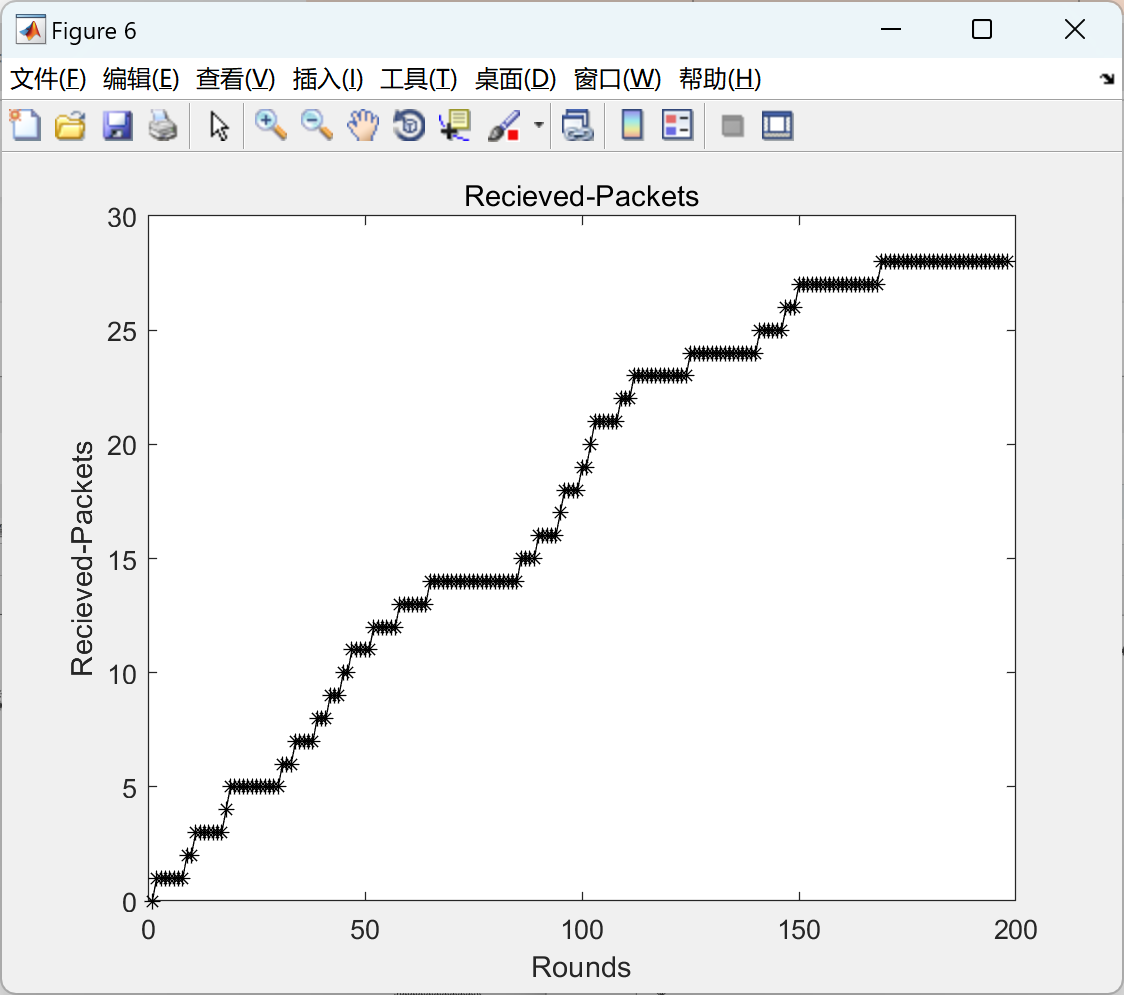
CPU 核心之间数据如何传播
高速缓存中的值被修改了,那么怎么同步到内存中呢?
- ① 写直达(Write-Through)
- ② 写回(Write-Back)
写直达(Write-Through) 简单,但是很慢,每次写都需要经过 内存总线
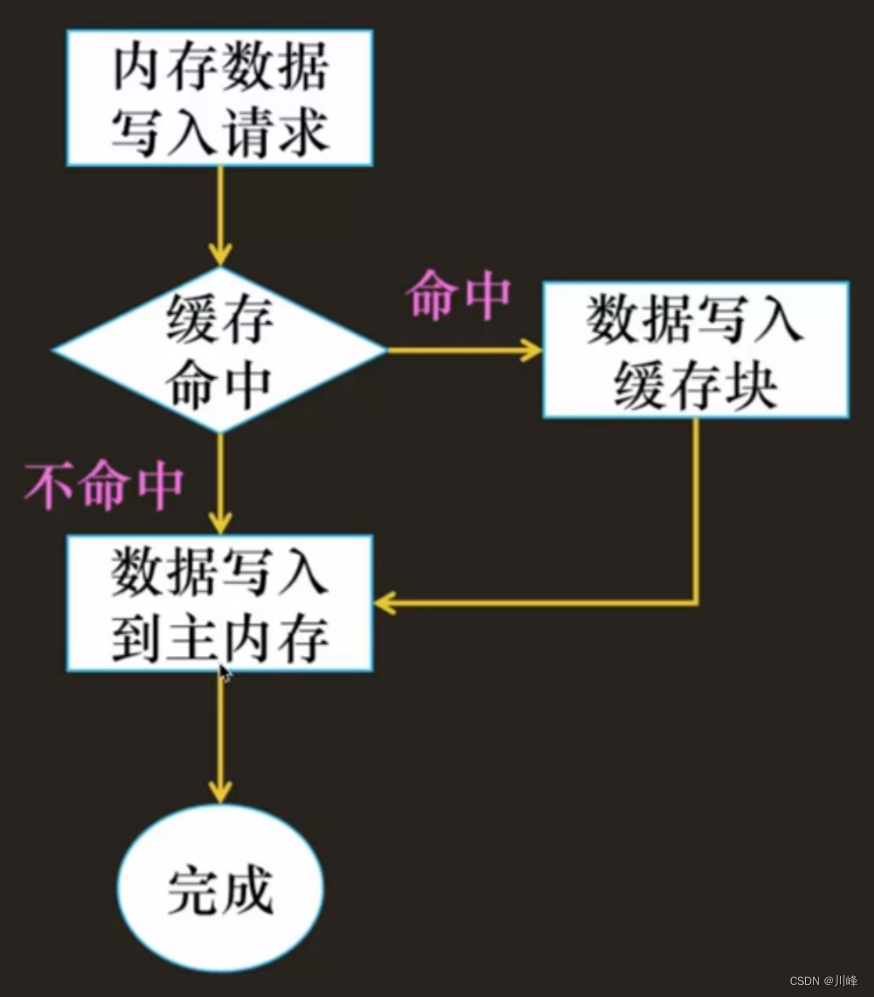
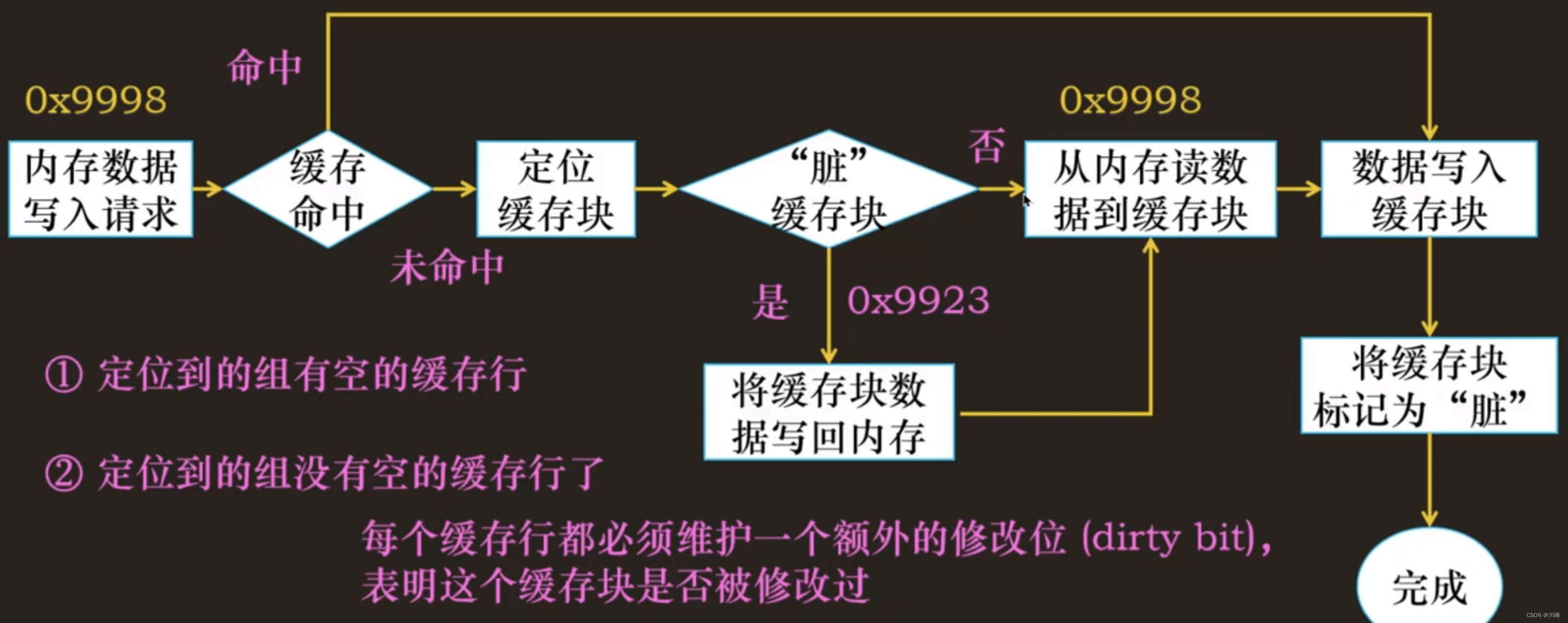
