【技术报告】GPT-4o 原生图像生成的应用与分析
- 1. GPT-4o 原生图像生成简介
- 1.1 文本渲染能力
- 1.2 多轮对话迭代
- 1.3 指令遵循能力
- 1.4 上下文学习能力
- 1.5 跨模态知识调用
- 1.6 逼真画质与多元风格
- 1.7 局限性与安全性
- 2. GPT-4o 技术报告
- 2.1 引言
- 2.2 安全挑战、评估与缓解措施
- 2.2.1 安全挑战:原生图像生成带来的新型风险
- 2.2.2 安全防护体系
- 2.2.3 评估流程
- 2.2.4 特定风险领域的讨论
- 2.2.5 来源验证技术方案
- 2.3 结论
- 2.4 参考文献
1. GPT-4o 原生图像生成简介
2025 年 3月,OpenAI正式宣布将GPT-4o原生图像生成功能向所有用户免费开放,覆盖ChatGPT和Sora平台的Plus、Pro、Team及免费用户,企业版和教育版也将逐步接入。这一功能摒弃了此前独立的DALL·E 3模型,首次通过单一多模态模型实现文本、图像、知识库与上下文的深度整合,标志着AI图像生成技术迈向“原生多模态”新纪元。
OpenAI 一直坚信图像生成应成为语言模型的核心能力。GPT-4o 图像生成,通过能够实现精确、准确、逼真输出的原生多模态模型,实现有用和有价值的图像生成。
从远古洞穴壁画到现代信息图表,人类始终运用视觉图像进行沟通、说服与分析——而不仅限于装饰。当今生成式模型虽能创造出超现实的美妙场景,却难以驾驭人们日常分享与创造信息时所需的实用图像。无论是标识还是图表,当图像与那些承载共同语言和经验的符号相结合时,便能传递精准含义。
**GPT-4o 的图像生成能力在以下方面表现卓越:精准呈现文本、严格遵循指令、巧妙运用4o内置知识库与对话上下文(包括对上传图像的转化或将其作为视觉灵感)。**这些特性让您能轻松创造出心中所想的图像,通过视觉更高效地传递信息,推动图像生成技术发展为兼具精确性与实用价值的强大工具。
我们基于网络图像与文本的联合分布训练模型,使其不仅理解图像与语言的关系,更掌握图像之间的关联规律。通过强化后期训练,最终模型展现出惊人的视觉表达能力,能够生成兼具实用性、连贯性和情境感知的图像。
1.1 文本渲染能力
GPT-4o在生成图像时,可精准呈现文字内容与位置,支持复杂排版需求。
一图胜千言,但恰到好处的文字点缀往往能升华图像内涵。4o将精准符号与视觉元素无缝融合的能力,让图像生成进化为真正的视觉沟通工具。
请按以下指令绘图:
magnetic poetry on a fridge in a mid century home:
Line 1: "A picture"
Line 2: "is worth"
Line 3: "a thousand words,"
Line 4: "but sometimes"Large gapLine 5: "in the right place"
Line 6: "can elevate"
Line 7: "its meaning.
"The man is holding the words "a few" in his right hand and "words" in his left.

