内存占用
ES的JVM heap按使用场景分为可GC部分和常驻部分。 可GC部分内存会随着GC操作而被回收; 常驻部分不会被GC,通常使用LRU策略来进行淘汰; 内存占用情况如下图:
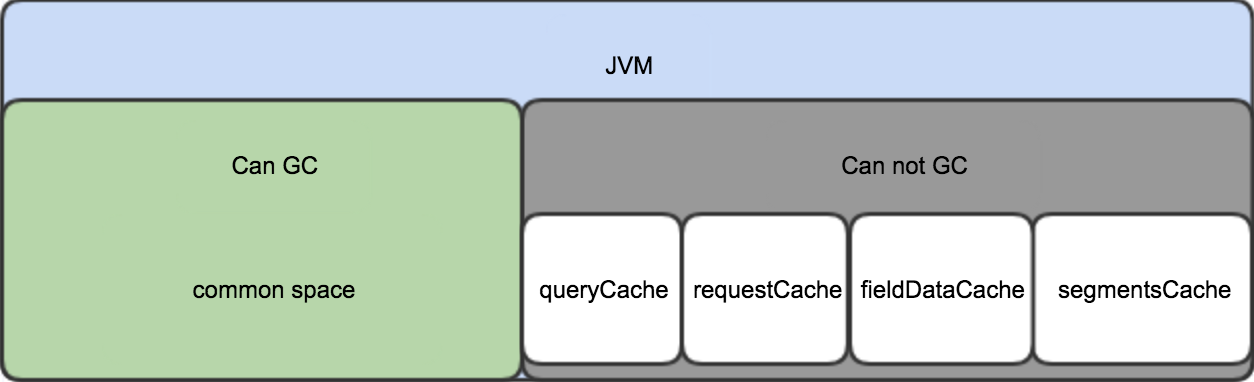
common space
包括了indexing buffer和其他ES运行需要的class。indexing buffer由indices.memory.index_buffer_size参数控制, 默认最大占用10%,当full up后,该部分数据被刷入磁盘对应的Segments中。这部分空间是可以被回收反复利用的。注意,这是设置给node的,所以是所有的索引共享的空间。
适当的提高这个的比例,可以提升写入的速度。但是要注意OOM安全的问题。要知道总的堆空间是有限的,当你在调大一个的时候,就要调小其他的大小。
Bulk Queue
一般来说,Bulk queue 不会消耗很多的 heap,但是见过一些用户为了提高 bulk 的速度,客户端设置了很大的并发量,并且将 bulk Queue 设置到不可思议的大,比如好几千。
Bulk Queue 是做什么用的?当所有的 bulk thread 都在忙,无法响应新的 bulk request 的时候,将 request 在内存里排列起来,然后慢慢清掉。
这在应对短暂的请求爆发的时候有用,但是如果集群本身索引速度一直跟不上,设置的好几千的 queue 都满了会是什么状况呢?取决于一个 bulk 的数据量大小,乘上 queue 的大小,heap 很有可能就不够用,内存溢出了。
一般来说官方默认的 thread pool 设置已经能很好的工作了,建议不要随意去「调优」相关的设置,很多时候都是适得其反的效果。
对高 cardinality 字段做 terms aggregation
所谓高 cardinality,就是该字段的唯一值比较多。
比如 client ip,可能存在上千万甚至上亿的不同值。对这种类型的字段做 terms aggregation 时,需要在内存里生成海量的分桶,内存需求会非常高。如果内部再嵌套有其他聚合,情况会更糟糕。
在做日志聚合分析时,一个典型的可以引起性能问题的场景,就是对带有参数的 url 字段做 terms aggregation。对于访问量大的网站,带有参数的 url 字段 cardinality 可能会到数亿,做一次 terms aggregation 内存开销巨大,然而对带有参数的 url 字段做聚合通常没有什么意义。
对于这类问题,可以额外索引一个 url_stem 字段,这个字段索引剥离掉参数部分的 url。可以极大降低内存消耗,提高聚合速度。
segmentsMemory
缓存段信息,包括FST,Dimensional points for numeric range filters,Deleted documents bitset ,Doc values and stored fields codec formats等数据。这部分缓存是必须的,不能进行大小设置,通常跟index息息相关,close index、force merge均会释放segmentsMemory空间。
可以通过命令可以 查看当前各块的使用情况。
GET _cat/nodes?v&h=id,ip,port,r,ramPercent,ramCurrent,heapMax,heapCurrent,fielddataMemory,queryCacheMemory,requestCacheMemory,segmentsMemory
Cluster State Buffer
ES 被设计成每个 node 都可以响应用户的 api 请求,因此每个 node 的内存里都包含有一份集群状态的拷贝。
这个 cluster state 包含诸如集群有多少个 node,多少个 index,每个 index 的 mapping 是什么?有少 shard,每个 shard 的分配情况等等 (ES 有各类 stats api 获取这类数据)。
在一个规模很大的集群,这个状态信息可能会非常大的,耗用的内存空间就不可忽视了。并且在 ES2.0 之前的版本,stat e的更新是由 master node 做完以后全量散播到其他结点的。频繁的状态更新就可以给 heap 带来很大的压力。在超大规模集群的情况下,可以考虑分集群并通过 tribe node 连接做到对用户 api 的透明,这样可以保证每个集群里的 state 信息不会膨胀得过大。
超大搜索聚合结果集的 fetch
ES 是分布式搜索引擎,搜索和聚合计算除了在各个 data node 并行计算以外,还需要将结果返回给汇总节点进行汇总和排序后再返回。
无论是搜索,还是聚合,如果返回结果的 size 设置过大,都会给 heap 造成很大的压力,特别是数据汇聚节点。超大的 size 多数情况下都是用户用例不对,比如本来是想计算 cardinality,却用了 terms aggregation + size:0 这样的方式; 对大结果集做深度分页;一次性拉取全量数据等等。
NodeQueryCache**
