目录
一.相关指针知识点
二.链表
1.为什么学了顺序表还要学链表
2.优点
三.实现
1.链表的打印 —— 理解链表结构
(2) 物理结构图
2.链表的尾插 —— 入门
错误写法:tail != NULL
总结:
正确代码物理图解:
(2) 尾插整体代码 (思考对吗?)
Bug
3.头插
4.尾删
Bug
5.头删
6.查找
7. Find 查找的功能
(1)pos 之前插入
(2)pos 位置删除
(3)pos 之后插入
(4)pos位置后面删除
四.思维提升
五.总结
1.传什么?
2.要不要断言?
(1)打印、查找
(2)pphead
(3)*pphead
六.整体代码
SList.h
SList.c
一.相关指针知识点
调用一个函数,就会建立一个空间,这个空间叫栈帧。局部变量是存放在栈帧里的(除了static修饰的局部变量)。函数结束,栈帧空间就销毁,局部变量也销毁
函数传参,不管是传值,还是传地址,其实都是拷贝。就看拷贝值还是地址。
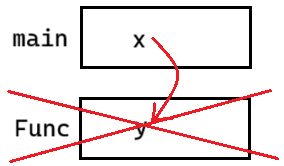
代码1:y 的改变,不会改变 x 的值
void Func(int y)
{
y = 1;
}
int main()
{
int x = 0;
Func(x);
return 0;
}这是两个栈帧,Func 里面是 y,main 里面是 x。x 传给 y 是拷贝给 y,y 的改变不会影响 x,并且 Func 会销毁
代码2:解决上面问题,传地址。改变的是 int ,使用的是 int 的指针
void Func(int* p)
{
*p = 1;
}
int main()
{
int x = 0;
Func(&x);
return 0;
}这里的 p 是 x 地址的拷贝。在传参里面,我们要改变什么,就要用它的指针。然后 * 解引用可以改变
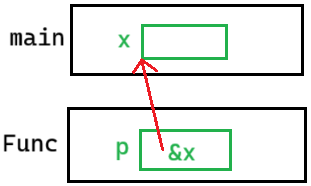
代码3:
void Func(int* ptr)
{
ptr = (int*)malloc(sizeof(int));
}
int main()
{
int* px = NULL;
Func(px);
free(px); // 加上也没用
return 0;
}这也是拷贝值,把 px 的值拷贝给 ptr,ptr 是空。但是我 malloc 了一块空间,让 ptr 指向这块空间。
px 拷贝给 ptr,ptr 的改变不会影响 px 。并且出了作用域 Func 销毁,malloc 的内存块还找不到了(内存泄漏),就算 free 也 free 不到
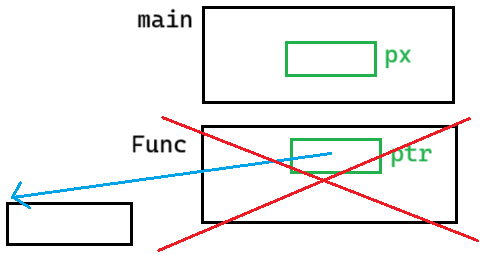
这里我们要改变的是 int* ,不是 int 。传 int* 不起作用。应该传 int**(二级指针)
代码4:改变 int* ,使用 int* 的地址,int**(二级指针)
void Func(int** pptr)
{
*pptr = (int*)malloc(sizeof(int));
}
int main()
{
int* px = NULL;
Func(&px);
free(px);
return 0;
}这里把 px 的地址传过去,pptr 指向 px 。malloc了一块空间,是让 *pptr 即 px 指向这块空间
Func 结束,栈帧销毁。但 px 还指向这块空间,free 可以 free 到。这里内存释放,值也拿回来了
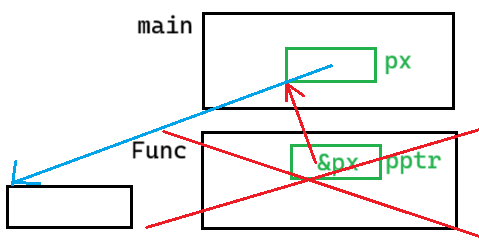
二.链表
1.为什么学了顺序表还要学链表
顺序表是有很多缺陷的:
(1)中间,头部 插入,删除数据,需要挪动数据,效率低下。你也不可能说在中间插入一块空间,没有这种概念,这本来就是一块连续的空间。
(2)空间不够需要扩容,拷贝数据,释放旧空间。会有不小的消耗
扩容有一定的效率消耗。原地扩还好,异地扩呢?
还可能会有一定的空间浪费。一次扩太少,会频繁扩;一次扩太多,浪费
能不能说,我用一点给一点呢?存一块数据,开一块空间
可以,但怎么管理呢?
顺序表里,开了整片空间,由于存放的数据是连续的,只需要记录这块空间最开始的地址。
现在要一块空间,去 malloc 。多次 malloc ,他们之间的地址不能保证相邻。
这时候,链表会用一个指针指向第一个内存块(节点 Node)。
为了通过第一个能找到第二个怎么办?上一个会存下一个的地址,上一个指向下一个。
什么时候结束?顺序表是 size 。链表里最后一个节点的指针存 NULL 即可
2.优点
不需要扩容。存一块,开一块。
可以从中间插入,不需要挪动数据。
顺序表,链表是互补,相辅相成的。很多情况是配合起来使用的
三.实现
上面的理解,链表是一个个的内存块,再由指针链接起来
先来定义它的结构:从语言的角度来说,凡是有多个数据,都要存到结构体里面
为方便替换成其他类型的数据,我们将类型统一重命名为 SLTDataType
1.链表的打印 —— 理解链表结构
SList.h
上一个节点要存下一个节点的地址,每个节点都是结构体类型,所以存结构体指针 next
链表要有个头指针 phead 指向第一个节点,判断结束只需要走到空 NULL 即可。
不能断言 phead 为空,空链表也可以打印
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
//打印链表
void SLTPrint(SLTNode* phead);SList.c
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
//while (cur->next != NULL) 错误写法!!!
