7.6 切片不能直接比较
- 7.7 切片过滤
- 7.8 切片的特定索引位置插入元素
- 7.9 切片的合并
- 八、切片表达式和切割切片
- 8.1 简单切片表达式
- 8.2 完整切片表达式
一、引入
我们在上一个节Go复合类型之数组类型提到过,数组作为最基本同构类型在 Go 语言中被保留了下来,但数组在使用上确有两点不足:固定的元素个数,以及传值机制下导致的开销较大。于是 Go 设计者们又引入了另外一种同构复合类型:切片(slice),来弥补数组的这两处不足。
二、切片(Slice)概述
2.1 基本介绍
切片(Slice)是编程中常用的数据结构,它是一种灵活的序列类型,通常用于对序列(如数组、列表、字符串等)进行部分或整体的访问、修改和操作。切片允许你从原始序列中选择一个范围(片段)的元素,而不需要复制整个序列。
在许多编程语言中,切片通常由两个索引值表示,一个起始索引和一个结束索引,这两个索引之间的元素将被提取出来。切片操作可以用于读取元素、替换元素、扩展序列等各种用途,使得代码更加简洁和可读。
- 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
- cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。
- 如果
slice == nil,那么len、cap结果都等于 0。
2.2 特点
切片的特点包括:
- 动态长度: 切片的长度可以随时增加或减少,而不需要重新声明或分配内存。
- 自动扩容: 当切片的容量不足以容纳新的元素时,切片会自动扩容,重新分配内存。
- **可变的数组:**切片的长度可以改变,因此,切片是一个可变的数组。
- 引用类型:切片本身不存储数据,而是引用底层数组中的数据,因此切片是引用类型。但自身是结构体,值拷贝传递。因此修改切片会影响底层数组,反之亦然。
2.3 切片与数组的区别
在Go中,切片与数组有以下区别:
- 长度固定 vs. 动态长度: 数组的长度是固定的,一旦声明后不能更改,而切片的长度可以动态增加或减少。
- 内存分配方式: 数组是固定大小的,它们在栈上分配内存。切片则在堆上分配内存,这使得切片更加灵活,但也增加了垃圾回收的复杂性。
- 复制与引用: 数组在赋值时会复制其数据,而切片只是对底层数组的引用,多个切片可以共享相同的底层数组。
- 容量: 数组的容量就是其长度,不可更改。切片的容量可以大于其长度,底层数组容纳了更多的元素,但只有切片的长度部分是可见的。
- 声明方式: 数组的长度是在声明时确定的,例如
var arr [5]int。切片则通过make函数来创建,例如slice := make([]int, 5, 10)。
三、 切片声明与初始化
定义:切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
3.1 方式一:使用切片字面量初始化
声明切片类型的基本语法如下:
var name []type
// 或者使用短变量声明
name := []type
其中,
- name:表示变量名
- type:表示切片中的元素类型
举个列子:
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{}
3.2 方式二:使用make函数初始化
通过 make 函数来创建切片,并指定底层数组的长度。我们直接看下面这行代码:
var a:= make([]type, length, capacity)
其中:
- type为数据类型
- length 为长度
- capacity 为容量
举个例子:
sl := make([]byte, 6, 10) // 其中10为cap值,即底层数组长度,6为切片的初始长度
如果没有在 make 中指定 cap 参数,那么底层数组长度 cap 就等于 len,比如:
