首先来看下TNDADATASET:
随便打开一个文件简单看下如下所示:
可以大概推测出来,这里面不同维度的数据集应该是由不同的穿戴式传感器采集得到的,最后一列的class表示的是当前的行为类型。
在我之前的博文里面已经做过了相关的工作了,如下:
《人体行为姿势识别数据集WISDM实践》
《UCI行为识别——Activity recognition with healthy older people using a batteryless wearable sensor Data Set》
所以这里我就不再赘述相关的背景内容性质的东西了,参考前面的文章就懂得这里应该如何来处理数据集了,首先是数据集加载解析处理:
def loadData(path):
"""
加载解析数据
"""
all_subject_data = []
for i in os.listdir(path):
subject_path = path + i
subject_data = pd.read_csv(subject_path)
subject_data.drop(
index=list(subject_data[subject_data["class"] <= 3].index), inplace=True
)
all_subject_data.append(subject_data)
all_subject_data = pd.concat(all_subject_data, axis=0)
all_subject_data.drop(
index=list(all_subject_data[all_subject_data["class"] == 0].index), inplace=True
)
X = all_subject_data[
[
"wri_Acc_X",
"wri_Acc_Y",
"wri_Acc_Z",
"wri_Gyr_X",
"wri_Gyr_Y",
"wri_Gyr_Z",
"wri_Mag_X",
"wri_Mag_Y",
"wri_Mag_Z",
"ank_Acc_X",
"ank_Acc_Y",
"ank_Acc_Z",
"ank_Gyr_X",
"ank_Gyr_Y",
"ank_Gyr_Z",
"ank_Mag_X",
"ank_Mag_Y",
"ank_Mag_Z",
"bac_Acc_X",
"bac_Acc_Y",
"bac_Acc_Z",
"bac_Gyr_X",
"bac_Gyr_Y",
"bac_Gyr_Z",
"bac_Mag_X",
"bac_Mag_Y",
"bac_Mag_Z",
]
]
y = all_subject_data["class"]
return X, y因为原始数据集中类别不均衡的存在,这里我丢掉了1 2 3这几种类别的行为动作,保留了4 5 6 7 8这五种行为动作的数据。
当然了也是可以全部保留的,本质都是一个多分类的问题。
接下来是特征提取部分,这里我们主要实现了包括:李雅普诺夫指数、递归图特征、庞加莱图特征、拓扑特征、近似熵特征、样本熵特征、模糊熵特征等在内的众多特征提取计算方法,后期可以综合使用。
这里以李雅普诺夫指数为例,看下对应的核心特征提取实现如下:
def lypnf_feature(data):
"""
李雅普诺夫指数 nolds库
"""
featuress = []
for j in tqdm(range(data.shape[0])):
fea = []
for i in range(data.shape[2]):
data_ = data[j, :, i]
feature = nolds.lyap_e(data_)
fea = np.hstack((fea, feature))
if j == 0:
featuress = np.concatenate((featuress, fea))
else:
featuress = np.vstack((featuress, fea))