//while(cur != NULL)
while (cur)
{
printf("%d->", cur->data);
cur = cur->next; // 指向下一个位置
// 不能写成 ++cur;
}
printf("NULL\n");
}问:为什么不能写成 ++cur ?
答:链表地址不连续,++cur 不能保证它指向下一个位置。如果强行把地址弄成连续,不就成顺序表了吗?
怎么理解 cur = cur->next;
cur 是结构体指针,cur-> 就是访问结构体成员。next 是结构体成员,是下一个节点的地址
赋值操作是把下一个节点的地址给 cur
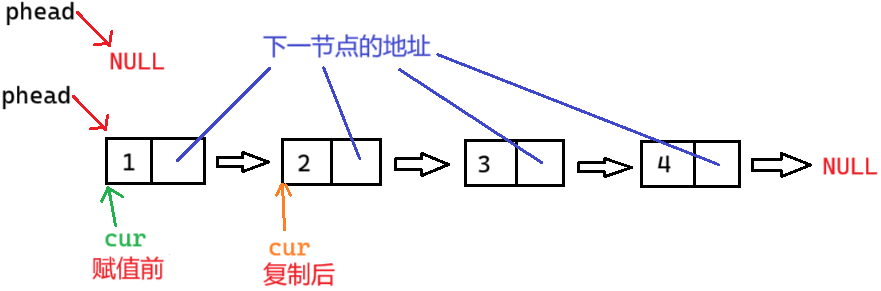
为什么循环判断条件 cur->next != NULL 为错?
cur->next 是下一节点地址。走到尾就结束了,没有打印最后的数据
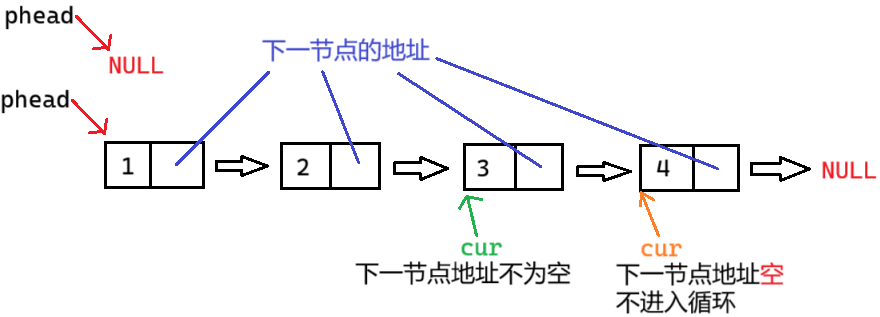
(2) 物理结构图
上面画的是逻辑结构图,是为方便理解,形象画出来的
物理结构图:实实在在数据在内存中的变化
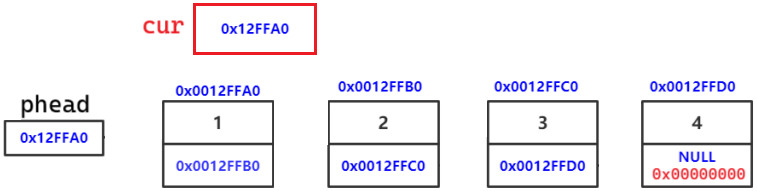
2.链表的尾插 —— 入门
依然不能断言 phead 为空。为空(没有数据)依然可以尾插
顺序表尾插,先要判断空间够不够,不够扩容。 链表不用,永远有空间
第一步:搞个节点,并初始化。后面多次用到,分装成函数
