超标量处理器设计——第三章_虚拟存储器
参考《超标量处理器》姚永斌著
文章目录
- 超标量处理器设计——第三章_虚拟存储器
- 3.2 地址转换
- 3.2.1 单级页表
- 3.2.2 多级页表
- 3.2.3 Page Fault
- 3.3 程序保护
- 3.4 加入TLB和Cache
- 3.4.1 TLB的设计
- TLB缺失
- TLB的写入
- 对TLB进行控制
- 3.4.2 Cache的设计
- 1. Virtual Cache
- 2. 对Cache进行控制
- 3.4.3 将TLB和Cache放入流水线
- 1. Physically-Indexed, Physicaly-Taged
- 2. Virtually-Indexed, Physicaly-Taged
- 3. Virtually-Indexed, Virtually-Taged
- 访问存储器时可能的情况
3.2 地址转换
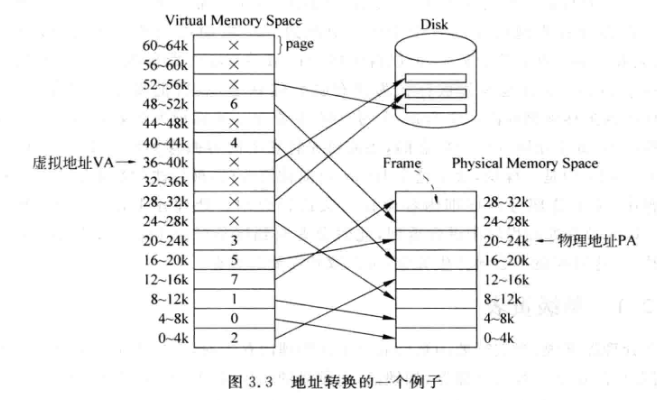
- 分页机制, 虚拟地址划分以页为单位(page),典型大小为4KB
- 物理地址也有页,与虚拟地址的页大小相同,但是称为帧(frame)
- 虚拟地址: VA ; 物理地址:PA
- VA由两部分组成:
- VPN(Virtual Page Number), 用来索引虚拟页
- Page offset, 页内偏移,对于4KB的页来说偏移需要12位
- PA也由两部分组成:
- PFN(Physical Frame Number), 用来索引物理页
- Page offset, 物理页内偏移,一般与虚拟地址的offset相同
- MMU负责VA到PA的转换
3.2.1 单级页表
- 当处理器只需要的页不在物理内存中,就发生了Page Fault; 处理该异常需要ms级别,需要尽量避免
- 页表(Page Table,PT)用来存储VA到PA的映射关系。这样VA的一个页就可以放在物理地址的任意一个帧上了