sl := make([]byte, 6) // cap = len = 6
3.3 方式三:基于数组的切片化
采用 array[low : high : max]语法基于一个已存在的数组创建切片。这种方式被称为数组的切片化,比如下面代码:
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
sl := arr[3:7:9]
fmt.Println("arr:", arr) //arr: [1 2 3 4 5 6 7 8 9 10]
fmt.Println("s1:", sl) //s1: [4 5 6 7]
我们基于数组 arr 创建了一个切片 sl,这个切片 sl 在运行时中的表示是这样:
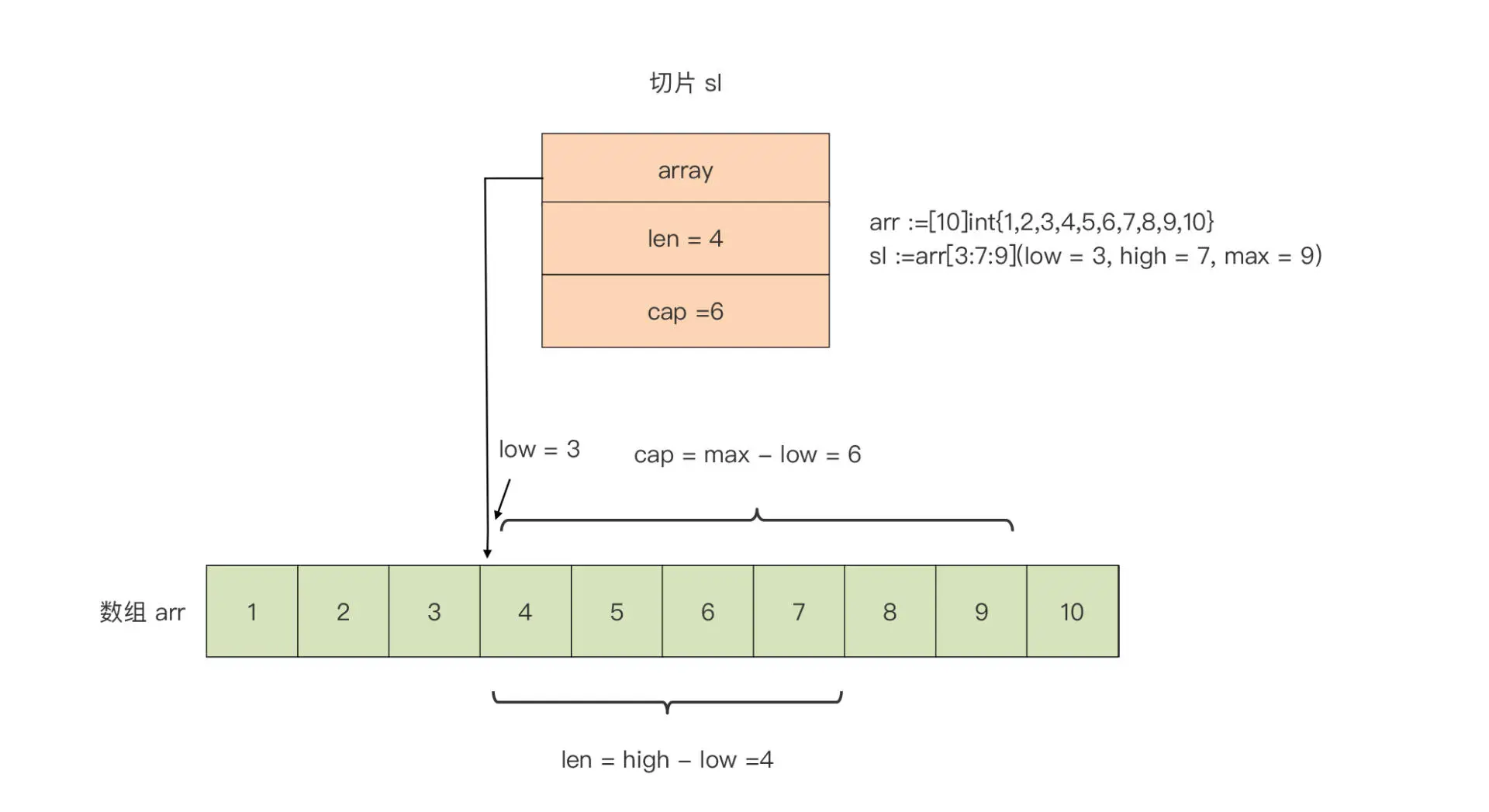
我们看到,基于数组创建的切片,它的起始元素从 low 所标识的下标值开始,切片的长度(len)是 high - low,它的容量是 max - low。而且,由于切片 sl 的底层数组就是数组 arr,对切片 sl 中元素的修改将直接影响数组 arr 变量。比如,如果我们将切片的第一个元素加 10,那么数组 arr 的第四个元素将变为 14:
sl[0] += 10
fmt.Println("arr[3] =", arr[3]) // 14
这样看来,**切片好比打开了一个访问与修改数组的“窗口”,**通过这个窗口,我们可以直接操作底层数组中的部分元素。这有些类似于我们操作文件之前打开的“文件描述符”(Windows 上称为句柄),通过文件描述符我们可以对底层的真实文件进行相关操作。可以说,切片之于数组就像是文件描述符之于文件。
在 Go 语言中,数组更多是“退居幕后”,承担的是底层存储空间的角色。切片就是数组的“描述符”,也正是因为这一特性,切片才能在函数参数传递时避免较大性能开销。因为我们传递的并不是数组本身,而是数组的“描述符”,而这个描述符的大小是固定的(见上面的三元组结构),无论底层的数组有多大,切片打开的“窗口”长度有多长,它都是不变的。此外,我们在进行数组切片化的时候,通常省略 max,而 max 的默认值为数组的长度。
另外,针对一个已存在的数组,我们还可以建立多个操作数组的切片,这些切片共享同一底层数组,切片对底层数组的操作也同样会反映到其他切片中。下面是为数组 arr 建立的两个切片的内存表示:
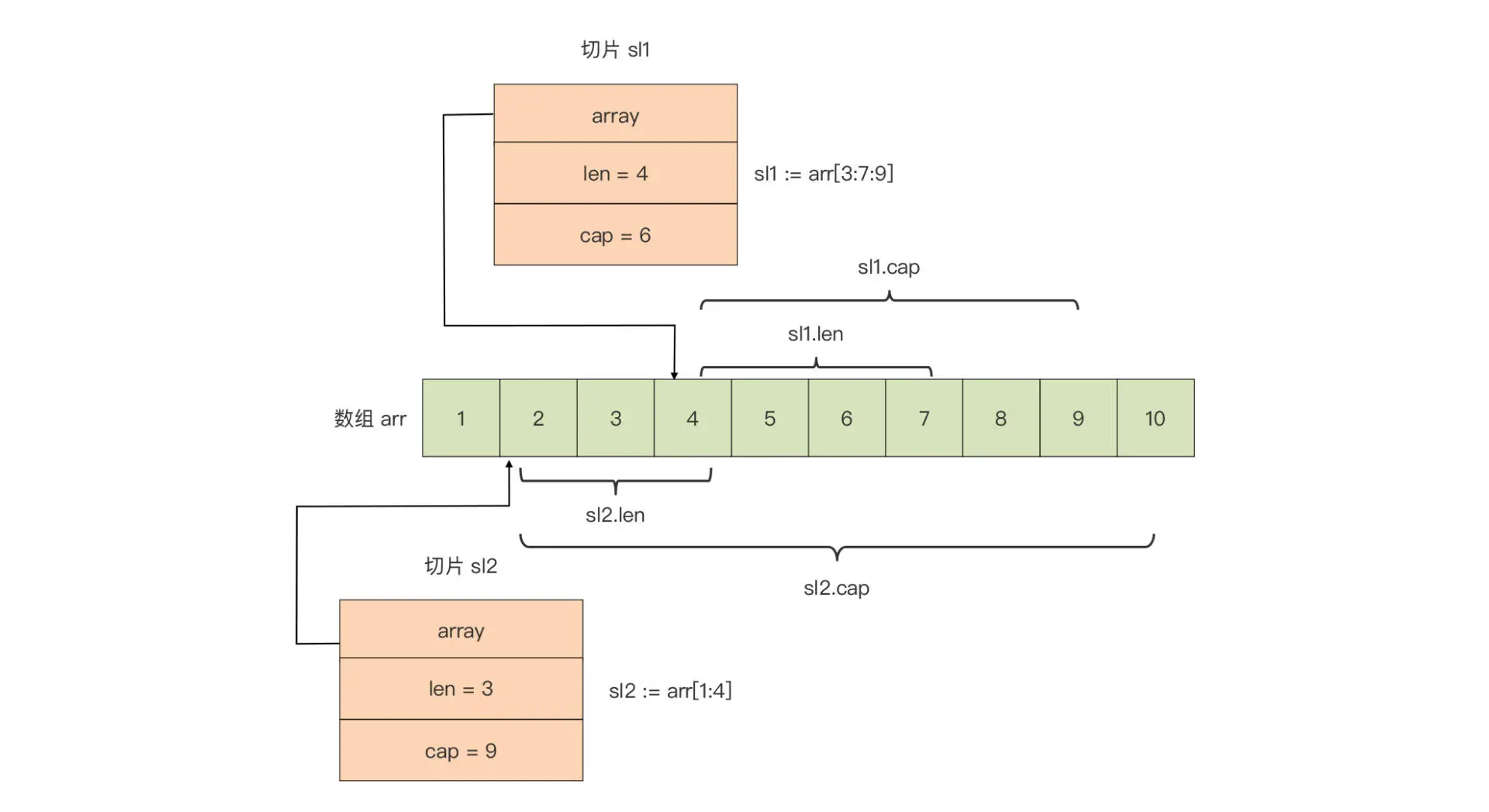
我们看到,上图中的两个切片 sl1 和 sl2 是数组 arr 的“描述符”,这样的情况下,无论我们通过哪个切片对数组进行的修改操作,都会反映到另一个切片中。比如,将 sl2[2]置为 14,那么 sl1[0]也会变成 14,因为 sl2[2]直接操作的是底层数组 arr 的第四个元素 arr[3]。
四、切片的本质(底层实现原理)
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)。
Go 切片在运行时其实是一个三元组结构,它在 Go 运行时中的表示如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
我们可以看到,每个切片包含三个字段:
array: 是指向底层数组的指针;len: 是切片的长度,即切片中当前元素的个数;cap: 是底层数组的长度,也是切片的最大容量,cap值永远大于等于len值。
如果我们用这个三元组结构表示切片类型变量 nums,会是这样:

我们看到,Go 编译器会自动为每个新创建的切片,建立一个底层数组,默认底层数组的长度与切片初始元素个数相同。
五、切片的动态扩容
5.1 切片的动态扩容介绍