第二步:找尾。 尾的特征:tail->next == NULL
// 搞节点,并初始化
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
// 初始化
newnode->data = x;
newnode->next = NULL;
return newnode;
}
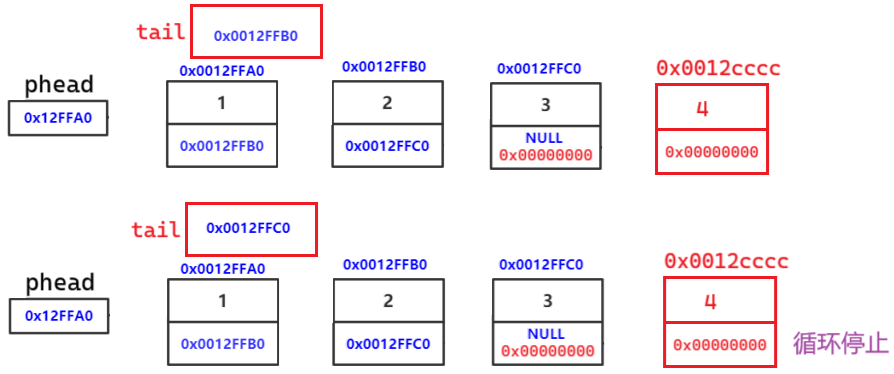
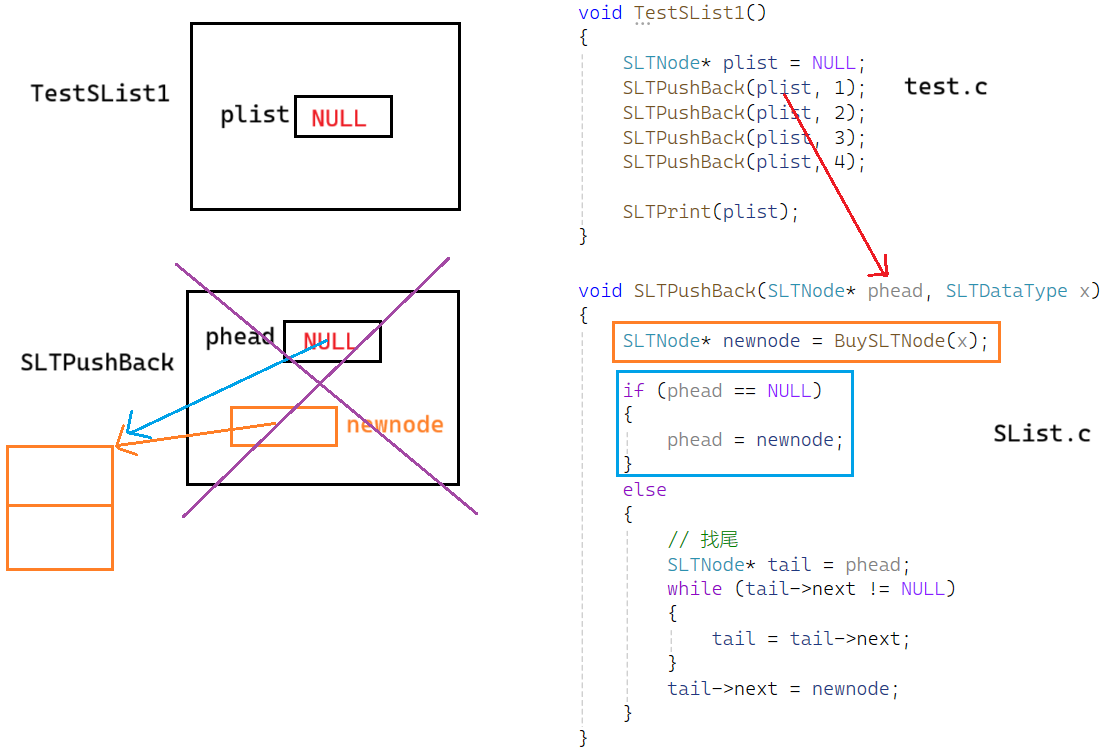
void SLTPushBack(SLTNode* phead, SLTDataType x) // 思考这里对吗?
{
SLTNode* newnode = BuySLTNode(x);
// 找尾
SLTNode* tail = phead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}错误写法:tail != NULL
// 找尾
SLTNode* tail = phead;
while (tail != NULL)
{
tail = tail->next;
}
tail = newnode;从逻辑结构图角度,看似正确:
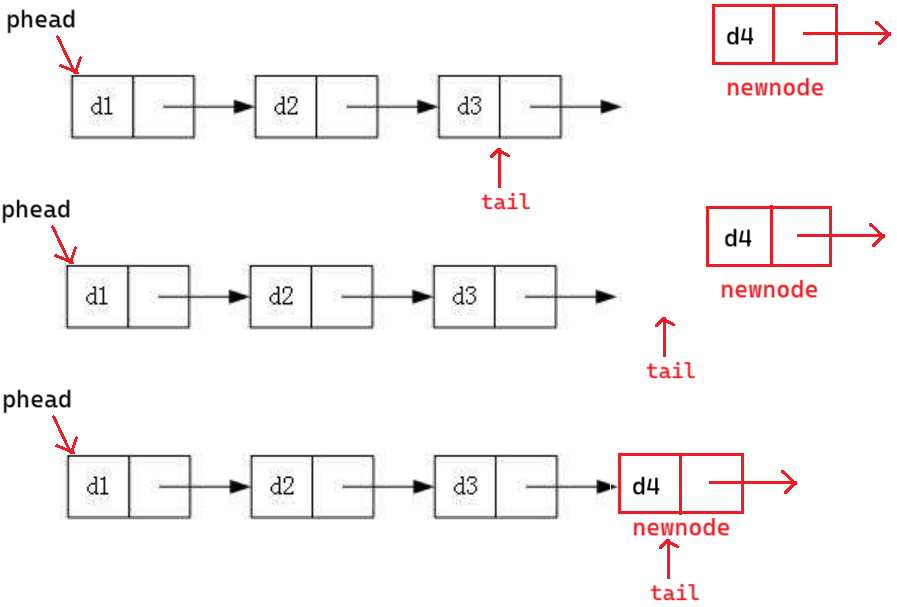
从物理结构图理解:
