内容介绍
本文整理了客户终身价值(CLV或者CLTV)的相关概念,并对一家英国线上零售公司的一年交易数据进行分析,计算该公司所有客户的CLV并且建立回归预测模型。
一、客户生命周期价值
用户生命周期价值Customer Lifetime value(缩写是CLV 或者CLTV), 也有称为Lifetime Value(LTV),值得是在客户整个生命周期中企业能获得的总价值。
CLV 与 LTV 有什么区别?
多数情况下二者没有区别,比较模糊的情况下是:LTV不包括成本,而CLV是扣掉成本后的利润。
比如在互联网行业、APP、移动广告等业务中,使用的公式是:
LTV=LT(活跃天数)*ARPU(用户每次活跃产生的价值)
同时LTV还会结合CAC(获客成本Customer acquisition cost)一起分析,CAC公式如下:
CAC=总市场花费/对应花费带来的总新用户数
可见在这个场景中LTV是计算用户支出的总金额(不包括成本)。
比如这篇文章认为LTV是总收入,而CLV是利润(去掉成本), 并且使用具体的例子解释。
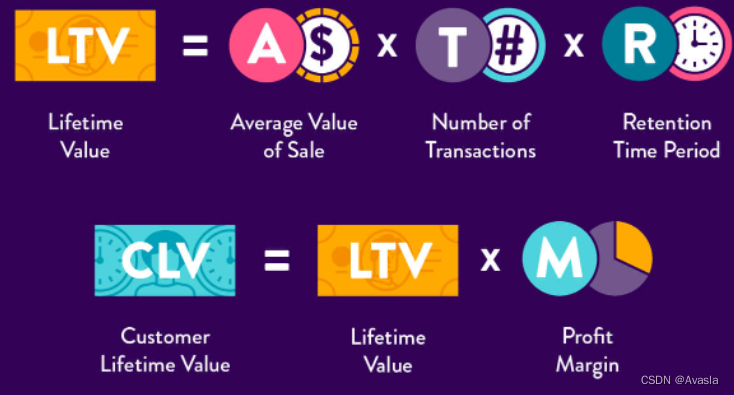
另外一篇文章中的CLV计算则是用的总收入。
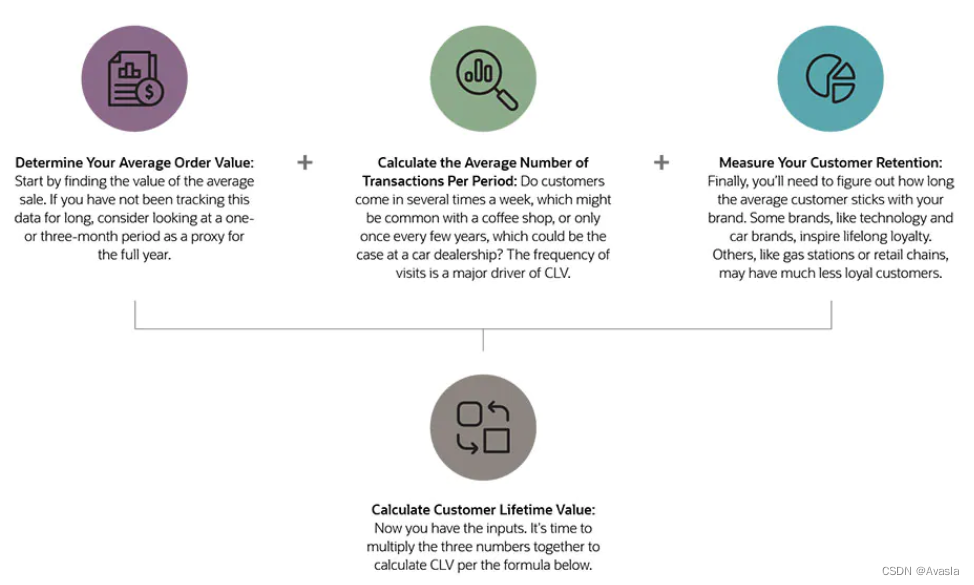
如何计算CLV?
