(清库存)
获取图片 重命名 帧差法
- 爬虫获取图片
- 文件重命名
- 帧差法获取关键帧
爬虫获取图片
# 图片在当前目录下生成
import requests
import re
num = 0
numPicture = 0
file = ''
List = []
def dowmloadPicture(html, keyword):
global num
# t =0
pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 先利用正则表达式找到图片url
print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
for each in pic_url:
print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
try:
if each is not None:
pic = requests.get(each, timeout=7)
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
else:
string = './' + keyword + '_' + str(num) + '.jpg' # 可改成绝对地址
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
num += 1
# if num >= numPicture:
# return
if __name__ == '__main__': # 主函数入口
header = {'content-type': 'application/json','User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
word = input("请输入搜索关键词: ")
num1 = 0
while 1:
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
r = requests.get(url + str(num1), headers=header, allow_redirects=False)
r.encoding = 'utf-8'
dowmloadPicture(r.text, word)
num1 = num1+20
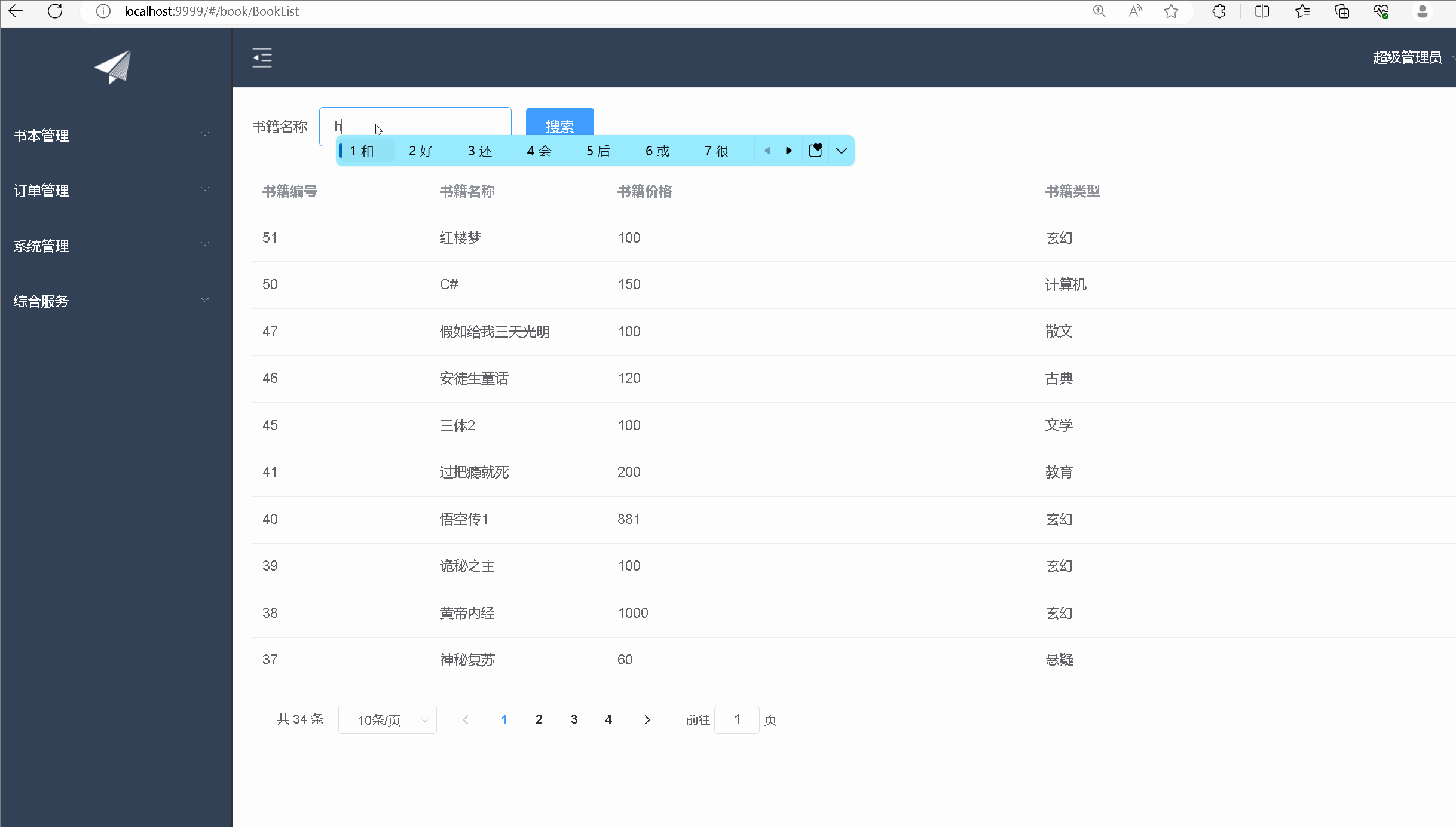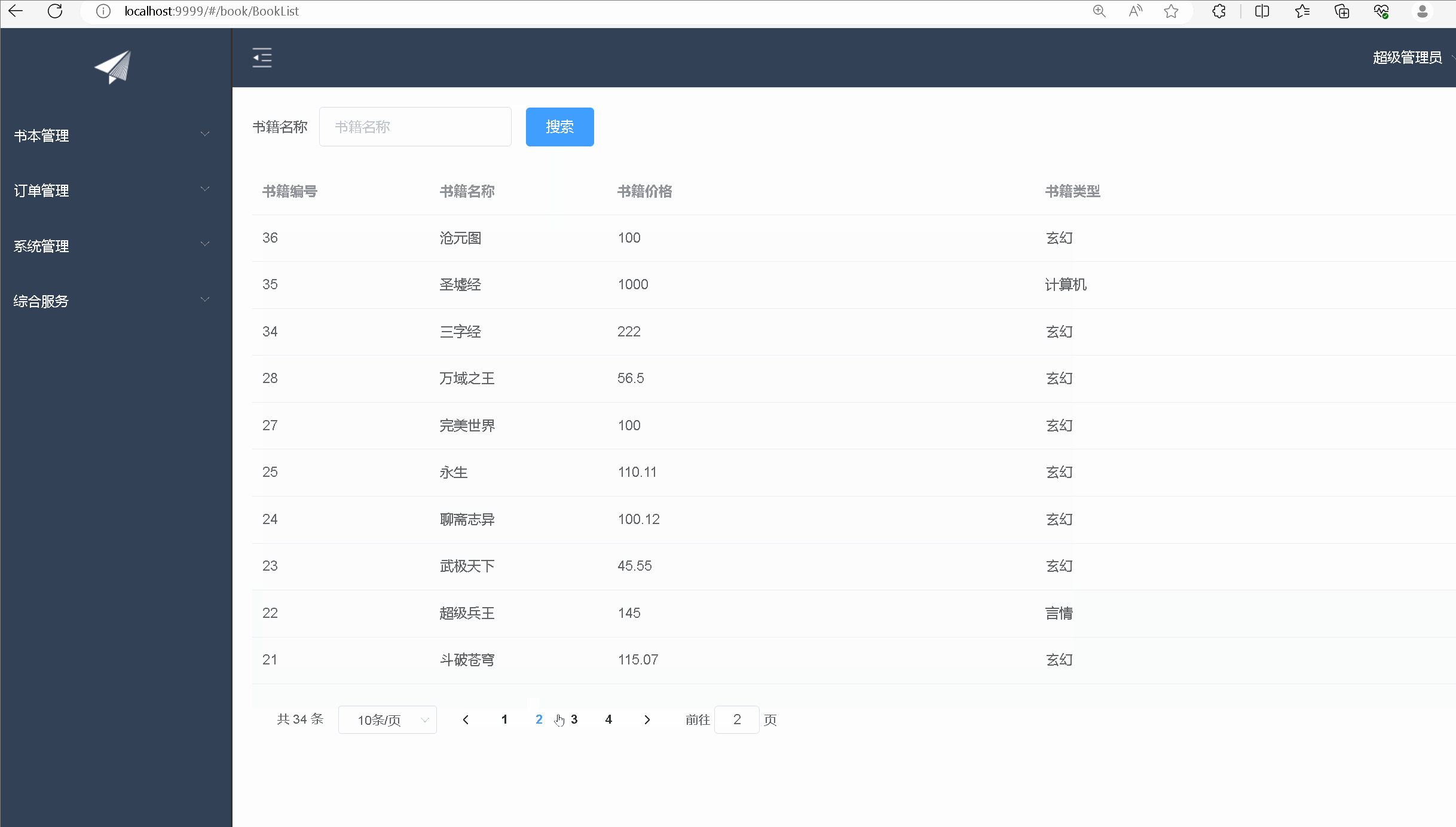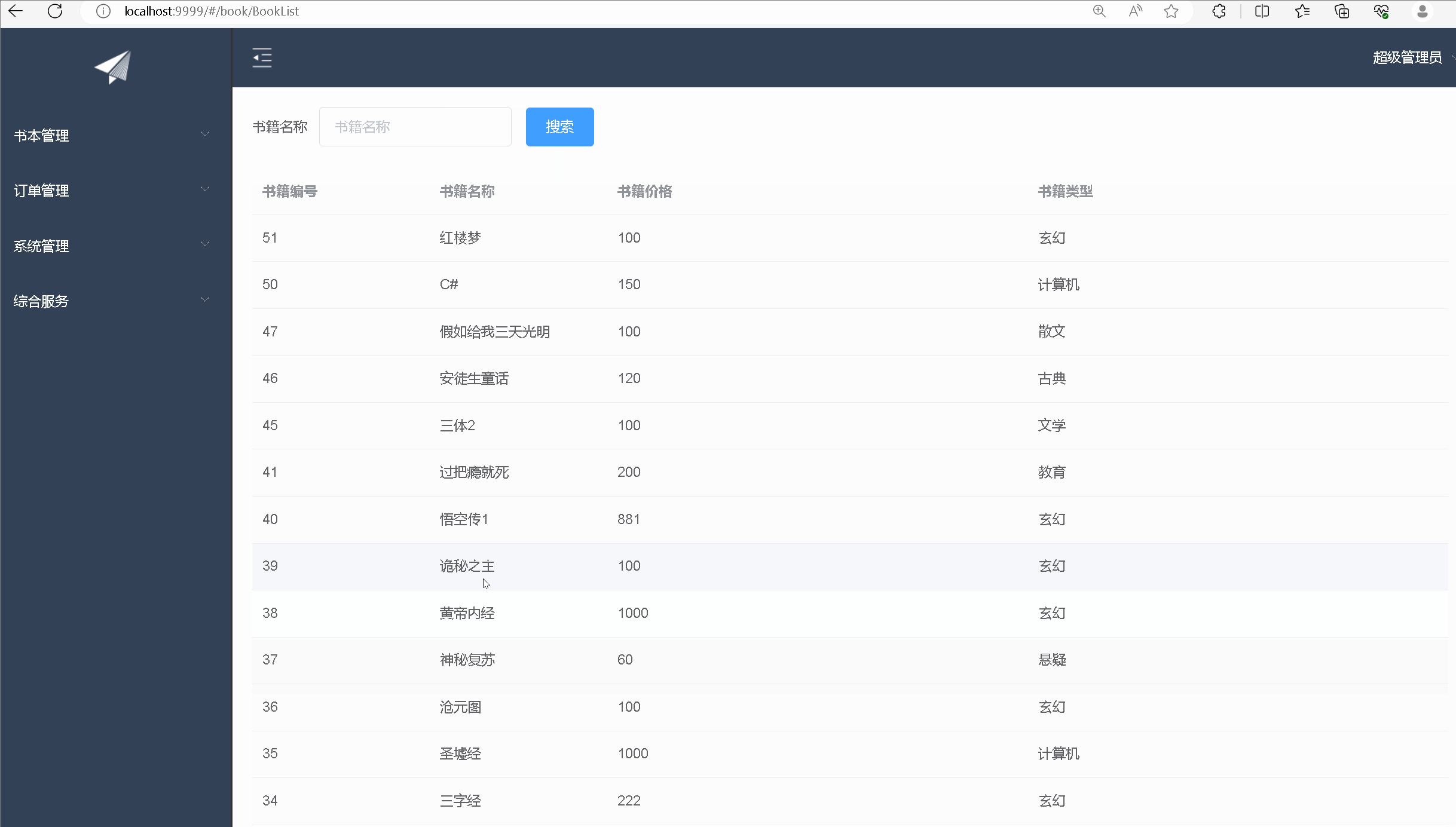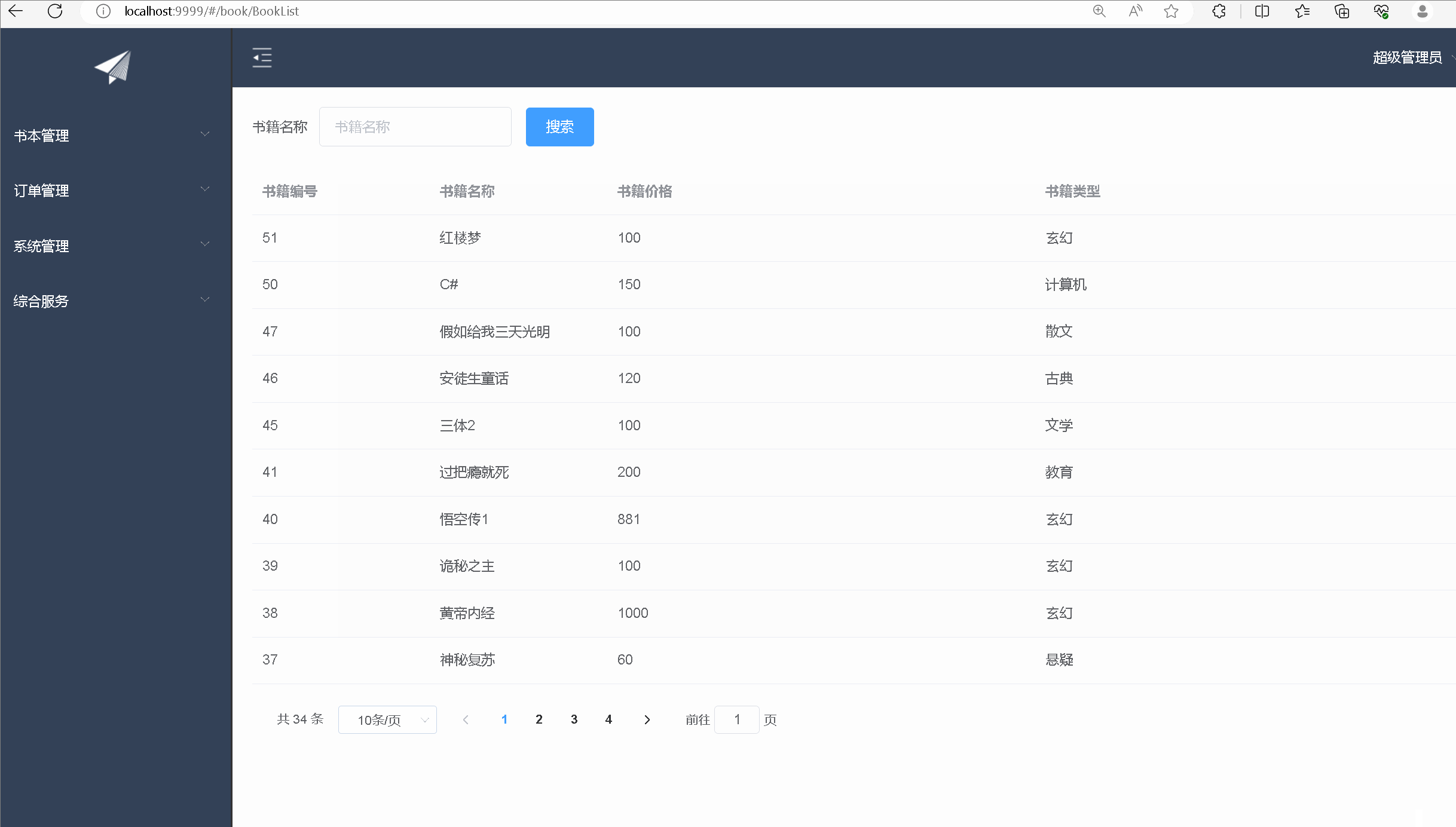