“动态扩容”指的就是,当我们通过 append 操作向切片追加数据的时候,如果这时切片的 len 值和 cap 值是相等的,也就是说切片底层数组已经没有空闲空间再来存储追加的值了,Go 运行时就会对这个切片做扩容操作,来保证切片始终能存储下追加的新值。Go会自动创建一个新的底层数组,并将原数组的元素复制到新数组中,从而实现切片的扩容。
前面的切片变量 nums 之所以可以存储下新追加的值,就是因为 Go 对其进行了动态扩容,也就是重新分配了其底层数组,从一个长度为 6 的数组变成了一个长为 12 的数组。
5.2 append() 方法为切片扩容添加元素(切片追加元素)
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)
func main(){
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
}
**注意:**通过var声明的零值切片可以在append()函数直接使用,无需初始化。
var s []int
s = append(s, 1, 2, 3)
没有必要像下面的代码一样初始化一个切片再传入append()函数使用,
s := []int{} // 没有必要初始化
s = append(s, 1, 2, 3)
var s = make([]int) // 没有必要初始化
s = append(s, 1, 2, 3)
每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
接下来,我们再通过一个例子来体会一下切片动态扩容的过程:
var s []int
s = append(s, 11)
fmt.Println(len(s), cap(s)) //1 1
s = append(s, 12)
fmt.Println(len(s), cap(s)) //2 2
s = append(s, 13)
fmt.Println(len(s), cap(s)) //3 4
s = append(s, 14)
fmt.Println(len(s), cap(s)) //4 4
s = append(s, 15)
fmt.Println(len(s), cap(s)) //5 8
在这个例子中,我们看到,append 会根据切片对底层数组容量的需求,对底层数组进行动态调整。具体我们一步步分析。
最开始,s 初值为零值(nil),这个时候 s 没有“绑定”底层数组。我们先通过 append 操作向切片 s 添加一个元素 11,这个时候,append 会先分配底层数组 u1(数组长度 1),然后将 s 内部表示中的 array 指向 u1,并设置 len = 1, cap = 1;
接着,我们通过 append 操作向切片 s 再添加第二个元素 12,这个时候 len(s) = 1,cap(s) = 1,append 判断底层数组剩余空间已经不能够满足添加新元素的要求了,于是它就创建了一个新的底层数组 u2,长度为 2(u1 数组长度的 2 倍),并把 u1 中的元素拷贝到 u2 中,最后将 s 内部表示中的 array 指向 u2,并设置 len = 2, cap = 2;
然后,第三步,我们通过 append 操作向切片 s 添加了第三个元素 13,这时 len(s) = 2,cap(s) = 2,append 判断底层数组剩余空间不能满足添加新元素的要求了,于是又创建了一个新的底层数组 u3,长度为 4(u2 数组长度的 2 倍),并把 u2 中的元素拷贝到 u3 中,最后把 s 内部表示中的 array 指向 u3,并设置 len = 3, cap 为 u3 数组长度,也就是 4 ;
第四步,我们依然通过 append 操作向切片 s 添加第四个元素 14,此时 len(s) = 3, cap(s) = 4,append 判断底层数组剩余空间可以满足添加新元素的要求,所以就把 14 放在下一个元素的位置 (数组 u3 末尾),并把 s 内部表示中的 len 加 1,变为 4;