- 页表放在物理内存中,每个进程都有自己的页表
- 页表寄存器(Page Table Register,PTR)用来索引页表
- PTR和VA寻址页的过程如下:
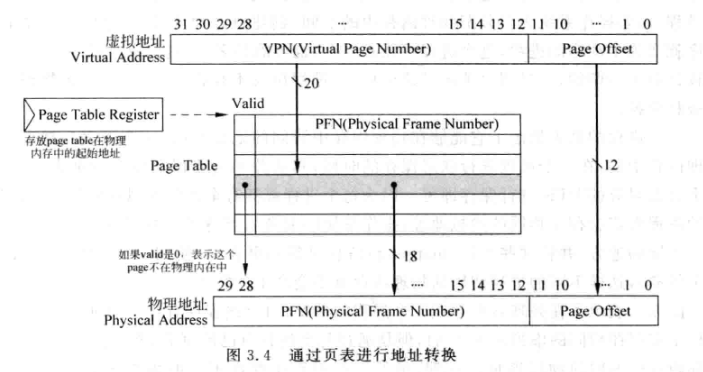
- 单级页表中,VPN只有20位,也就是说一个页表的表项数就是2^20也就是1M, 每个表项存储的是PFN,也就是18bit,但是物理内存数据位宽是32bit,所以剩下的14bit就可以用来存有效位,页读写属性等
- 因此单级页表大小为1M*4B=4MB大小,显然是很庞大的,如果每个进程都有一个4MB的页表,那…
- 单级页表访问内存(两次访问物理内存):
- 根据PTR定位物理内存中的页表
- 根据VPN访问页表中的PFN
- 根据PFN访问物理内存
-
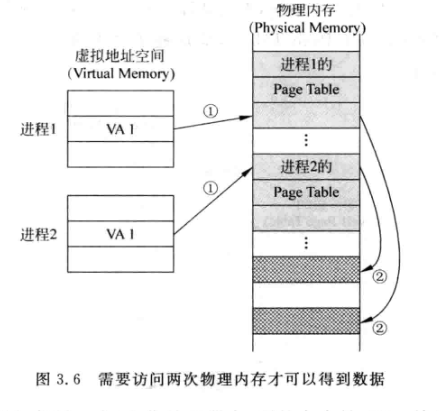
3.2.2 多级页表
- 单级的页表一张就要4MB的巨大空间,而且还要是连续的
- 多级页表将单级页表进行进一步划分, 从而实现更小的子页, 也不需要巨大的连续的地址空间
- 下面是一个多级页表的案例:
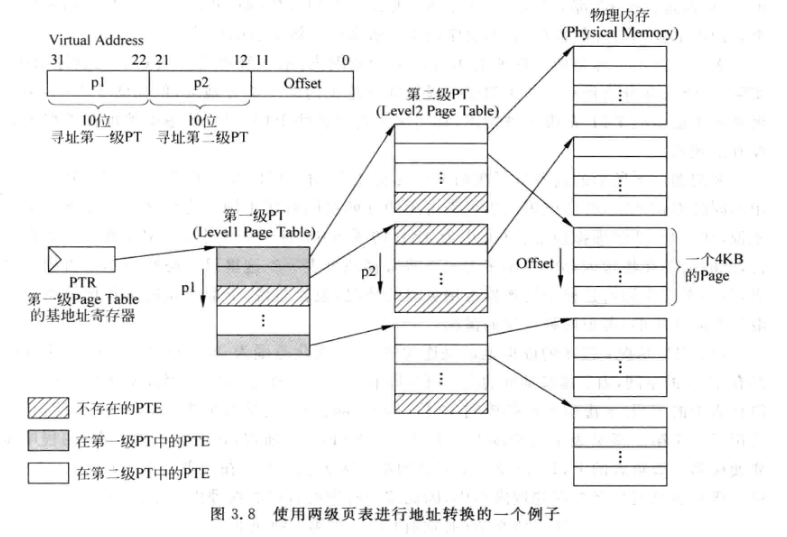
- 用PTR索引到第一级页表在物理内存中的位置
- 用VA的p1部分寻址第一级页表中的PFN, 根据一级页表PFN寻址第二级页表
- 用VA的p2部分寻址第二级页表中的PFN, 根据二级页表PFN寻址最终的页
- 操作系统动态地创建一二级页表: 当p1发生变化时, 会创建新的二级页表, p2变化时则不会创建新的页表
- 一个一级和二级页表都有2^10个表项, 因为物理内存是32位, 所以大小均为4KB, 正好可以放进物理内存的一个页内
- 一级页表4KB大小一般是不可避免的, 而二级页表则是根据需求逐步创建的, 操作系统会尽量让虚拟地址集中, 减少二级页表的开辟
- 易于扩展, 当处理器增加到64位, 可以通过增加级数来减少页表的占用:

