🐌个人主页: 🐌 叶落闲庭
💨我的专栏:💨
c语言
数据结构
javaEE
操作系统
Redis
石可破也,而不可夺坚;丹可磨也,而不可夺赤。
HashSet
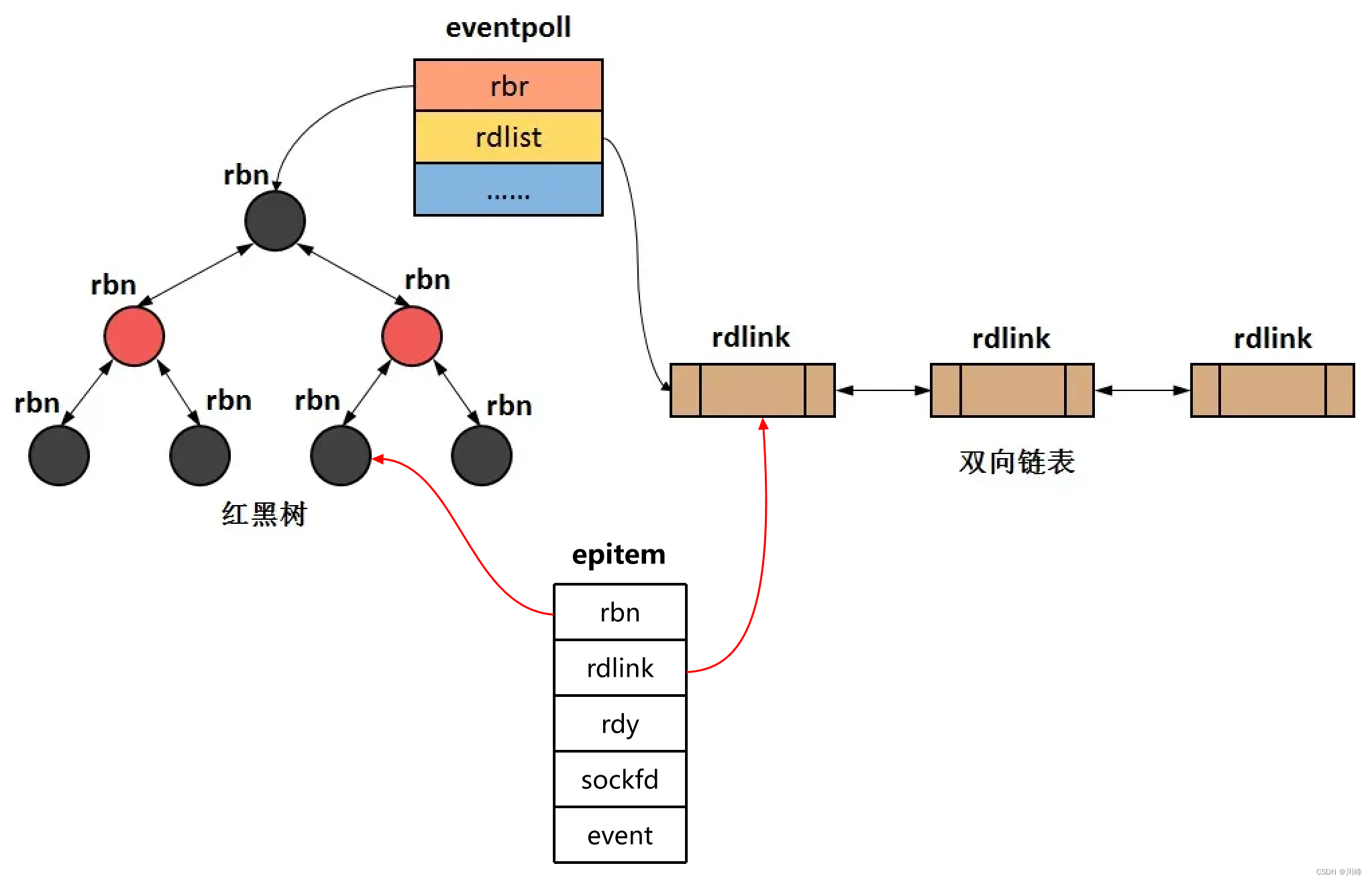
- 一、 HashSet 集合的底层数据结构
- 二、 HashSet 添加元素的过程
- 三、 HashSet 为什么存和取的顺序不一样
- 四、 HashSet 为什么没有索引
- 五、 HashSet 的去重机制
- Set 系列集合
-
- 无序:存取顺序不一致
-
- 不重复:可以去除重复
-
- 无索引:没有带索引的方法,所以不能使用普通fo循环遍历,也不能通过索引来获取元素
一、 HashSet 集合的底层数据结构
- HashSet :无序、不重复、无索引
- HashSet 底层是采用哈希表存储数据的,哈希表是一种对于增删改查数据性能都较好的结构
- 哈希表在JDK8之前是由数组+链表组成的,在JDK8之后是由数组+链表+红黑树组成的
- 在哈希表中,最重要的是哈希值,哈希值就是对象的整数表现形式,HashSet 在存数据的时候,会根据数组长度和哈希值计算出要存入的位置,哈希值是根据hashCode()方法计算出来的int型的整数,hashCode()方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算,一般情况下,自定义的对象都要重写hashCode()方法,利用对象内部的属性值计算哈希值。