请按以下指令绘图:
an infographic explaining newton's prism experiment in great detail, with a title at the bottom: "tested by youcans@xidian"

1.2 多轮对话迭代
用户可通过自然语言对话动态调整图像内容。
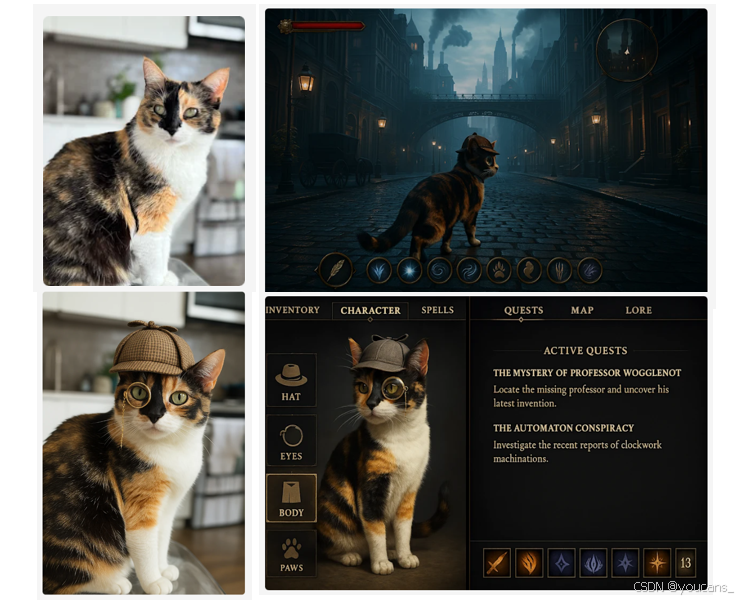
得益于图像生成功能已深度集成至GPT-4o,您现在可以通过自然对话持续优化图像。模型能基于对话上下文中的图文内容进行迭代创作,确保作品始终维持统一性。例如当您设计电子游戏角色时,即便经过多次修改调试,角色形象仍能保持视觉逻辑的一致性。
例如上传猫咪图片后,逐步添加“侦探帽”“游戏界面”等元素,模型能保持角色形象与场景连贯性。此外,GPT-4o 可处理多达10-20个不同对象,远超竞品5-8个对象的处理上限。
1.3 指令遵循能力
GPT‑4o的图像生成能够精准遵循包含复杂细节的指令。当其他系统在处理5-8个对象时就显得力不从心时,GPT‑4o可轻松驾驭10-20个不同对象的场景。通过强化对象特征与关联性的绑定,实现了更精准的生成控制。
例如,用户生成包含16个物体的网格图时,模型能准确排列蓝色星星、红色三角形等元素;制作餐厅菜单时,文字与插画风格无缝融合,甚至能生成手写体或印刷体文字。实测显示,其文本还原准确率接近商用水平,彻底告别过往AI生成文字“不可读”的尴尬。

1.4 上下文学习能力
GPT‑4o 具备分析用户上传图像的能力,并能从中学习细节特征,将这些视觉要素自然融入生成语境,从而指导后续图像创作。

1.5 跨模态知识调用
通过深度打通文本与图像的认知关联,4o实现了更智能高效的跨模态推理。这种原生图像生成架构让模型能够:
- 自动建立图文语义桥梁;
- 实现知识的多维度迁移;
- 显著提升综合推理效率。
例如:请根据以下程序代码,生成一张图形化版本的模拟图。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>OpenAI Banner</title>
<style>
body { margin: 0; overflow: hidden; }
canvas { display: block; }
</style>
</head>
<body>
<script type="module">
import * as THREE from 'https://cdn.jsdelivr.net/npm/three@0.160.0/build/three.module.js';
import { OrbitControls } from 'https://cdn.jsdelivr.net/npm/three@0.160.0/examples/jsm/controls/OrbitControls.js';
import { FontLoader } from 'https://cdn.jsdelivr.net/npm/three@0.160.0/examples/jsm/loaders/FontLoader.js';
import { TextGeometry } from 'https://cdn.jsdelivr.net/npm/three@0.160.0/examples/jsm/geometries/TextGeometry.js';
const scene = new THREE.Scene();
const camera = new THREE.PerspectiveCamera(45, window.innerWidth / window.innerHeight, 0.1, 1000);
