嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
如何使用thefuzz 库,它允许我们在python中进行模糊字符串匹配。
此外,我们将学习如何使用process 模块,该模块允许我们在模糊字符串逻辑的帮助下有效地匹配或提取字符串。
使用thefuzz 模块来匹配模糊字符串
这个库在旧版本中有一个有趣的名字,因为它有一个特定的名字,这个名字被重新命名。
所以现在是由不同的库来维护;但是,它目前的版本叫做thefuzz ,所以这就是你可以通过下面的命令来安装的。
pip install thefuzz
但是,如果你在网上看例子,你会发现一些例子的旧名称是fuzzywuzzy 。所以,它已经不再被维护并且过时了,但是你可能会发现一些用这个名字的例子。
thefuzz 库是基于 ,所以你必须用这个命令来安装它。python-Levenshtei
pip install python-Levenshtein
而如果你在安装过程中遇到一些问题,你可以使用下面的命令,如果再次遇到错误,那么你可以在google上搜索,找到相关的解决方案。
pip install python-Levenshtein-wheels
本质上,模糊匹配字符串就像使用regex或沿着两个字符串的比较。
在模糊逻辑的情况下,你的条件的真值可以是0 和1 之间的任何实数。
因此,基本上,不是说任何东西是True 或False ,你只是给它在0 到1 之间的任何值。
它是通过使用距离度量计算两个字符串之间的不相似性,其形式是一个称为距离的值。
使用给定的字符串,你使用一些算法找到两个字符串之间的距离。一旦你完成了安装过程,你必须从thefuzz 模块中导入fuzz 和process 。
from thefuzz import fuzz, process
在使用fuzz ,我们将手动检查两个字符串之间的不相似性。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
ST1='Just a test'
ST2='just a test'
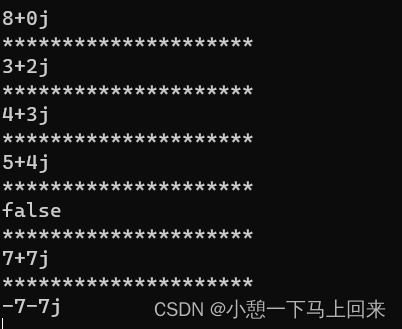
print(ST1==ST2)
print(ST1!=ST2)
它将返回一个布尔值,但以一种模糊的方式,你会得到这些字符串的相似程度的百分数。
False
True
模糊字符串匹配允许我们以模糊的方式更有效、更快速地完成这项工作。假设我们有一个例子,有两个字符串,其中一个字符串与大写的J (如上所述)不相同。
如果我们现在去调用ratio() 函数,它给我们一个相似性的度量,那么这将为我们提供一个相当高的比率,即91 ,而不是100 。
from thefuzz import fuzz, process
print(fuzz.ratio(ST1, ST2))
输出:
91
如果字符串更加延长,例如,如果我们不只是改变一个字符,而是改变一个完全不同的字符串,那么看看它的回报,看一看。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
ST1='This is a test string for test'
ST2='There aresome test string for testing'
print(fuzz.ratio(ST1,ST2))
现在可能会有一些相似之处,但会很75 ;这只是一个简单的比率,并不复杂。
75
我们还可以继续尝试像部分比例这样的东西。例如,我们有两个字符串,我们想确定它们的分数。
ST1='There are test'
ST2='There are test string for testing'
print(fuzz.partial_ratio(ST1,ST2))
使用partial_ratio() ,我们会得到100%,因为这两个字符串有相同的子字符串(There are test)。
在ST2 ,我们有一些不同的词(字符串),但这并不重要,因为我们看的是部分比率或个别部分,但简单的比率并不类似。
100
假设我们有相似的字符串,但有不同的顺序;然后,我们使用另一个度量。
CASE_1='This generation rules the nation'
CASE_2='Rules the nation This generation'
两种情况下,在该短语的相同含义上有完全相同的文字,但使用ratio() ,就会有相当大的不同,而使用partial_ratio() ,就会有不同。
如果我们通过token_sort_ratio() ,这将是100%,因为它基本上是完全相同的文字,但顺序不同。
因此,这就是token_sort_ratio() ,该函数将单个标记进行排序,它们的顺序并不重要。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
print(fuzz.ratio(CASE_1,CASE_2))
print(fuzz.partial_ratio(CASE_1,CASE_2))
print(fuzz.token_sort_ratio(CASE_1,CASE_2))
输出:
47
64
100
现在,如果我们用另一个词来改变一些词,我们会有一个不同的数字,但基本上,这是一个比率;
它不关心个别标记的顺序。
CASE_1='This generation rules the nation'
CASE_2='Rules the nation has This generation'
print(fuzz.ratio(CASE_1,CASE_2))
print(fuzz.partial_ratio(CASE_1,CASE_2))
print(fuzz.token_sort_ratio(CASE_1,CASE_2))
输出:
44
64
94
