文章目录
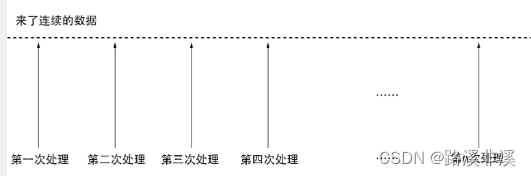
1, datafram根据相同的key聚合 2, 数据合并:获取采集10,20,30分钟es索引数据
data1 = { 'key' : [ 'A' , 'B' ] ,
'value' : [ 1 , 2 ] }
df1 = pd. DataFrame( data1)
data2 = { 'key' : [ 'A' , 'B' ] ,
'value' : [ 11 , 22 ] }
df2 = pd. DataFrame( data2)
data3 = { 'key' : [ 'A' , 'B' , 'c' ] ,
'value' : [ 111 , 222 , 333 ] }
df3 = pd. DataFrame( data3)
& gt; & gt; > mdf1= pd. merge( df1, df2, on= 'key' )
& gt; & gt; > mdf1
key value_x value_y
0 A 1 11
1 B 2 22
mdf = pd. merge( pd. merge( df1, df2, on= 'key' ) , df3, on= 'key' )
& gt; & gt; > mdf2= pd. merge( mdf1, df3, on= 'key' )
& gt; & gt; > mdf2
key value_x value_y value
0 A 1 11 111
1 B 2 22 222
[ root@localhost ]
import json
import time
import requests
import os
import sys
import glob
import pandas as pd
def deloldfile( workdir) :
all_files = glob.glob( os.path.join( workdir, '*' ))
file_list = [ ]
for file in all_files:
file_list.append(( file, os.path.getatime( file)) )
file_list.sort( key= lambda x: x[ 1 ] , reverse = False)
for file in file_list[ :-3] :
os.remove( file[ 0 ] )
def createfile( workdir,fileName) :
if not os.path.exists( workdir) :
os.makedirs( workdir)
file = open( workdir+fileName,'w' ,encoding= "utf-8" )
return file
def readfile( workdir) :
if not os.path.exists( workdir) :
os.makedirs( workdir)
all_files = glob.glob( os.path.join( workdir, '*' ))
file_list = [ ]
for file in all_files:
file_list.append(( file, os.path.getatime( file)) )
files = [ ]
file_list.sort( key= lambda x: x[ 1 ] , reverse = False)
for file in file_list:
files.append( file[ 0 ] )
return files
def writejson( file,jsonArr) :
for js in jsonArr:
jstr = json.dumps( js) +"\n "
file.write( jstr)
file.close( )
def getdata( domain,password) :
url = "http://" +domain+"/_cat/indices?format=json"
auth = ( 'elastic' , password)
response = requests.get( url, auth = auth)
if response.status_code == 200 :
jsonArr = json.loads( response.text)
df = pd.json_normalize( jsonArr)
dfnew = df.drop( [ "uuid" ,"docs.deleted" ] , axis = 1 )
workdir = "/data/es-indices/"
workdir_tmp = workdir+"tmp/"
f_time = time.strftime( "%Y-%m-%d_%H-%M-%S" ,time.localtime( ))
filename = "es-data-{}.json" .format( f_time)
filename_tmp = "tmp-{}.json" .format( f_time)
file = createfile( workdir_tmp,filename_tmp)
writejson( file,jsonArr)
deloldfile( workdir_tmp)
deloldfile( workdir)
files = readfile( workdir_tmp)
if len( files) > 1 :
print( files[ 0 ] )
print( files[ 1 ] )
df1 = pd.read_json( files[ 0 ] ,lines= True)
df2 = pd.read_json( files[ 1 ] ,lines= True)
df1 = df1.drop( [ "health" ,"status" ,"uuid" ,"pri" ,"rep" ,"docs.deleted" ,"store.size" ,"pri.store.size" ] , axis = 1 )
df2 = df2.drop( [ "health" ,"status" ,"uuid" ,"pri" ,"rep" ,"docs.deleted" ,"store.size" ,"pri.store.size" ] , axis = 1 )
mdf = pd.merge( df1, df2, on = 'index' , how = 'outer' )
else:
mdf = dfnew
mdf2 = pd.merge( dfnew, mdf, on = 'index' , how = 'outer' )
mdf2 = mdf2.rename( columns= { "docs.count_x" : "docs.count_30" , "docs.count_y" : "docs.count_20" } )
file = createfile( workdir,filename)
for idx,row in mdf2.iterrows( ) :
jstr = row.to_json( )
file.write( jstr+"\n " )
file.close( )
else:
print( '请求失败,状态码:' , response.status_code)
domain = "196.1.0.106:9200"
password = "123456"
getdata( domain,password)
[ root@localhost]
/data/es-indices/tmp/tmp-2023-09-28_13-56-12.json
/data/es-indices/tmp/tmp-2023-09-28_14-11-47.json
[ root@localhost]
total 148
-rw------- 1 root root 46791 Sep 28 13 :56 es-data-2023-09-28_13-56-12.json
-rw------- 1 root root 46788 Sep 28 14 :11 es-data-2023-09-28_14-11-47.json
-rw------- 1 root root 46788 Sep 28 14 :12 es-data-2023-09-28_14-12-07.json
drwx------ 2 root root 4096 Sep 28 14 :12 tmp
[ root@localhost]
total 156
-rw------- 1 root root 52367 Sep 28 13 :56 tmp-2023-09-28_13-56-12.json
-rw------- 1 root root 52364 Sep 28 14 :11 tmp-2023-09-28_14-11-47.json
-rw------- 1 root root 52364 Sep 28 14 :12 tmp-2023-09-28_14-12-07.json
[ root@localhost]
{ "health" : "green" ,"status" : "open" ,"index" : "test_2023_09" ,"pri" : "3" ,"rep" : "1" ,"docs.count" : "14393" ,"store.size" : "29.7mb" ,"pri.store.size" : "13.9mb" ,"docs.count_30" :14391.0,"docs.count_20" :14393.0}
[ root@localhost]
{ "health" : "green" ,"status" : "open" ,"index" : "test_2023_09" ,"pri" : "3" ,"rep" : "1" ,"docs.count" : "14422" ,"store.size" : "33.5mb" ,"pri.store.size" : "15.8mb" ,"docs.count_30" :14391.0,"docs.count_20" :14393.0}
[ root@localhost]
{ "health" : "green" ,"status" : "open" ,"index" : "test_2023_09" ,"pri" : "3" ,"rep" : "1" ,"docs.count" : "14427" ,"store.size" : "33.5mb" ,"pri.store.size" : "15.8mb" ,"docs.count_30" :14393.0,"docs.count_20" :14422.0}