- 虚拟内存的优点:
- 让每个进程都能独占地址空间
- 方便管理物理内存, 可以将连续的虚拟地址映射到不连续的物理地址, 从而减小物理内存的碎片
- 为所有进程分配的总物理内存之和可以大于实际的物理内存大小, 因为有些页可能存在磁盘的swap区
- 可以实现管理每个页的访问权限
3.2.3 Page Fault
- 一个进程的虚拟地址访问页表时, 发现对应的PTE有效位为0, 表示这个页还没有放到物理内存中, 就发生了Page Fault
- 发生Page Fault异常时, 处理器跳转到异常处理程序入口地址, 该程序会根据某个算法从物理内存中找到空闲的地方, 将需要的页从硬盘中搬进来, 并将新的对应关系写到PTE中
- 虚拟地址并不能知道一个页在硬盘中的位置, 需要在swap空间中, 存储一个进程所有的页, 还会保存一个表格记录每个页在硬盘中的位置
- 页表中包含的内容:
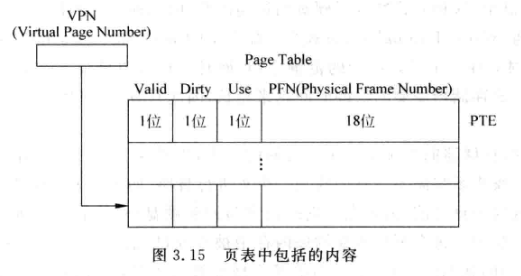
- valid表示是否在物理内存中, Dirty表示对应的表项是否被修改,供write back时处理, Use位表示对应地址最近是否被访问过,用来实现PLRU
3.3 程序保护
- 操作系统本身也有指令和数据, 但是操作系统可以直接访问物理内存
- 物理内存中有一部分地址范围专门供操作系统使用, 不允许别的进程随意访问
- ARM中采用二级页表, 第二级(当然第一级也可以有, 控制的范围更大)的页表的每个PTE有一个AP关键字:
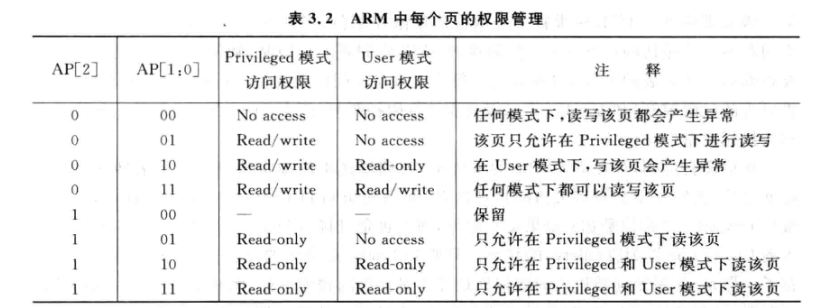
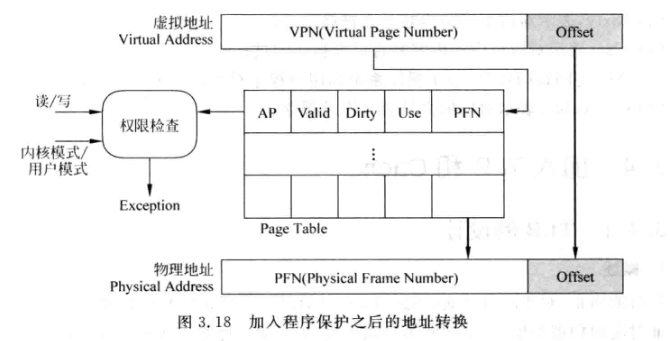
- 处理器的VA转换为PA后, 实际不会直接访问物理内存, 而是先访问D-Cache
- 但是如果VA是要访问芯片外设, 例如LCD的驱动模块寄存器, 那这些地址就不能被缓存, 所以VA到PA的映射有一块去与是不能被缓存的, 可以在页表中进行标记.
