【数据结构】&&【C++】哈希表的模拟实现(哈希桶)
- 一.哈希桶概念
- 二.哈希桶模拟实现
- ①.哈希结点的定义
- ②.数据类型适配
- ③.哈希表的插入
- ④.哈希表的查找
- ⑤.哈希表的删除
- ⑥.哈希表的析构
- 三.完整代码
一.哈希桶概念
哈希桶这种形式的方法本质上是开散列法,又叫链地址法。
首先对数据(关键码值集合)使用除留余数法,计算出对应的哈希地址,具有相同的地址的数据就归于同一个子集,每个子集称为一个桶,每个桶里的元素就用单链表的形式链接到一起。每个链表的头部存储在哈希表里。
除留余数法
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,我们通常直接让p的值为哈希表的长度。
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
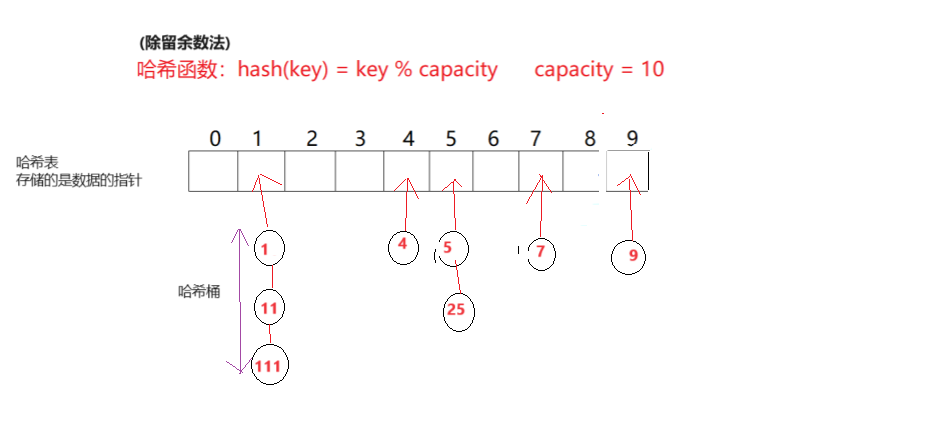

所以我们可以注意到哈希桶里的元素都是那些发生哈希冲突的元素。
我们要在模拟实现之前,分析一下哈希表的结构是如何的,首先哈希表底层存储的是一个数组指针,数组里存的都是指向哈希结点的指针。还需要存一个计算表里数据个数的变量。用来计算负载因子的大小。(负载因子就是表里数据的个数除以表的大小)
哈希结点里存的就是数据了,不过除了存储数据外,还应该存一个可以指向下一个位置的指针,用来链接哈希冲突的元素。
二.哈希桶模拟实现
①.哈希结点的定义
哈希结点里存储的是数据和指向下一个结点的指针。
存储的数据可以是pair<K,V>类型的数据。
//哈希结点
template <class K,class V>
struct HashNode
{
pair<K, V> _kv;
//存储的数据
HashNode<K, V>* _next;
//指向下一个结点的指针
HashNode(const pair<K,V> kv)
:_kv(kv)
,_next(nullptr)
{}
};
在插入之前我们要完成哈希表框架的搭建:首先给哈希表开辟10个大小的空间。
template<class K,class V >
//哈希表
class Hash_table
{
typedef HashNode<K, V> Node;
public:
Hash_table()
{
//构造
_table.resize(10, nullptr);
//首先开出十个空间,每个空间值为空
}
bool insert(const pair<K, V> _kv)
{
……………………
}
private:
//底层封装的是一个数组指针
//数组里的指针指向的都是哈希结点
vector<Node*> _table;
//底层还封装一个大小n表示实际表中的数据个数
size_t n=0;///用来计算负载因子
};
②.数据类型适配
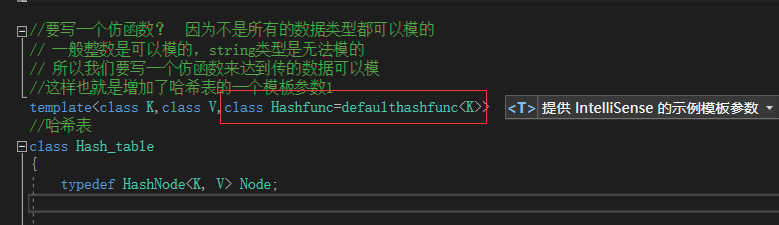
我们这里采用除留余数法来计算数据的哈希地址。也就是用数据取模表的大小,计算出对应的哈希地址。但问题是,这里的数据不一定是int类型啊,如果是string类型呢?我们知道只有数值类型才可以支持取模,其他类型是不支持取模的。那怎么处理呢?
