萌新的Risc-V学习之再看读不懂的流水线设计-10
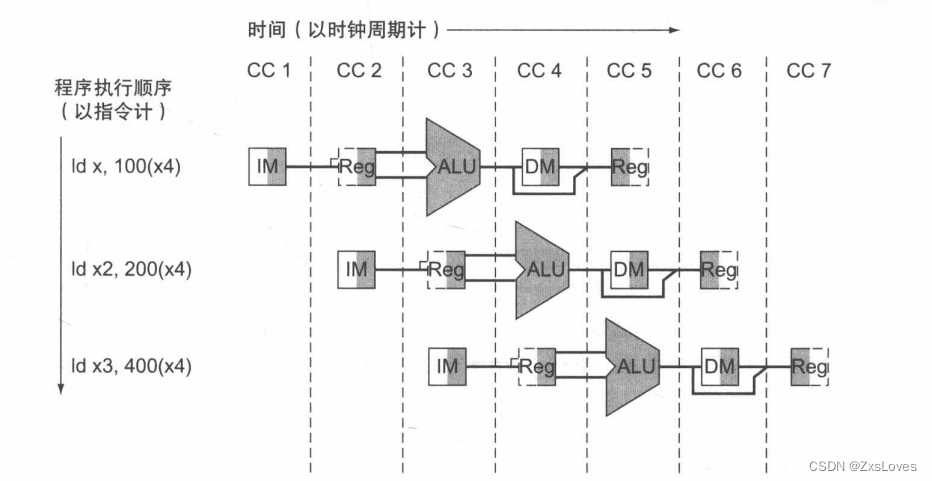
我们将流水线和之前案例中洗衣服的例子进行对照
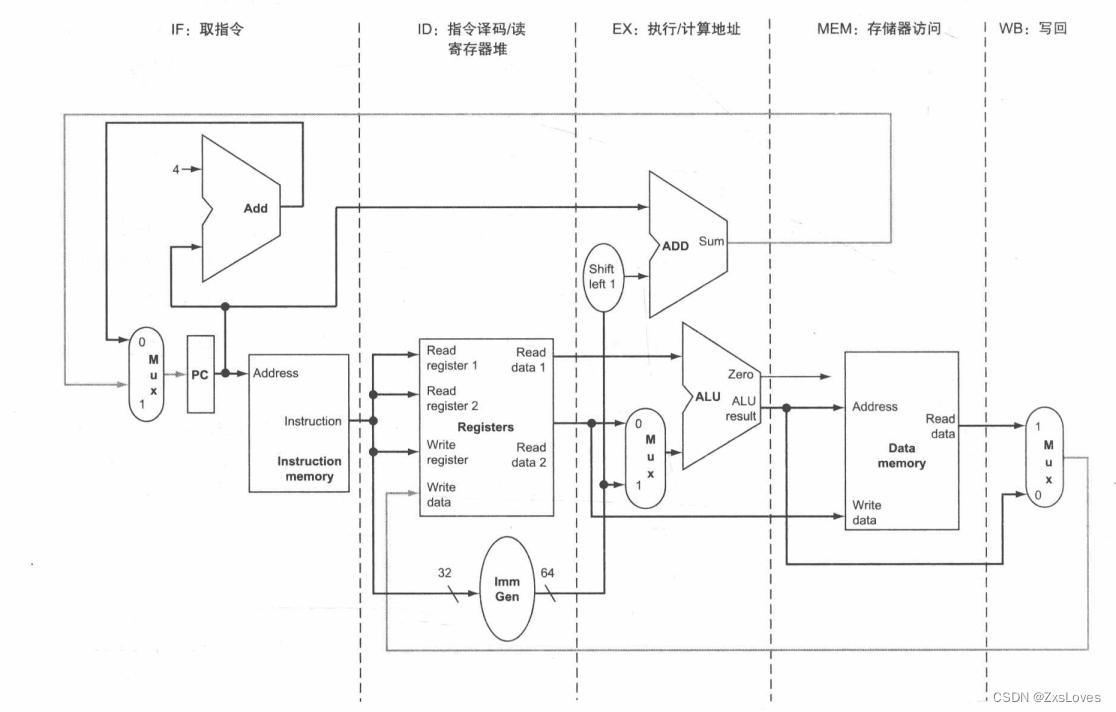
我们把整个流水线分为5个阶段
也就是做成五级流水线
- IF: 取指令
- ID: 指令译码和读寄存器堆
- EX: 执行或计算地址
- MEM: 数据存储器访问
- WB: 写回
我先在这里表述一下基本的几个指令的用法
一
add x1 x2 x3
R型指令
R[rd] = R[rn] +R [rm]
1.取出指令, PC 自增。
2.从寄存器堆读出两个寄存器 x2 x3, 同时主控制单元在此步骤计算控制信号。
3.根据部分操作码确定 ALU 的功能,对从寄存器堆读出的数据进行操作。
4.将 ALU 的结果写入寄存器堆中的目标寄存器 (x1)
二
现在介绍一下ld 的用法
R[rt] = M [ R[rn] + DATAaddr ]
ld x1 , offset(x2)
1.从指令存储器中取出指令, PC 自增。
2.从寄存器堆读出寄存器 (x2) 的值。
3.ALU 将从寄存器堆中读出的值和符号扩展后的指令中的 12 位(偏移量)相加。
4.将 ALU 的结果用作数据存储器的地址。
5.将从存储器读出的数据写入寄存器堆 (X 1)
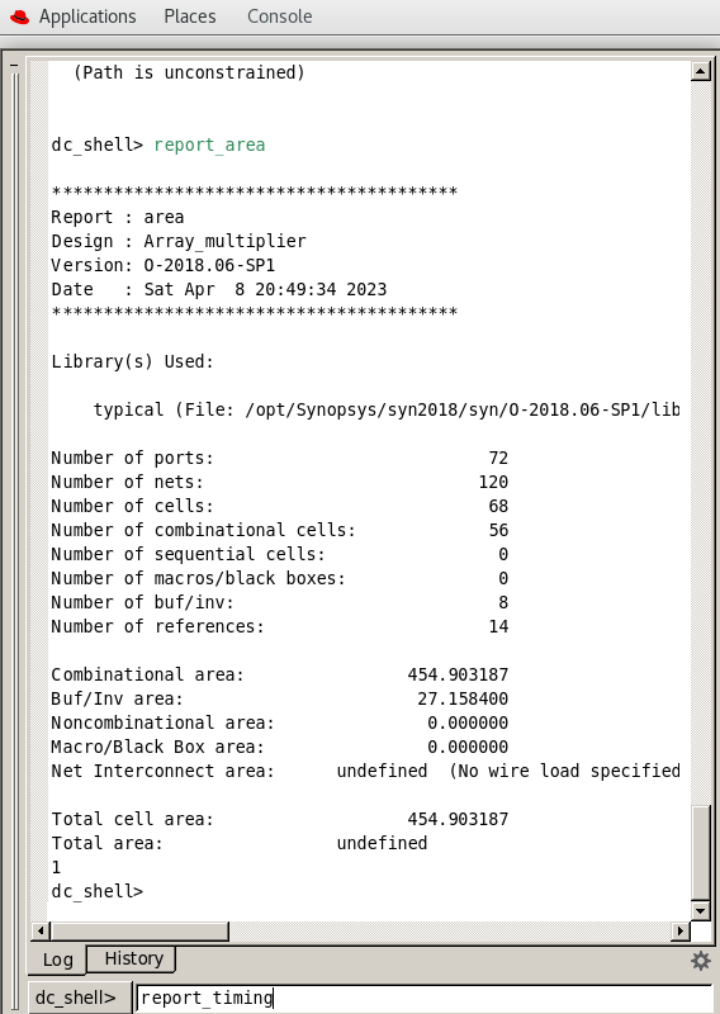
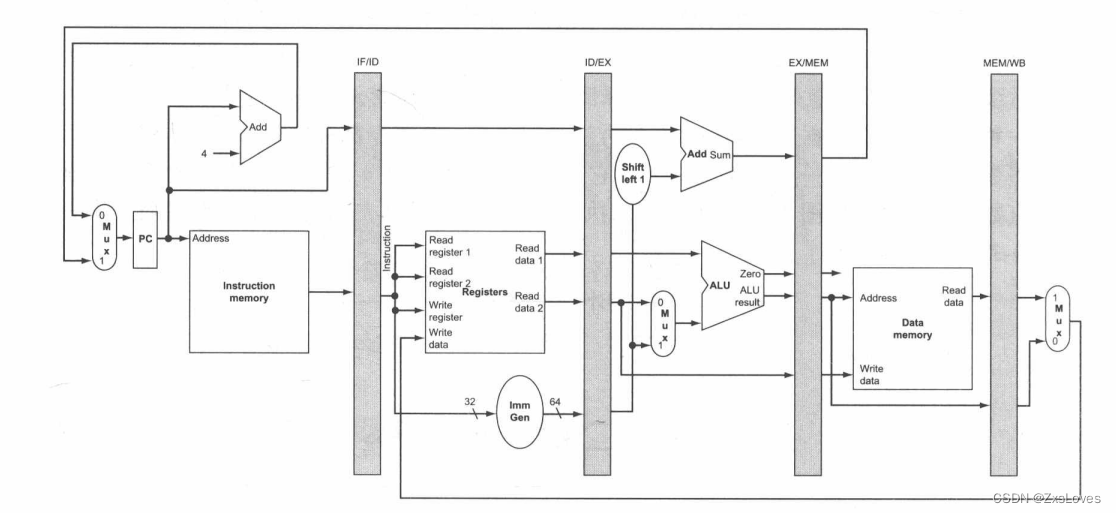
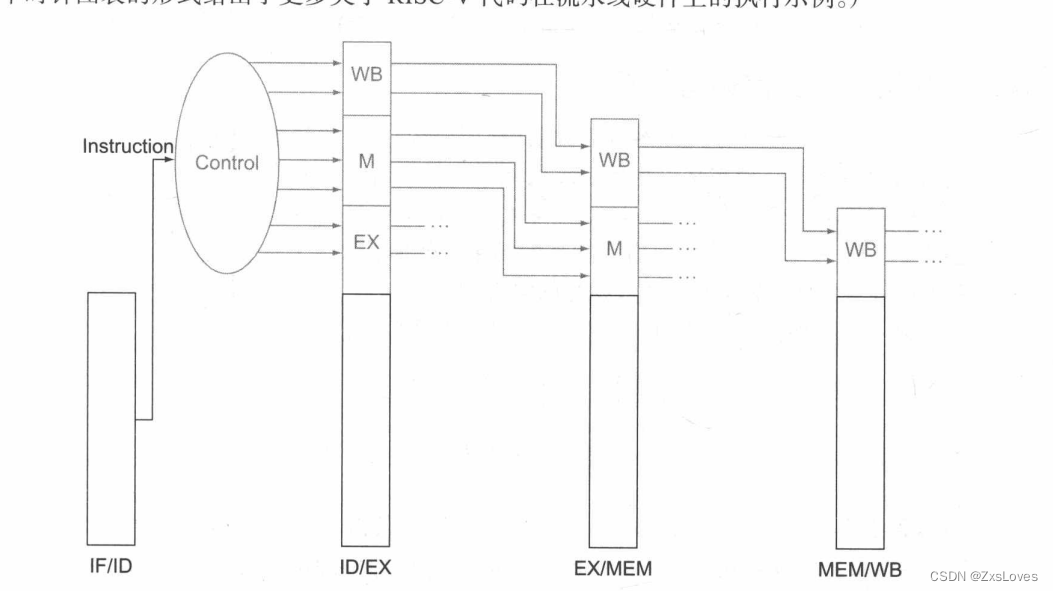
《计算机组成原理》对流水线的刻画来说会有以下安排
IM 表示指令寄存器和取值阶段的 PC, Reg表示指令译码/寄存器读取阶段 (ID) 的寄存器堆和符号扩展单元,等等。为了保持正确的时序,这种形式化的数据通路将寄存器堆划分成两个逻辑部分:寄存器读取阶段 (ID) 的寄存器读和写回 (WB) 阶段的寄存器写。这种复用被表示为:在 ID 阶段,当寄存器堆没有被写入时,使用虚线绘制未被着色的寄存器堆的左半部分;在 WB 阶段,当寄存器堆没有被读取时,使用虚线绘制未被着色的寄存器堆的右半部分。与前文一致,我们假设寄存器堆是在时钟周期的前半部分写入的,在时钟周期的后半部分被读取