比如一个客户每年都在会在一家商店里买东西,每个月花200元,一共有10年时间在这家店消费。那么对于这家商店而言,这个客户的终身价值就是他在店里一共消费的金额,即200*12*10=24000元。
1. CLV计算公式
在实际商业分析中,仅仅分析一个客户是没有意义的,一般是要去计算整个企业、或者不同产品、地区的CLV。由上面单个用户的计算过成,可以推导出:
客户终身价值(CLV)=客户价值(Customer Value) * 平均客户生命周期(Average Customer Lifespan)
其中,
客户价值(Customer Value)=平均支付金额(Average purchase value)*平均支付次数(Average purchase frequency)
- 平均支付金额(Average purchase value)= 总收入(Total Revenue) /总订单数(Total Number of Orders)
- 平均支付次数(Average purchase frequency)=总订单数(Total Number of Orders)/总客户数(Total Number of Customers)
客户的生命周期比较难预估,尤其是新的企业,可能没有足够的时间去观察平均的客户生命周期。
**客户生命周期(Customer Lifetime)**=1/Churn Rate
其中,
- 客户流失率(Churn Rate): 流失用户数/总用户数=1-留存率
- 客户留存率(Repeat Rate) : 留存用户数/总用户数
2.历史CLV计算公式
就是前面提到过的公式,常用于游戏、APP等互联网业务数据分析中:
CLV=LT(活跃天数)*ARPU(用户每次活跃产生的价值)
这种方法根据企业过去的毛利润来计算客户的生命周期价值,很简单直接。
3.传统 CLV 计算方法
因为业务增长是波动变化的,客户的支付总金额不可能一成不变,客户数量也在不断变化,还要考虑到通货膨胀的影响,传统的CLV计算公式为:

此计算涉及一些额外的概念:
- GML——每个客户生命周期的毛利率(gross margin per customer lifespan): 这是期望在平均客户生命周期内赚取的利润(即收入减去成本)
- R——留存率(Retention Rate): 在设定的时间段内留在您身边的客户百分比(相对于在那段时间内流失的客户)
- D——贴现率(Discount Rate): 考虑通货膨胀的百分比。这通常设置为 10%。
更多的计算方法可以参考这篇文章
CLV预测方法
这里简单介绍两种方法。
1. 直接估计
客户每年支付总金额*客户关系时长-总获客/服务成本
直接根据经验或者历史数据去预估各项数据,比如:
- 过去三年的平均收入是500元,
- 客户关系维持时间是5年,即5年的生命,
- 获客成本 50元
- 服务成本每年10元
CLV=500*5-50-10*5=2500-100=2400(元)
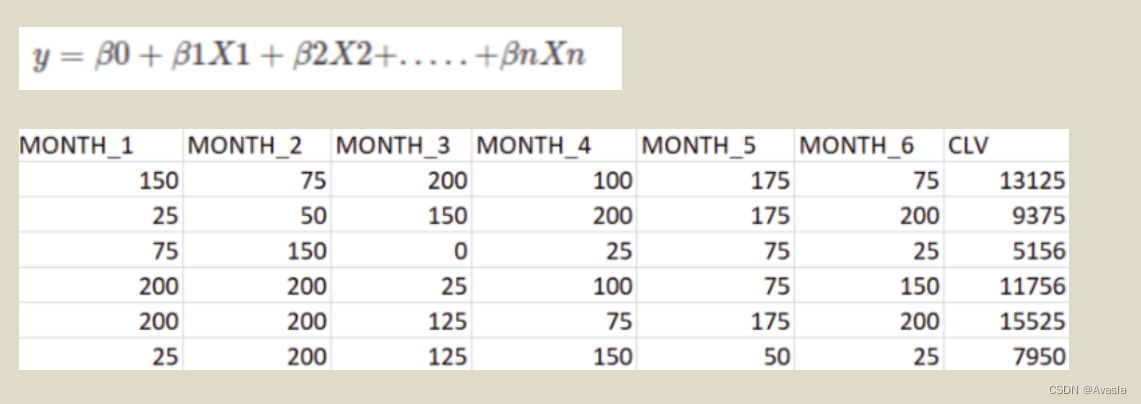
2. 基于历史数据建立预测模型
现存客户CLV预测模型,根据历史数据对未来的一个时间进行预测,可以使用近6个月或者过去三年的数据进行数据建模,求出下面这个拟合公式的各项参数:
二、客户价值CLV计算
数据集简介
数据集包含一家在英国注册的在线零售公司于 01/12/2010 和 09/12/2011 之间发生的所有交易。该公司主要销售各种场合的礼品,公司的许多客户都是批发商。
数据集一共包含8列:
- InvoiceNo:发票编号。标称,为每笔交易唯一分配的 6 位整数。如果此代码以字母“c”开头,则表示取消。
- StockCode:商品(商品)代码。标称,为每个不同的产品唯一分配的 5 位整数。
- Description: 描述。 产品(项目)名称。
- Quantity:数量。每笔交易每个产品(项目)的数量。
- InvoiceDate:发票日期和时间,每笔交易产生的日期和时间。
- UnitPrice:单价,单位产品价格(以英镑为单位)。
- CustomerID:客户编号,一个唯一分配给每个客户的 5 位整数。
- Country:国名,每个客户所在国家/地区的名称。
数据导入
#导入包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import datetime as dt
import numpy as np
#数据读取