通常这种情况,我们就需要使用仿函数来处理了。根据不同情况处理:
对于数值类型我们可以直接强制类型转换成size_t类型,这样做的好处就是对于负数我们也可以进行取模了。
template <class K>
struct defaulthashfunc//默认的仿函数可以让数据模
{
size_t operator()(const K& key)
{
return (size_t)key;
//将key强行类型转化
//这样作的意义:可以负数也可以进行模了
}
};
如果对于string类型,那我们可以将string类型的字符全部相加,这样就会得到一个数值。不过这样可能会存在大量的冲突,可能两个不同的字符串,最后得到的数值是一样大的。所以为了减少冲突。又大佬依据大量的数据处理,得出,每个字符都乘数131后再相加,这样就可以大大减少冲突概率。
template <class string>
struct defaulthashfunc
{
size_t operator()(const string& str)
{
//为了减少冲突,我们将字符串的每个字符的值相加
size_t hash = 0;
for (auto& it : str)
{
hash *= 131;
hash += it;
}
return hash;
}
};
然后我们再使用一个模板的特化:
就可以根据传的模板类型来调用不同的仿函数了。
template <>
//模板的特化,当数据类型是int的时候就默认使用defaulthashfunc<int>,当数据类型是string类型时,就默认使用defaulthashfunc<string>
struct defaulthashfunc<string>
{
size_t operator()(const string& str)
{
//为了减少冲突,我们将字符串的每个字符的值相加
size_t hash = 0;
for (auto& it : str)
{
hash *= 131;
hash += it;
}
return hash;
}
};
③.哈希表的插入
Ⅰ.将数据插入到哈希表中的逻辑很简单
第一步:根据除留余数法将数据对于的哈希地址求出来。
第二步:为插入的数据创建结点。
第三步:将创建好的新结点头插到哈希表里。
第四步:对应的n要++.
【问题】为什么是头插而不是尾插呢?
尾插也可以,但是尾插还需要找尾,头插直接插入到哈希表里即可,让新结点的尾部指向原来的新结点,而原来新结点的位置就变成了新结点。
size_t hashi = hf(_kv.first) % _table.size();
//计算哈希地址
Node* newnode = new Node(_kv);
//创建新结点
newnode->_next = _table[hashi];
_table[hashi] = newnode;
//将新结点头插到哈希表里
++n;
//对应的n++
Ⅱ.难的是哈希表的扩容逻辑
【问题】:为什么要扩容,为什么要控制扩容逻辑?
有人可能有些迷惑,为什么要扩容啊?我们底层使用的不是vector吗?vector不是会自动扩容吗?确实,vector会自动扩容,但我们不能使用vector的自动扩容。为什么呢?
原因2:如果我们不扩容,当数据很多时,就可能会发生很多冲突,一旦冲突多了(哈希桶很长),那么跟单链表有什么区别呢?
原因1:因为我们的数值都是按照哈希表的大小进行取模获取的地址的,一旦哈希表扩容后,那么原来冲突的数值就又可能不冲突了,原来不冲突的数值就可能冲突了。所以我们一旦扩容完,还需要对这些数值进行重新定位,重新进行哈希插入。
【问题】:那什么时候应该扩容呢?