总是来说 前半部分是写 后半部分是读取
我们一步步来分析 既然想要对功能进行复用 那么一定要把数据进行适当的存储 我们需要在两项之间增加一个寄存器把数据存储下来
寄存器的名称由两个被该寄存器分开的阶段的名称来命名。例如, IF ID 阶段之间的流水线寄存器被命名为 IF/ID
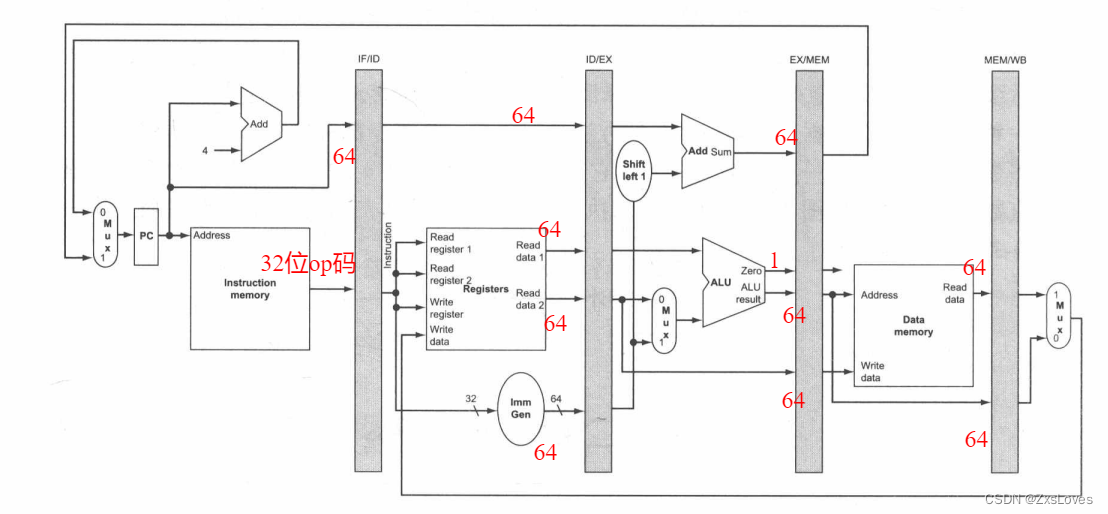
IF/ID 寄存器的位宽必须为 96 位,因为它需要同时存储从存储器中提取出的 32 位指令以及自增的 64 PC 地址。我们将在本章中逐渐增加这些寄存器的位宽,不过目前,其他三个流水线寄存器的位宽分别为 256 位、193 位和 128位
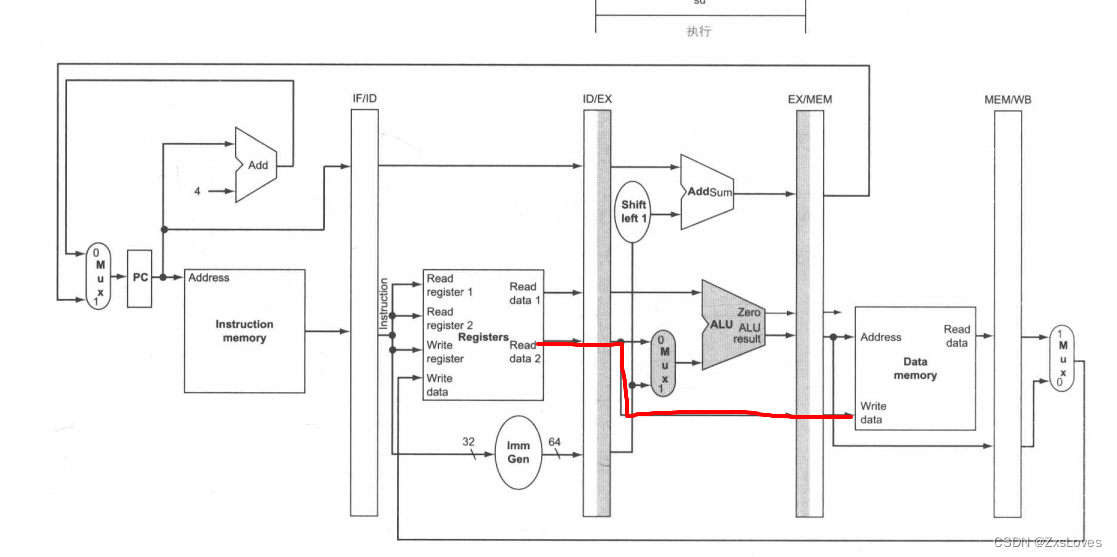
其他都还好说 这里有一段 对STUR的 研究
EX: 存储指令在流水线中的第三个阶段。不同千图 4-35 中加载指令的第三个流水阶段,第二个寄存器中的值被加载到 EX/MEM 流水线寄存器中以用千下一个阶段。尽管总是将第二个寄存器中的值写入 EX/MEM 流水线寄存器中不会造成任何影响,但为了使流水线更容易被理解,我们仅在存储指令中写第二个寄存器中的值
这里说的是 M [ R[Rn] + DTAaddr ] = R [ Rt ]
这个意思说的是 我们先读取到的Rt 的内容 然后 存放在 ID/EX 接下来 存下来 会继续存到 EX/MEM中去
大概都理解了 让我们去看一下最后总结一下
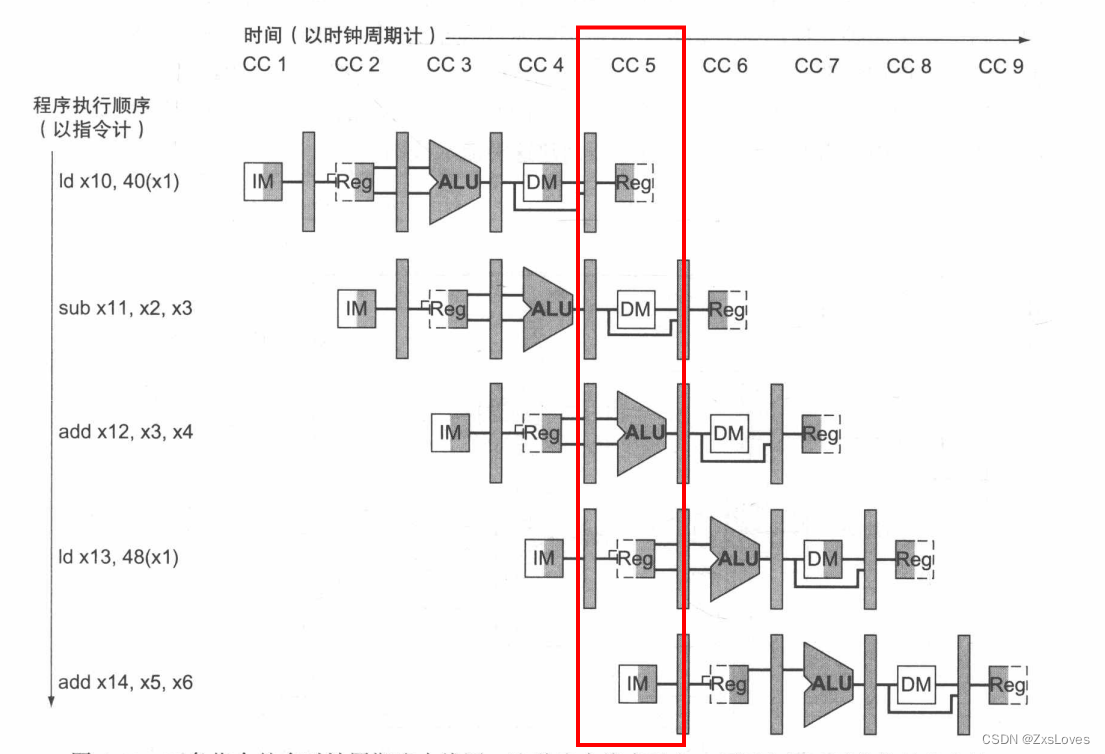
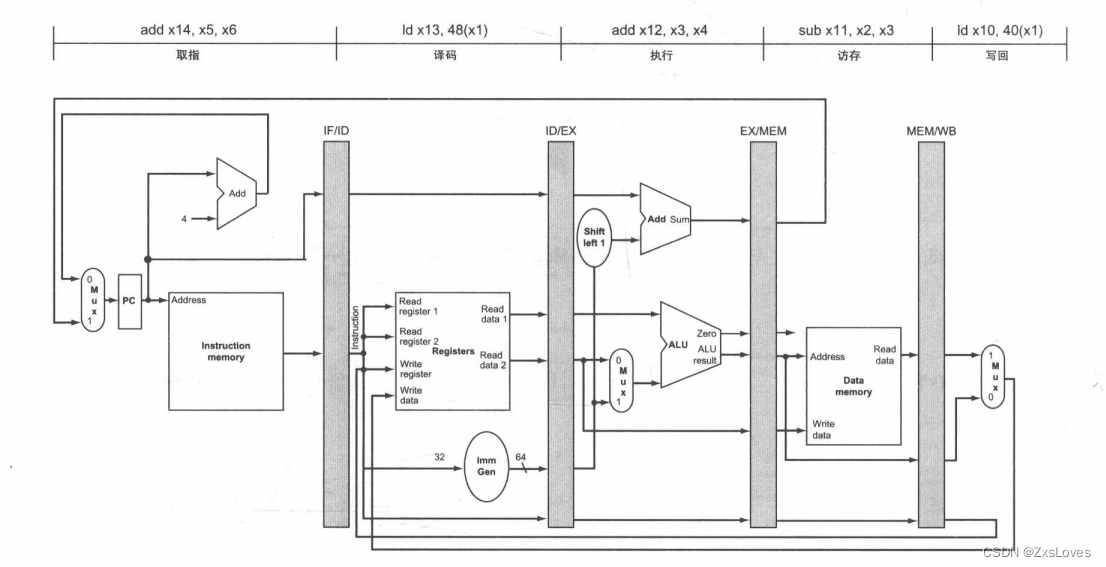
下面讲述的是一个大体上的对控制信号的排布 其实并不重要
因为他对单周期的改造和我自己写的单周期并不相同
1.取指:读指令存储器和写 PC 的控制信号总是有效的,因此在这个阶段没有什么需要特别控制的内容。