- 目前页表的内容实际包括:

3.4 加入TLB和Cache
3.4.1 TLB的设计
- 对于两级页表, 需要访问物理内存两次才能的到物理地址, 延时太长了
- 增加一个页表的Cache, 加速这一过程, 将页表中最近使用的PTE缓存起来, 称为TLB (Translation Lookaside Buffer)
- TLB只有时间相关性
- 一般TLB是全相连的, 容量不会很大
- TLB内容:
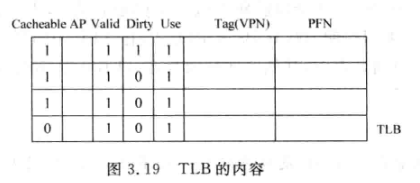
- 通常在现代处理器中, 页大小都是可变的, 以灵活地支持不同大小的程序, 减少页内碎片(Page Fragment)
- 例如在MIPS的TLB中有一个12位的Pagemask来表示被映射页的大小

TLB缺失
-
TLB因为容量较小, 还是比较容易发生缺失的, 具体有以下几种情况:
- 虚拟地址对应的页不在物理内存中
- 虚拟地址对应的页在物理内存中, 但是页表中对应该页的PTE还没放到TLB
- 虚拟地址对应的页在物理内存中, 也曾经存在于TLB, 但在后续被替换出去了(与2本质相同)
-
PTW (Page Table Walk): 从页表中找到映射关系, 将其写入TLB的过程
-
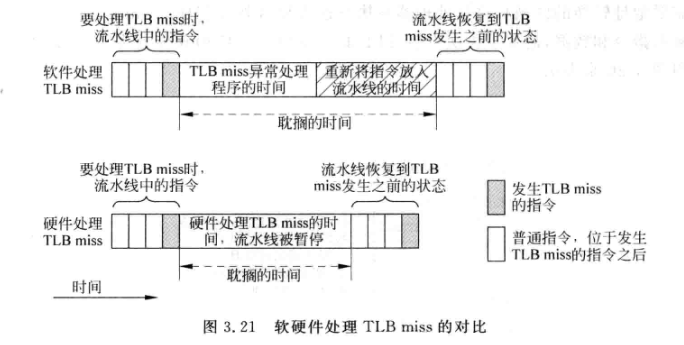
软件实现PTW: 通常只需要硬件支持TLB的读写操作, 当TLB失效时触发异常, 冲刷流水线.操作系统有一段程序专门处理TLB缺失异常, 因为该程序位于操作系统区, 所以地址不需要进行转换, 不会再次发生TLB缺失:

- 处理完成后重新执行TLB miss的指令
-
硬件实现PTW : 由MMU完成, 当发现TLB缺失, MMU自动使用VA来寻址物理内存中的页表. 只需要用状态机逐级查找即可.
- 前提是PTE有效, 也就是需要操作系统保证页表已经在物理内存中建立好了, 否则会报Page Fault
- 适合超标量处理器, 不需要冲刷流水线, 但还是会暂停流水线
-
-
硬件PTW的延时更小:
- TLB的替换可以使用LRU, 但是实际上对TLB来说随机替换(时钟算法)效果较好
TLB的写入
- 有了TLB后, VA会先访问TLB而不是页表, 也就是说valid, dirty这些标志位也是先更新TLB中的, 页表中的对应标记只有在TLB写回页表时才会更新, 这样操作系统在Page Fault时无法找到合适的页进行替换
- 解决: TLB中记录的页都不能被从物理内存中替换出去
对TLB进行控制
- TLB是页表的子集, 如果一个页的映射关系在页表中不存在了, 那么他在TLB中也不该存在, 例如:
- 一个进程结束时, 进程指令,数据和堆栈的页表需要变为无效来释放物理内存. 而此时I-TLB中可能存在该进程的程序的PTE, 此时需要根据ASID来将相应的TLB项抹掉
- 当进程占用物理内存过大, 操作系统可能会将该进程中一些不经常使用的页写回硬盘, 此时也需要将页表中的映射关系置为无效, 但是TLB中一般不做处理, 因为这些项后续可能也会继续使用