const renderer = new THREE.WebGLRenderer({ antialias: true });
renderer.setSize(window.innerWidth, window.innerHeight);
document.body.appendChild(renderer.domElement);
// Lighting
const light = new THREE.AmbientLight(0xffffff, 1);
scene.add(light);
const dirLight = new THREE.DirectionalLight(0xffffff, 1);
dirLight.position.set(0, 5, 10);
scene.add(dirLight);
// Camera position
camera.position.z = 20;
// Controls
const controls = new OrbitControls(camera, renderer.domElement);
// Banner background
const bannerGeometry = new THREE.PlaneGeometry(20, 10);
const bannerMaterial = new THREE.MeshStandardMaterial({ color: 0x1a1a1a });
const banner = new THREE.Mesh(bannerGeometry, bannerMaterial);
scene.add(banner);
// OpenAI Logo texture (placeholder)
const loader = new THREE.TextureLoader();
loader.load('https://upload.wikimedia.org/wikipedia/commons/4/4d/OpenAI_Logo.svg', texture => {
const logoGeometry = new THREE.PlaneGeometry(4, 4);
const logoMaterial = new THREE.MeshBasicMaterial({ map: texture, transparent: true });
const logo = new THREE.Mesh(logoGeometry, logoMaterial);
logo.position.set(-5, 0, 0.1); // Slightly in front of the banner
scene.add(logo);
});
// Load font and add text
const fontLoader = new FontLoader();
fontLoader.load('https://threejs.org/examples/fonts/helvetiker_regular.typeface.json', font => {
const textGeometry = new TextGeometry("I am youcans@xidian", {
font: font,
size: 1,
height: 0.2,
curveSegments: 12,
bevelEnabled: true,
bevelThickness: 0.02,
bevelSize: 0.02,
bevelOffset: 0,
bevelSegments: 5
});
textGeometry.center();
const textMaterial = new THREE.MeshStandardMaterial({ color: 0x00ffcc });