2.指令译码/读寄存器堆:在 RISC-V 指令格式中两个源寄存器总是位于相同的位置,因此在这个阶段也没有什么需要特别控制的内容。
3.执行/地址计算:要设置的信号是 ALUOp和 ALUSrc , 这个信号选择 ALU 操作,并将读数据 或者符号扩展的立即数作为 ALU 的输入。
4.存储器访问:本阶段要设置的控制线是 Branch MemRead MemWrite 。这些信号分别由相等则分支、加载和存储指令设置。除非控制电路标示这是一条分支指令并且 ALU的输出为 0, 否则将选择线性地址的下一条指令作为 PCSrc 信号。
5. 写回:两条控制线是 MemtoReg和 RegWrite, Mem oReg决定是将 ALU 结果还是将存储器值发送到寄存器堆中, Re Writ 写入所选值。
EX阶段的两个操作是 ALUop ALUSrc
M阶段的三个操作是 Branch MemRead MemWrite
WB阶段的两个操作是 MentoReg RegWrite
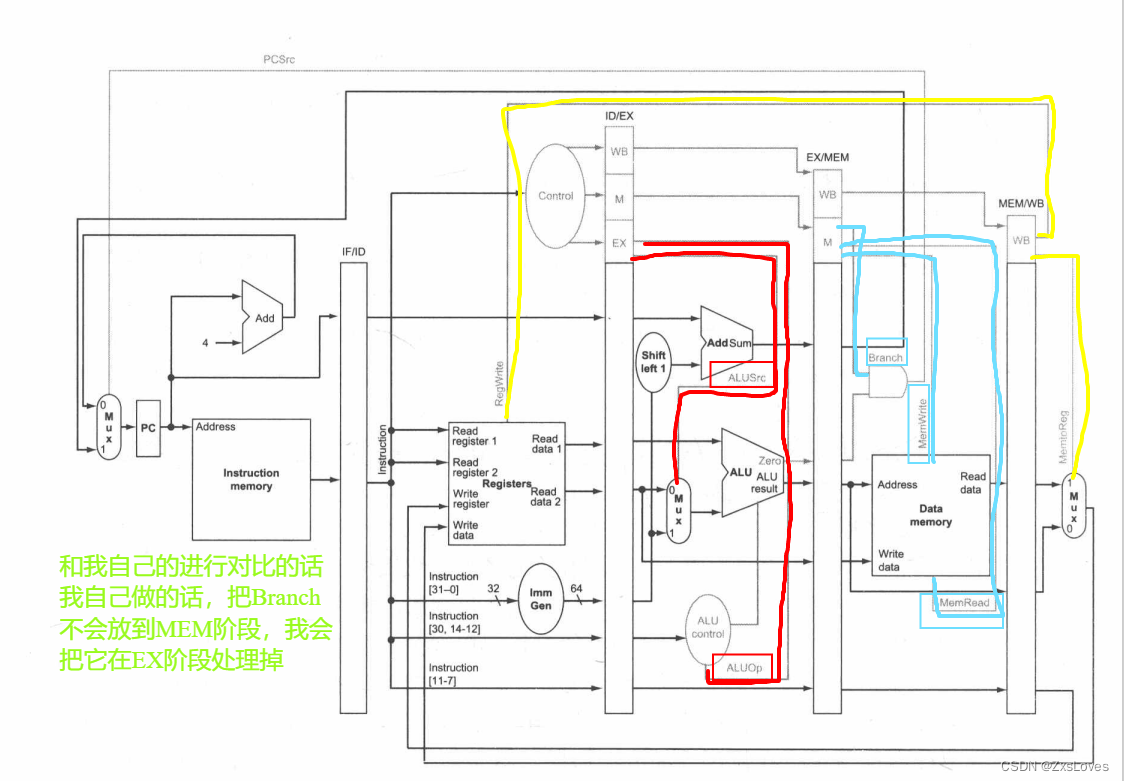

虽然我大概懂了 但是我觉得毫无意义
往下推论
我们并不是一定要在最后Datamemory 阶段传递数据的 我们每次在寄存器运算完成后都可以把数据存下来以备后续的使用
下面是讲述的包含前递之后的整个电路图
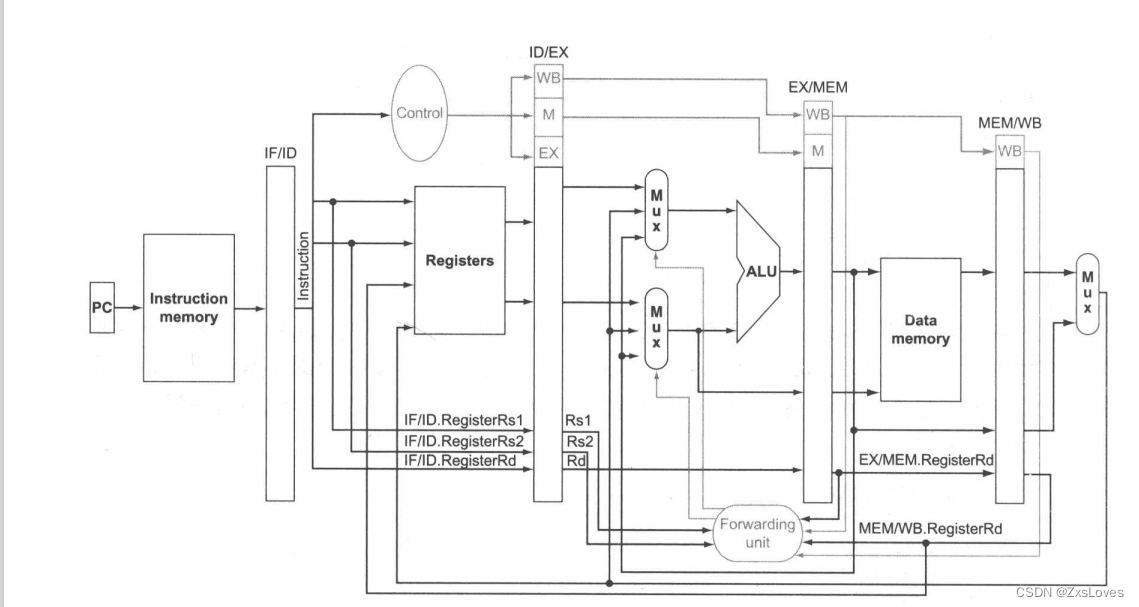
okok我们在这里先做一个总结
从一开始拿到数据 那先讲control信号 控制信号进行分段 每段传递一个功能 用完就丢弃
然而数据也是这样的 传递过去一个部门只执行一项东西 因为是流水线嘛
所以我们对于control信号 可以分开执行
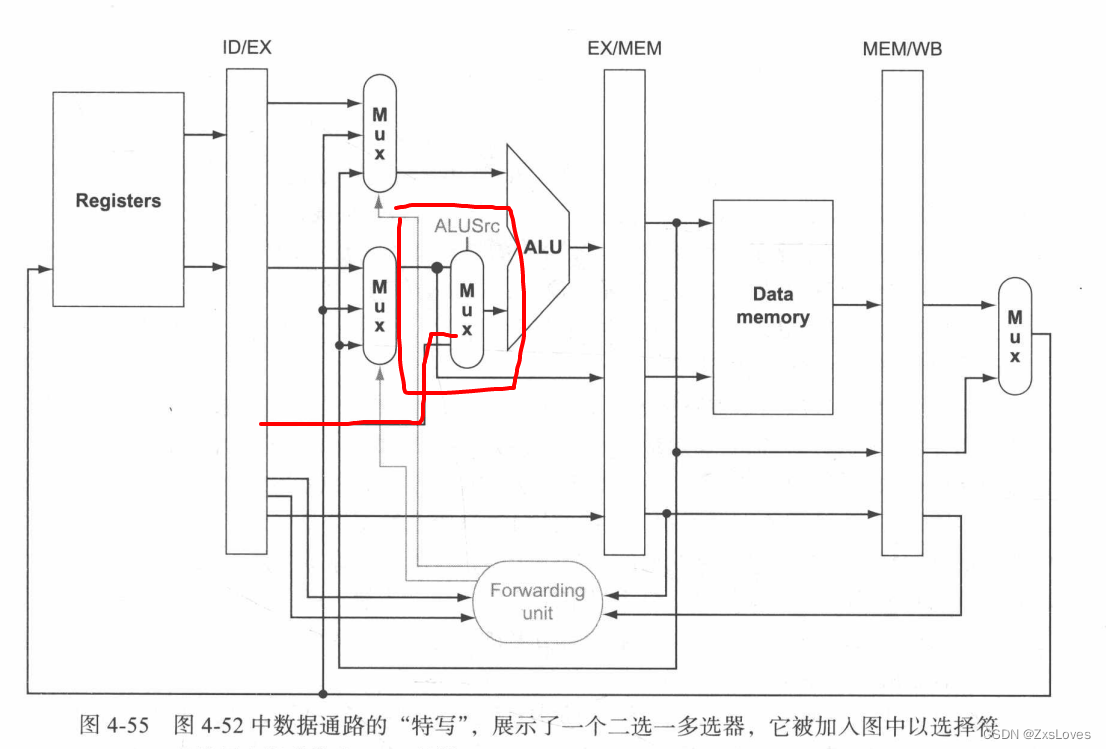
控制信号说完之后 我们讲述 数据通路的运转
数据通路 我们 在传递中意识到了并不是一定要等到结算完成之后才读取
我们可以在寄存器中读取数据
这就引出了前递的概念
当然我们上面介绍是关于R型指令的前递
我大概明白上面的意思
从表格上我们可以看出数据主要可以来自三个大方向
1.寄存器堆 (自己提取)
2.ALU计算结果 (maybe 是 需要R型的结果)