但我们的第五步又通过 append 操作,向切片 s 添加最后一个元素 15,这时 len(s) = 4,cap(s) = 4,append 判断底层数组剩余空间又不够了,于是创建了一个新的底层数组 u4,长度为 8(u3 数组长度的 2 倍),并将 u3 中的元素拷贝到 u4 中,最后将 s 内部表示中的 array 指向 u4,并设置 len = 5, cap 为 u4 数组长度,也就是 8。
到这里,这个动态扩容的过程就结束了。我们看到,append 会根据切片的需要,在当前底层数组容量无法满足的情况下,动态分配新的数组,新数组长度会按一定规律扩展。在上面这段代码中,针对元素是 int 型的数组,新数组的容量是当前数组的 2 倍。新数组建立后,append 会把旧数组中的数据拷贝到新数组中,之后新数组便成为了切片的底层数组,旧数组会被垃圾回收掉。
不过 append 操作的这种自动扩容行为,有些时候会给我们开发者带来一些困惑,比如基于一个已有数组建立的切片,一旦追加的数据操作触碰到切片的容量上限(实质上也是数组容量的上界),切片就会和原数组解除“绑定”,后续对切片的任何修改都不会反映到原数组中了。我们再来看这段代码:
u := [...]int{11, 12, 13, 14, 15}
fmt.Println("array:", u) // [11, 12, 13, 14, 15]
s := u[1:3]
fmt.Printf("slice(len=%d, cap=%d): %v\n", len(s), cap(s), s) // [12, 13]
s = append(s, 24)
fmt.Println("after append 24, array:", u)
fmt.Printf("after append 24, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
s = append(s, 25)
fmt.Println("after append 25, array:", u)
fmt.Printf("after append 25, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
s = append(s, 26)
fmt.Println("after append 26, array:", u)
fmt.Printf("after append 26, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
s[0] = 22
fmt.Println("after reassign 1st elem of slice, array:", u)
fmt.Printf("after reassign 1st elem of slice, slice(len=%d, cap=%d): %v\n", len(s), cap(s), s)
输出:
array: [11 12 13 14 15]
slice(len=2, cap=4): [12 13]
after append 24, array: [11 12 13 24 15]
after append 24, slice(len=3, cap=4): [12 13 24]
after append 25, array: [11 12 13 24 25]
after append 25, slice(len=4, cap=4): [12 13 24 25]
after append 26, array: [11 12 13 24 25]
after append 26, slice(len=5, cap=8): [12 13 24 25 26]