文件重命名
图片在images文件夹内
# ######################最终版##################### #
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = './images/' # 表示需要命名处理的文件夹
def rename(self):
filelist = os.listdir(self.path) # 获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
i = 1 # 表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其
# 他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), 'pachong_' + str(i) + '.jpg') # 处理后的格式也为jpg格式的,当然这里可以改成png格式
# dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg') 这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
帧差法获取关键帧

下载的文件夹在bilibili
帧差法 结果在bilibili_result
# -*- coding: utf-8 -*-
import cv2
import os
import time
import operator # 内置操作符函数接口(后面排序用到)
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import argrelextrema # 极值点
def smooth(x, window_len=13, window='hanning'):
"""使用具有所需大小的窗口使数据平滑。
"""
print(len(x), window_len)
s = np.r_[2 * x[0] - x[window_len:1:-1],
x, 2 * x[-1] - x[-1:-window_len:-1]]
# print(len(s))
if window == 'flat': # moving average平移
w = np.ones(window_len, 'd')
else:
w = getattr(np, window)(window_len)
y = np.convolve(w / w.sum(), s, mode='same')
return y[window_len - 1:-window_len + 1]
class Frame:
"""用于保存有关每个帧的信息
"""
def __init__(self, id, diff):
self.id = id
self.diff = diff
def __lt__(self, other):
if self.id == other.id:
return self.id < other.id
return self.id < other.id
def __gt__(self, other):
return other.__lt__(self)
def __eq__(self, other):
return self.id == other.id and self.id == other.id
def __ne__(self, other):
return not self.__eq__(other)
def rel_change(a, b):
x = (b - a) / max(a, b)
print(x)
return x
def getEffectiveFrame(videopath, dirfile):
# 如果文件目录不存在则创建目录
if not os.path.exists(dirfile):
os.makedirs(dirfile)
(filepath, tempfilename) = os.path.split(videopath) # 分离路径和文件名
(filename, extension) = os.path.splitext(tempfilename) # 区分文件的名字和后缀
# Setting fixed threshold criteria设置固定阈值标准
USE_THRESH = False
# fixed threshold value固定阈值
THRESH = 0.6
# Setting fixed threshold criteria设置固定阈值标准
USE_TOP_ORDER = False
# Setting local maxima criteria设置局部最大值标准
USE_LOCAL_MAXIMA = True
# Number of top sorted frames排名最高的帧数
NUM_TOP_FRAMES = 50
# smoothing window size平滑窗口大小
len_window = int(10) # 50
print("target video :" + videopath)
print("frame save directory: " + dirfile)
# load video and compute diff between frames加载视频并计算帧之间的差异
cap = cv2.VideoCapture(str(videopath))