3.datamemory (maybe is used at ld or sd)
在这个结尾 它补充了一段 说是立即数没考虑进去最后加了一个新的立即数选择模块
ok 总结完毕 我们接下来看的是 非R型指令
这里面有一个什么问题呢
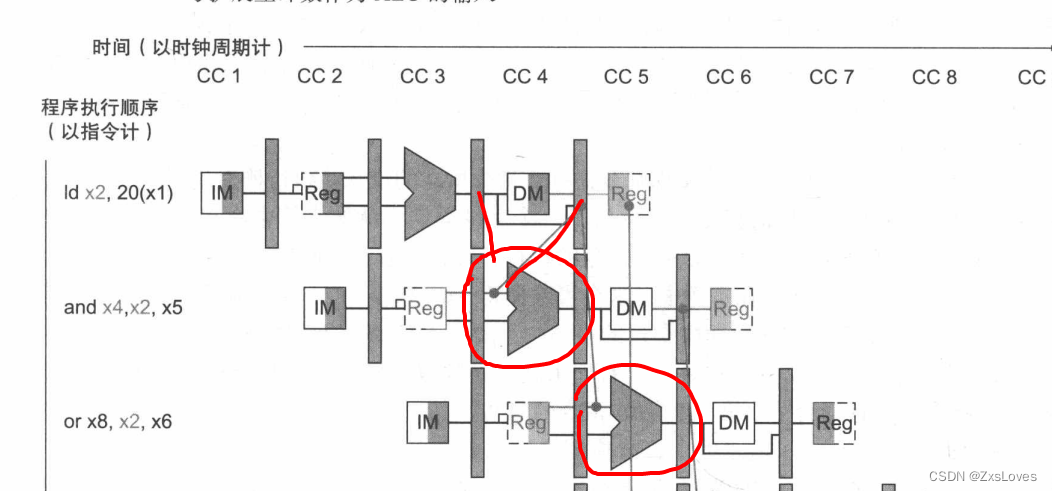
我们观察可知
因为我们所使用各项数据 基本上都是在ALU阶段
我们不去管这条指令是啥 主要在于他是否用到了上一条指令
我们观察上一条指令是R型那么我们在ALU刚计算完就可以直接拿数据了
但是如果上一条是LD或者SD 那么最终数据的取值 会在datamemory中
这里又会有数据位的参差 其实相对来说差了一整个时钟周期
所以对我们来说 我们的解决方法是增加一个检测单元
从而可以在加载指令和相关加载指令结果的指令之间加入一个流水线阻塞。
回想一下,我们在加载指令和 型指令中使用 Regi erRd 也就是指令的 11(11 :7) 表示指定的寄存器。第一行测试是为了查看指令是否是加载指令:只有加载指令需要读取数据存储器。接下来的两行检测在 EX 阶段的加载指令的目标寄存器是否与 ID 阶段的指令中的某一个源寄存器相匹配。如果条件成立,指令会停顿一个时钟周期。在一个时钟周期后,前递逻辑就可以处理这个相关并继续执行程序了。(如果没有前递,那么图 4-56 中的指令还需要再停顿一个时钟周期。)
接下来说一下 这个暂停是怎么做的
如果处于 ID 阶段的指令被停顿了,那么在 IF 阶段中的指令也一定要被停顿,否则已经取到的指令就会丢失。只需要简单地禁止 PC 寄存器和 IF/ID 流水线寄存器的改变就可以阻止这两条指令的执行。·
因为我们需要的是正确的ALU的输入 而对我们来说 停顿一个时钟周期
因为ALU不执行操作 那么 前面的阶段也不能执行
ID IF 两个阶段的操作需要停止
不更新新的值 那么是否会继续使用原本的老的值呢。如果这些寄存器被保护,在 IF 阶段的指令就会继续使用相同的 PC取指令,同时在 ID 阶段的寄存器就会继续使用 IF/ID 流水线寄存器中相同的字段读寄存器。