after reassign 1st elem of slice, array: [11 12 13 24 25]
after reassign 1st elem of slice, slice(len=5, cap=8): [22 13 24 25 26]
这里,在 append 25 之后,切片的元素已经触碰到了底层数组 u 的边界了。然后我们再 append 26 之后,append 发现底层数组已经无法满足 append 的要求,于是新创建了一个底层数组(数组长度为 cap(s) 的 2 倍,即 8),并将 slice 的元素拷贝到新数组中了。所以,从上面的结果可以看出:
append()函数将元素追加到切片的最后并返回该切片。- 切片numSlice的容量按照1,2,4,8,16这样的规则自动进行扩容,每次扩容后都是扩容前的2倍,会重新申请一个底层数组,把值copy进去。
append()函数还支持一次性追加多个元素。 例如:
slice := []int{1, 2, 3}
// 使用 append() 函数一次性追加多个元素
slice = append(slice, 4, 5, 6)
fmt.Println(slice) // 输出 [1 2 3 4 5 6]
5.2 切片的扩容策略
可以通过查看$GOROOT/src/runtime/slice.go源码,其中扩容相关代码如下:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
从上面的代码可以看出以下内容:
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。
六、获取切片的长度和容量
在Go语言中,你可以使用内置的len()和cap()函数来获取切片的长度和容量。切片的长度表示切片当前包含的元素个数,切片的容量表示底层数组中可以容纳的元素个数。
6.1 获取切片的长度
使用len()函数可以获取切片的长度。切片的长度是指切片当前包含的元素个数。
下面是一个示例:
package main
import "fmt"
func main() {
// 声明一个切片
slice := []int{1, 2, 3, 4, 5}
// 使用 len() 函数获取切片的长度
length := len(slice)
fmt.Printf("切片的长度是:%d\n", length) // 输出 "切片的长度是:5"
}
在上面的示例中,len(slice)返回了切片slice的长度,即5个元素。
6.2 获取切片的容量
使用cap()函数可以获取切片的容量。切片的容量是指底层数组中可以容纳的元素个数,它通常会大于或等于切片的长度。
下面是一个示例:
package main
import "fmt"
func main() {
// 声明一个切片
slice := []int{1, 2, 3, 4, 5}
// 使用 cap() 函数获取切片的容量
capacity := cap(slice)
fmt.Printf("切片的容量是:%d\n", capacity) // 输出 "切片的容量是:5"
}
七、切片的常用操作
7.1 判断切片是否为空
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
slice := []int{}
isEmpty := len(slice) == 0 // 判断切片是否为空,值为true
7.2 从切片中删除元素
Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素。 代码如下:
slice := []int{1, 2, 3, 4, 5}
indexToDelete := 2
slice = append(slice[:indexToDelete], slice[indexToDelete+1:]...)