int index = (数组长度 - 1) & 哈希值;
- 对象的哈希值特点:
-
- 如果没有重写hashCode()方法,同一个类创建的不同对象计算出的哈希值是不同的
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
public static void main(String[] args) {
//创建对象
//没有重写hashCode方法,计算出的哈希值是不同的
Student s1 = new Student();
Student s2 = new Student();
System.out.println(s1.hashCode());//460141958
System.out.println(s2.hashCode());//1163157884
}
- 如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
public class Student {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
public static void main(String[] args) {
//创建对象
//如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
Student s1 = new Student();
Student s2 = new Student();
System.out.println(s1.hashCode());//961
System.out.println(s2.hashCode());//961
}
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
public static void main(String[] args) {
//在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
System.out.println("abc".hashCode());//96354
System.out.println("acD".hashCode());//96354
}
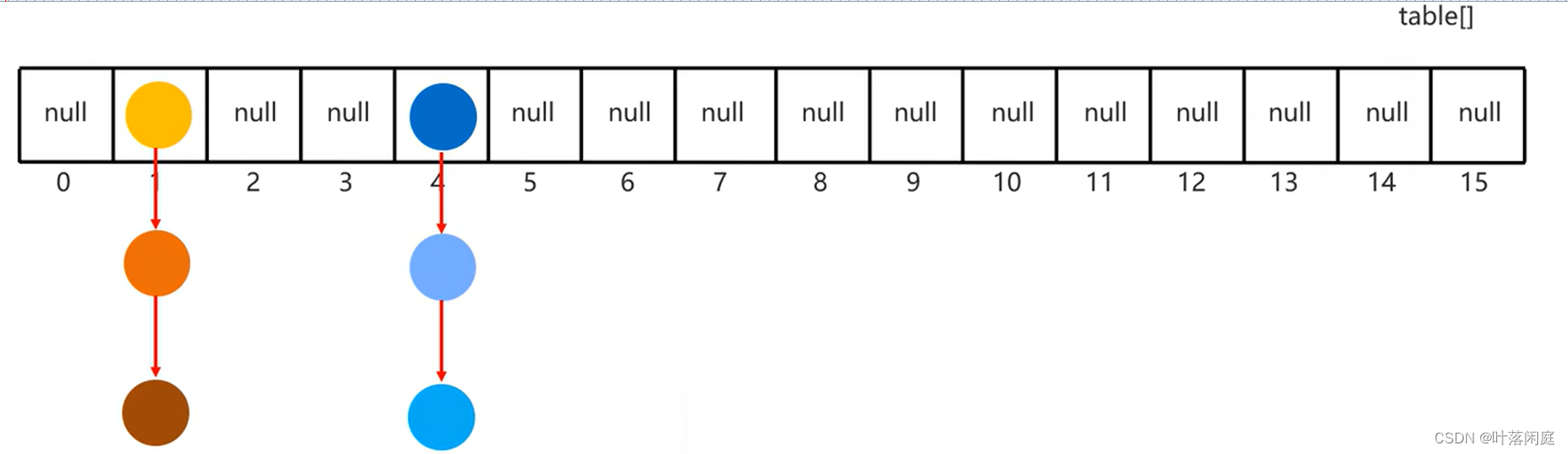
二、 HashSet 添加元素的过程
HashSet在JDK8以后的底层原理:
- 创建一个默认长度为16,默认加载因子为0.75的数组,数组名为table
- 根据元素的哈希值跟数组长度计算处应存入的位置
int index = (数组长度 - 1) & 哈希值;
- 判断当前位置是否为null,如果是null,则直接存入
- 如果当前位置不是null,表示有元素,则调用equals()方法与当前位置的属性进行比较
-
- 如果相同,则舍弃不存
-
- 如果不同,则存入数组,形成链表