如何在流水线中插入空指令(就像气泡那样)呢?从图 4-47 中可知,解除 EX MEMWB 阶段的七个控制信号(将它们设置为 0) 就可以产生一个“没有任何操作”的指令,也就是空指令。通过识别 ID 阶段的冒险,我们可以通过将 ID/EX 流水线寄存器中 EX MEMWB 的控制字段设置为 来向流水线中插入一个气泡。这些不会产生负面作用的控制值在每个时钟周期向前传递并产生适当的效果:在控制值均为 的情况下,不会有寄存器或者存储器被写入数据。
and 指令所在的流水线执行槽变成了 no p指令,并且所有在 and 指令之后的指令都被延后了一个时钟周期。就像水管中出现了一个气泡那样,这个停顿气泡延后了它之后的所有指令的执行,并且随着每个时钟周期沿着流水线继续前进,直到其退出流水线。在本例中,这个冒险使得 and 指令和 or 指令在第 个时钟周期内重复了它们在第 个时钟周期内做过的事情: and 指令读寄存器和解码, or 指令从指令存储器中重新取了一遍指令。这种重复看起来就像是停顿一样,它的影响是拉伸了 and令和 or 指令,并且延后了取第 and 指令的时间。
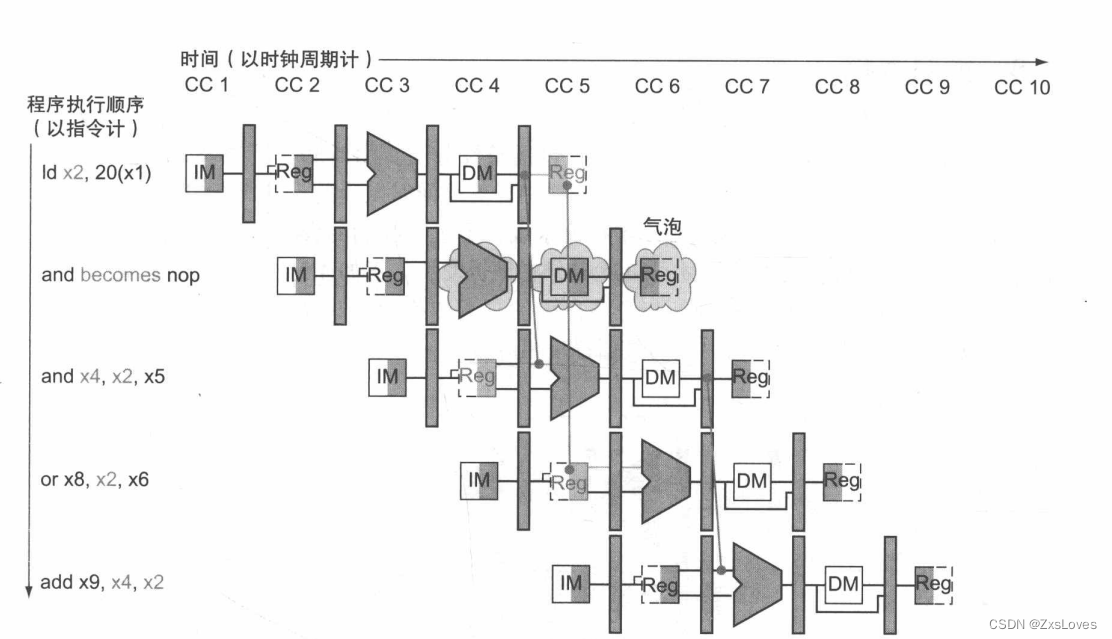
在流水线中插入停顿的方法。通过将 and 指令替换成 no p,在第 个时钟周期中插入了一个停顿。需要注意的是 and 指令在第 和第 个时钟周期内被译码和解码,但它的 EX 阶段被延后到第 个时钟周期中(如果没有停顿, EX 阶段应该发生在第 个时钟周期中。)相应的,or 指令在第 个时钟周期被译码,但它的 ID 阶段被延后到第 个时钟周期中(如果没有停顿, ID 阶段应该发生在第 个时钟周期中。)在插入气泡后,所有的相关性沿着时间轴继续向前,但是不会再发生冒险了
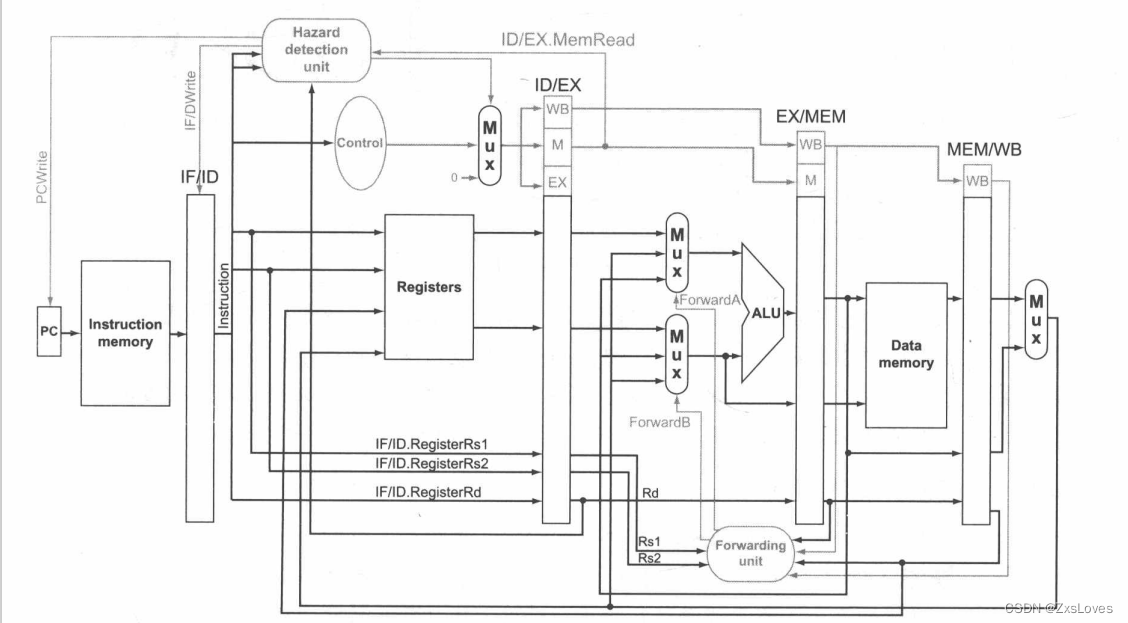
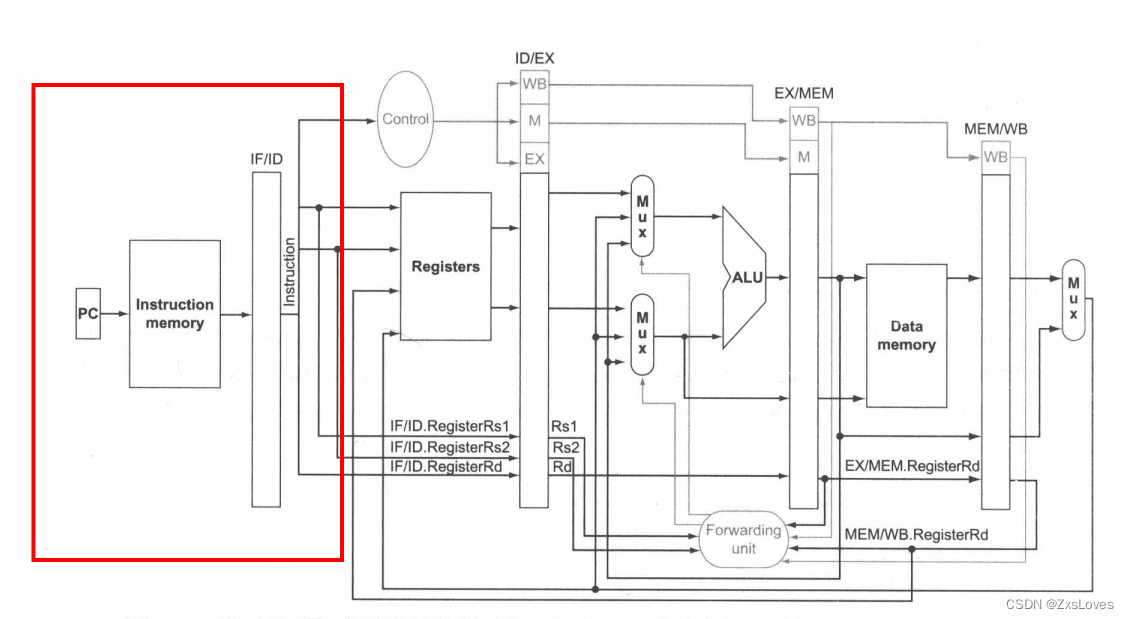
图中高亮显示了流水线中冒险检测单元和前递单元之间的连接。和原来一样,前递单元控制 ALU 多选器,用相应的流水线寄存器中的值替换通用寄存器中的值。冒险检测单元控制 PC IF/ID 流水线寄存器的写入,以及在实际控制值和全 之间选择的多选器。如果加载-使用冒险被检测为真,则冒险检测单元会停顿并清除所有控制字段。