data=pd.read_excel('Online Retail.xlsx', parse_dates=['InvoiceDate'])
#查看数据
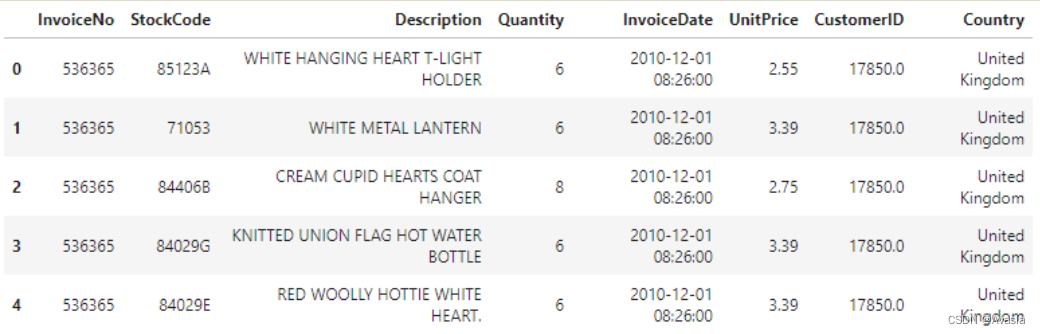
data.head()
处理异常值
# 查看数据分布
data.describe()
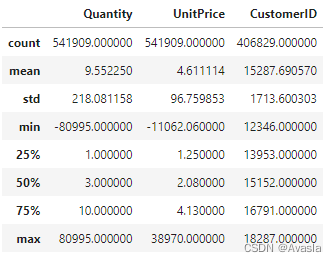
数据集中的数量Quantity和价格中包含异常的负数,应是属于取消订单,但这里先当作异常值直接删除。
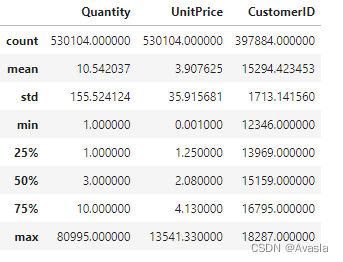
#filter
data = data[(data['Quantity']>0)&(data['UnitPrice']>0)]
data.describe()
处理缺失值
# 查看缺失情况
data.isnull().sum()
![![[Pasted image 20221221221220.png]]](https://img-blog.csdnimg.cn/1b976b2895fc4827a258219de3cf76ec.png)
用户ID有很多缺失值,这里也直接处理掉。
#删除缺失值
data=data.dropna()
#检查结果
data.isnull().sum()
计算总金额
#Calulate total purchase
data['TotalPurchase'] = data['Quantity'] * data['UnitPrice']
查看国家和客户的分布情况
#删除重复数据
filtered_data=data[['Country','CustomerID']].drop_duplicates()
#查看前十个最多客户的国家
filtered_data.Country.value_counts()[:10].plot(kind='bar')
![![[Pasted image 20221221190539.png]]](https://img-blog.csdnimg.cn/cdd44b64b2e84425983b2b3a492d57c5.png)
图上可以见,用户主要集中在UK,所以我们先分析UK的客户。
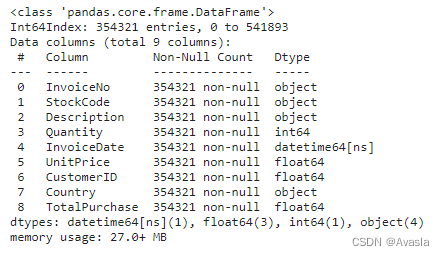
uk_data=data[data.Country=='United Kingdom']
uk_data.info()
#选取需要的数据列
uk_data=uk_data[['CustomerID','InvoiceDate','InvoiceNo','Quantity','UnitPrice','TotalPurchase']]
# 根据客户ID分组,分别计算出最近消费时间、总消费单数和总消费金额
uk_data_group=uk_data.groupby('CustomerID').agg({'InvoiceDate': lambda date: (date.max() - date.min()).days,
'InvoiceNo': lambda num: len(num),
'Quantity': lambda quant: quant.sum(),
'TotalPurchase': lambda price: price.sum()})
#重命名
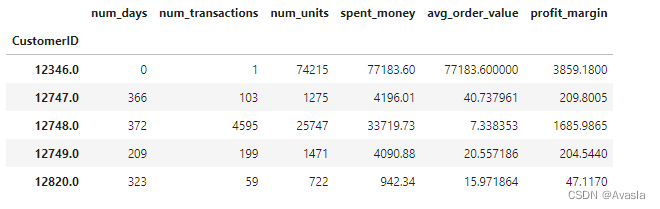
uk_data_group.columns=['num_days','num_transactions','num_units','spent_money']
#查看结果
uk_data_group.head()
![![[Pasted image 20221221221824.png]]](https://img-blog.csdnimg.cn/3e5bac24d56c4a67b63c5d3e7f380162.png)
计算CLTV
CLTV = ((Average Order Value x Purchase Frequency)/Churn Rate) x Profit margin. Customer Value = Average Order Value * Purchase Frequency
# Average Order Value
uk_data_group['avg_order_value']=uk_data_group['spent_money']/uk_data_group['num_transactions']