token_sort_ratio() 也是不同的,因为它有更多的词在里面,但我们也有一个叫做token_set_ratio() 的东西,一个集合包含每个标记只有一次。
所以,它出现的频率并不重要;让我们看看一个例子字符串。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
CASE_1='This generation'
CASE_2='This This generation generation generation generation'
print(fuzz.ratio(CASE_1,CASE_2))
print(fuzz.partial_ratio(CASE_1,CASE_2))
print(fuzz.token_sort_ratio(CASE_1,CASE_2))
print(fuzz.token_set_ratio(CASE_1,CASE_2))
我们可以看到一些相当低的分数,但是我们使用token_set_ratio() 函数得到了100%的分数,因为我们有两个令牌,This 和generation 存在于两个字符串中。
使用process 模块,以高效的方式使用模糊字符串匹配
不仅有fuzz ,还有process ,因为process 是有帮助的,可以使用这种模糊匹配从一个集合中提取出来。
例如,我们准备了几个列表项来演示。
Diff_items=['programing language','Native language','React language',
'People stuff', 'This generation', 'Coding and stuff']
其中一些是非常相似的,你可以看到(母语或编程语言),现在我们可以去挑选最好的个别匹配。
我们可以手动操作,只需评估分数,然后挑选出最优秀的人选,但我们也可以用process 。
要做到这一点,我们必须调用process 模块中的extract() 函数。
它需要几个参数,第一个是目标字符串,第二个是你要提取的集合,第三个是限制,将匹配或提取的内容限制为两个。
例如,如果我们想提取像language ,在这种情况下,选择母语和编程语言。
print(process.extract('language',Diff_items,limit=2))
输出:
[('programing language', 90), ('Native language', 90)]
问题是:
-
这不是NLP(自然语言处理);
-
这背后没有智能;
-
它只是看单个标记。
因此,举例来说,如果我们使用programming 作为目标字符串并运行这个。
第一个匹配将是programming language ,但第二个匹配将是Native language ,这将不是编码。
即使我们有编码,因为从语义上讲,编码更接近于编程,但这并不重要,因为我们在这里没有使用AI。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
Diff_items=['programing language','Native language','React language',
'People stuff', 'Hello World', 'Coding and stuff']
print(process.extract('programing',Diff_items,limit=2))
输出:
[('programing language', 90), ('Native language', 36)]
另一个最后的例子是这是如何有用的;
我们有一个庞大的书库,想找到一本书,但我们不知道确切的名字或如何调用它。
在这种情况下,我们可以使用extract() ,在这个函数里面,我们将把fuzz.token_sort_ratio 传给scorer 参数。
LISt_OF_Books=['The python everyone volume 1 - Beginner',
'The python everyone volume 2 - Machine Learning',
'The python everyone volume 3 - Data Science',
'The python everyone volume 4 - Finance',
'The python everyone volume 5 - Neural Network',
'The python everyone volume 6 - Computer Vision',
'Different Data Science book',
'Java everyone beginner book',
'python everyone Algorithms and Data Structure']
print(process.extract('python Data Science',LISt_OF_Books,limit=3,scorer=fuzz.token_sort_ratio))
我们只是传递它,我们并没有调用它,现在,我们在这里得到了最高的结果,我们得到了另一本数据科学书作为第二个结果。
输出:
[('The python everyone volume 3 - Data Science', 63), ('Different Data Science book', 61), ('python everyone Algorithms and Data Structure', 47)]
这就是如何是相当准确的,如果你有一个项目,你必须以模糊的方式找到它,它可以相当有帮助。
我们也可以用它来实现你的程序自动化。
还有一些额外的资源,你可以使用github和stackoverflow找到更多帮助。
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。