return featuress
整体特征工程融合提取存储实现如下:
def buildFeature(dataDir="./TNDADATASET/"):
"""
特征工程
"""
data, label = load_data(dataDir)
data_processed, label_processed = data_preprocesssing(data, label, 128, 64)
# 特征提取
in_data_rec = rec_feature(data_processed)
print("in_data_rec shape:", in_data_rec.shape)
in_data_poincare = poincare_feature(data_processed)
print("in_data_poincare shape:", in_data_poincare.shape)
in_data_topo = topo_feature(data_processed, 5, 5)
print("in_data_topo shape:", in_data_topo.shape)
in_data_lypnf = lypnf_feature(data_processed)
print("in_data_lypnf shape:", in_data_lypnf.shape)
m = 2
in_data_apx = apx_feature(data_processed, m)
print("in_data_apx shape:", in_data_apx.shape)
m, n = 2, 2
in_data_fuz = fuz_feature(data_processed, m, n)
print("in_data_fuz shape:", in_data_fuz.shape)
m = 1
in_data_samp = samp_feature(data_processed, m)
print("in_data_samp shape:", in_data_samp.shape)
feature = {}
feature["rec_feature"] = in_data_rec.tolist()
feature["poincare_feature"] = in_data_poincare.tolist()
feature["topo_feature"] = in_data_topo.tolist()
feature["lypnf_feature"] = in_data_lypnf.tolist()
feature["apx_feature"] = in_data_apx.tolist()
feature["fuz_feature"] = in_data_fuz.tolist()
feature["samp_feature"] = in_data_samp.tolist()
feature["label"] = label_processed.tolist()
with open("feature.json", "w") as f:
f.write(json.dumps(feature))
sample_num = in_data_rec.shape[0]
rec = in_data_rec.tolist()
poincare = in_data_poincare.tolist()
topo = in_data_topo.tolist()
lypnf = in_data_lypnf.tolist()
apx = in_data_apx.tolist()
fuz = in_data_fuz.tolist()
samp = in_data_samp.tolist()
labels = label_processed.tolist()
result = []
for i in range(sample_num):