- TLB的管理主要包括:

3.4.2 Cache的设计
1. Virtual Cache
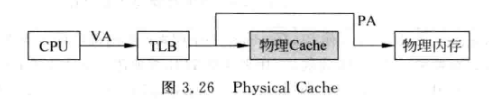
- 使用物理地址进行寻址的Cache, 称为物理Cache (Physical Cache):
- 使用虚拟地址进行寻址的Cache, 称为虚拟Cache (Virtual Cache):
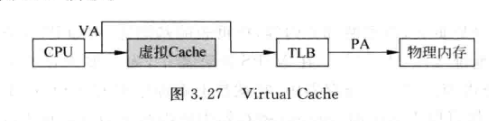
- 使用虚拟Cache可以降低访问数据的延迟
- 物理地址是唯一的, 两个不同的物理地址对应物理内存的两个不同位置, 但是虚拟地址会引入两个新问题:
-
同义问题(synonyms), 也叫重名(aliasing): 多个虚拟地址对应同一个物理地址, 例如多个进程的不同虚拟地址对应同一个物理地址. 该问题会导致浪费Cache空间, 并且当执行store指令写数据到虚拟Cache时, 只会修改一个地址的数据, 其他对应相同物理地址的line不会被修改, 导致数据出错.

-
如果页是4KB, Cache大小比页小, 则同义问题不会发生. 因为VA中的低12位是偏移量,与PA的低12位一定是相同的. 如果两个VA对应到了同一个PA, 那么这两个VA的低12位一定是相同的. 所以如果Cache小于4KB, 那么这两个VA在Cache中实际寻址到相同的line
-
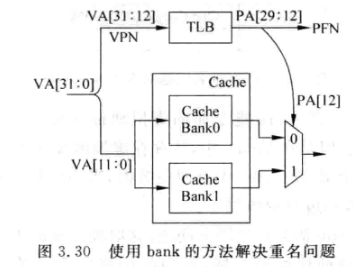
解决同义的一个方法是bank, 原理就是利用了12位offset:
-
-
如图, 假设Cache是一个8KB直接相连的Cache, 可以拆分为两个4KB的bank, 两个bank都用12位offset寻址, 如果两个不同的VA的高20位经过TLB转换后得到同一个PA, 那么经过PA[12]选择的bank结果就是相同的, 也就是说两个不同的VA如果对应同一个PA, 那么经过bank Cache处理最后一定访问到同一个line, 消除了同义问题
-
-
- 同名问题(homonyms), 不同进程的相同虚拟地址对应不同的物理地址. 当从一个进程切换到另一个进程时, 新的进程使用虚拟地址访问数据, 可能会得到上一个进程相同虚拟地址对应的不同数据。
-
最简单的方法是进程切换时将虚拟cache的内容都置为无效,但是如果频繁切换进程, 情况TLB和Cache代价就很大
-
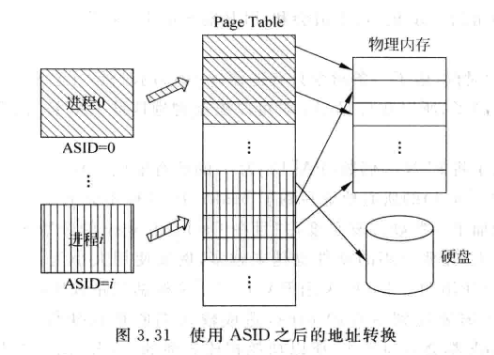
可以在虚拟地址中增加一部分内容来表示进程编号, 称为 PID(Process ID)或者 ASID(Address Space IDentifier),这样只需要进程切换时将对应ASID的cache line置为无效即可。
-
ASID相当于扩充了虚拟地址, 让不同进程使用不同段的虚拟地址:
-
-
新的问题:如果进程要共享一个页,怎么实现?