我们现在分析控制冒险
迄今为止,我们只将对冒险的关注局限在算术操作和数据传输中。然而,正如 4.5 节所示,流水线冒险也包括条件分支。画出了一个指令序列,并标明在这个流水线中分支是何时发生的。每个时钟周期都必须进行取值操作以维持流水线,不过在我们的设计中,要等到 MEM 流水线阶段才可以决定分支是否发生。正如 4.5节中所述,这种为了决定正确执行指令所产生的延迟被称为控制冒险或分支冒险,这与我们之前讨论的数据冒险相对应。
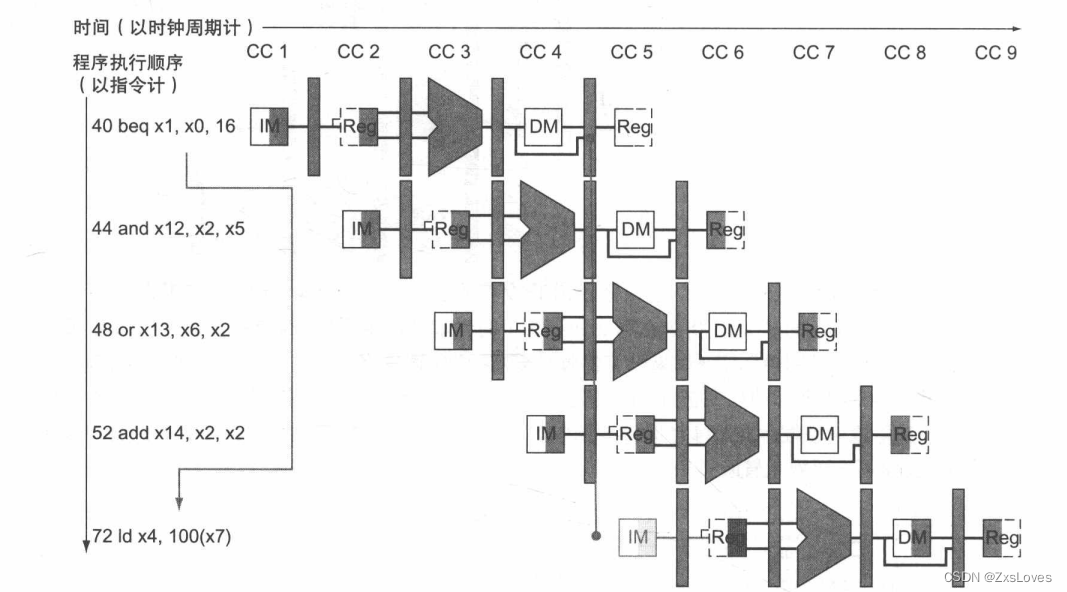
分支指令对流水线的影响。指令左边的数字 (40 44 等)代表指令的地址。因为分支指令在 MEM 阶段决定是否跳转(也就是图中 be q指令在第 个时钟周期内的操作),分支指令后续的三条指令都将被取值并且开始执行。如果不进行干预,这三条后续指令会在 beq指令跳转到地址 72 上的 指令之前就开始执行(图 4-29 使用了额外的硬件以减小控制冒险至一个时钟周期,而本图使用的是没有优化的数据通路。
我们这里说的分支指令在MEM阶段是从最上面的那个beq说起的 因为对我来说 我之前在写单周期的代码的时候 并没有放到MEM阶段 但是他在写代码的时候放到了MEM阶段
阻塞流水线直到分支完成的策略非常耗时。一种提升分支阻塞效率的方法是惊测条件分支不发生并持续执行顺序指令流。一旦条件分支发生,已经被读取和译码的指令就将被丢弃,流水线继续从分支目标处开始执行。如果条件分支不发生的概率是50%, 同时丢弃指令的代价又很小,那么这种优化方式可以减少一半由控制冒险带来的代价。想要丢弃指令,只需要将初始控制值变为 即可,这与指令停顿以解决加载-使用的据冒险类似。不同的是,丢弃指令的同时也需要改变当分支指令到达 MEM 阶段时 IF ID和EX阶段的三条指令,;而在加载-使用的数据停顿中,只需要将 ID 阶段的控制信号变为 并且将该阶段的指令从流水线中过滤出去即可。丢弃指令,意味着我们必须能够将流水线中 IF ID EX 阶段中的指令都清除。