它是node级别的filter过滤器结果缓存,大小由indices.queries.cache.size 参数控制,默认10%,我们也可设定固定的值例如:512mb。使用LRU淘汰策略。注意不会被GC,只会被LRU替换。index.queries.cache.enabled该参数可以决定是否开启节点的query cache,默认为开启。 只能在创建索引或者关闭索引(close)时设置 。
-
只有Filter下的子Query才能参与Cache
-
不能参与Cache的Query有TermQuery/MatchAllDocsQuery/MatchNoDocsQuery/BooleanQuery/DisjunnctionMaxQuery
-
MultiTermQuery/MultiTermQueryConstantScoreWrapper/TermInSetQuery/Point*Query的Query查询超过 2次 会被Cache,其它Query要 5次
默认每个段 大于10000个doc 或 每个段的doc数大于总doc数的 30% 时才允许参与cache
默认情况下,节点查询缓存最多可容纳 10000个查询,最多占总堆空间的 10%
为了确定查询是否符合缓存条件,Elasticsearch 维护查询历史记录以跟踪事件的发生。
如果一个段至少包含 10000 个文档,并且该段具有超过一个分片的文档总数的 3% 的文档数,则按每个段进行缓存。由于缓存是按段划分的,因此合并段可使缓存的查询无效。
ShardRequestCache
它是shard级别的query result缓存, 默认的主要用于缓存 size=0 的请求,aggs和 suggestions,还有就是hits.total 。使用LRU淘汰策略。通过indices.requests.cache.size参数控制,默认1%。设置后整个NODE都生效。
fieldDataCache
主要用于对text类型的字段 sort 以及 aggs 的字段。这会把字段的值加载到内存中,以便于快速访问。field data cache 的构建非常昂贵,因此最好能分配足够的内存以保障它能长时间处于被加载的状态。 indices.fielddata.cache.size 该参数可以设置大小,可以设置堆的百分比,例如10%,也可以固定大小5G。注意这个参数 需要在:elasticsearch.yml 中设置,重启后生效 。
当字段在首次sort,aggregations,or in a script时创建,读取磁盘上所有segment的的倒排索引,反转 term<->doc 的关系,加载到jvm heap,it remains there for the lifetime of the segment.
ES2.0以后,正式默认启用 Doc Values 特性(1.x 需要手动更改 mapping 开启),将 field data 在 indexing time 构建在磁盘上,经过一系列优化,可以达到比之前采用 field data cache 机制更好的性能。因此需要限制对 field data cache 的使用,最好是完全不用,可以极大释放 heap 压力。es默认是不开启的。
fieldDataCache最好不要用,它很可能会导致OOM:Es官方文档整理-3.Doc Values和FieldData - 搜索技术 - 博客园
| 类目 | 默认占比 | 是否常驻 | 淘汰策略(在控制大小情况下) | 控制参数 |
|---|---|---|---|---|
| query cache | 10% | 是 | LRU | indices.queries.cache.size |
| request cache | 1% | 是 | LRU | indices.requests.cache.size |
| fielddata cache | 无限制(es默认禁用)熔断器,帮我们限制了即使使用,也不能超过堆内存的百分之四十。 | 是 | LRU | indices.fielddata.cache.size |
| segment memory | 无限制(我们需要对此建立监控) | 是 | 无 | 不能通过参数控制 |
| common space | 70% | 否 | GC | 通过熔断器 indices.breaker.total.limit 限制 |
对我们的堆内存建立起来完整的监控,避免OOM问题
-
倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
-
各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
-
避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
-
cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
-
想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
-
根据监控数据理解内存需求,合理配置各类circuit breaker,将内存溢出风险降低到最低。
elasticsearch内存占用详细分析_水的精神-华为云开发者联盟