写回(Write-Back):尽可能推迟更新,只有当替换算法要驱逐这个更新过的缓存块时,才把它写回到内存中。由于局部性,写回能显著地减少总线流量,但是它的缺点是复杂。
写传播(Write Propagation)
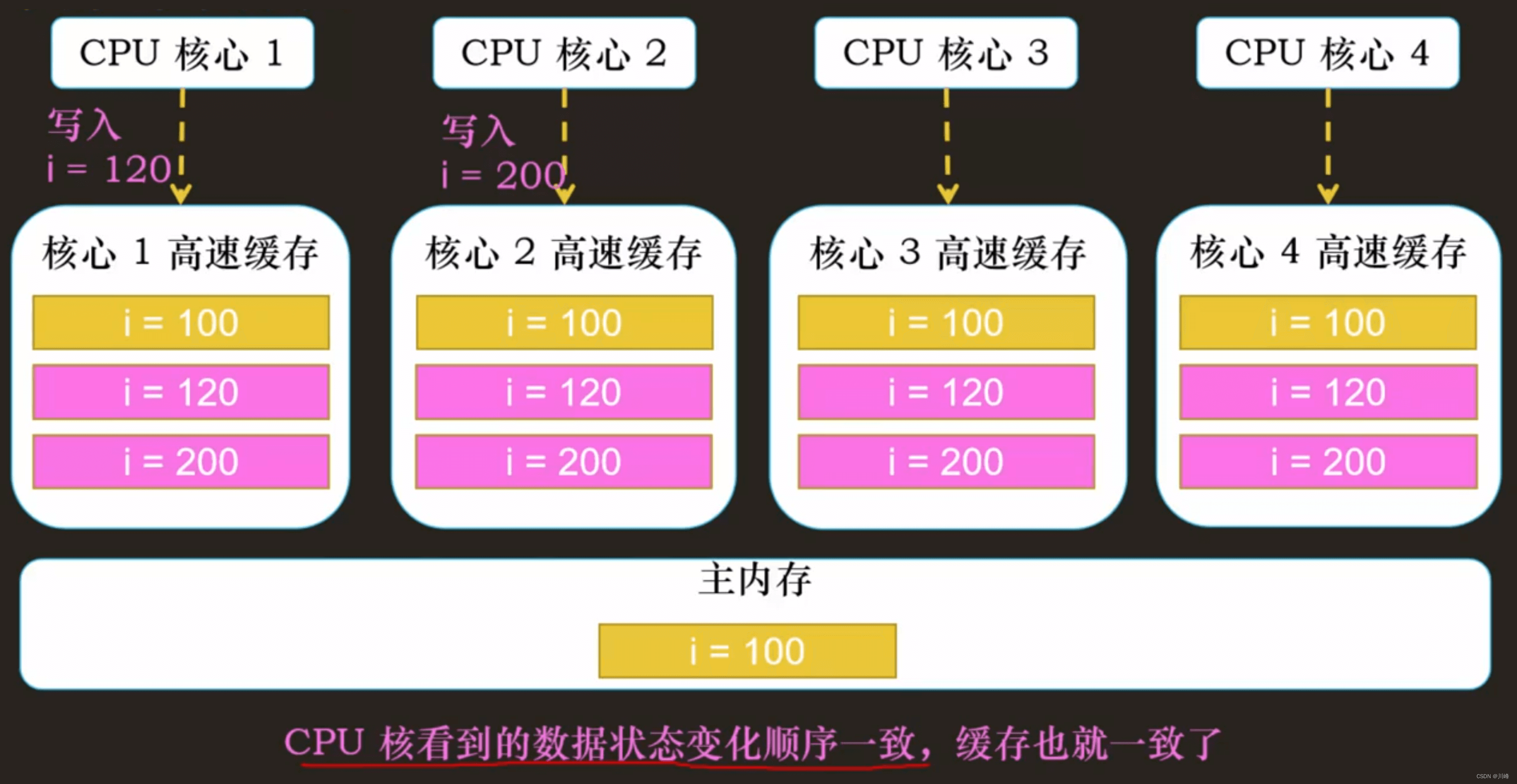
写传播是说,在一个 CPU 核心里,我们的 Cache 数据更新,必须能够传播到其他的对应核心节点的 Cache Line 里。

事务的串行化(Transaction Serialization)