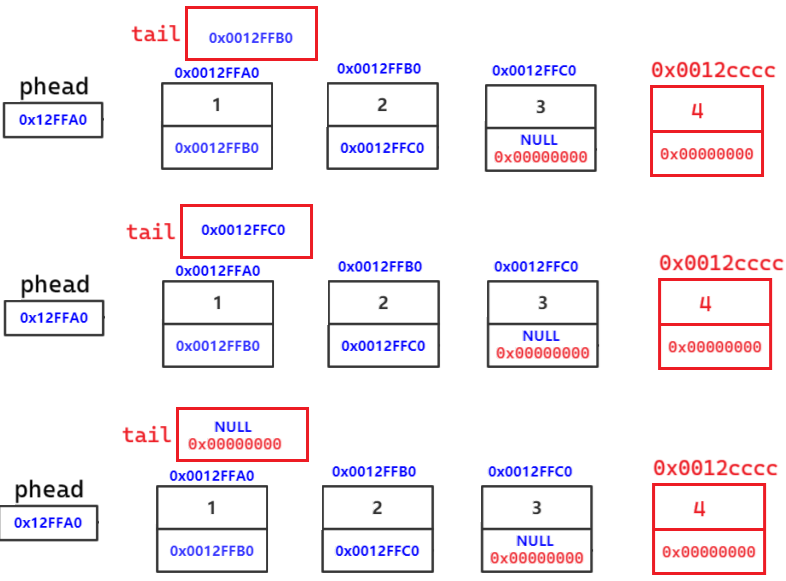
tail ,newnode 都是局部变量,出了作用域销毁

上一个节点没有存下一个节点的地址,链接失败
总结:
tail 是个局部变量。不应该赋值给 tail 。应该赋值给 tail 指向的结构体(存放下一个节点地址的)成员
不为空链表尾插的本质:原尾节点中要存新的尾节点的地址
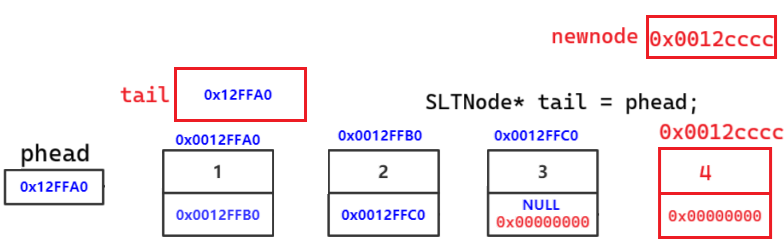
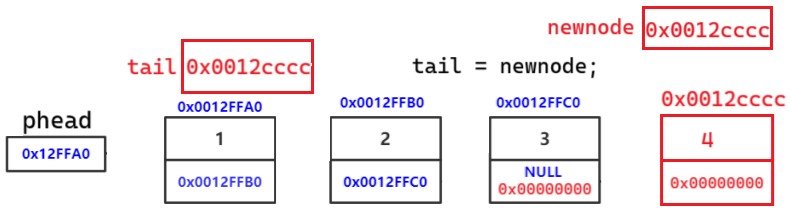
正确代码物理图解:
// 找尾
SLTNode* tail = phead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;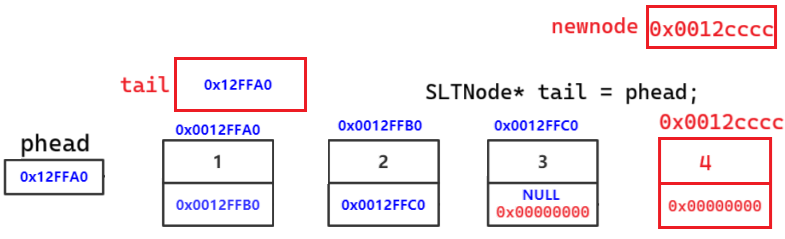
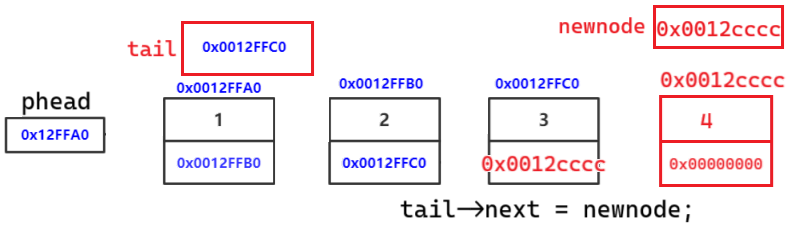
tail ,newnode 都是局部变量,出了作用域销毁

上一个节点存储下一个节点的地址,链接成功
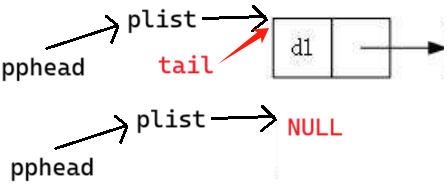
(2) 空链表尾插
phead == NULL tail = phead 让 phead 指向新节点即可
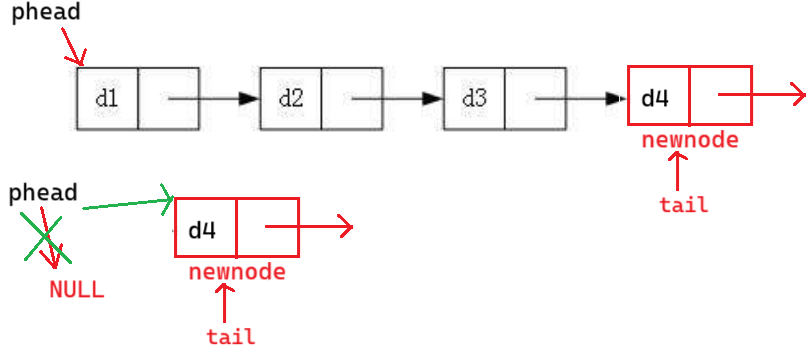
(2) 尾插整体代码 (思考对吗?)