- JDK8以前,新元素存入数组,老元素挂在新元素下面形成链表
- JDK8之后,新元素挂在老元素下面形成链表
- 当链表长度大于8且数组长度大于等于64时,当前链表会自动转成红黑树
- 如果集合中存储的是自定义对象,必须重写 hashCode 和 equals 方法
三、 HashSet 为什么存和取的顺序不一样
HashSet 在遍历的时候是从数组的0索引开始遍历的,每个索引下都要遍历该索引下对应的链表,当遍历到一个索引,这个索引的值为空时,会跳过,遍历下一个索引,该索引下对应有链表时,就会遍历这个链表,若是红黑树,也会遍历这个红黑树,按这个原则遍历数组,因为某个索引下对应的元素不一定就是存入时的顺序,所以HashSet 在存和取时的顺序也不一定相同。
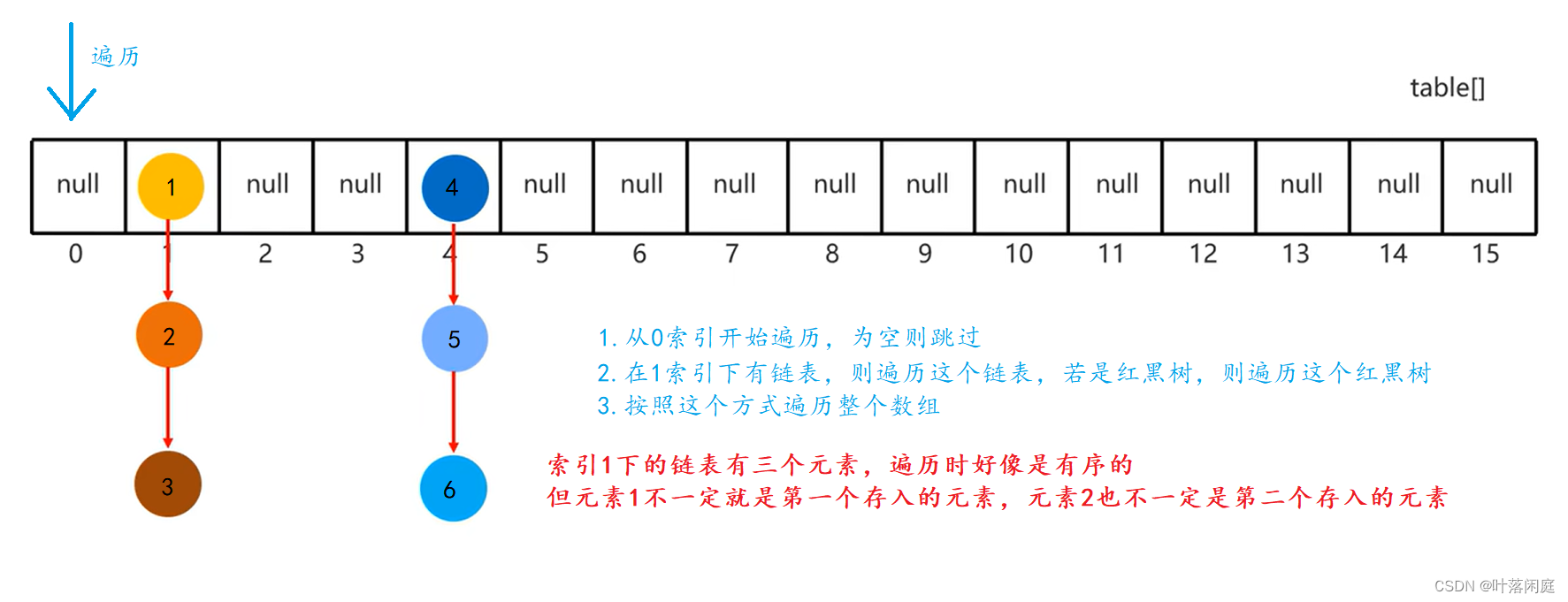
四、 HashSet 为什么没有索引
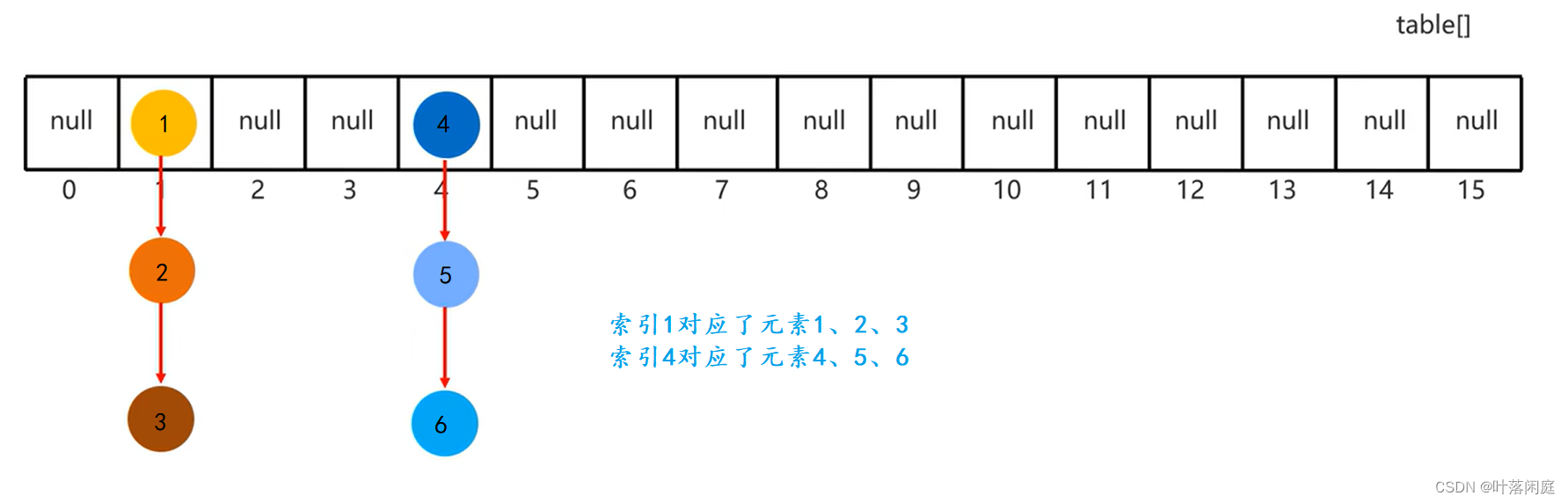
HashSet 是由数组+链表+红黑树组成的,数组是有索引的,但是存在HashSet 中的元素是通过链表或红黑树的形式挂在数组的每个索引下的,也就是每个索引可能对应多个元素,所以HashSet 不能由索引找到对应的元素。
五、 HashSet 的去重机制
HashSet 是通过HashCode计算出每个元素应该存放的位置,,然后通过equals方法去比较对象内部的属性值是否一致,保证不会出现重复的元素。