curr_frame = None
prev_frame = None
frame_diffs = []
frames = []
success, frame = cap.read()
i = 0
while (success):
luv = cv2.cvtColor(frame, cv2.COLOR_BGR2LUV)
curr_frame = luv
if curr_frame is not None and prev_frame is not None:
# logic here
diff = cv2.absdiff(curr_frame, prev_frame) # 获取差分图
diff_sum = np.sum(diff)
diff_sum_mean = diff_sum / (diff.shape[0] * diff.shape[1]) # 平均帧
frame_diffs.append(diff_sum_mean)
frame = Frame(i, diff_sum_mean)
frames.append(frame)
prev_frame = curr_frame
i = i + 1
success, frame = cap.read()
cap.release()
# compute keyframe
keyframe_id_set = set()
if USE_TOP_ORDER:
# sort the list in descending order以降序对列表进行排序
frames.sort(key=operator.attrgetter("diff"), reverse=True) # 排序operator.attrgetter
for keyframe in frames[:NUM_TOP_FRAMES]:
keyframe_id_set.add(keyframe.id)
if USE_THRESH:
print("Using Threshold") # 使用阈值
for i in range(1, len(frames)):
if (rel_change(np.float(frames[i - 1].diff), np.float(frames[i].diff)) >= THRESH):
keyframe_id_set.add(frames[i].id)
if USE_LOCAL_MAXIMA:
print("Using Local Maxima") # 使用局部极大值
diff_array = np.array(frame_diffs)
sm_diff_array = smooth(diff_array, len_window) # 平滑