SList.h
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
//打印链表
void SLTPrint(SLTNode* phead);
//尾插
void SLTPushBack(SLTNode* phead, SLTDataType x); // 思考这里对不对SList.c
void SLTPushBack(SLTNode* phead, SLTDataType x) // 对吗?
{
SLTNode* newnode = BuySLTNode(x);
if (phead == NULL)
{
phead = newnode;
}
else
{
// 找尾
SLTNode* tail = phead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}Test.c
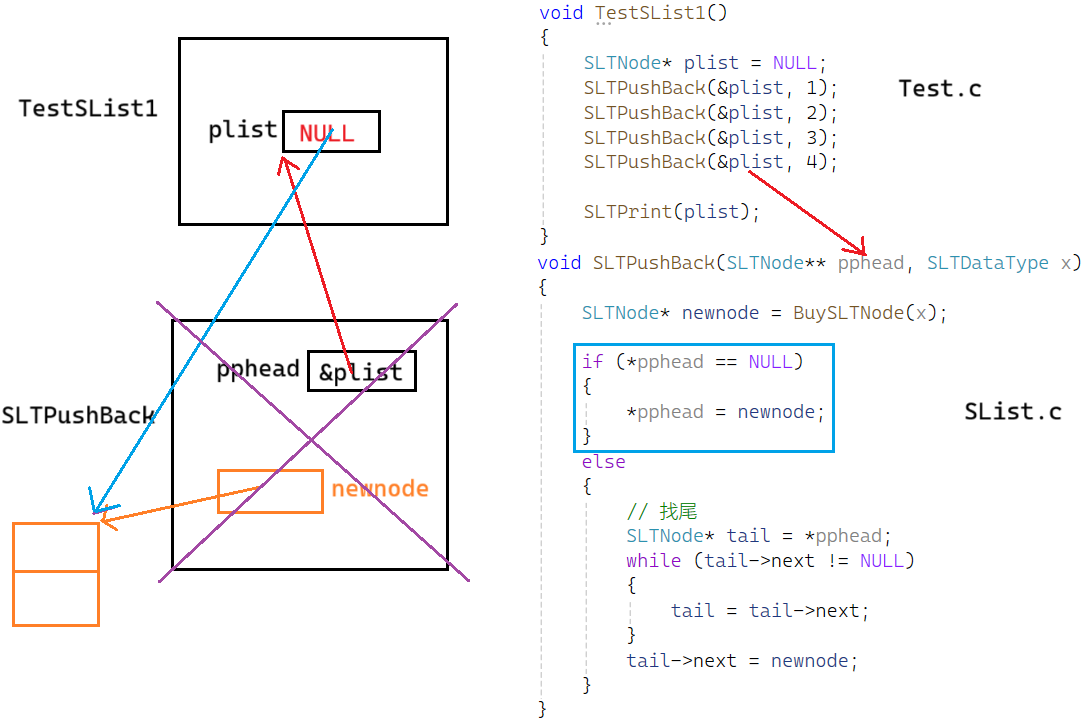
void TestSList1()
{
SLTNode* plist = NULL;
SLTPushBack(plist, 1);
SLTPushBack(plist, 2);
SLTPushBack(plist, 3);
SLTPushBack(plist, 4);
SLTPrint(plist);
}Bug
我们运行上面的代码: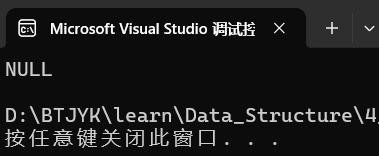
看下图,phead 和 newnode 都是结构体指针类型的指针变量
phead = newnode 是赋值行为,其真正含义是让 phead 也指向 newnode 指向的新节点
函数结束,栈帧空间销毁。我们的目标是让 plist 指向新节点,但最后没有,造成了内存泄漏
改Bug
我们要改变 SLNode* plist ,传参里要传 SLNode* plist 的地址 ,用 SLNode** 接收
SList.h
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
//打印链表
void SLTPrint(SLTNode* phead);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);SList.c
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySLTNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
// 找尾
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}pphead 存的是 plist 的指针。*pphead 就是 plist 。
函数结束,栈帧空间销毁。plist 指向了新节点
链表运行结果:
3.头插
盲猜头插要用二级指针,因为一定有一个情况是为空,为空肯定要用
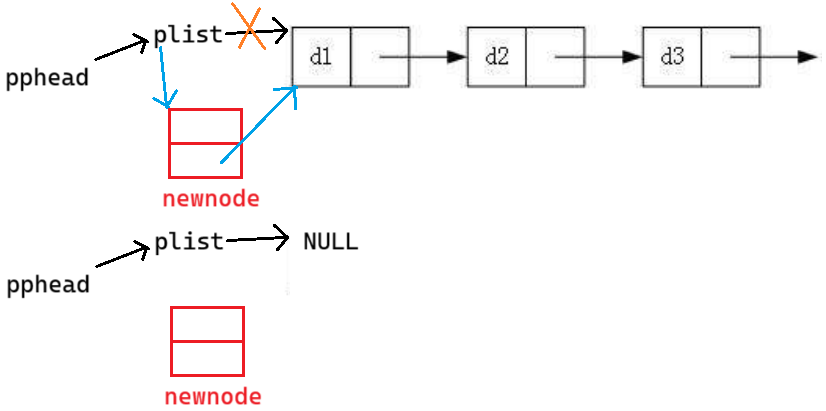
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}如果传的是 phead ,改变的就是 phead ,无法改变外边的 plist
这段代码同样可以解决空的情况
4.尾删
SList.c
void SLTPopBack(SLTNode** pphead) // 这么写对吗?