事务串行化是说,我们在一个 CPU 核心里面的写入顺序,在其他的核心节点看起来,顺序是一样的。
CPU 核心之间数据传播的两种方式
- ① 写失效(Write Invalidate)
- ② 写广播(Write Broadcast)
写失效(Write Invalidate):只有一个 CPU 核心负责写入数据,其他的核心对应缓存行失效,需要这个数据的时候,才同步读取到这个写入。
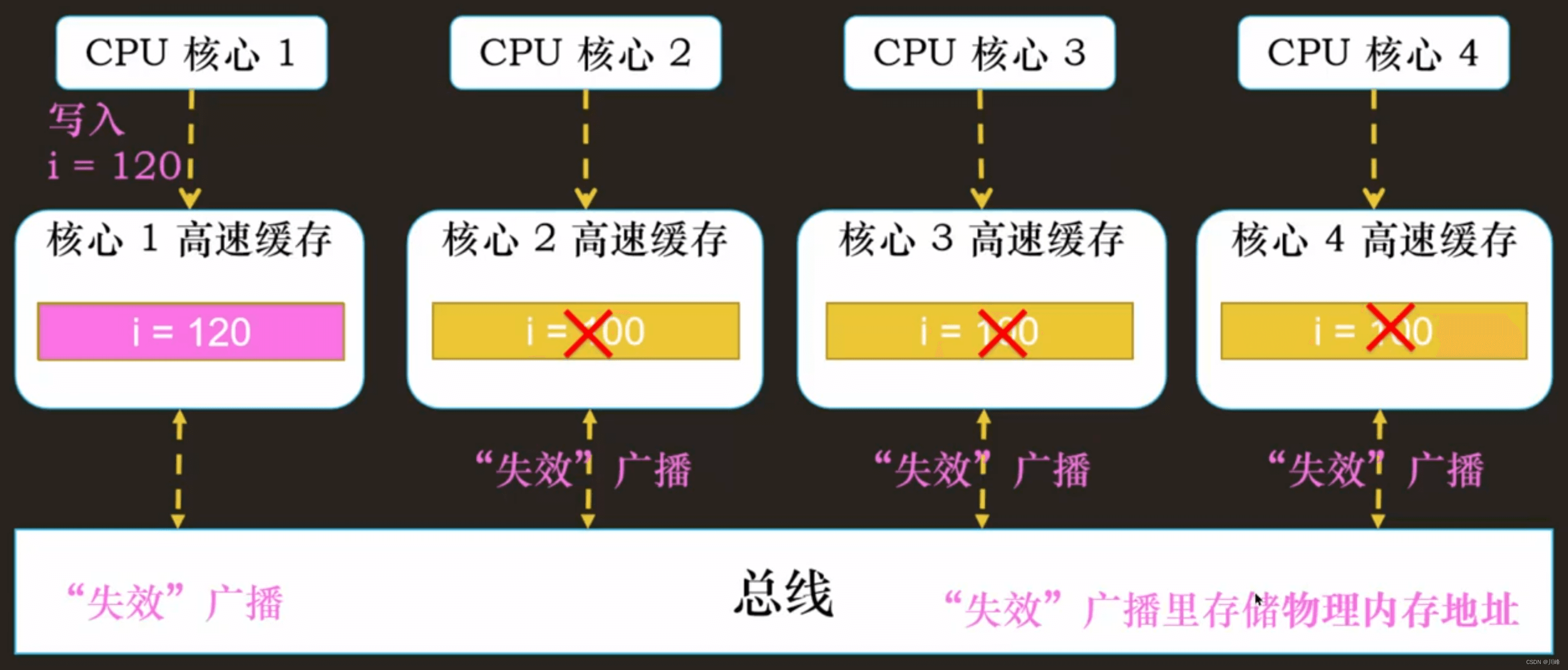