- 再增加一个标志位, 称为Global位,简称G位, 当一个页不只是属于某个进程,而是所有页共享,则将其置1
- G位是1的页表,不需要理会ASID
-
新的问题:引入ASID后虚拟地址变大, 导致一级和二级页表变大(如果ASID有8位,那两者的地址都要多加4bit变为14地址)
-
采用三级页表,一级页表用ASID寻址:
-

-
会导致多访问一次物理内存,延时变长
-
-
当进程数超出ASID时,会挑一个不常用的ASID,将TLB对应内容清空,分配新进程给他,并覆盖PTR
-
2. 对Cache进行控制
Cache的使用场景:
- 当DMA需将物理内存中的数据搬到其他地方, 但是此时物理内存中最新的数据还在D-Cache中时, 需要将D-Cache中的脏位内容写回到物理内存
- 当DMA从外界版数据到物理内存, 而该地址又在D-Cache中,那么需要将D-Cache的该地址置为无效
- 当Page Fault时,需要从硬盘中读取一个页并写入物理内存, 如果物理内存该页是脏的,且该页部分内容位于D-Cache, 就要先将D-Cache内容写回物理内存
- 处理器可能会执行一些自修改指令,将后续要执行的指令进行修改, 写入D-Cache, 再写回到物理内存, 同时将I-Cache中的内容都置为无效, 才能保证处理器执行到最新的指令
因此对Cache需要以下操作(clean是指将dirty位为1的line写回物理内存):

- ARM采用协处理器寄存器的方式管理Cache, MIPS则有专门的Cache指令
3.4.3 将TLB和Cache放入流水线
1. Physically-Indexed, Physicaly-Taged
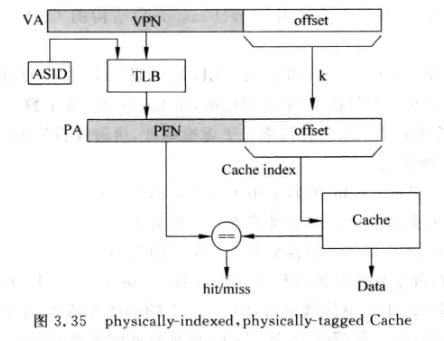
- 真实处理器中很少采用, 因为它串行了TLB和Cache的访问,延迟较大, 实际上offset作为index可以并行访问, 改进方案如下:
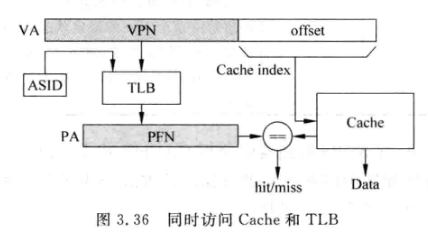
- 限制: 对Cache大小有限制, 只能容纳offset项