{
assert(pphead);
assert(*pphead);
// 找尾
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
free(tail);
tail = NULL;
}Test.c
void TestSList1()
{
SLTNode* plist = NULL;
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
}Bug
 碰上这种情况多半是野指针,调试看看
碰上这种情况多半是野指针,调试看看
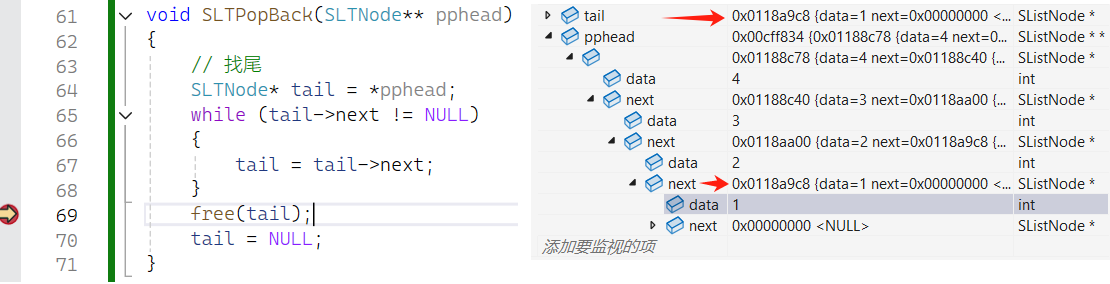
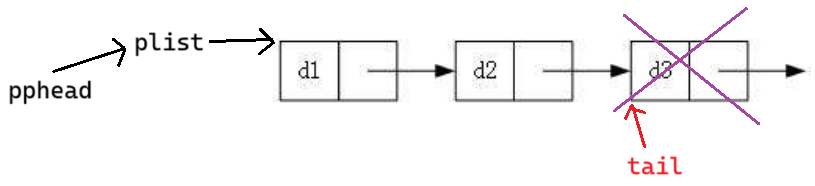
尾就是1这个节点,2这个节点存着他的地址
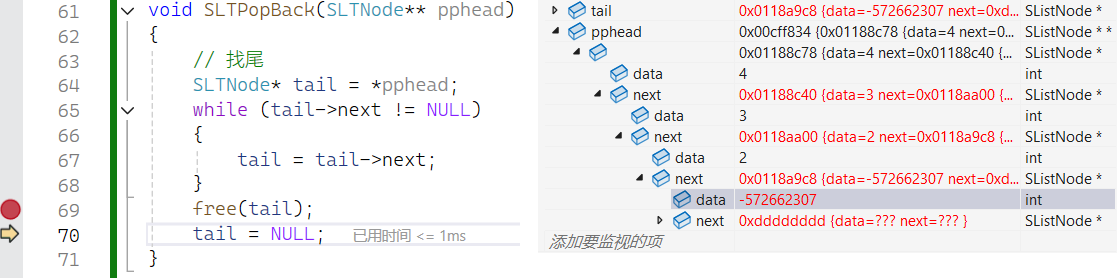
直接把 tail 指向的尾节点 free 了,前一个节点的 next 就是野指针了。指向已经被释放的空间的指针是野指针
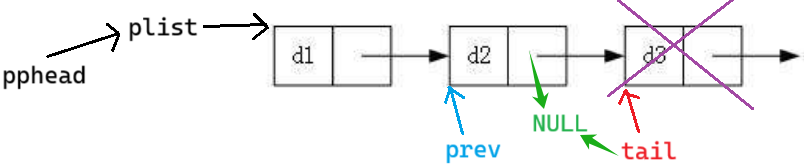
这里把 tail 置空,不会把前一个节点的 next 置空
前一个节点是结构体,想改变结构体的内容要用结构体指针
修改1
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* prev = NULL;
// 找尾
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
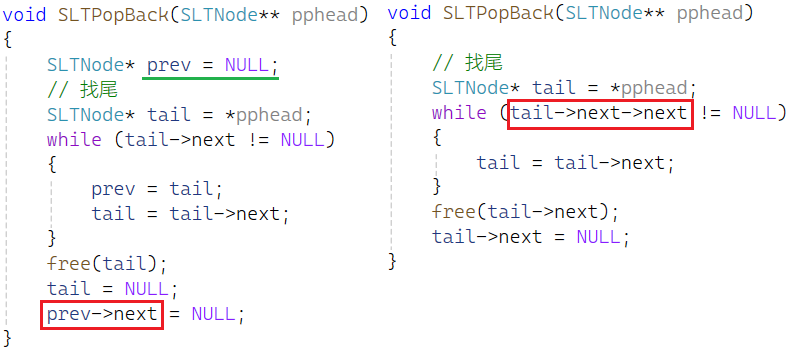
修改2:找的是倒数第2个
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
// 找尾
SLTNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}如果链表删到只剩1个元素,还删。
如果链表本身为空
void TestSList1()
{
SLTNode* plist = NULL;
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
}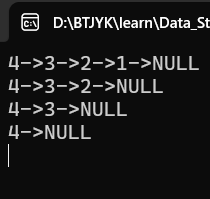
下面用红圈圈起来的是两组代码在只剩1个的情况下,分别有误的地方
修改:只有1个节点,直接 free,plist 置空。不用找尾节点
所以尾删如果用一级指针接收,phead 是 plist 的拷贝,对 phead 置空的改变不影响 plist,达不到置空 plist 的目的,plist 会变成野指针
void SLTPopBack(SLTNode** pphead)
{
//暴力检查
assert(pphead);
assert(*pphead);
//温柔检查
/*if (*pphead == NULL)
return;*/
if ((*pphead)->next == NULL) // 只有1个节点
{
free(*pphead);
*pphead = NULL;
}
else // 多个节点
{
/*SLTNode* prev = NULL;
// 找尾
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;*/
// 找尾
SLTNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}5.头删
不需要单独处理只有1个节点的情况
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* first = *pphead;
*pphead = first->next;
free(first);
first = NULL;
}6.查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}返回的是对应节点的指针,可以用 Find 实现修改
void TestSList2()
{
SLTNode* plist = NULL;
