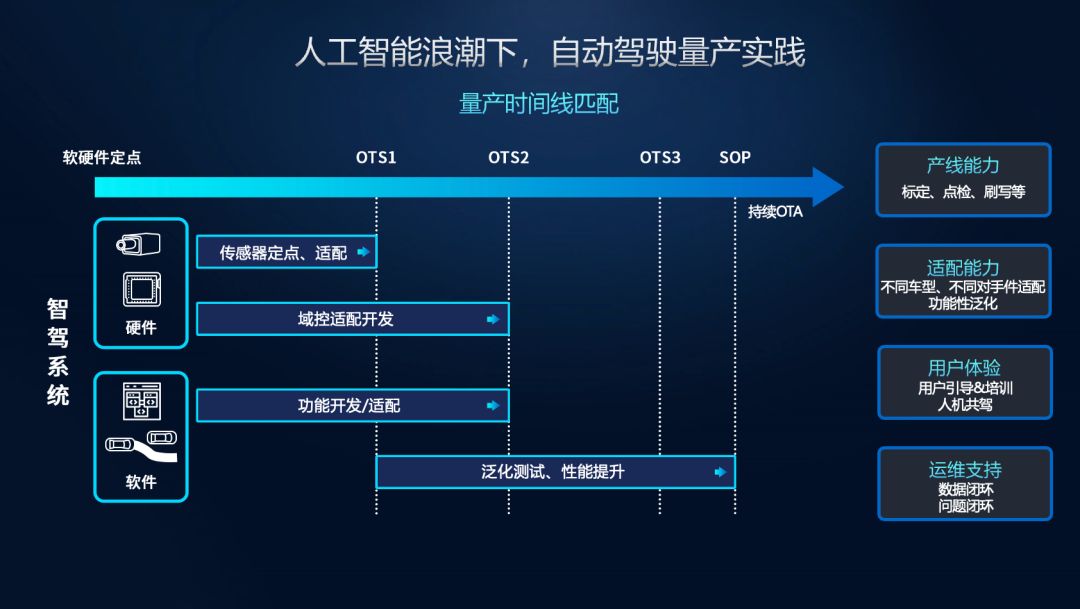
验证曲线 validation_curve
一、简介
validation_curve验证曲线,可确定不同参数值下的训练和测试分数
根据指定参数的不同值计算估计器的得分
这与使用一个参数的网格搜索类似。不过,这也会计算训练得分,只是一个用于绘制结果的工具。
二、官网API
官网API
sklearn.model_selection.validation_curve(estimator, X, y, *, param_name, param_range, groups=None, cv=None, scoring=None, n_jobs=None, pre_dispatch='all', verbose=0, error_score=nan, fit_params=None)
需要导包:from sklearn.model_selection import validation_curve
这里的参数还是比较多的,具体的参数使用,可以根据官网给的demo进行学习,多动手尝试;这里就以一些常用的参数进行说明。
参数
①estimator
一个该类型的对象,每次验证时都会被克隆。它还必须实现 “预测”,除非 scoring 是一个不依赖 "预测 "来计算分数的可调用对象。这里使用支持向量机分类模型进行测试,SVC(C=3.0,kernel='sigmoid’,gamma=‘auto’,random_state=42),详细参数可参考博文:三、支持向量机算法(SVC,Support Vector Classification)(有监督学习)
具体官网详情如下:

②X
训练向量,其中 n_samples 是样本数,n_features 是特征数。
说白了就是自变量
具体官网详情如下:
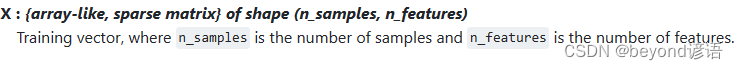
③y
分类或回归时,相对于 X 的目标值;无监督学习时,则为None。
说白了就是因变量
具体官网详情如下:

④cv
确定交叉验证分割策略
“None”,默认5倍交叉验证
int,用于指定(分层)KFold 中的折叠数,即K值
具体官网详情如下:

返回值
①train_scores
训练集得分
具体官网详情如下:
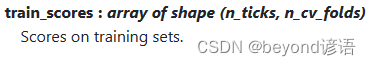
②test_scores
测试集得分
具体官网详情如下:

三、项目实战
①导包
若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import validation_curve
②加载数据集
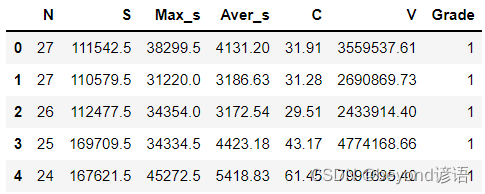
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
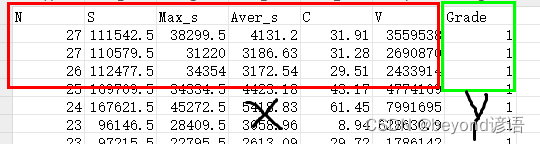
通过pandas读入文本数据集,展示前五行数据
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③调用函数获取损失结果
获取测试结果
train_sizes,train_loss, val_loss = learning_curve(
SVC(C=3.0,kernel='sigmoid’,gamma=‘auto’,random_state=42), X, Y, cv=10, scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1] # 在整个过程中的10%取一次,25%取一次,50%取一次,75%取一次,100%取一次
)
print(train_sizes)
print(train_loss)
print(val_loss)
④绘图
train_loss_mean = -np.mean(train_loss, axis=1)
val_loss_mean = -np.mean(val_loss,axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-',color='r',label='Training')
plt.plot(train_sizes,val_loss_mean,'o-',color='g', label='Cross-validation')
plt.xlabel('Training examples')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
⑤完整代码
from sklearn.model_selection import learning_curve
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
train_sizes,train_loss, val_loss = learning_curve(
SVC(C=3.0,kernel='sigmoid’,gamma=‘auto’,random_state=42), X, Y, cv=10, scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1] # 在整个过程中的10%取一次,25%取一次,50%取一次,75%取一次,100%取一次
)
print(train_sizes)
print(train_loss)
print(val_loss)
train_loss_mean = -np.mean(train_loss, axis=1)
val_loss_mean = -np.mean(val_loss,axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-',color='r',label='Training')
plt.plot(train_sizes,val_loss_mean,'o-',color='g', label='Cross-validation')
plt.xlabel('Training examples')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()



![[C++_containers]10分钟让你掌握vector](https://img-blog.csdnimg.cn/2061eb2ab5e14341aee0189b14c35bbd.png)