#purchase_frequency
purchase_frequency=sum(uk_data_group['num_transactions'])/uk_data_group.shape[0]
# Repeat Rate
repeat_rate=uk_data_group[uk_data_group.num_transactions > 1].shape[0]/uk_data_group.shape[0]
#Churn Rate
churn_rate=1-repeat_rate
利润率假设
利润率是常用的盈利比率。它代表总销售额的多少百分比作为收益获得。假设我们的业务在总销售额中有大约 5% 的利润。
uk_data_group['profit_margin']=uk_data_group['spent_money']*0.05
#查看结果
uk_data_group.head()
# Customer Value
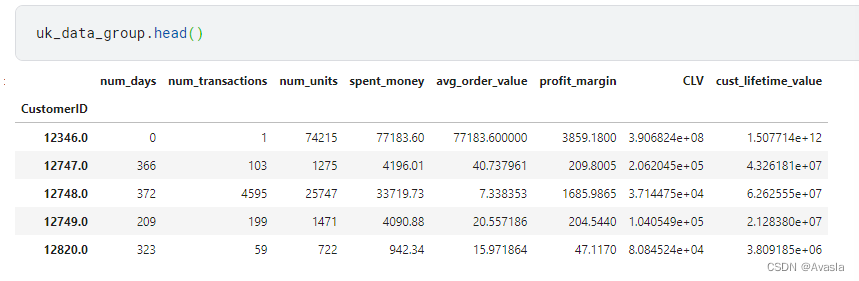
uk_data_group['CLV']=(uk_data_group['avg_order_value']*purchase_frequency)/churn_rate
# Customer Lifetime Value
uk_data_group['cust_lifetime_value']=uk_data_group['CLV']*uk_data_group['profit_margin']
CLTV预测模型
模型训练
#提取年月
uk_data['month_yr'] = uk_data['InvoiceDate'].apply(lambda x: x.strftime('%b-%Y'))
#将数据转置
sale=uk_data.pivot_table(index=['CustomerID'],columns=['month_yr'],values='TotalPurchase',aggfunc='sum',fill_value=0).reset_index()
#计算每个客户的CLV
sale['CLV']=sale.iloc[:,2:].sum(axis=1)
#查看结果
sale.head()
将原数据转换成以客户ID为行,年月为列的数据集。
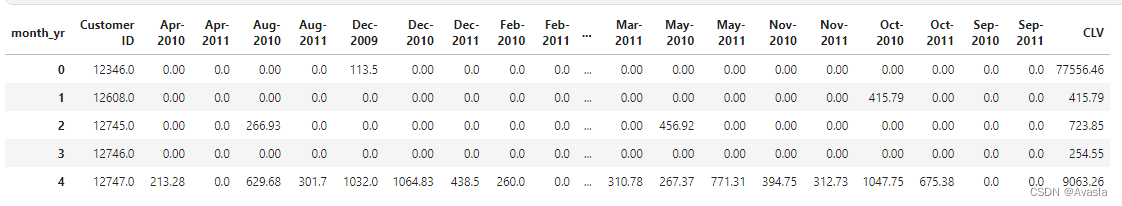
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
#取最近6个月的数据作为特征X,CLV是Y
X=sale[['Dec-2011','Nov-2011', 'Oct-2011','Sep-2011','Aug-2011','Jul-2011']]
y=sale[['CLV']]
#数据集切分
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=0)
#模型训练
linreg = LinearRegression()
linreg.fit(X_train, y_train)
#结果预测
y_pred = linreg.predict(X_test)
# 打印截距和系数
print(linreg.intercept_)
print(linreg.coef_)

模型评估
#模型评估
from sklearn import metrics
print("R-Square:",metrics.r2_score(y_test, y_pred))
print("MAE:",metrics.mean_absolute_error(y_test,y_pred))
print("MSE",metrics.mean_squared_error(y_test, y_pred))
print("RMSE:",np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
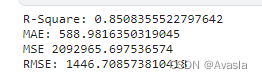
R平方介于 0-1 之间,越接近 1,回归拟合效果越好,一般认为 超过 0.8 的模型拟合优度比较高。
该模型的R平方为0.85,因此该模型的拟合效果比较高。


![[N1CTF 2018]eating_cms parse_url绕过](https://img-blog.csdnimg.cn/0d49f17c376c4762818dd8bc11c30ed9.png)