测试环境:cuda11.3 pytorch1.11 rtx3090 wsl2 ubuntu20.04
踩了很多坑,网上很多博主的代码根本跑不通,自己去github仓库复现修改的
网上博主的代码日常出现cpu,gpu混合,或许是人家分布式训练了,哈哈哈
下面上干货吧,宝子们点个关注,点个赞,没有废话
yolov8_yaml文件修改(目标检测就修改
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 9, SwinV2_CSPB, [512, 512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, SwinV2_CSPB, [1024, 1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
在nn/modules/block.py最下面加入
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from .conv import Conv, DWConv, GhostConv, LightConv, RepConv
from .transformer import TransformerBlock
import numpy as np
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# print(attn.dtype, v.dtype)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
# print(attn.dtype, v.dtype)
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# print(attn.dtype, v.dtype)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
# print(attn.dtype, v.dtype)
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class WindowAttention_v2(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,
pretrained_window_size=[0, 0]):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.pretrained_window_size = pretrained_window_size
self.num_heads = num_heads
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))), requires_grad=True)
# mlp to generate continuous relative position bias
self.cpb_mlp = nn.Sequential(nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False))
# get relative_coords_table
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
relative_coords_table = torch.stack(
torch.meshgrid([relative_coords_h,
relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
relative_coords_table *= 8 # normalize to -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / np.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(dim))
self.v_bias = nn.Parameter(torch.zeros(dim))
else:
self.q_bias = None
self.v_bias = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# cosine attention
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
max_tensor = torch.log(torch.tensor(1. / 0.01)).to(self.logit_scale.device)
logit_scale = torch.clamp(self.logit_scale, max=max_tensor).exp()
attn = attn * logit_scale
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, ' \
f'pretrained_window_size={self.pretrained_window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class Mlp_v2(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
# add 2 functions
class SwinTransformerLayer_v2(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm, pretrained_window_size=0):
super().__init__()
self.dim = dim
# self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# if min(self.input_resolution) <= self.window_size:
# # if window size is larger than input resolution, we don't partition windows
# self.shift_size = 0
# self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention_v2(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop,
pretrained_window_size=(pretrained_window_size, pretrained_window_size))
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_v2(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# reshape x[b c h w] to x[b l c]
_, _, H_, W_ = x.shape