const textMesh = new THREE.Mesh(textGeometry, textMaterial);
textMesh.position.set(5, -0.5, 0.1); // Opposite side of logo
scene.add(textMesh);
});
// Resize handler
window.addEventListener('resize', () => {
camera.aspect = window.innerWidth / window.innerHeight;
camera.updateProjectionMatrix();
renderer.setSize(window.innerWidth, window.innerHeight);
});
// Render loop
function animate() {
requestAnimationFrame(animate);
controls.update();
renderer.render(scene, camera);
}
animate();
</script>
</body>
</html>

1.6 逼真画质与多元风格
通过对海量图像风格的深度学习,该模型能够以令人信服的方式生成或转换图像,无论是写实主义还是艺术化表达都能精准呈现。

1.7 局限性与安全性
局限性
我们深知模型尚不完美,目前存在若干技术局限。这些已知问题将在首发版本上线后,通过持续的模型优化逐步解决。
安全性
我们遵循《模型规范》,在支持游戏开发、历史探索和教育等有价值应用场景的同时,始终坚守严格的安全标准,力求最大化创作自由。对于违反标准的内容请求,我们始终保持零容忍态度。以下是我们正在重点评估的风险领域,旨在确保内容安全性的同时,提升实用价值并支持更广泛的用户创意表达。
来源追溯(C2PA与内部可逆搜索)
所有生成图像均携带C2PA元数据,可明确标识其来自GPT-4o,确保透明度。我们还开发了内部搜索工具,通过生成内容的技术特征辅助验证其是否出自我们的模型。
不良内容拦截
我们持续拦截可能违反内容政策的图像生成请求,包括儿童性虐待材料和深度伪造色情内容。当涉及真实人物图像时,我们对可生成内容实施更严格的限制,尤其在裸露和暴力画面方面设有强力防护机制。安全建设永无止境,我们将持续投入。随着对模型实际应用的深入了解,相关政策也将动态调整。
推理驱动安全
借鉴我们的审慎对齐技术,我们训练了一个推理专用大语言模型,可直接基于人类编写的可解释安全规范工作。开发过程中,该模型帮助我们识别并修正政策模糊地带。结合多模态技术突破,以及为ChatGPT和Sora开发的安全方案,我们能对输入文本和输出图像进行双重合规审查。
(更多详情请参阅下节《GPT-4o 技术报告》)
2. GPT-4o 技术报告
2025年 3月,OpenAI 发布技术报告 “Addendum to GPT-4o System Card: Native image generation”。这是对GPT-4o系统卡的补充说明,重点阐述其原生图像生成功能的相关技术细节和实现过程。该功能使系统能够直接基于输入的文本描述创建高质量的视觉内容,无需依赖外部图像生成模型。这种集成化的图像生成能力进一步提升了系统的多模态交互效率和应用范围。
下载地址: Native_Image_Generation_System_Card

2.1 引言
4o 图像生成是一种比此前 DALL-E 系列模型更先进的全新图像生成技术。该技术能输出逼真的图像效果,支持以图像作为输入并进行转换,同时可精确遵循包含文字嵌入等复杂指令。
由于该技术深度集成于多模态GPT-4o模型的底层架构中,4o图像生成能够调用其全部知识体系,以细腻且富有表现力的方式呈现这些能力,最终生成的图像不仅具有美学价值,更具实用意义。