困难的部分是分支决定本身。对于相等时跳转指令,需要在 ID 阶段比较两个寄存器中的值是否相等。相等的判断方法可以是先将相应位进行异或操作,再对结果按位进行或操作。将分支检测移动到 ID 阶段还需要额外的前递和冒险检测硬件,因为分支可能依赖还在流水线中的结果,在优化后依然要保证运行正确。例如,为了实现相等时跳转指令(或者不等时跳转指令),需要在 ID 阶段将结果前递给相等测试逻辑。这里存在两个复杂的因素:.在 ID 阶段需要将指令译码,决定是否需要将指令旁路至相等检测单元,并且完成相等测试以防指令是一条分支指令,此时可以将 PC 设置为分支目标地址。对分支指令的操作数进行前递的操作原先是由 ALU 前递逻辑处理的,但是在 ID 阶段引入相等检测单元后就需要添加新的前递逻辑。需要注意的是,旁路获得的分支指令的源操作数既可以从 EX/MEM流水线寄存器中获得,也可以从 MEM/WB 流水线寄存器中获得。.在 ID 阶段分支比较所需的值可能在之后才会产生,因此可能会产生数据冒险,所以指令停顿也是必需的。例如,如果一条 ALU 指令恰好在分支指令之前,并且这条 ALU 指令产生条件分支检测时所需的操作数,那么一次指令停顿就是必需的,因为 ALU 指令的 EX阶段将发生在分支指令的 ID 阶段之后。又例如,如果一条加载指令恰好在条件分支指令之后,并且条件分支指令依赖加载指令的结果,那么两个时钟周期的停顿就是必需的,因为加载指令的结果要在 MEM 阶段的最后才能产生,但是在分支指令的 ID 阶段的开始就需要了
总结一下 我们想把整个控制冒险浓缩到ID阶段解决
那么会带来许多的问题 因为IF/ID寄存器会提供指令的立即数字段 也会提供 PC的值
接下来 两个难点 一个是计算分支目标的地址 还有一个是判断分支条件
我们把指令发送给ID阶段后,ID阶段会确定是否传递至旁路检测单元
但是这个旁路检测单元需要传递很多信息给他 比如说来自两个ALU端的数据究竟在哪里 需要很多单元的前递去供养这个内容的加法
还有第二个问题 我们在ID阶段 那么其实相对来说比之前的EX还要早 那么 就像是加载指令一样来自于 MEM阶段的怎么办呢 是不是还有采取停顿的操作