fmt.Println(slice) // 输出 [1 2 4 5]
总结一下就是:要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
7.3 使用copy()函数复制切片
首先我们来看一个问题:
func main() {
a := []int{1, 2, 3, 4, 5}
b := a
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(b) //[1 2 3 4 5]
b[0] = 1000
fmt.Println(a) //[1000 2 3 4 5]
fmt.Println(b) //[1000 2 3 4 5]
}
由于切片是引用类型,所以a和b其实都指向了同一块内存地址。修改b的同时a的值也会发生变化。
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T)
其中:
- srcSlice: 数据来源切片
- destSlice: 目标切片
举个例子:
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //使用copy()函数将切片a中的元素复制到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}
7.4 切片的赋值拷贝
下面的代码中演示了拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意。
func main() {
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
}
注意:切片的更改会影响底层数组,数组的更改会影响切片
7.5 切片遍历
在Go语言中,你可以使用不同的方法来遍历切片,具体取决于你的需求。以下是一些常见的切片遍历方法:
7.5.1 使用for循环和索引遍历
最常见的遍历切片的方法是使用for循环。你可以使用range关键字来遍历切片中的元素。以下是一个示例:
slice := []int{1, 2, 3, 4, 5}
// 根据索引来遍历
for i := 0; i < len(slice); i++ {
fmt.Println(i, slice[i])
}
在上述示例中,我们使用了for循环来初始化索引i,然后使用len(s)来获取切片s的长度,最后通过索引i来访问切片的每个元素。
7.5.2 使用for range遍历并忽略索引
如果你只关心元素的值而不需要索引,也可以使用for循环和索引来遍历切片。以下是一个示例:
slice := []int{1, 2, 3, 4, 5}
for _, value := range slice {
fmt.Printf("值:%d\n", value)
}
7.6 切片不能直接比较
切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。 切片唯一合法的比较操作是和nil比较。 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil,例如下面的示例:
var s1 []int //len(s1)=0;cap(s1)=0;s1==nil
s2 := []int{} //len(s2)=0;cap(s2)=0;s2!=nil
s3 := make([]int, 0) //len(s3)=0;cap(s3)=0;s3!=nil
// 判断切片是否为空
if len(s1) == 0 && len(s2) == 0 && len(s3) == 0 {
fmt.Println("以上切片都是空切片!")