当哈希桶里平均存储一个数据时就进行扩容,也就是当负载因子是1时就进行扩容。
Ⅲ.扩容逻辑
①当负载因子到达1时就进行扩容
②按照二倍扩容开空间,开辟一个新的哈希表。
③遍历旧表,将旧表上的结点全部拿下来,按照插入逻辑迁到新表上。
④最后遍历完后,将新表和旧表交换一下,这样数据就到旧表上了。
bool insert(const pair<K, V> _kv)
{
Hashfunc hf;
//仿函数可以使数据模
//在插入之前,确认一下表里是否已经有了这个值,如果有了就不用插入了 -->这个查找函数后面会写,这里直接先用
if (find(_kv.first))
{
return false;
}
//我们自己控制扩容逻辑,虽然vector会自己扩容,但我们要控制。因为扩容完,有的key会冲突有的值又不冲突了。
//如果不扩容,那么冲突多了就根单链表一样了
//当负载因子大约等于1时就要扩容,平均每个桶里有一个数据
if (n == _table.size())//负载因子=1
{
//异地扩容,重新开空间
size_t newSize = _table.size() * 2;
//2倍空间大小
vector<Node*> newtable;
newtable.resize(newSize, nullptr);
//不能再复用下面的方法,这样不好,因为就又重开空间,然后又要释放,
//我们应该将原来的结点拿过来使用
//所以我们遍历旧表,将旧表的结点拿过来,签到新表上
for (size_t i = 0; i < _table.size(); i++)
{
//扩容后,空间size变大了,有的数据就可能会存到不同的桶里了
//拿下来的结点要重新计算放进哪个位置
Node* cur = _table[i];
//cur只是哈希桶头结点,后面可能还有结点,所以需要将cur后面的结点全部拿走
//cur后面可能还有链接的结点
while (cur)
{
size_t hashi = hf(cur->_kv.first) % newtable.size();
//按照上面的插入逻辑
Node* next = cur->_next;
//记录一下当前结点后面的位置,不然后面就被覆盖了
//头插到新表
cur->_next = newtable[hashi];
//头插 这个结点的 接到插入结点的前面对吧
//那么next就接到newtavle[i]
newtable[hashi] = cur;
//往后走接着拿走
cur = next;
}
//当前桶里的结点被拿光后,就置为空
_table[i] = nullptr;
}
//这个新表就是我们想要的表,那么我们利用vector、的交换,让旧表和新表交换
_table.swap(newtable);
}
//插入逻辑
size_t hashi = hf(_kv.first) % _table.size();
Node* newnode = new Node(_kv);
newnode->_next = _table[hashi];
_table[hashi] = newnode;
//将新结点头插到哈希桶里
++n;
return true;
}
④.哈希表的查找
插入简单的很,就计算数值对应的哈希地址,看该哈希地址上是否有该值就可以了。不过由于哈希冲突,可能查找的值在哈希桶头结点的后面。所以需要遍历一下哈希桶。
Node* find(const K& key)
{
Hashfunc hf;
//仿函数,用来获取数据的数值大小
size_t hashi = hf(key)% _table.size();
Node* cur = _table[hashi];
//用来遍历哈希桶
while (cur)
{
if (cur->_kv.first == key)
return cur;
else
cur = cur->_next;
}
return nullptr;
}
⑤.哈希表的删除
删除的逻辑也很简单,就是找到key的位置,然后删除掉key所在的结点即可。那我们可不可以复用find函数来查找要删除的结点呢?
不能。因为删除逻辑需要找到所删除结点的前后位置,这样才可以删除结点,即让前面结点的next指向后面的结点。而find只找到要删除结点的位置,前后位置是找不到,所以不能直接使用,但我们可以使用其中的逻辑。
删除逻辑
①首先根据除留余数法计算数值的哈希地址。
②遍历所在的哈希桶,在遍历时,需要记录前面结点的位置。
③找到要删除结点后,就删除,没有找到就继续往后找,记录前面位置。
③注意要删除结点可能是头结点。
bool erase(const K& key)
{
Hashfunc hf;
//可以复用find吗?先用find找到key然后删除key呢?4
//不可以,因为删除一个结点需要找到这个结点的前面和后面的位置,但这里只有key的位置,所以不能直接复用find,但是复用其中的步骤
size_t hashi = hf(key) % _table.size();
Node* cur = _table[hashi];
Node* prev = nullptr;
while (cur)
{
if (cur->_kv.first == key)//找到要删除的结点后
{
//删除逻辑:将前面的结点的指针指向后面的前面
//还有一种可能cur就是桶里的第一个,那么就是头删了,prev就是nullptr
if (prev == nullptr)
{
_table[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
//每次先记录一下前面的结点位置
cur = cur->_next;
}
}
return false;
}
⑥.哈希表的析构
为什么要写析构呢?我们使用的不是vector吗?vector不是会自动调用析构函数吗?