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
// 值为2的节点 *2
SLTNode* ret = SLTFind(plist, 2);
ret->data *= 2;
SLTPrint(plist);
}![]()
Find 主要是与下面的功能相配合
7. Find 查找的功能
我们这里不传下标,传结构体指针,与 C++ 贴合
(1)pos 之前插入
为啥不是在 pos 位置插入? 是把 pos 及以后的数据往后移,所以逻辑上说是之前插入
单链表不适合 pos 之前插入,只适合在后面插入,因为要找到 pos 前一个节点的地址,只能从头找
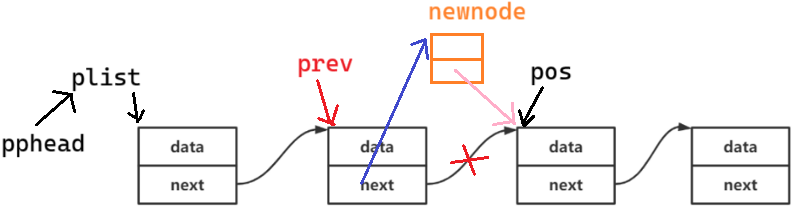
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else
{
// 找到 pos 的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos;
prev->next = newnode;
}
}如果 pos 不是链表里的指针,while 循环停不下来,最终出现空指针
这种情况怎么办 (甚至 pos 就是 NULL)?
说明传错了,断言,起码可以排除 NULL
(2)pos 位置删除
这里 *pphead 可以不断言,pos 间接断言了
pos 不为空,有节点,一定不为空链表
pos 位删除,要找到前一个位置。pos 是头,就是头删,先处理这个特殊情况
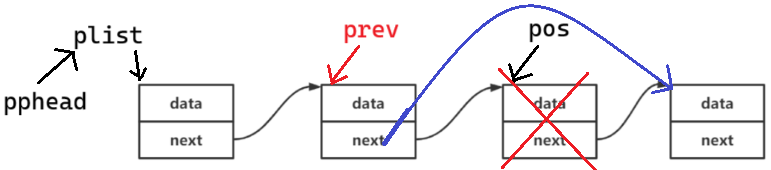
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
assert(*pphead);
if (*pphead == pos)
{
SLTPopFront(pphead);
}
else
{
// 找到 pos 的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
// pos = NULL;
}
}pos = NULL 没用,形参的修改不改变实参。要不要传二级指针呢?不。
为保持和其他的一致性,通常由用的人考虑置空
void TestSList4()
{
SLTNode* plist = NULL;
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
SLTNode* ret = SLTFind(plist, 2);
SLTErase(&plist, ret);
ret = NULL;
SLTPrint(plist);
}
(3)pos 之后插入
错误写法:会造成死循环
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
pos->next = newnode;
newnode->next = pos->next;
}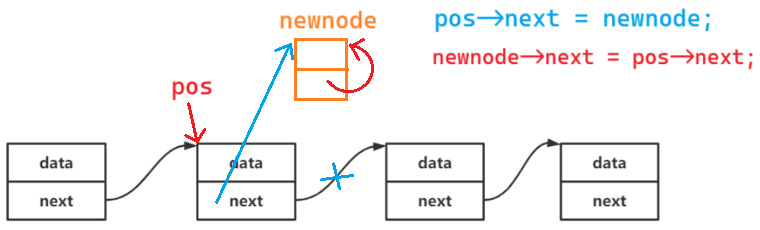
正确写法:先改后面
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}(4)pos位置后面删除
法1:pos->next = pos->next->next; 这里从右往左赋值 橙圈的内容丢了,所以要引入del
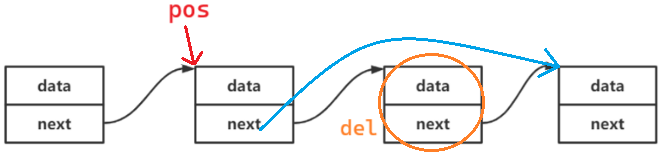
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;
pos->next = pos->next->next;
free(del);
del = NULL;
}法2:好理解
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}四.思维提升
单链表给了 pos 没给头指针
(1)插入
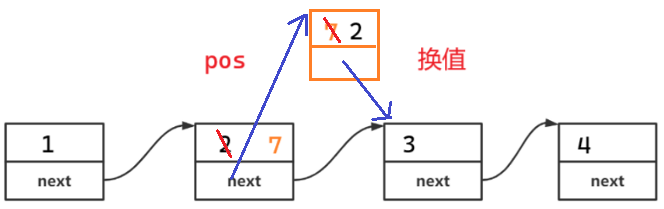
(2)删除
没有前一个位置,就删后一个。先换值,后删。但是不能删尾
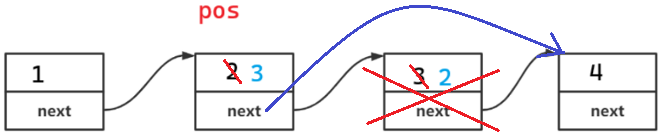
五.总结
1.传什么?