2. Virtually-Indexed, Physicaly-Taged
- 直接用虚拟地址的一部分寻址Cache
- 访问Cache和TLB可以并行
- 根据寻址Cache的虚拟地址长度, 有三种情况, 其中k是offset长度, L是cache line数, b是cache数据宽度:
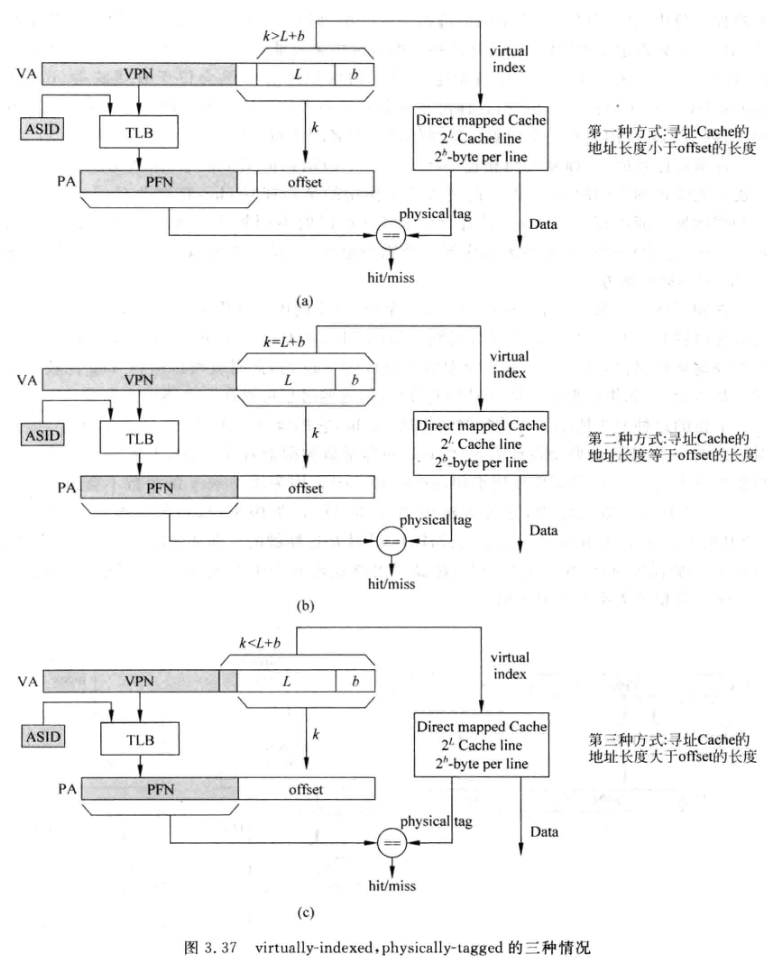
-
上图中的(1)(2)其实是一种情况, 此时直接用虚拟地址[L+b-1:0]来寻址Cache, 并将Tag和TLB出来的PFN进行比较. 这种设计可以避免同义问题(在上文中提到了, 因为寻址cache的地址位数小与等于offset位数)
- 这种方式对Cache的容量有限制, 单way必须小于4KB, 当然可以增加way来增加容量:
-

-
图(3)就是第二种情况, 适合容量比较大的Cache
-
会有同义问题:
-
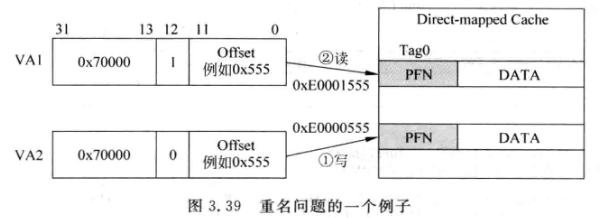
-
VA1和VA2假设对应同一个物理地址, 虽然两者低12位相同, 位[12]不同, 这就导致两个地址映射到不同的两个cache line上, 浪费cache空间, 且造成同一个物理地址的数据不匹配
-
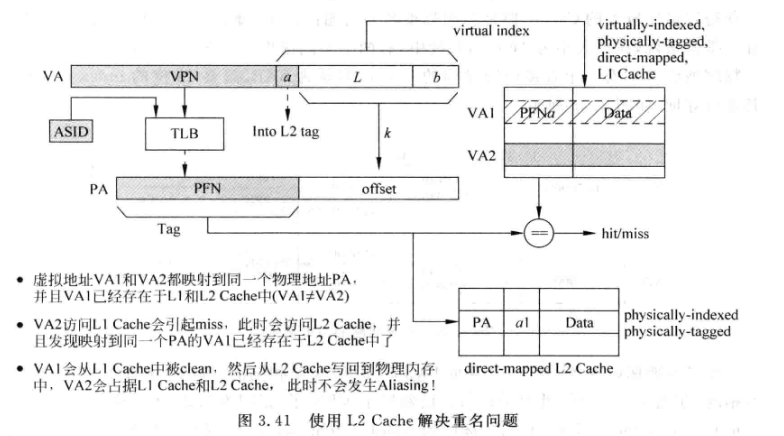
除了用之前提到的bank方法解决同义问题, 还可以使用inclusive L2 Cache解决:
-
-
L2需要是physically-indexed, physically-tagged
-
L2 Cache中还需要对PA进行标记, 用k-L-b也就是VA的a部分对L2中的PA进行标记. 这样当VA2转换为PA后访问L2, tag命中, 还需要检查a是否相等, 如果不等表示存在和VA2重名的虚拟地址(VA1), 此时应该先根据a和offset找到Cache中的VA1对应cache line, 将其置为无效(如果dirty=1还需要进行clean), 这样L1Cache就不存在重名的虚拟地址了, 然后再将VA2的数据从L2搬到L1.