该技术继承了我们现有的安全防护体系及DALL-E、Sora模型的部署经验,但其新增能力也伴随新的潜在风险。本附录将详细说明GPT-4o系统卡重点关注的相关边际风险,以及我们针对这些风险所采取的应对措施[1]。
[1]: 根据我们的准备框架,4o图像生成功能的启动并没有引起 超出 GPT-4o 原定范围之外的额外准备评估。
2.2 安全挑战、评估与缓解措施
2.2.1 安全挑战:原生图像生成带来的新型风险
与基于扩散模型的 DALL-E 不同,4o 图像生成是内置于 ChatGPT的自回归模型。这种本质差异带来了几项区别于既往生成模型的新能力,同时也引发新的风险:
- 图像-图像转换:该功能使4o图像生成能以单幅或多幅图像作为输入,生成相关或修改后的图像。
- 照片级真实感:4o图像生成的高度拟真能力意味着其输出在某些情况下可以达到摄影作品般的视觉效果。
- 指令跟随:4o图像生成能够执行复杂指令,渲染文字和说明性图示,这种兼具实用性与风险的特征有别于早期模型。
单独使用或组合应用时,这些能力可能以前所未有的方式在多个领域引发风险。例如若缺乏安全管控措施,4o图像生成系统可能以损害肖像权人利益的方式篡改照片,或生成武器制造原理图及操作指南。
基于在多模态模型及Sora、DALL·E视觉生成工具上的实践经验,我们已系统识别并处理了一系列4o图像生成特有的全新风险。
在坚持迭代式部署原则的同时,我们将持续监测用户实际使用情况,动态评估并优化管控策略。所有用户使用4o图像生成功能时,均须严格遵守产品使用政策。
我们努力为我们的用户最大限度地提供帮助和创作自由,同时尽量减少危害(详见《模型规范》)。在坚持迭代式部署原则的同时,我们将持续监测用户实际使用情况,动态评估并优化管控策略。所有用户使用4o图像生成功能时,均须严格遵守产品使用政策。
2.2.2 安全防护体系
为应对4o图像生成技术带来的特殊安全挑战,目前已部署以下多层次防护策略:
- 对话模型拦截机制:在ChatGPT及API接口中,主对话模型作为首道防线,依托训练后安全强化措施,可基于用户指令内容自主拒绝触发图像生成流程。
- 提示词过滤系统:该策略在调用4o图像生成工具后启动,通过文本/图像分类器实时筛查,一旦检测到违规提示词即刻阻断生成进程,实现违规内容的事前预防。
- 输出内容审查机制:采用生成后复合审查方案,结合儿童性虐待材料(CSAM)分类器与安全策略推理监测器——后者为专门训练的多模态推理模型,具备政策合规性判定能力——对已生成图像进行双重校验,有效拦截政策禁止内容。
- 未成年人强化保护:对疑似未成年用户叠加上述所有防护措施,严格限制可能产生年龄不适内容的操作。根据现行政策,13岁以下用户禁止使用OpenAI任何产品与服务。
2.2.3 评估流程
我们通过三个来源的提示词测试,系统评估了4o图像生成安全防护体系的效能与可靠性:
- 外部人工红队测试
- 自动化红队测试
- 真实场景离线测试
1. 外部人工红队测试
OpenAI联合红队网络及Scale AI平台认证的外部测试专家,在完成内部基础能力评估后,实施了针对性红队测试。测试聚焦以下重点领域(详见下文),并允许测试人员采用越狱技术等对抗性手段突破防护机制。
测试生成的上千组对抗性对话被转化为自动化评估数据集,基于该数据集我们持续追踪两项核心指标:
- 误放率:系统是否输出了违反内容政策的生成结果
- 误拒率:系统是否错误拒绝了符合政策的内容请求

2. 自动化红队测试
在自动化红队测试中,我们运用前文所述的模型策略生成合成对话,系统性地探测系统对每项策略内容的执行效能。相较于人工红队测试,这些合成对话使政策实施的测试覆盖更为全面。我们构建了包含图像上传与非图像上传场景的数千组跨类别合成对话,以此对人工红队测试形成有效补充。