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size != 0 or W_ % self.window_size != 0:
Padding = True
# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
# print('2', x.shape)
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c
# create mask from init to forward
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(self.norm1(x))
# FFN
x = x + self.drop_path(self.norm2(self.mlp(x)))
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h w
if Padding:
x = x[:, :, :H_, :W_] # reverse padding
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class SwinTransformer2Block(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=7):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer_v2(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i
in range(num_layers)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x
class SwinV2_CSPB(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(SwinV2_CSPB, self).__init__()
c_ = int(c2) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformer2Block(c_, c_, num_heads, n)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
x1 = self.cv1(x)
y1 = self.m(x1)
y2 = self.cv2(x1)
return self.cv3(torch.cat((y1, y2), dim=1))随后在这个目录的init.py里面把你的新的东西放进去
from .block import (C1, C2, C3, C3TR, DFL, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, GhostBottleneck,
HGBlock, HGStem, Proto, RepC3,GAM_Attention,ResBlock_CBAM,GCT,C3STR,SwinV2_CSPB)
from .conv import (CBAM, ChannelAttention, Concat, Conv, Conv2, ConvTranspose, DWConv, DWConvTranspose2d, Focus,
GhostConv, LightConv, RepConv, SpatialAttention)
from .head import Classify, Detect, Pose, RTDETRDecoder, Segment
from .transformer import (AIFI, MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer, LayerNorm2d,
MLPBlock, MSDeformAttn, TransformerBlock, TransformerEncoderLayer, TransformerLayer)
__all__ = ('Conv', 'Conv2', 'LightConv', 'RepConv', 'DWConv', 'DWConvTranspose2d', 'ConvTranspose', 'Focus',
'GhostConv', 'ChannelAttention', 'SpatialAttention', 'CBAM', 'Concat', 'TransformerLayer',
'TransformerBlock', 'MLPBlock', 'LayerNorm2d', 'DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3',
'C2f', 'C3x', 'C3TR', 'C3Ghost', 'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'Detect',
'Segment', 'Pose', 'Classify', 'TransformerEncoderLayer', 'RepC3', 'RTDETRDecoder', 'AIFI',
'DeformableTransformerDecoder', 'DeformableTransformerDecoderLayer', 'MSDeformAttn', 'MLP','ResBlock_CBAM','CBAM','GAM_Attention',
'GCT','C3STR','SwinV2_CSPB')然后去task.py
在导包那里,把这个导入进去
rom ultralytics.nn.modules import (AIFI, C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x,
Classify, Concat, Conv, Conv2, ConvTranspose, Detect, DWConv, DWConvTranspose2d,
Focus, GhostBottleneck, GhostConv, HGBlock, HGStem, Pose, RepC3, RepConv,
RTDETRDecoder ,Segment,CBAM,GAM_Attention,ResBlock_CBAM,GCT,C3STR,SwinV2_CSPB)然后同样在task.py里面搜索if m in
把你的新的swin模块放进去
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3
,CBAM , GAM_Attention ,ResBlock_CBAM,GCT,C3STR,SwinV2_CSPB):最后
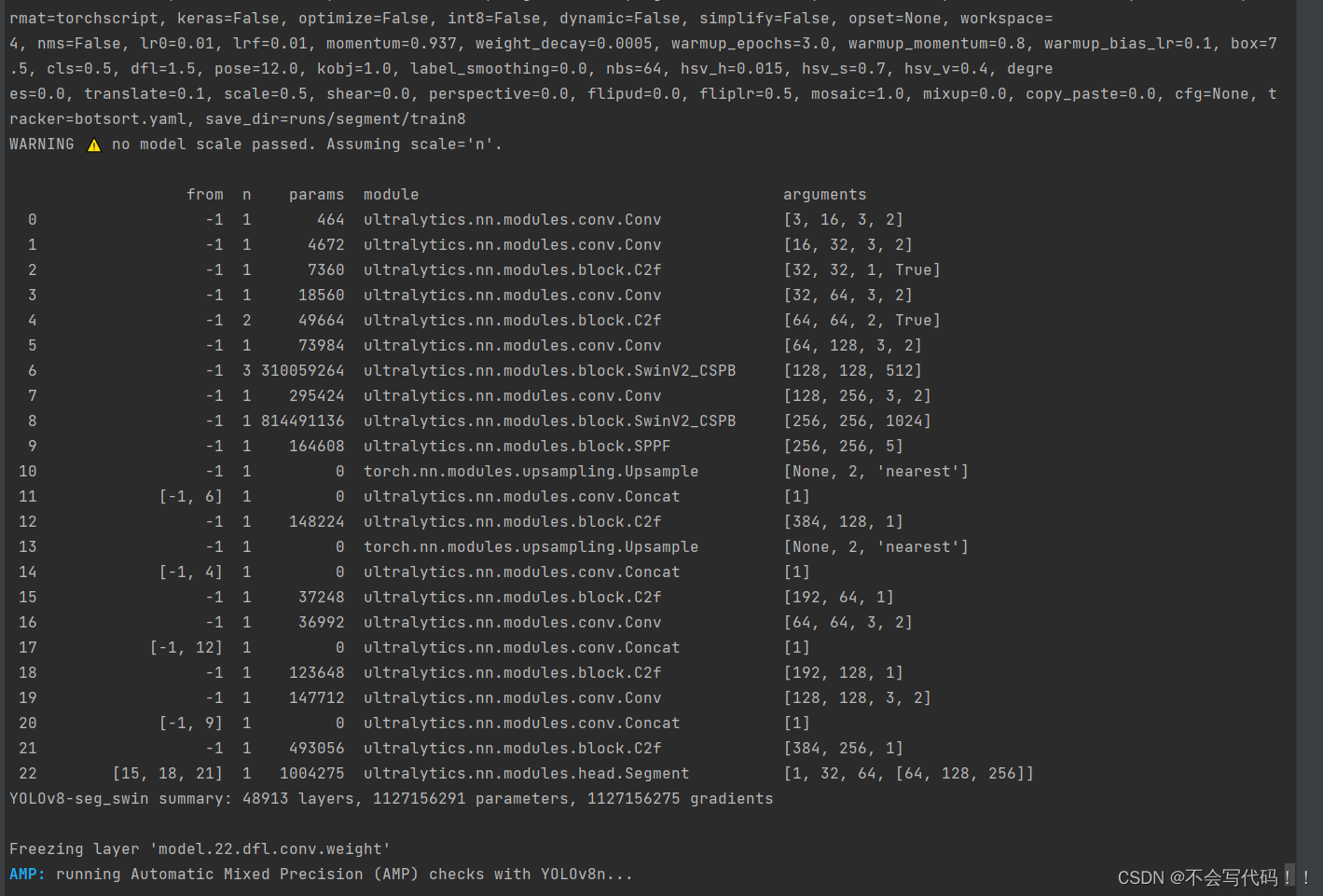
命令行:python setup.py install 注册
命令行:你的训练命令

![[RCTF2015]EasySQL 二次注入 regexp指定字段 reverse逆序输出](https://img-blog.csdnimg.cn/ca94ca45f8ab42d9a462c2af77dc0ecd.png)