one_vec = rec[i] + poincare[i] + topo[i] + lypnf[i] + apx[i] + fuz[i] + samp[i]
one_label = labels[i]
one_vec.append(one_label)
result.append(one_vec)
print("result_shape: ", np.array(result).shape)
with open("allfeature.json", "w") as f:
f.write(json.dumps(result))执行耗时较长,输出如下:

得到所需的特征数据之后就可以构建模型来进行训练测试计算了。
这里的机器学习模型主要是基于sklearn库来进行快速地搭建使用,主要选择了:LR、RF、GBDT、SVM这四种经典的模型进行试验对比分析,如下所示:
以LR模型为例,看下核心完整构建流程实现如下:
def lrModel(data='feature.json',rationum=0.30,model_path='lr.model'):
'''
逻辑回归模型
'''
with open(data) as f:
data_list=json.load(f)
x_list,y_list=[],[]
for i in range(len(data_list)):
y_list.append(data_list[i][-1])
x_list.append(data_list[i][:-1])
label=list(set(y_list))
print('y_list: ',label)
X_train,X_test,y_train,y_test=splitData(x_list, y_list,ratio=rationum)
model=LogisticRegression()
model=DecisionTreeClassifier()
model.fit(X_train,y_train)
#预测、分析
y_pred=model.predict(X_test).tolist()
plotConfusionMatrix(y_test,y_pred,label,save_path=saveDir+'LR.png')
#计算模型在测试集上的得分
accuracy=model.score(X_test,y_test)
print('logisticRegressionModel model_score: ',accuracy)
Precision,Recall,F1=calThree(y_test,y_pred)
saveModel(model,save_path=model_path)
result={}
result['accuracy'],result['F_value']=accuracy,F1
result['precision'],result['recall']=Precision,Recall
print('type: ', type(y_test), type(y_pred))
result['y_true'],result['y_pred']=y_test,y_pred
return result看下对比混淆矩阵,如下所示:
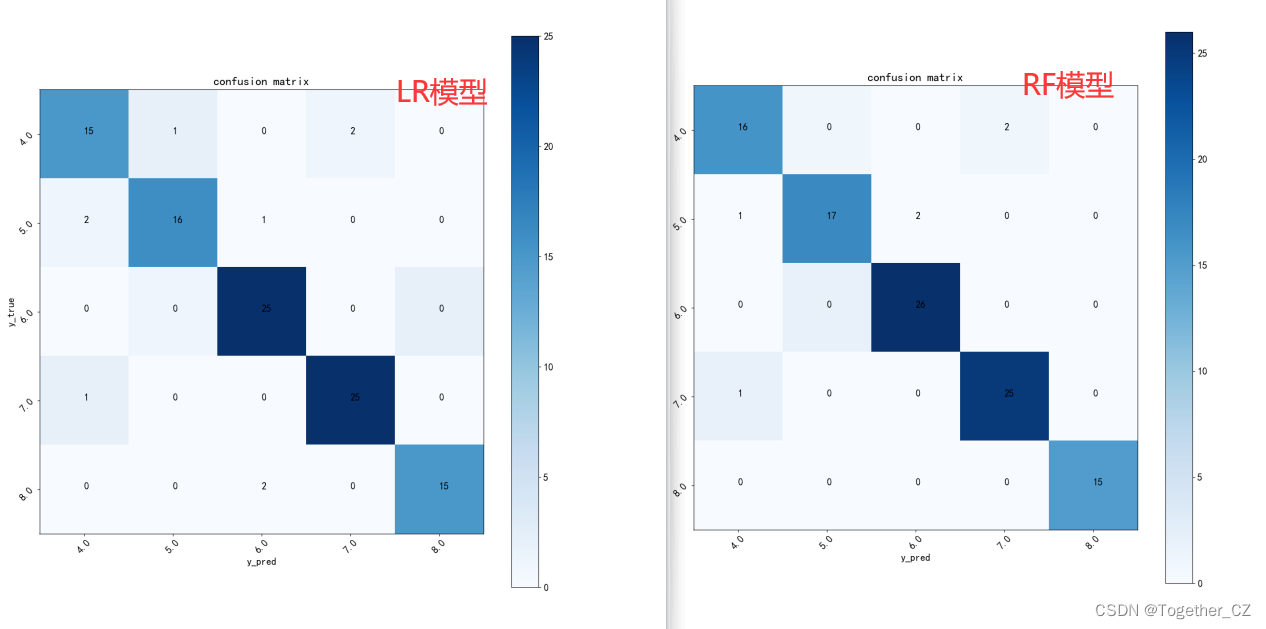

可以看到:四种不同的模型整体的效果都是很不错的。
之后为了对比深度学习模型与机器学习模型的优劣,我又依次开发了:LSTM、CNN-LSTM、BILSTM三种模型库,时间问题就不再一一解释了,直接看最终的结果:
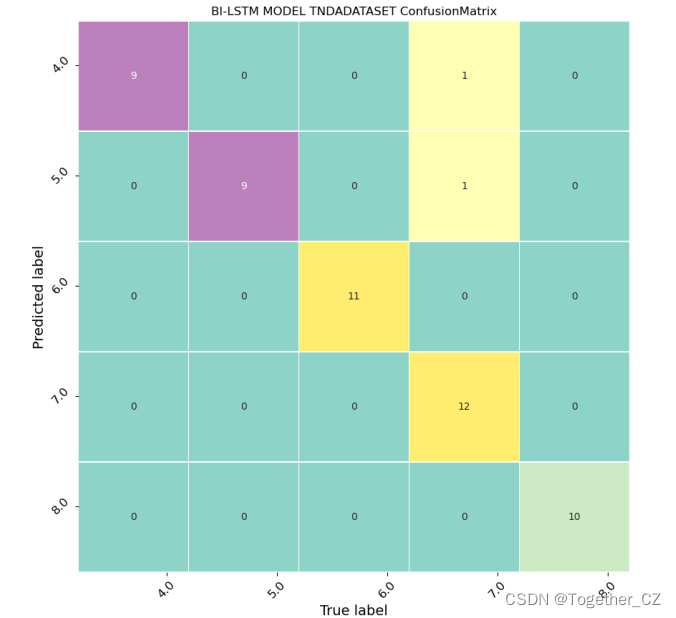
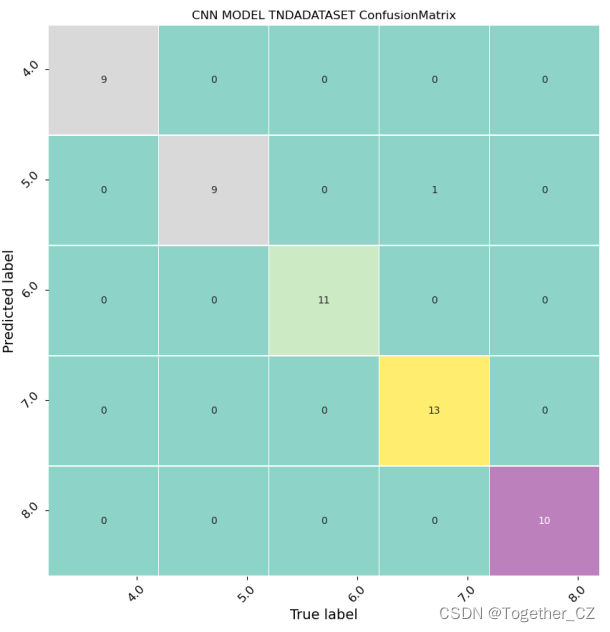

















![[XCTF]red_green(难度2)](https://img-blog.csdnimg.cn/c16ebdb1d3f940418e6bee637673b192.jpeg)