写广播(Write Broadcast):一个写入请求广播到所有的 CPU 核心,同时更新各个核心里的 Cache。
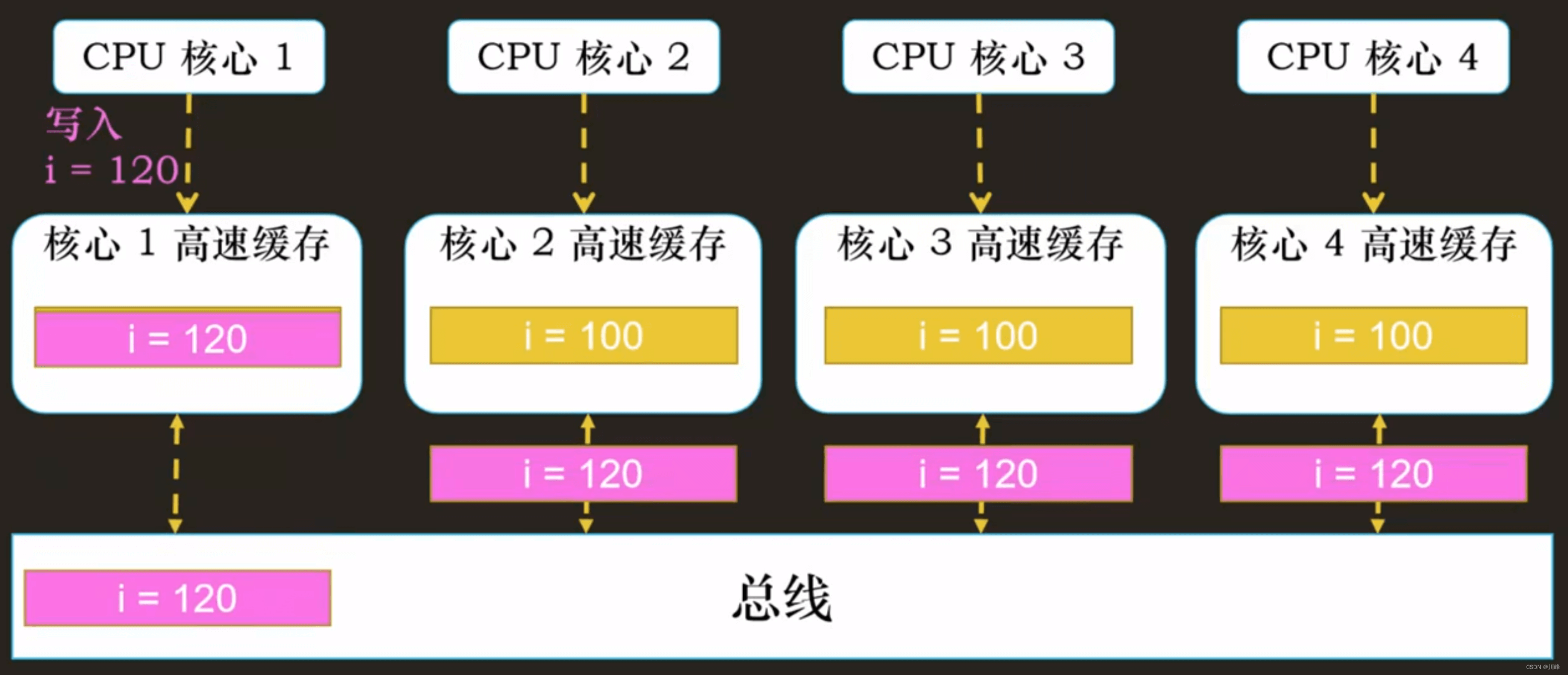
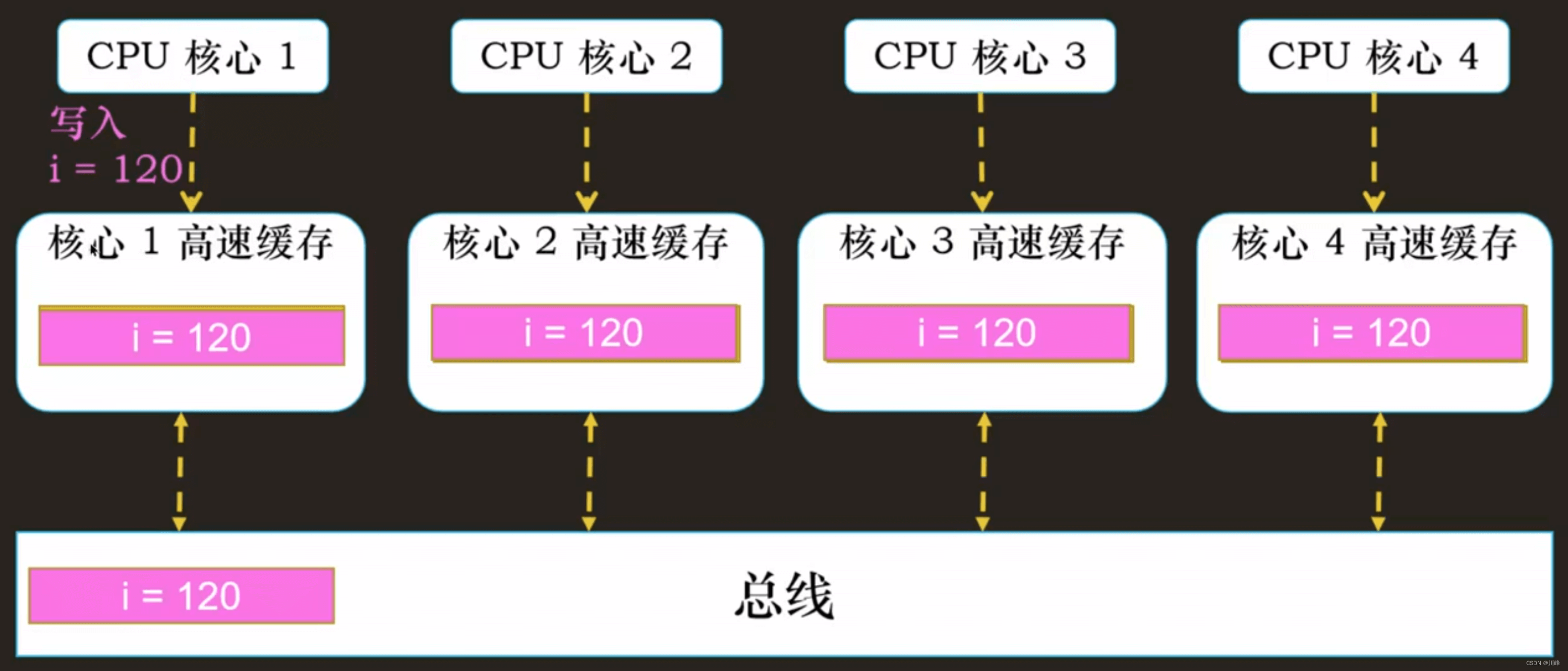
写失效 VS 写广播
-
① 写广播在实现上自然很简单,但是写广播需要占用更多的总线带宽
-
② 写失效只需要告诉其他的 CPU 核心,哪一个内存地址的缓存失效了,但是写广播还需要把对应的数据传输给其他 CPU 核心。
