自学Python可以找到工作吗?自学Python找工作主要看自己的学习能力,自学能力很强学完并精通当然可以工作,不过对于大多数人而言一般都挺难,学习不成系统,遇到问题没人解决很容易放弃半途而废。
学Python能干很多很多事,做日常任务,如自动备份MP3;可做网站,很多著名的网站是Python写的;做网络游戏的后台,很多在线游戏的后台都是Python开发的。如果你自学到可以轻松开发编写这些项目那么找工作也没有问题的。
自学Python达到什么水平可以找工作?大部分Python相关岗位任职要求 :
1、有爬虫工作经验并有高并发大量采集项目经验;
2、熟练Python编程语言,掌握反爬技术,图片识别码,滑动块识验码等技术;
3、熟悉Scrapy、Django、Flask等框架;
4、熟悉关系型数据库(MySQL/PostgreSQL/Oracle),缓存数据库(Redis/Memcached);
5、精通一种开源爬虫框架,如scrapy等,有开发爬虫框架、构建过分布式爬虫系统者优先;
6、熟练使用Python编程语言进行后台开发;
7、熟练掌握Web开发框架与技术,如Django, Flask, Node.js等;
8、熟悉HTTP协议;
9、熟悉数据结构、数据库以及其他编程基础;
10、了解DevOps,有源代码控制、CI/CD经验;
11、具备MySQL等数据相关库或组件知识经验;
自学Python可能花费的时间较长,如果是零基础自学很容易中途放弃,如果有一定的编程基础那么自学Python效果比较号,掌握了相关Python技能不愁找不到薪资待遇满意的工作。
自学Python知识基础入门比较快,达到精通程序需要不断通过实践练习。精通Python编程语言要通过大量的实践来积累经验,解决遇到的各种疑难问题,分析别人的源码,分享自己分码的这个过程,通过实践精通Python的方方面面。从编程开始不断的动手去编写代码,去实践去修改不断总结经验,熟能生巧达到精通的水平。具体相应的Python岗位要求才能找到合适的工作。
Python近段时间一直涨势迅猛,在各大编程排行榜中崭露头角,得益于它多功能性和简单易上手的特性,让它可以在很多不同的工作中发挥重大作用。
正因如此,目前几乎所有大中型互联网企业都在使用 Python 完成各种各样的工作,比如Web应用开发、自动化运维、人工智能领域、网路爬虫、科学计算、游戏开发等领域均已离不开Python。
特别是在和数据相关的领域,比如数据科学、数据分析、机器学习等领域的首选语言都是Python!
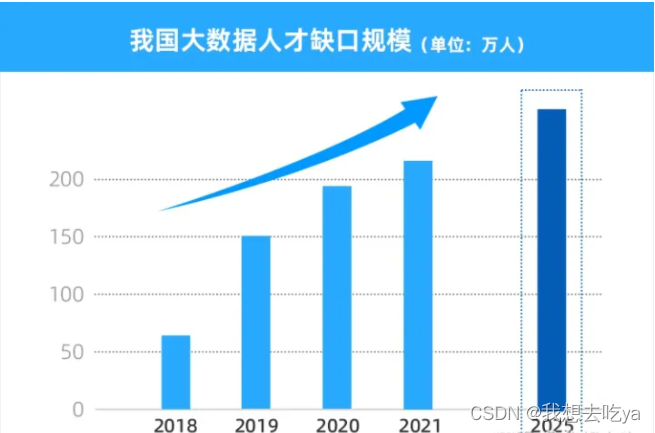
我们可以看到,随着数字经济发展按下“快进键”,擅长Python的大数据人才越来越受企业青睐,不仅招聘需求量大,就业薪资也非常高!
据《新职业——大数据工程技术人员就业景气现状分析报告》显示,预计2025年前大数据人才需求仍保持 30%-40% 的增速,行业人才需求量达到 250 万 。
1、什么是大数据?
关于大数据的解释,比较官方的定义是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。简单来说,大数据就是结构化的传统数据再加上非结构化的新数据。那么传统数据和新数据又是什么呢?传统数据就是IT业务系统里面的数据,如客户资料、财务数据等。这些数据是结构化的,量也不是特别大,一般只是TB级。对比传统数据,还有一种叫“新数据”,是来源于社区网络、互联网等渠道,包括文本、图片、音频、视频等非结构化的数据。目前全世界75%以上都是非结构化数据,而且还一直呈现爆炸性的增长。
2、大数据有哪些特点?
(1)容量大
数据体量大,数据的大小决定所考虑的数据的价值的和潜在的信息。
(2)种类多样
数据类型的多样性,包括传统数据库、图像、文件和其他复杂的记录,如果只有单一的数据,那么这些数据就没有了价值,比如只有单一的个人数据,或者单一的用户提交数据,这些数据还不能称为大数据,所以说大数据还需要是多样性的,比如当前的上网用户中,年龄,学历,爱好,性格等等每个人的特征都不一样,这个也就是大数据的多样性。
(3)快速
数据的速度,就是通过算法对数据的逻辑处理速度非常快,1秒定律,可从各种类型的数据中快速获得高价值的信息,这一点也是和传统的数据挖掘技术有着本质的不同。
(4)价值大
你如果有1PB以上的全国所有20-35年轻人的上网数据的时候,那么它自然就有了商业价值,比如通过分析这些数据,我们就知道这些人的爱好,进而指导产品的发展方向等等。如果有了全国几百万病人的数据,根据这些数据进行分析就能预测疾病的发生,这些都是大数据的价值。
4、大数据的应用场景
(1)金融:大数据在高频交易、社交情绪分析和信贷风险分析三大金融创新领域发挥重大作用。
(2)城市管理:可以利用大数据实现智能交通、环保监测、城市规划和智能安防。
(3)医疗:在发现诊断疾病时,疾病的确诊和治疗方案的确定是最困难的。而借助于大数据平台我们可以收集不同病例和治疗方案,以及病人的基本特征,可以建立针对疾病特点的数据库。
(4)零售:零售行业可以了通过大数据技术,了解客户消费喜好和趋势,进行商品的精准营销,降低营销成本。另外,还能依据客户购买产品,为客户提供可能购买的其它产品,扩大销售额。
(5)气象:借助于大数据技术,天气预报的准确性和实效性将会大大提高,预报的及时性将会大大提升,同时对于重大自然灾害,例如龙卷风,通过大数据计算平台,人们将会更加精确地了解其运动轨迹和危害的等级,有利于帮助人们提高应对自然灾害的能力。
Python语言简单易懂,适合零基础入门,在编程语言排名上升最快,能完成数据挖掘、机器学习、实时计算在内的各种大数据集成任务。
根据国内的发展形势,大数据未来的发展前景会非常好。自 2018 年企业纷纷开始数字化转型,一二线城市对大数据领域的人才需求非常强烈,未来几年,三四线城市的人才需求也会大增。
在大数据领域,国内发展的比较晚,从 2016 年开始,仅有 200 多所大学开设了大数据相关的专业,也就是说 2020 年第一批毕业生才刚刚步入社会,我国市场环境处于急需大数据人才但人才不足的阶段,所以未来大数据领域会有很多的就业机遇。
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台