我们刚开始拿到链表,plist 是 NULL 。要插入新节点,要让 plist 指向新节点,会改变 plist ,所以要传指针的地址。
删除时,总会删到空,这时要将 plist 置为 NULL ,也改变 plist ,所以也传指针的地址
如果不需要修改头指针的链接,就传一级指针
2.要不要断言?
断言可以排出明显的错误,避免调试耗时。一定不能为空,就断言
(1)打印、查找
问:是否要 assert 指针 phead 为空? (一级指针)
答:不要。空的 (没有数据) 的链表,顺序表都可以打印、查找。链表为空时,phead == NULL,断言直接终止程序不合适。
顺序表,链表结构不一样,不能一概而论。
phead 是指向第一个存有数据的节点,链表为空时,phead == NULL
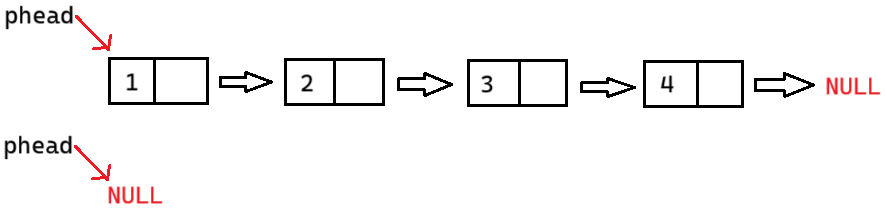
顺序表的打印
void SLPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}指针 ps 指向结构体 SL ,顺序表的数据不是存储在结构体上。而是存储在结构体里的一个指针 a 指向的空间。即使顺序表里没有数据,ps 指向的结构体也是必须要有的。ps->a 是否为空也不重要,到底有没有数据,取决于 ps->size 是否为 0
所以对顺序表而言,指针就不能为空
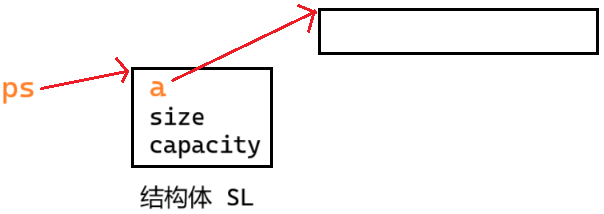
总结:不要看到指针上来就断言
(2)pphead
要,pphead 不能为空。为什么?
pphead 是 plist 的地址。plist 是指针变量,值有可能是空,地址一定不为空
(3)*pphead
*pphead 就是 plist ,是看是否为空 (二级指针)
要不要断言 *pphead 取决于函数是否包容空链表的情况
先 assert ( pphead ) 后 assert ( *pphead ) 如果反了,先 * ,再检查,有啥用?
空链表能插入,不断言;不能删,要断言。
六.整体代码
SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
void SLTPrint(SLTNode* phead); // 打印链表
void SLTPushBack(SLTNode** pphead, SLTDataType x); // 尾插
void SLTPushFront(SLTNode** pphead, SLTDataType x); // 头插
void SLTPopBack(SLTNode** pphead); // 尾删
void SLTPopFront(SLTNode** pphead); // 头删
SLTNode* SLTFind(SLTNode* phead, SLTDataType x); // 查找
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x); // pos之前插入
void SLTErase(SLTNode** pphead, SLTNode* pos); // pos位置删除
void SLTInsertAfter(SLTNode* pos, SLTDataType x); // pos之后插入
void SLTEraseAfter(SLTNode* pos); // pos位置后面删除SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "SList.h"
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
//while (cur->next != NULL) 错误写法!!!
//while(cur != NULL)
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
//cur++; 错误写法!!!
}
printf("NULL\n");
}
// 搞新节点,并初始化
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
// 初始化
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySLTNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
// 找尾
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SLTPopBack(SLTNode** pphead)
{
//暴力检查
assert(pphead);
assert(*pphead);
//温柔检查
/*if (*pphead == NULL)
return;*/
if ((*pphead)->next == NULL) // 只有1个节点
{
free(*pphead);
*pphead = NULL;
}
else // 多个节点
{
/*SLTNode* prev = NULL;
// 找尾
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;*/
// 找尾
SLTNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* first = *pphead;
*pphead = first->next;
free(first);
first = NULL;
}
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else
{
// 找到 pos 的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos;
prev->next = newnode;
}
}
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
assert(*pphead);
if (*pphead == pos)
{
SLTPopFront(pphead);
}
else
{
// 找到 pos 的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
// pos = NULL;
}
}
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
//SLTNode* del = pos->next;
//pos->next = pos->next->next;
//free(del);
//del = NULL;
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}本篇的分享就到这里了,感谢观看,如果对你有帮助,别忘了点赞+收藏+关注。
小编会以自己学习过程中遇到的问题为素材,持续为您推送文章