各种缓存请求
处理器向高速缓存发出的请求包括:
- PrRd:处理器请求读取一个缓存块。
- PrWr:处理器请求改写一个缓存块。
总线方面的请求:
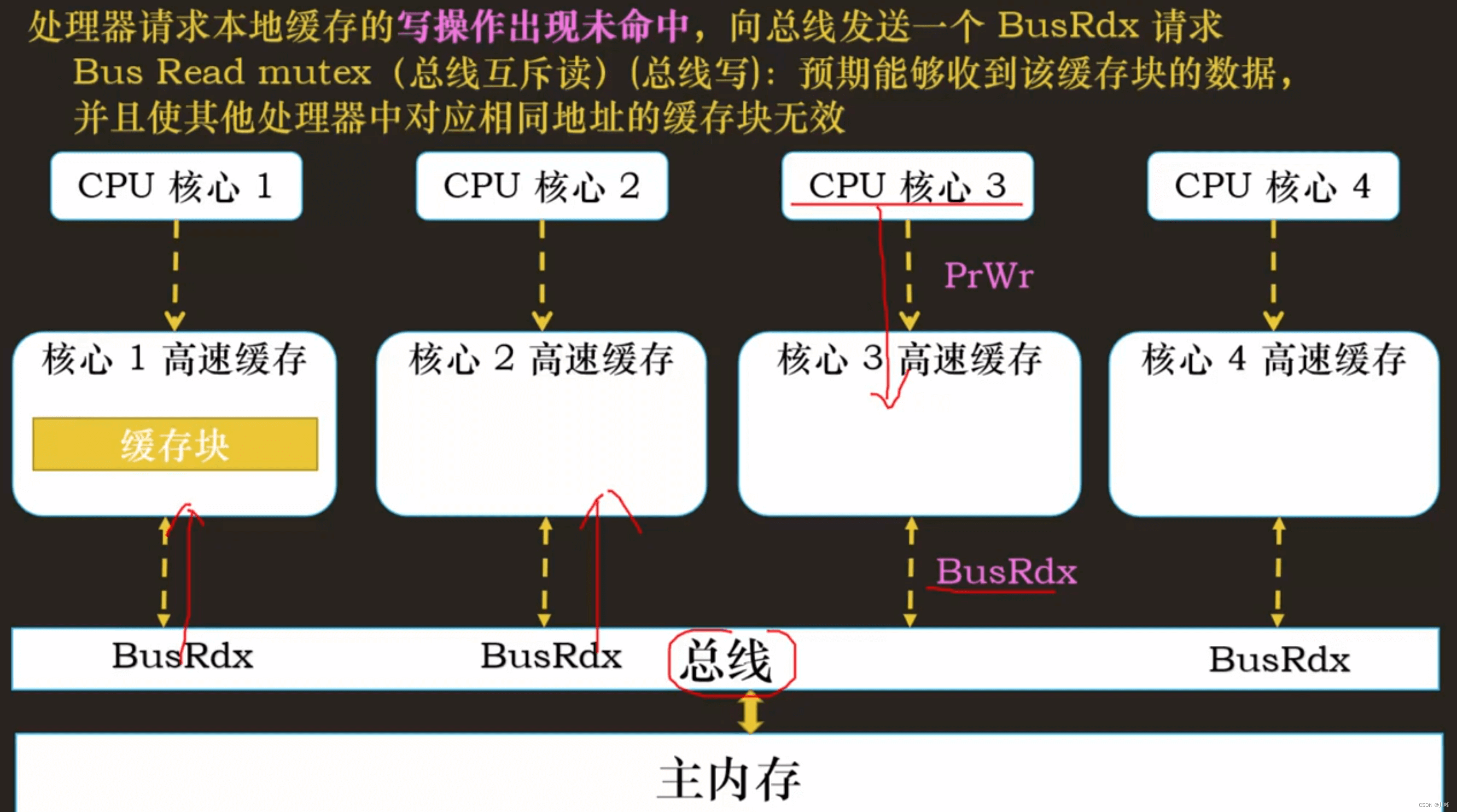
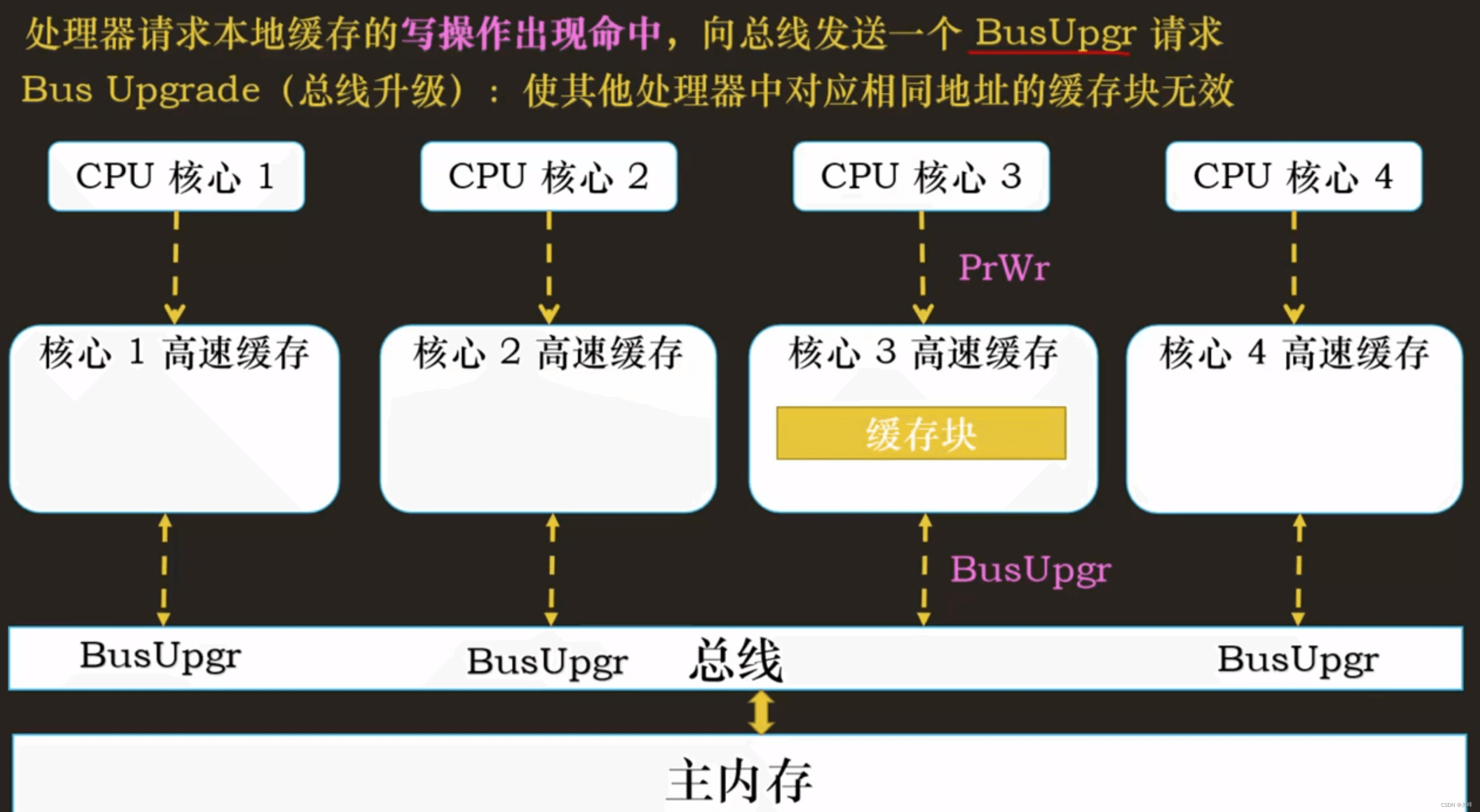
- BusRd:当处理器的请求缓存的读操作出现未命中,它会向总线发送一个BusRd请求