尽管这很困难,但是将条件分支指令的执行移动到 ID 阶段的确是一个有效的优化,因为这将分支发生时的代价减轻至只有一条指令,也就是分支发生时正在取的那条指令,下面的例题展示了实现前递路径和检测冒险的更多实现细节。
为了清除 IF 阶段的指令,我们添加了一条称为 IF.Flush 的控制线,它将 IF/IF 流水线寄存器中的指令字段设置为 。将寄存器清空的结果是将已经取到的指令转换成一条 no p指令,该指令不进行任何操作,也不改变任何状态。
我们这里先介绍一下两张图片的对比差距
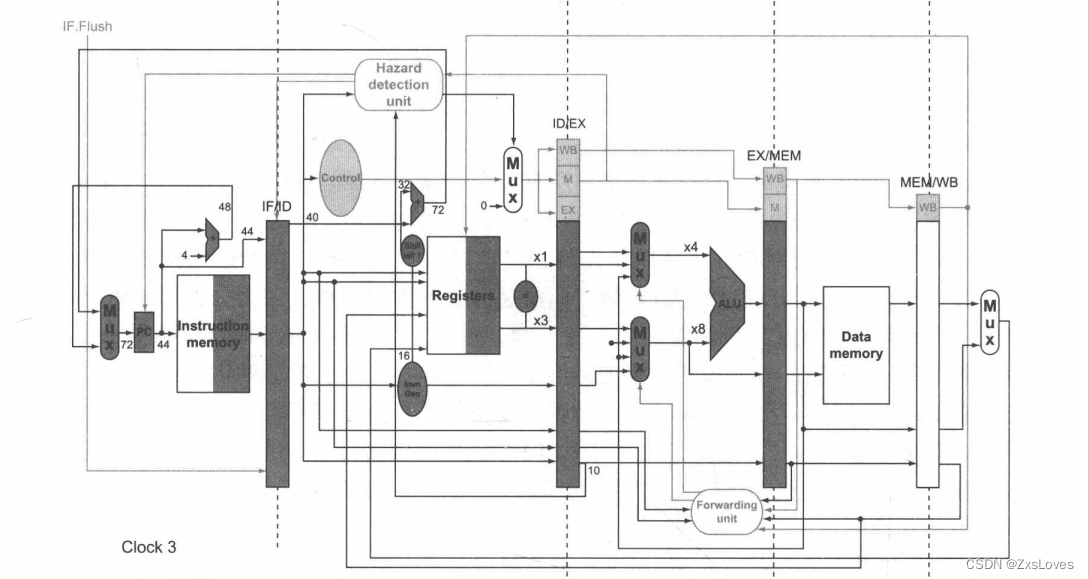
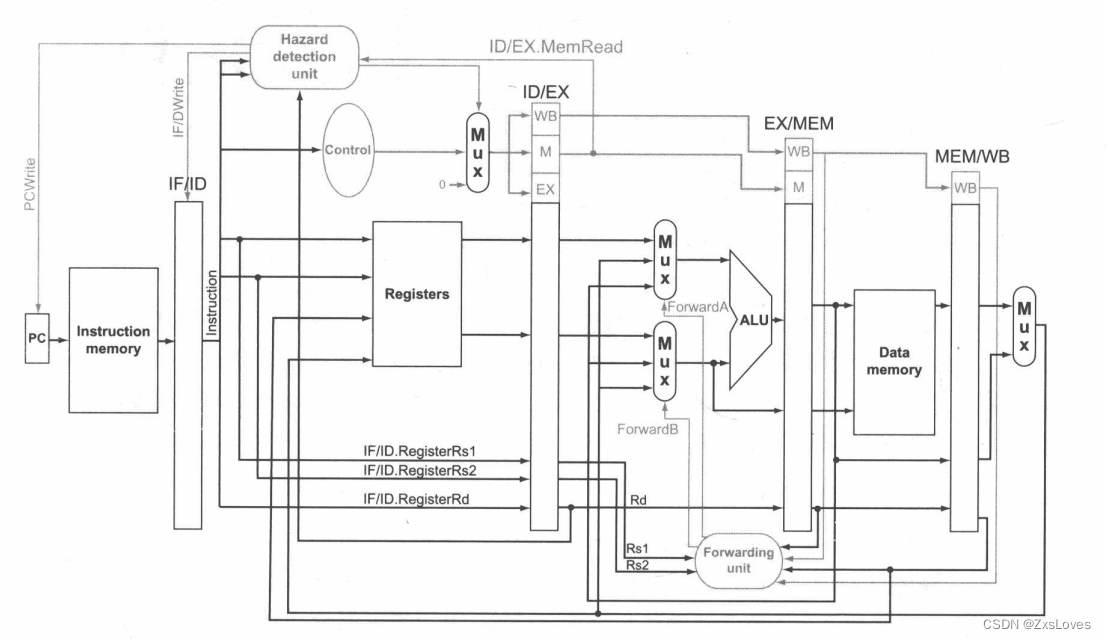 发现ID阶段多了几个新的旁路设施用来进行计算
发现ID阶段多了几个新的旁路设施用来进行计算
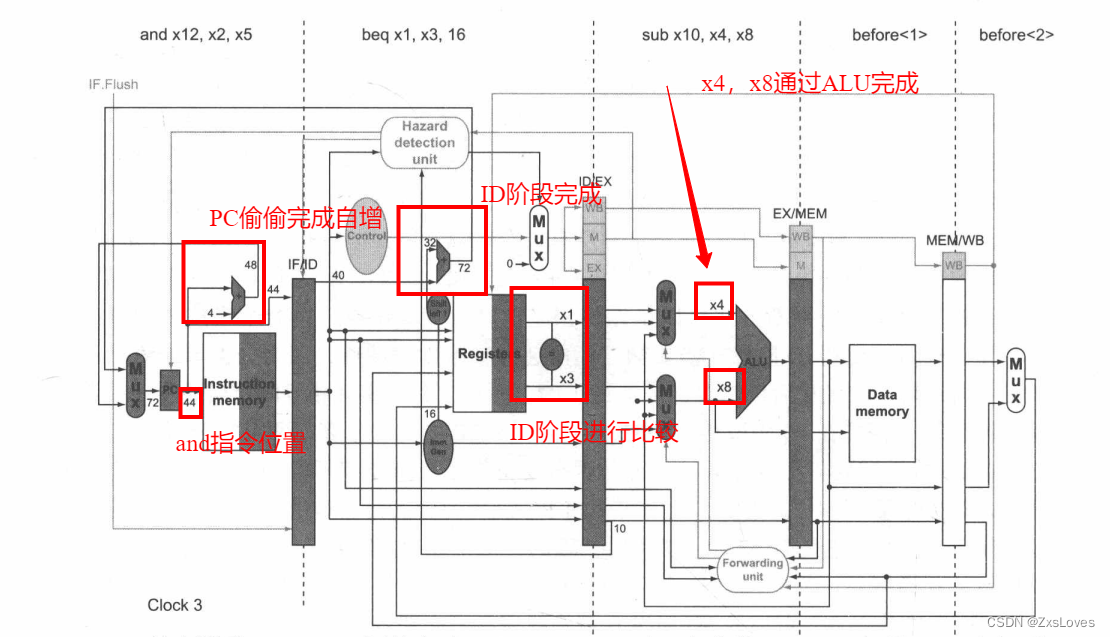
我们先讲述一下 这个基本的需要完成的代码的条数
36 sub x10, x4, x8
40 beq x1, x3,16 //PC-rela ti vebranch t o40+16*2=72
44 and x12, x2, x5
48 or x13, x2, x6
… …
72 ld x4, 50(x 7)
我们先来分析时刻三全状态的不同的意思
第四个时钟
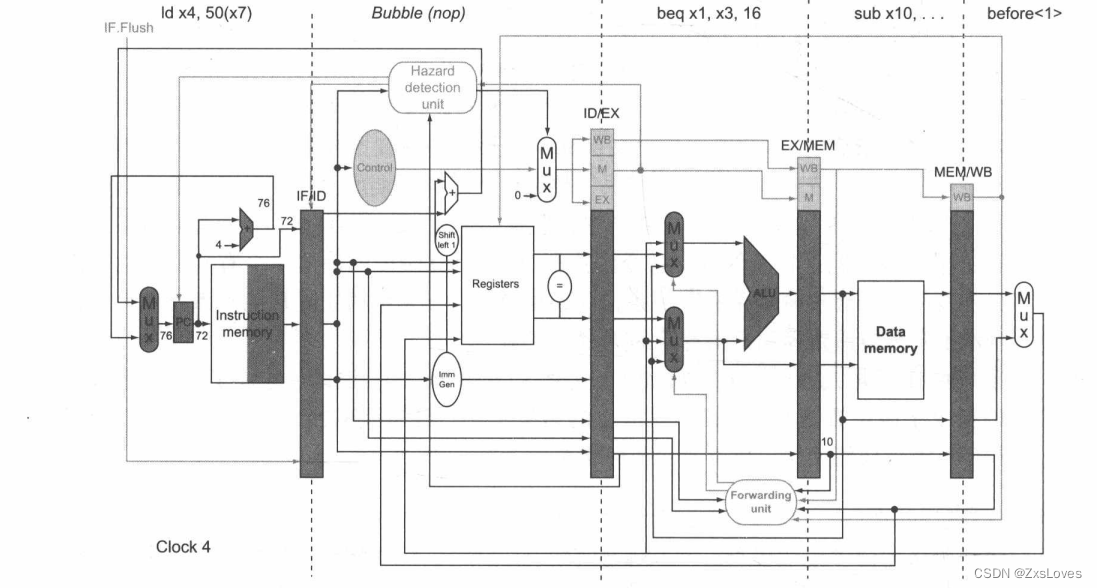
在第 个时钟周期的 ID 阶段决定分支执行必须被执行,因此选择 72 作为下一 PC跳转地址,并且将下个时钟周期获取到的指令置 。第 个时钟周期显示了地址 72中的指令被获取,并且因为分支发生而在流水线中产生了一个气泡或者 nop指令
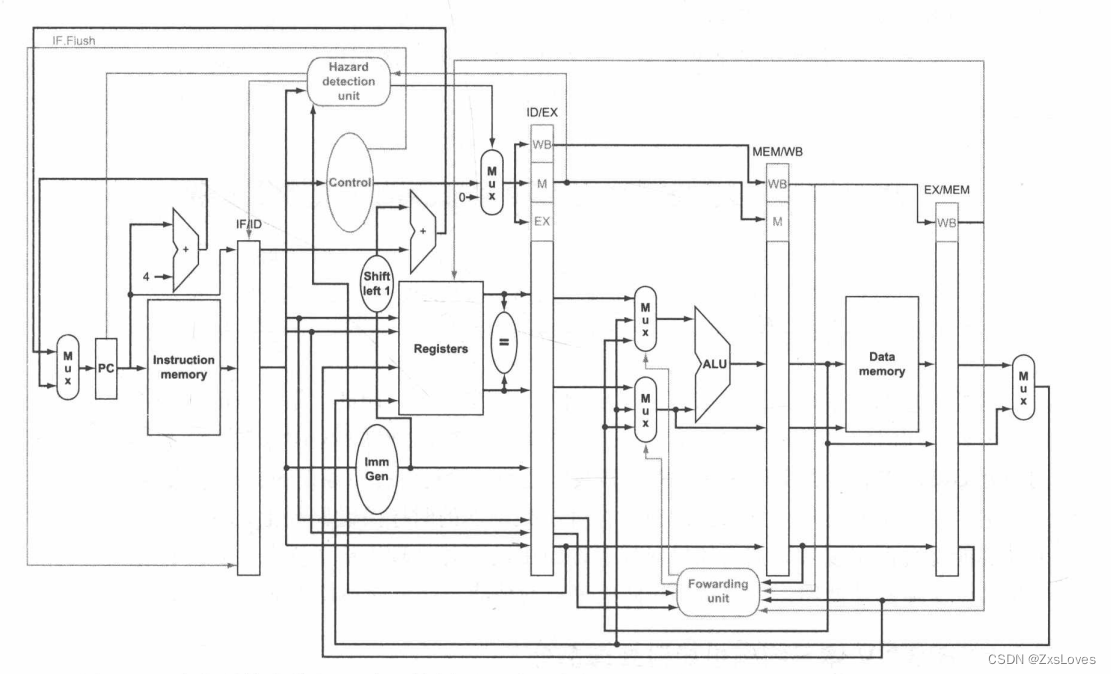
最终实现的流水线运行图
(它其实还说了一个可以存东西的最大流水线没精力看了 把这个搞完就好了)

![[AIGC] “惊天神器!Java大师推荐的终极工具 Netty ,让你的代码速度狂飙!“](https://img-blog.csdnimg.cn/8a466ed7b8f24f7b93327d63d3358fd4.png)