frame_indexes = np.asarray(argrelextrema(sm_diff_array, np.greater))[0] # 找极值
for i in frame_indexes:
keyframe_id_set.add(frames[i - 1].id) # 记录极值帧数
plt.figure(figsize=(40, 20))
plt.locator_params("x", nbins=100)
# stem 绘制离散函数,polt是连续函数
plt.stem(sm_diff_array, linefmt='-', markerfmt='o', basefmt='--', label='sm_diff_array')
plt.savefig(dirfile + filename + '_plot.png')
# save all keyframes as image将所有关键帧另存为图像
cap = cv2.VideoCapture(str(videopath))
curr_frame = None
keyframes = []
success, frame = cap.read()
idx = 0
while (success):
if idx in keyframe_id_set:
name = filename + '_' + str(idx) + ".jpg"
cv2.imwrite(dirfile + name, frame)
keyframe_id_set.remove(idx)
idx = idx + 1
success, frame = cap.read()
cap.release()
if __name__ == "__main__":
print("[INFO]Effective Frame.")
start = time.time()
videos_path = 'bilibili/'
outfile = 'bilibili_result/' # 处理完的帧
video_files = [os.path.join(videos_path, video_file) for video_file in os.listdir(videos_path)]
#
for video_file in video_files:
getEffectiveFrame(video_file, outfile)
print("[INFO]Extract Result time: ", time.time() - start)



![[RCTF2015]EasySQL 二次注入 regexp指定字段 reverse逆序输出](https://img-blog.csdnimg.cn/ca94ca45f8ab42d9a462c2af77dc0ecd.png)