确实,vector会调用析构函数,但要注意vector存储的数据指针类型,是自定义类型,没有默认构造,所以我们开辟的结点的那些空间,需要我们自己释放,不然无法释放。
最简单的就是遍历哈希桶即可,将每个结点都释放。
~Hash_table()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
//要先保存起来
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
三.完整代码
#pragma once
using namespace std;
#include <vector>
#include<iostream>
//哈希桶
//哈希结点
template <class K,class V>
struct HashNode
{
pair<K, V> _kv;
//存储的数据
HashNode<K, V>* _next;
//指向下一个结点的指针
HashNode(const pair<K,V> kv)
:_kv(kv)
,_next(nullptr)
{}
};
template <class K>
struct defaulthashfunc//默认的仿函数可以让数据模
{
size_t operator()(const K& key)
{
return (size_t)key;
//将key强行类型转化
//这样作的意义:可以负数也可以进行模了
}
};
template <>
//模板的特化,当数据类型是int的时候就默认使用defaulthashfunc<int>,当数据类型是string类型时,就默认使用defaulthashfunc<string>
struct defaulthashfunc<string>
{
size_t operator()(const string& str)
{
//为了减少冲突,我们将字符串的每个字符的值相加
size_t hash = 0;
for (auto& it : str)
{
hash *= 131;
hash += it;
}
return hash;
}
};
//要写一个仿函数? 因为不是所有的数据类型都可以模的
// 一般整数是可以模的,string类型是无法模的
// 所以我们要写一个仿函数来达到传的数据可以模
//这样也就是增加了哈希表的一个模板参数l
template<class K,class V,class Hashfunc=defaulthashfunc<K>>
//哈希表
class Hash_table
{
typedef HashNode<K, V> Node;
//哈希需要将写析构函数,虽然自定义类型vector会自动调用默认析构,但它里面的成员是内置类型,没有默认构造,
//所以需要我们自己析构每个结点
public:
~Hash_table()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
//要先保存起来
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
Hash_table()
{
//构造
_table.resize(10, nullptr);
//首先开出十个空间,每个空间值为空
}
bool insert(const pair<K, V> _kv)
{
Hashfunc hf;
//仿函数可以使数据模
//在插入之前,确认一下表里是否已经有了这个值,如果有了就不用插入了
if (find(_kv.first))
{
return false;
}
//我们自己控制扩容逻辑,虽然vector会自己扩容,但我们要控制。因为扩容完,有的key会冲突有的值又不冲突了。
//如果不扩容,那么冲突多了就根单链表一样了
//当负载因子大约等于1时就要扩容,平均每个桶里有一个数据
if (n == _table.size())
{
//异地扩容,重新开空间
size_t newSize = _table.size() * 2;
vector<Node*> newtable;
newtable.resize(newSize, nullptr);
//不能再复用下面的方法,这样不好,因为就又重开空间,然后又要释放,
//我们应该将原来的结点拿过来使用
//所以我们遍历旧表,将旧表的结点拿过来,签到新表上
for (size_t i = 0; i < _table.size(); i++)
{
//扩容后,空间size变大了,有的数据就可能会存到不同的桶里了
//拿下来的结点要重新计算放进哪个位置
Node* cur = _table[i];
//cur后面可能还有链接的结点
while (cur)
{
size_t hashi = hf(cur->_kv.first) % newtable.size();
Node* next = cur->_next;
//头插到新表
cur->_next = newtable[hashi];
//头插 这个结点的 接到插入结点的前面对吧
//那么next就接到newtavle[i]
newtable[hashi] = cur;
//往后走接着拿走
cur = next;
}
//当前桶里的结点被拿光后,就置为空
_table[i] = nullptr;
}
//这个新表就是我们想要的表,那么我们利用vector、的交换,让旧表和新表交换
_table.swap(newtable);
}
size_t hashi = hf(_kv.first) % _table.size();
Node* newnode = new Node(_kv);
newnode->_next = _table[hashi];
_table[hashi] = newnode;
//将新结点头插到哈希桶里
++n;
return true;
}
Node* find(const K& key)
{
Hashfunc hf;
size_t hashi = hf(key)% _table.size();
Node* cur = _table[hashi];
while (cur)
{
if (cur->_kv.first == key)
return cur;
else
cur = cur->_next;
}
return nullptr;
}
void Print()
{
for (int i = 0; i < _table.size(); i++)
{
printf("[%d]", i);
Node* cur = _table[i];
while (cur)
{
cout << cur->_kv.first << " ";
cur = cur->_next;
}
cout << endl;
}
}
bool erase(const K& key)
{
Hashfunc hf;
//可以复用find吗?先用find找到key然后删除key呢?4
//不可以,因为删除一个结点需要找到这个结点的前面和后面的位置,但这里只有key的位置,所以不能直接复用find,但是复用其中的步骤
size_t hashi = hf(key) % _table.size();
Node* cur = _table[hashi];
Node* prev = nullptr;
while (cur)
{
if (cur->_kv.first == key)//找到要删除的结点后
{
//将前面的结点的指针指向后面的前面
//还有一种可能cur就是桶里的第一个,那么就是头删了,prev就是nullptr
if (prev == nullptr)
{
_table[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
//每次先记录一下前面的结点位置
cur = cur->_next;
}
}
return false;
}
private:
//底层封装的是一个数组
//数组里的指针指向的都是哈希结点
vector<Node*> _table;
//底层还封装一个大小n表示实际表中的数据个数
size_t n=0;///用来计算负载因子
};


![[C++ 网络协议] 异步通知I/O模型](https://img-blog.csdnimg.cn/6107f8eecc204eedb99d161d0d3d838e.png)