}
所以要判断一个切片是否是空的,要使用len(s) == 0来判断,不应该使用s == nil来判断。
7.7 切片过滤
在Go语言中,可以通过自定义函数来实现切片的过滤操作。过滤操作通常包括以下几个步骤:
- 创建一个新的切片,用于存储过滤后的元素。
- 遍历原始切片,对每个元素应用过滤条件,符合条件的元素添加到新切片中。
- 返回新的切片,其中包含满足过滤条件的元素。
下面是一个示例,演示如何对切片进行过滤操作:
package main
import "fmt"
func main() {
// 原始切片
numbers := []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
// 过滤条件:保留偶数
filteredNumbers := filter(numbers, func(num int) bool {
return num%2 == 0
})
fmt.Println(filteredNumbers) // 输出 [2 4 6 8]
}
// filter 函数用于对切片进行过滤
func filter(slice []int, condition func(int) bool) []int {
filtered := []int{}
for _, num := range slice {
if condition(num) {
filtered = append(filtered, num)
}
}
return filtered
}
7.8 切片的特定索引位置插入元素
要在切片的特定索引位置插入元素,你可以执行以下步骤:
- 创建一个新的切片,用于存储插入元素后的结果。
- 将原始切片的前部分(不包括插入位置之后的元素)追加到新切片中。
- 追加要插入的元素。
- 将原始切片的剩余部分(插入位置之后的元素)追加到新切片中。
- 返回新切片,其中包含插入元素后的结果。
以下是一个示例,演示如何在切片的特定索引位置插入元素:
package main
import "fmt"
func main() {
// 原始切片
slice := []int{1, 2, 3, 4, 5}
// 插入元素 99 到索引位置 2
index := 2
elementToInsert := 99
// 执行插入操作
result := insert(slice, index, elementToInsert)
fmt.Println(result) // 输出 [1 2 99 3 4 5]
}
// insert 函数用于在切片的特定索引位置插入元素
func insert(slice []int, index int, element int) []int {
// 创建新切片
result := make([]int, len(slice)+1)
// 复制原始切片的前部分到新切片中
copy(result[:index], slice[:index])
// 插入元素到新切片
result[index] = element
// 复制原始切片的剩余部分到新切片中
copy(result[index+1:], slice[index:])
return result
}
7.9 切片的合并
要将多个切片合并成一个切片,你可以使用append()函数。append()函数可以接受多个切片,并将它们合并到一个新的切片中。以下是一个示例:
package main
import "fmt"
func main() {
// 定义多个切片
slice1 := []int{1, 2, 3}
slice2 := []int{4, 5}
slice3 := []int{6, 7, 8}
// 合并切片
mergedSlice := mergeSlices(slice1, slice2, slice3)
fmt.Println(mergedSlice) // 输出 [1 2 3 4 5 6 7 8]
}
// mergeSlices 函数用于合并多个切片
func mergeSlices(slices ...[]int) []int {
// 计算总长度
totalLength := 0
for _, slice := range slices {
totalLength += len(slice)
}
// 创建新切片
mergedSlice := make([]int, totalLength)
// 复制每个切片到新切片
index := 0
for _, slice := range slices {
copy(mergedSlice[index:], slice)
index += len(slice)
}
return mergedSlice
}
八、切片表达式和切割切片
切片表达式从字符串、数组、指向数组或切片的指针构造子字符串或切片。它有两种变体:一种指定low和high两个索引界限值的简单的形式,另一种是除了low和high索引界限值外还指定容量的完整的形式。
8.1 简单切片表达式
切片的底层就是一个数组,所以我们可以基于数组通过切片表达式得到切片。 切片表达式中的low和high表示一个索引范围(左包含,右不包含),也就是下面代码中从数组a中选出1<=索引值<4的元素组成切片s,得到的切片长度=high-low,容量等于得到的切片的底层数组的容量。
func main() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s := a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s))
}
输出:
s:[2 3] len(s):2 cap(s):4
注意:
对于数组或字符串,如果0 <= low <= high <= len(a),则索引合法,否则就会索引越界(out of range)。
对切片再执行切片表达式时(切片再切片),high的上限边界是切片的容量cap(a),而不是长度。常量索引必须是非负的,并且可以用int类型的值表示;对于数组或常量字符串,常量索引也必须在有效范围内。如果low和high两个指标都是常数,它们必须满足low <= high。如果索引在运行时超出范围,就会发生运行时panic。
func main() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s := a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s))
s2 := s[3:4] // 索引的上限是cap(s)而不是len(s)
fmt.Printf("s2:%v len(s2):%v cap(s2):%v\n", s2, len(s2), cap(s2))
}
输出:
s:[2 3] len(s):2 cap(s):4
s2:[5] len(s2):1 cap(s2):1
8.2 完整切片表达式
对于数组,指向数组的指针,或切片a(注意不能是字符串)支持完整切片表达式:
a[low : high : max]
上面的代码会构造与简单切片表达式a[low: high]相同类型、相同长度和元素的切片。另外,它会将得到的结果切片的容量设置为max-low。在完整切片表达式中只有第一个索引值(low)可以省略;它默认为0。
func main() {
a := [5]int{1, 2, 3, 4, 5}
t := a[1:3:5]
fmt.Printf("t:%v len(t):%v cap(t):%v\n", t, len(t), cap(t))
}
输出结果:
t:[2 3] len(t):2 cap(t):4
完整切片表达式需要满足的条件是0 <= low <= high <= max <= cap(a),其他条件和简单切片表达式相同。