- BusRdX:当处理器请求缓存的写操作出现未命中,它会向总线发送一个BusRdX请求
- BusUpgr:当处理器请求缓存的写操作命中时,它它会向总线发送一个BusUpgr
- Flush:该请求表明一个缓存块正在被写回内存

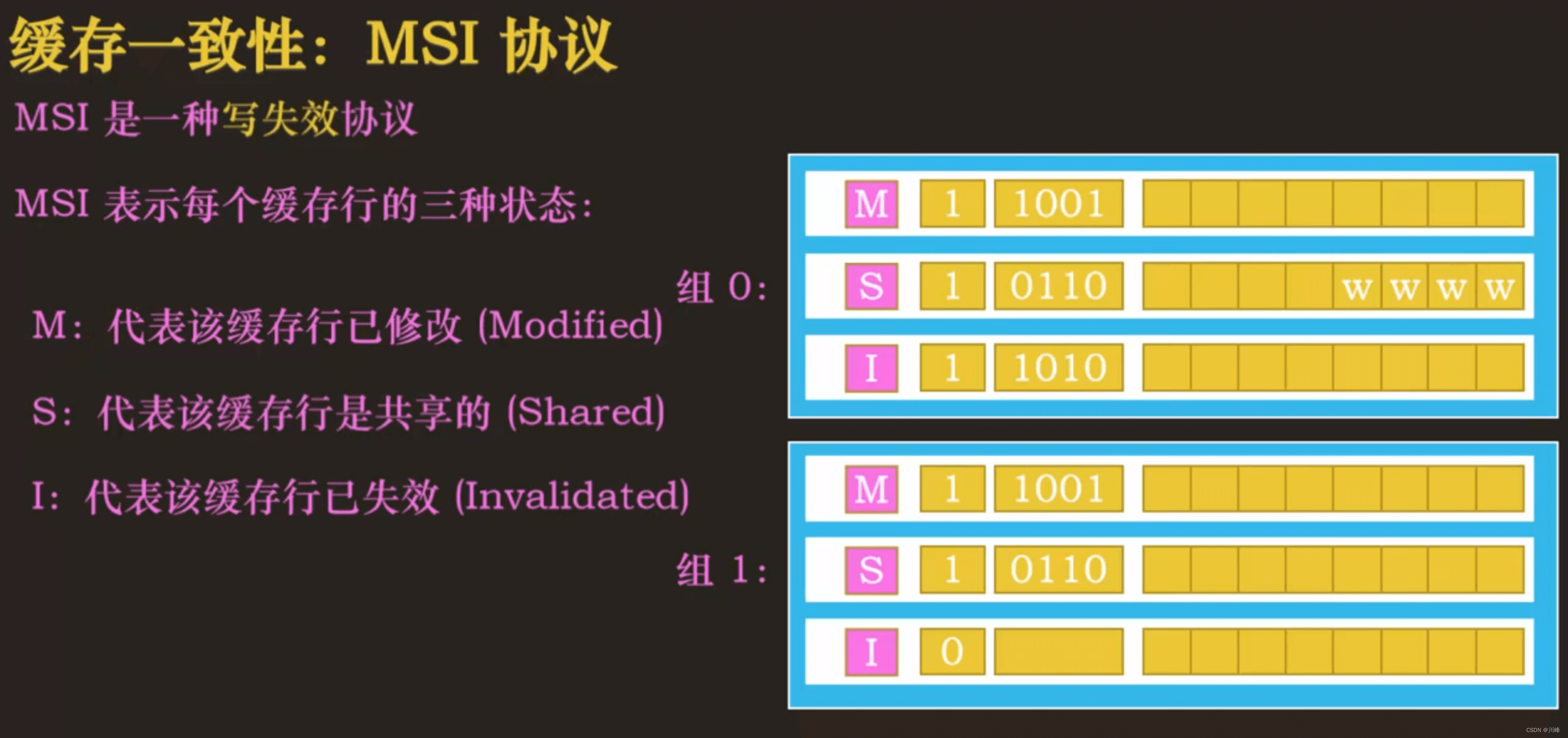
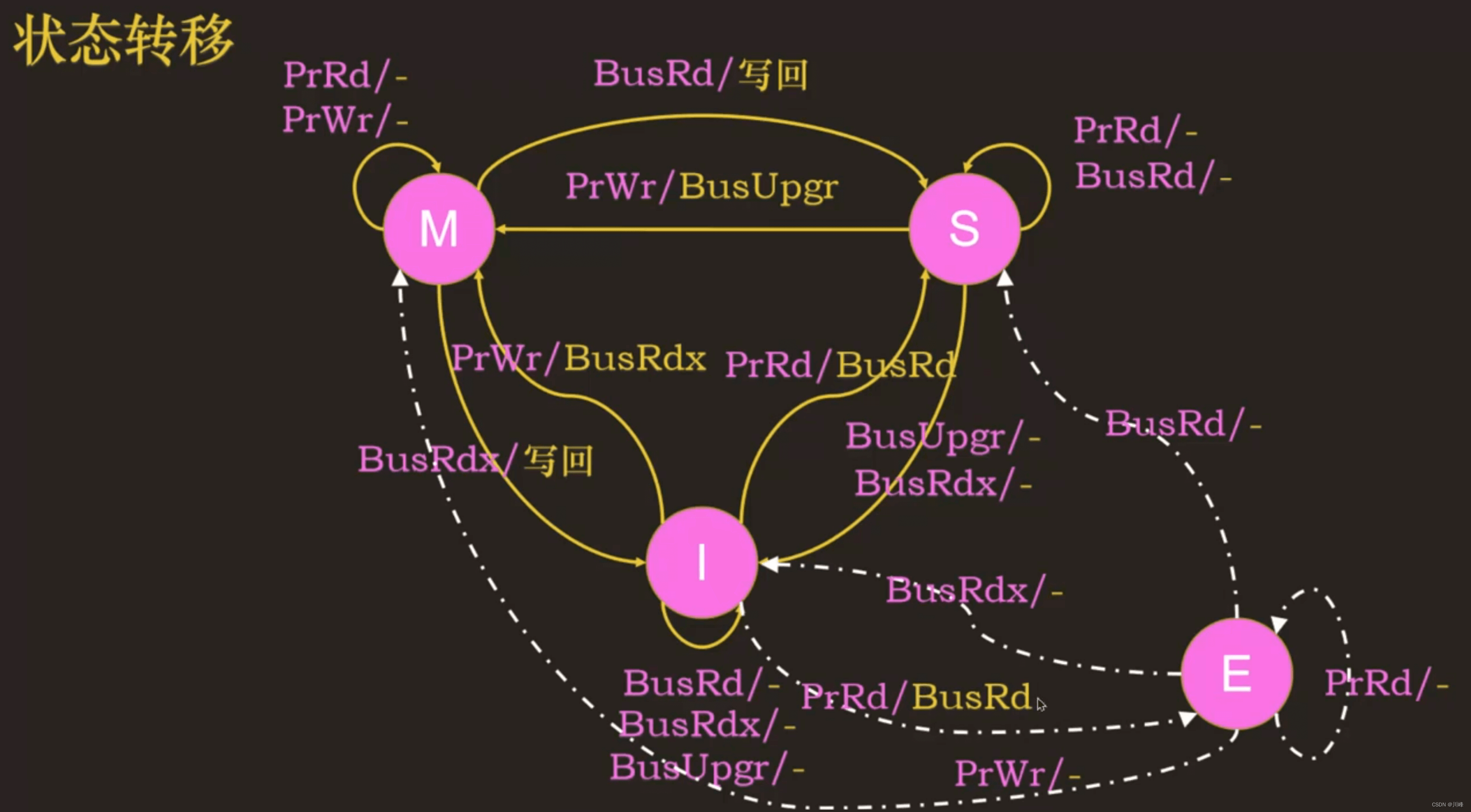
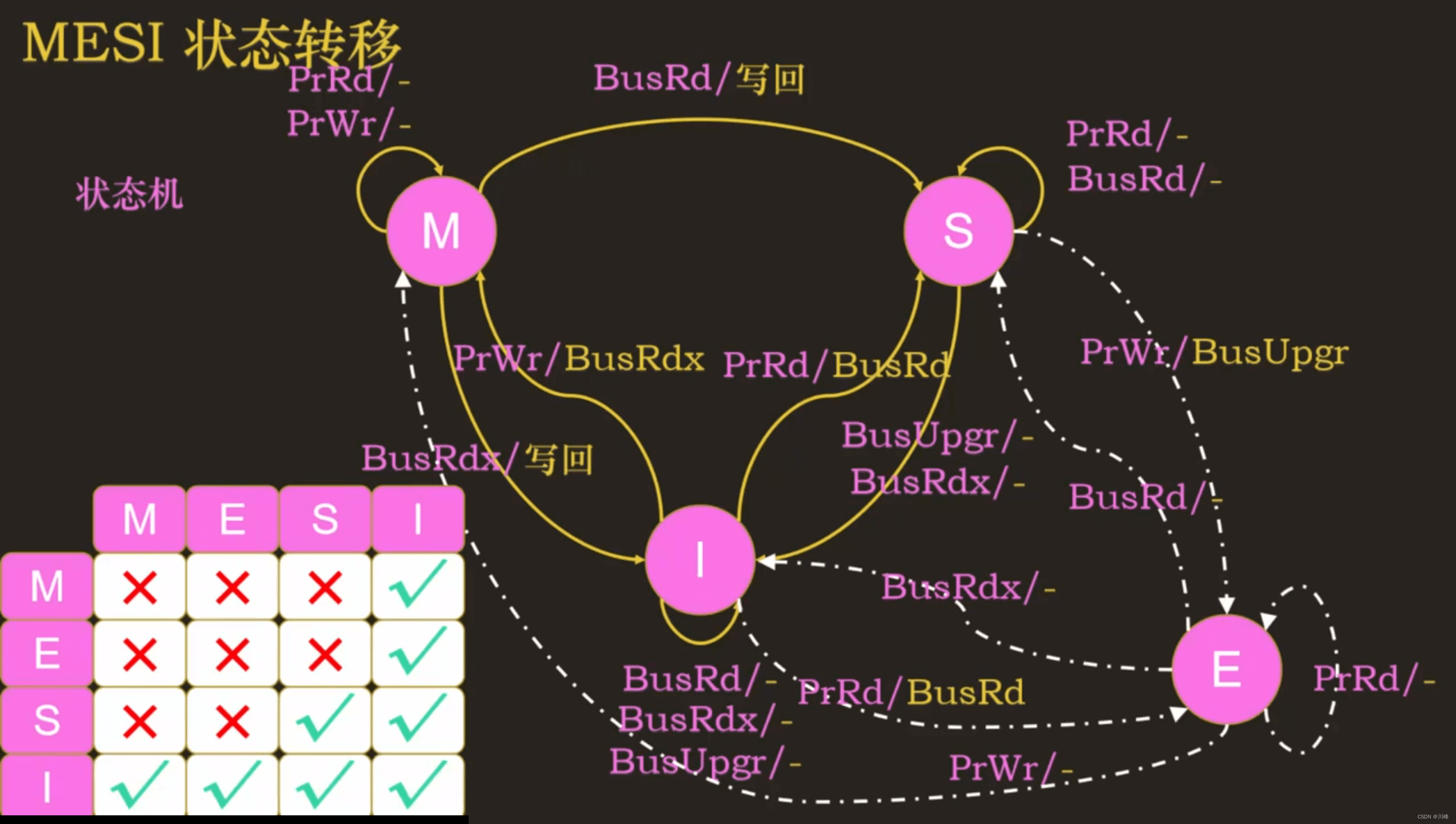
MSI协议和MESI协议
MSI协议