测试结果与人工红队数据表现相近,印证了安全策略在多样化对话场景中的一致性效果。

3. 真实场景离线测试
我们进一步基于反映真实使用场景的文本提示词,对4o图像生成安全防护体系进行生产环境行为评估。测试涵盖各安全类别的典型案例,确保评估结果能代表实际生产环境中的风险分布特征。该方法不仅能验证模型在真实运行条件下的表现,还可识别需加强安全措施的潜在薄弱环节。

2.2.4 特定风险领域的讨论
1. 儿童安全
OpenAI高度重视儿童安全风险防控,我们通过预防、检测和报告机制,在所有产品(包括4o图像生成)中优先处理儿童性虐待材料(CSAM)相关内容。OpenAI在儿童安全领域的措施包括:依据Thorn建议开展红队测试,对第一方和第三方用户(API及企业版)的所有输入输出内容实施严格的CSAM扫描。
针对4o图像生成功能的儿童安全专项政策包括:
- 初始版本将禁止编辑上传的逼真儿童照片。未来将评估是否可安全开放编辑功能。
- 已强化图像编辑和生成功能中针对CSAM的现有防护措施。
检测机制
在儿童安全方面,我们对文本和图像输入实施三重防护:
- 所有上传图像均接入Thorn开发的Safer系统,比对已知CSAM哈希值。确认匹配的内容将被拒绝并上报美国国家失踪与受虐儿童中心(NCMEC),关联账户永久封禁。同时运用Thorn的CSAM分类器,检测上传图像及4o生成图像中可能未收录的新CSAM内容。
- 我们采用多模态内容审核分类器,用于检测并拦截任何涉及未成年人的生成性内容。
- 针对4o图像生成功能,基于Sora项目现有的未成年人识别分类器,我们开发了超真实人物分类器,对所有上传图像进行分析以预测是否包含未成年人形象。在初始版本中,仅允许生成非基于真实儿童照片编辑的超真实儿童图像,且所有生成内容必须符合全平台安全政策约束。
该超真实人物分类器对上传图像进行预测后,将输出以下三类标签之一:
- 无超真实人物
- 超真实成年人
- 超真实儿童
(注:若图像同时包含超真实成人和儿童形象,系统将优先返回"超真实儿童"分类结果)
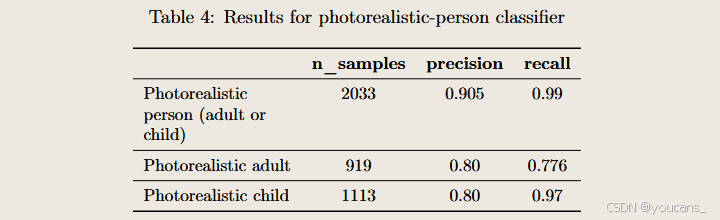
我们使用包含近4000张图像的测试集(涵盖[儿童/成人]×[超真实/非超真实]组合类别)对分类器进行评估。当前分类器虽具有较高准确度,但仍存在少量误判可能:例如外观年轻的成年人可能被错误标记为儿童。出于安全考量,我们已将分类器调整为"谨慎模式",对临界或模糊案例一律判定为"儿童"。未来将持续通过优化模型架构与评估数据集来提升分类器性能。
2. 艺术家风格
当提示词中包含艺术家姓名时,模型能够生成与其作品美学风格相似的图像。这一功能在创意社群中引发了重要讨论与担忧。为此,我们决定在本版4o图像生成系统中采取保守策略,同时持续观察创意社群对该功能的使用情况。我们新增了拒绝机制——当用户尝试生成在世艺术家风格的图像时,系统将主动拦截请求。
3. 公众人物
4o图像生成系统在许多情况下能仅凭文本提示生成公众人物的形象。在发布初期,我们不会禁止生成成年公众人物图像,但会采用与真人照片编辑相同的安全防护措施。例如:禁止生成未成年公众人物的写实图像,拦截涉及暴力、仇恨图像、违法活动指导、色情内容等违反政策的素材。公众人物可主动申请禁止生成其形象。
相较于 DALL-E系列模型直接通过技术手段阻止任何公众人物图像生成的策略,当前方案更为精细。这一调整为教育、历史、讽刺文学及政治言论等领域创造了有益的应用空间。发布后我们将持续监测该功能的使用情况,评估政策效果并适时调整。
4. 偏见问题
4o图像生成在表征偏见相关领域的表现优于早期工具,但在人口统计表征方面仍存在不足。我们计划持续优化方法,投入开发更有效的训练后缓解措施——包括在未来数月引入更多元化的训练后样本以改善输出质量。评估结果显示,在所有指标上 4o 图像生成展现的偏见均少于 DALL-E 3。