-
3. Virtually-Indexed, Virtually-Taged
- 用虚拟地址直接访问Cache
- 如果命中, 都不需要TLB参与, 缺失时才需要
- 仍然会有重名问题, 也可以通过L2 Cache来解决:
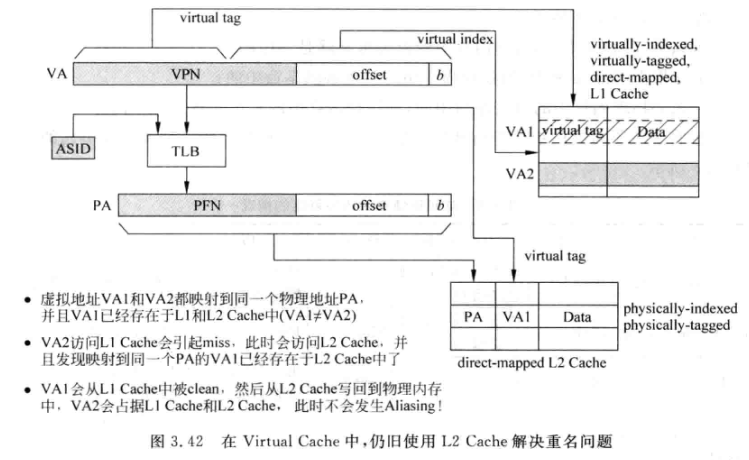
- 相比与上面L2中只存储a部分的虚拟地址, 此时需要在L2中保存完整的VA, 当VA2访问L2时, 发现同一个PA对应的标记是VA1, 表示有重名的虚拟地址, 根据标记VA1找到L1 Cache中对应的line, 进行相关(上文已经提过)操作
- 之所以这里要用完整的VA作为L2中的标记, 是因为此时是virtually-tag的结构, 需要用VA来进行tag比较, 所以L2要定位到L1中的表项必须存储完整的VA, 或者至少应该是VA中除去offset的部分.
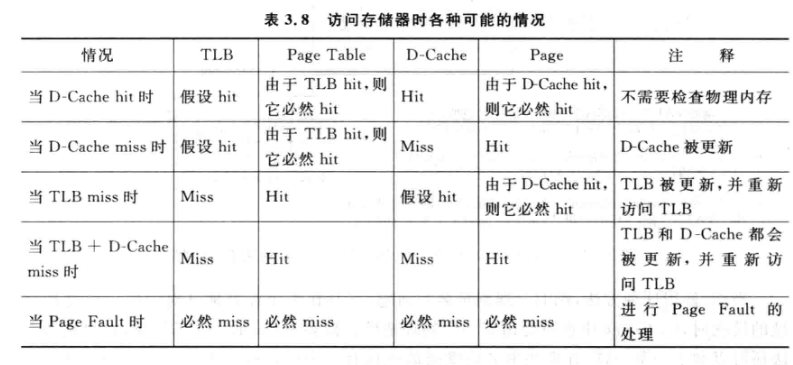
访问存储器时可能的情况
公众号已开通,想了解更多相关内容可以扫一扫下方二维码~











![[N1CTF 2018]eating_cms parse_url绕过](https://img-blog.csdnimg.cn/0d49f17c376c4762818dd8bc11c30ed9.png)