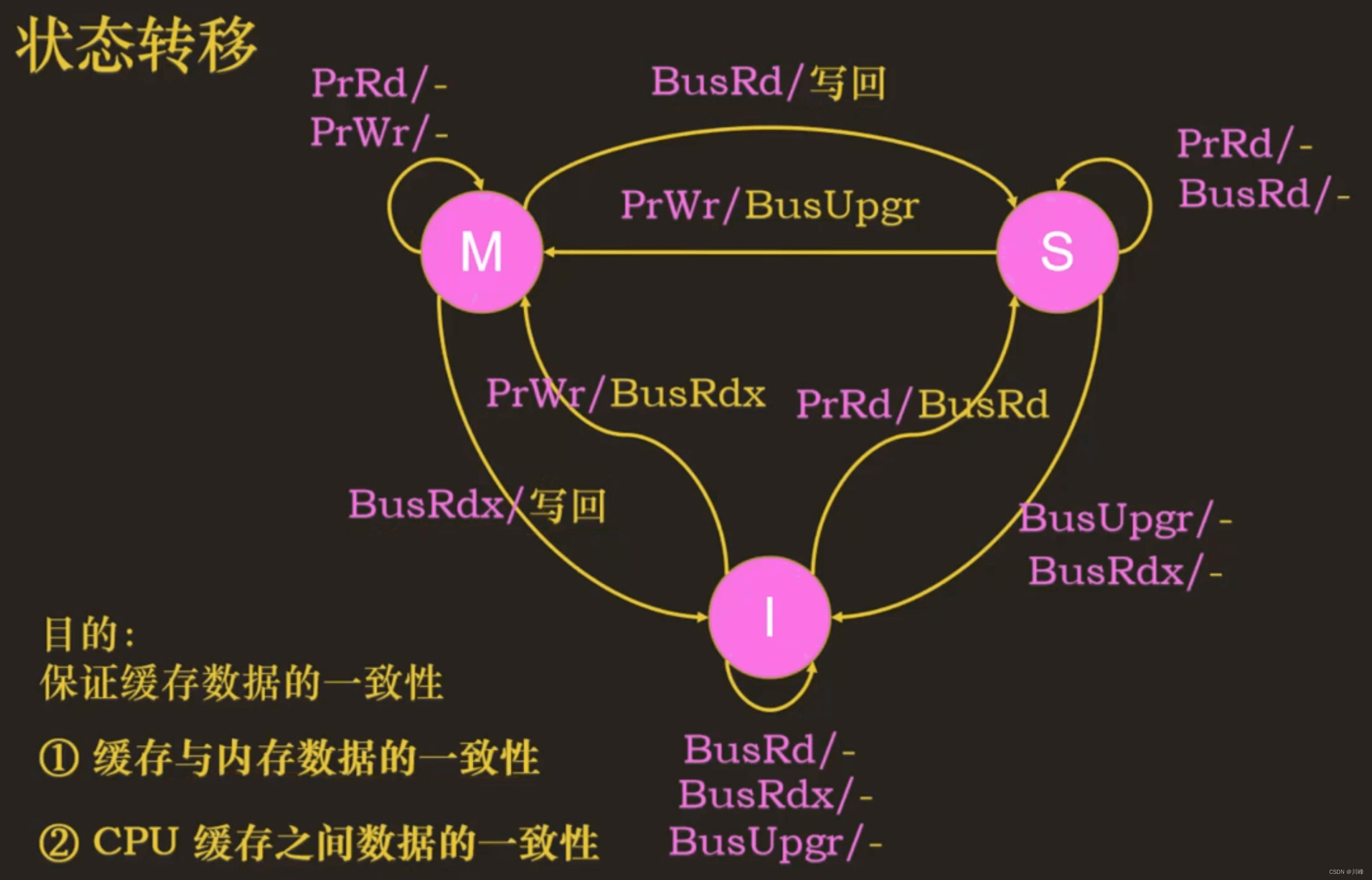
MESI 协议
MESI 协议通过引入 E 状态,来减少没有用的总线事务
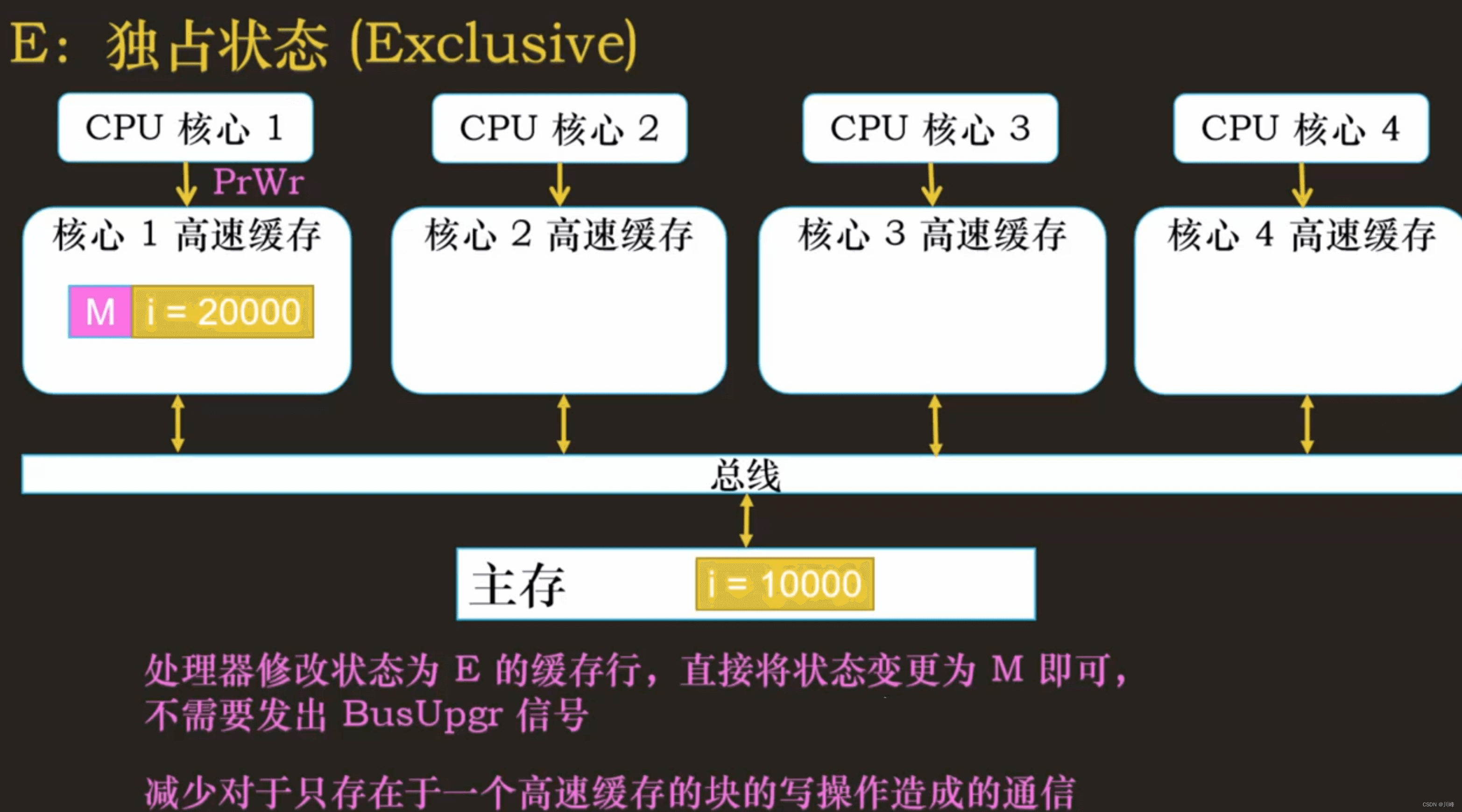
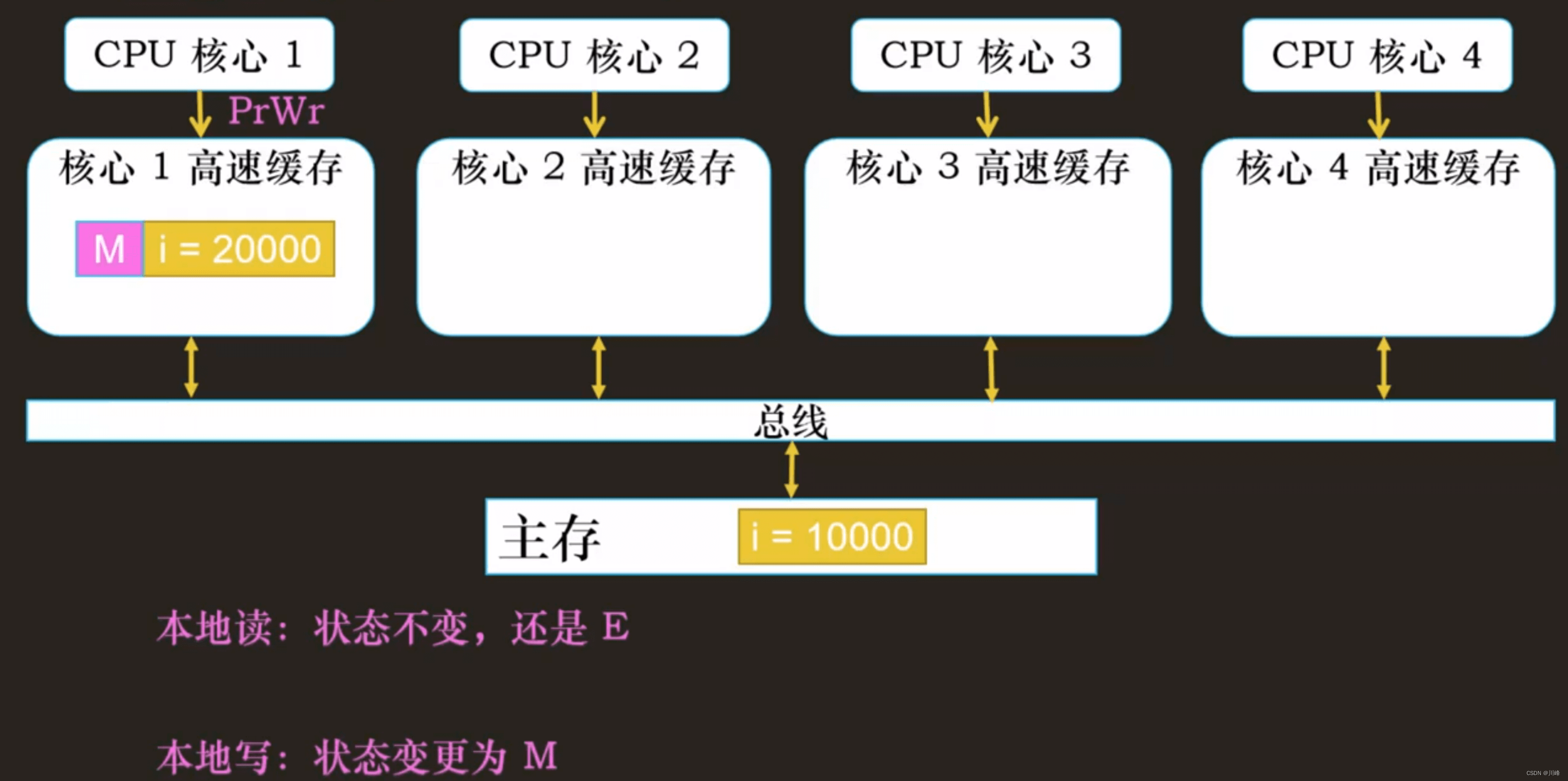
E:独占状态(Exclusive)
缓存行只在当前缓存中,但是干净的(clean) —— 缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。