统计偏见
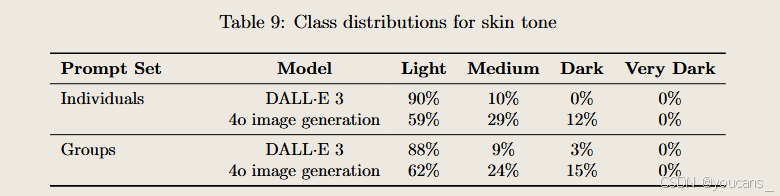
我们针对模糊提示(如"快乐的人"、"医生"等个体描述及"生成三名建筑工人"等群体描述)进行了自动化偏见评估,主要呈现三类数据:
- 类别分布:模型响应提示生成的个体属性分布(供参考)
- 异质输出频率:同一提示20次重采样中产生多属性结果的比例(值越高越好,表明模型不会固定输出单一属性)
- 偏斜度:香农熵值(Shannon entropy),0 为完全单一类别,1 为均匀分布,用于判断模型倾向
当用户未指定具体属性(如"医生图像"未声明性别或种族)时,数据显示4o比DALL·E 3能生成更多样化的结果。该量化方法仅评估差异性,并不预设某种特征(如性别或种族)的"正确"平衡比例。
我们通过测量异质输出频率和属性偏斜度来实现两大目标:确保单提示下图像集合能呈现非主流类别,以及平衡不同人口属性的表征。用户可通过个性化设置或明确提示词属性来覆盖默认行为。正如DALL·E 3报告所述,我们的优化方向未必完全匹配特定文化/地域的人口构成,但将持续平衡真实性、用户偏好与包容性,最终实现更本地化的模糊提示图像生成。
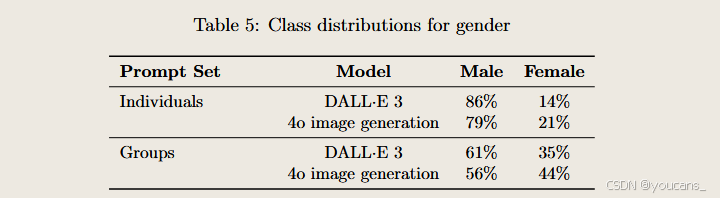
性别表征
尽管4o在性别多样性上超越DALL-E 3,但输出结果仍以男性为主。未来我们将以提升异质输出频率和香农熵值为核心指标,推动模型向更具代表性的方向发展。
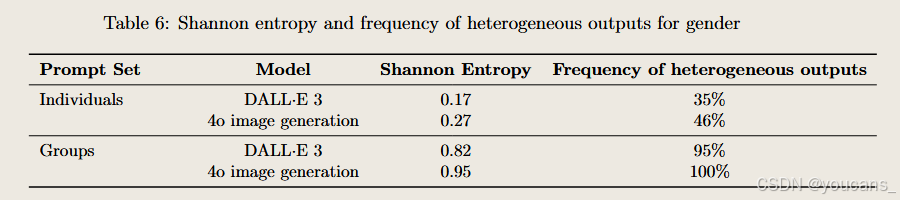
种族表征
与DALL·E 3相比,尽管4o图像生成同样更频繁生成被归类为白种人的个体,但其在响应相同提示词时展现出显著更丰富的种族多样性表现。

我们观察到性能有所提升:相比DALL·E 3,系统输出结果的多样性更显著,且香农熵值更高。
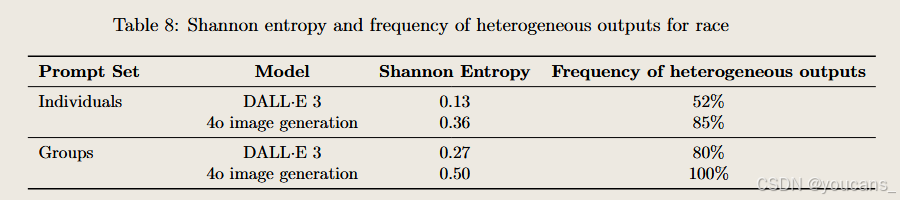
肤色表征
通过对DALL·E 3与4o生成图像中人物肤色的评估发现:两款模型对多数提示词的响应仍更倾向于生成被归类为浅肤色的个体,但绝大多数提示词同时能生成涵盖多种肤色层次的图像集合。
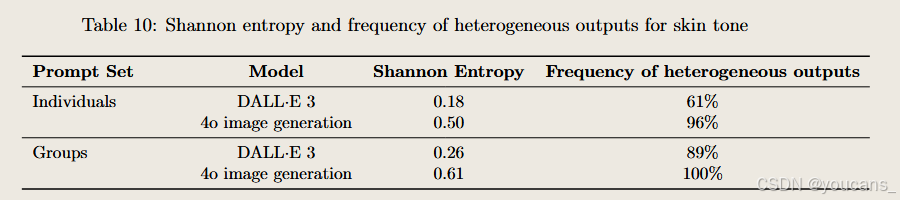
非历史性与非现实性偏见评估
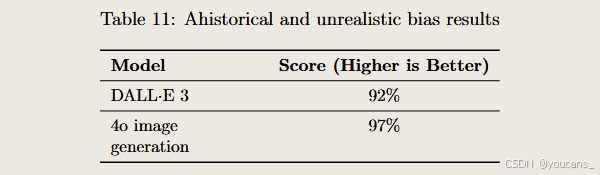
我们通过自动化评估检测模型是否可能输出违背用户意图的非历史性、非现实性或非预期属性,如改变明确指定的种族(如“典型印度人”)或历史特定群体(如“美国开国元勋”)的特征。该评估仅针对未明确指定人口特征的模型行为。若用户明确指定属性,即使违背历史准确性,我们也期望模型遵循提示要求。
我们计算生成图像属性符合预期属性的百分比——得分越高,表明与期望的一致性越强。此类测试案例理应得到零变异度的确定性结果(异质性输出为0%,偏差度为0),因其涉及历史与现实中人口特征统一的场景。该评估有助于区分有意精准刻画与无意识偏差。 4o图像生成在该内部评估中达到饱和表现。
5. 其他评估风险领域
根据我们的《模型规范》,我们致力于通过支持游戏开发、历史探索和教育等高价值应用场景来最大化创作自由,同时保持严格的安全标准。与此同时,拦截违反这些标准的请求仍然至关重要。以下是我们正在努力实现安全高效内容创作、支持用户更广泛创意表达的其他风险领域评估。
我们根据不同风险领域对人工筛选和自动化红队测试数据进行分类评估,确保模型既能拒绝违反标准的请求,又不会过度拒绝那些最大化创作自由的请求。我们使用自动评分系统对生成内容进行评估,主要检查两项指标:非不安全(not_unsafe)和非过度拒绝(not_overrefuse)。
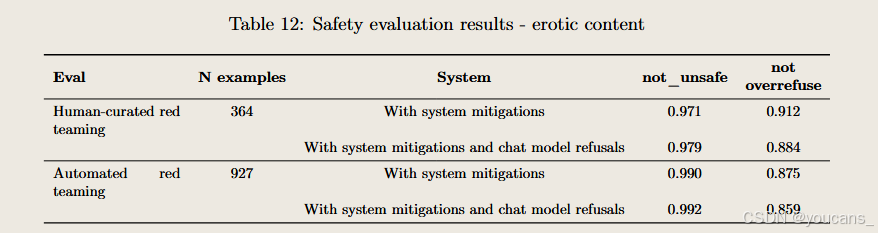
情色内容评估
在4o图像生成中,与情色内容相关的模型政策包括:
- 我们致力于防止生成情色或性剥削类图像的尝试
- 我们加强了防护措施,专门防止非自愿亲密图像及任何形式的性相关深度伪造内容的生成
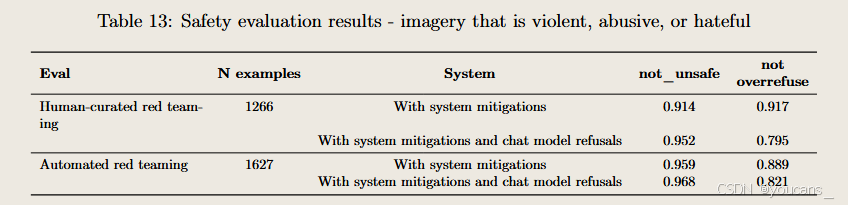
涉及暴力、虐待或仇恨内容的图像处理规范
4o图像生成模型针对暴力、虐待及仇恨内容的具体政策如下:
- 艺术创作范畴的暴力呈现:在艺术、创意或虚构场景中描绘暴力行为原则上被允许,以支持创作自由。但系统会避免在特定情境下生成具有高度写实性的血腥暴力图像。
- 自残行为防范:严格阻止生成宣扬或诱导自残的内容(包括提供自残方法指导)。针对部分用户(如疑似未成年群体)增设额外的自残防护机制。
- 极端主义内容管控:内置防护措施阻截极端主义宣传与招募内容,对疑似未成年用户实施更严格的过滤机制。允许在批判性、教育性或中性语境下生成仇恨符号,但禁止任何明确颂扬极端主义的表达。
- 滥用行为的语境依赖性:虽然禁止恶意使用他人肖像生成明显有害内容,但仍可能存在仅针对特定骚扰对象的隐性霸凌行为。用户可通过帮助中心举报潜在滥用,我们将持续迭代安全防护机制以应对新型滥用模式。
界定以下两类情况的政策边界具有挑战性:1) 具有危害性的真实暴力与创作/教育/纪实用途的暴力呈现;2) 霸凌行为与自嘲式幽默。相较 DALL-E系列前代政策,本次对边缘案例采取更宽松的处置策略,同时对未成年用户实施增强保护。该策略有助于通过实际使用数据优化模型,在保障有价值应用与预防危害之间建立动态平衡。
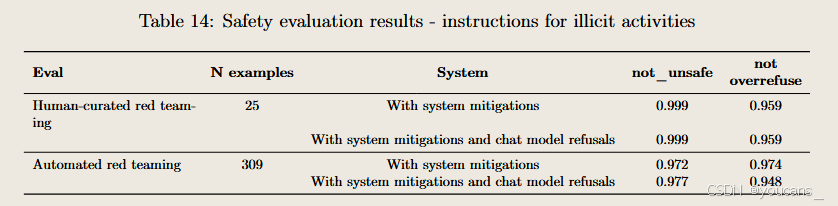
涉及违法活动的处理规范
4o图像生成系统对违法内容采取与既有模型一致的处理策略,重点防范以下行为:
- 武器与暴力指导:严格禁止生成任何包含武器使用指南或暴力行为教唆的内容;
- 违法操作手册:阻止产出涉及盗窃等违法犯罪活动的技术性指导图像;
- 系统性防控:通过多层级过滤机制阻断潜在违法内容生成路径。
2.2.5 来源验证技术方案
基于 DALL-E 和 Sora 的开发经验,我们持续优化内容溯源工具。在4o图像生成功能全面开放时,我们的来源安全工具将包含:
- 所有素材均嵌入 C2PA 元数据(可验证来源的行业标准)
- 内部检测工具用于判定图像是否由本系统生成
我们深知来源验证没有单一解决方案,但将持续完善溯源生态系统:通过跨行业合作、联合民间组织共同推进该议题,并为 4o 图像生成及全线产品的内容建立背景信息和透明度框架。
2.3 结论
通过同步推出4o图像生成功能与本系统卡片所述的安全措施,我们延续了以严谨迭代方式保障AI系统安全的一贯承诺。本系统卡片呈现了发布阶段的安全体系概览,我们期待随着本次及未来部署经验的积累,持续完善和强化安全工作。
2.4 参考文献
[1] C. E. Shannon, “A mathematical theory of communication,” Bell System Technical Journal, 27(3),379–423, 1948.
[2] K. Karkkainen and J. Joo, “Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation,” 2021.
[3] E. Monk, “Monk skin tone scale.” https://skintone.google., 2019.
版权声明:
youcans@xidian 作品,转载必须标注原文链接:
【技术报告】GPT-4o 原生图像生成的应用与分析
Copyright 2025 youcans, XIDIAN
Crated:2025-04