MESI 属于硬件级别的协议
不管是信号的发送、传输、总线仲裁、缓存行的修改等都属于硬件级别的。所谓的硬件,本质上就是一堆电子电路而已。也就是说一般的话,CPU 高速缓存的一致性是由硬件保证的。不同的架构的CPU,提供不同的缓存一致性协议。MESI 是属于经典的,常用的缓存一致性协议,其他很多协议都是在 MESI 基础之上的优化。
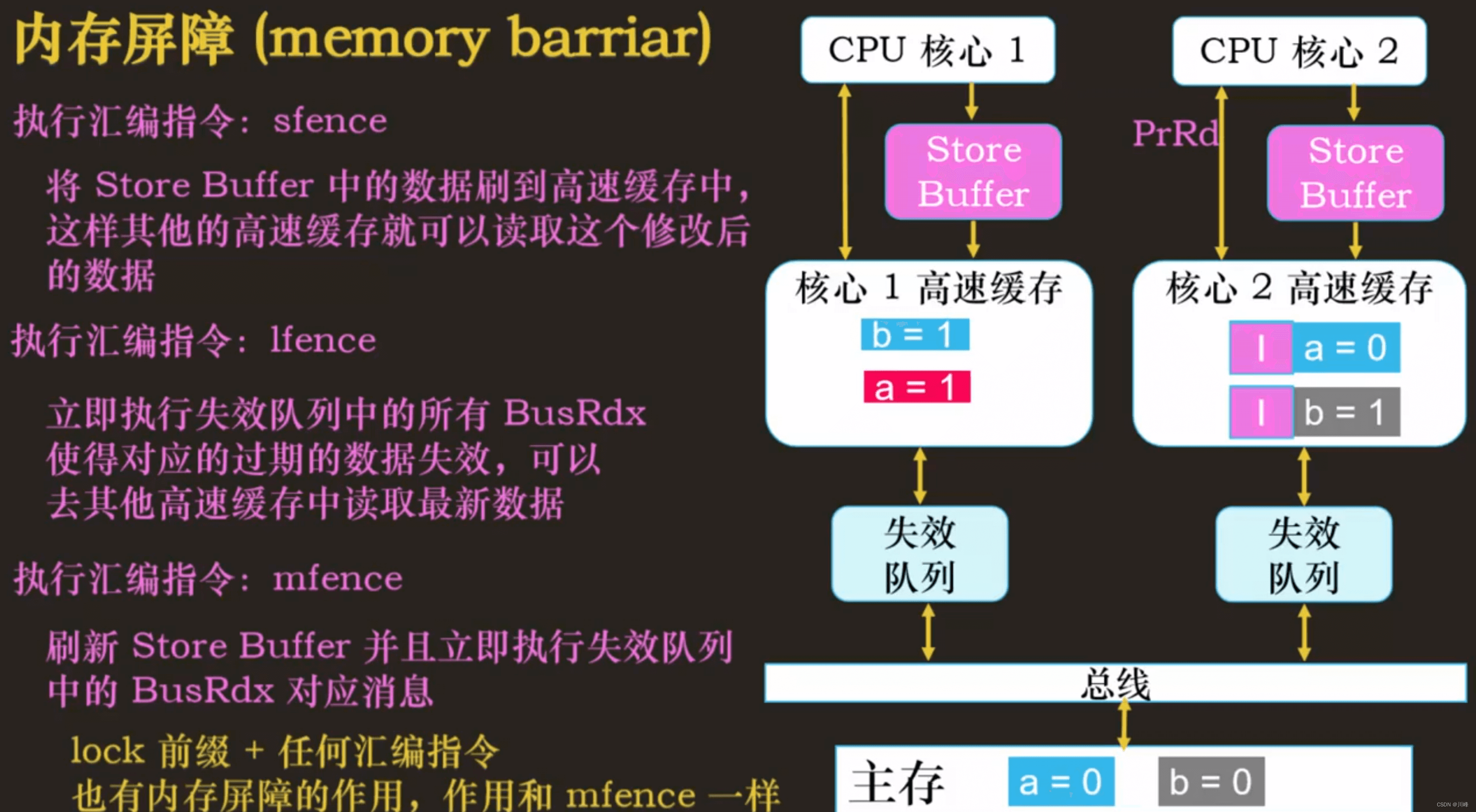
内存屏障
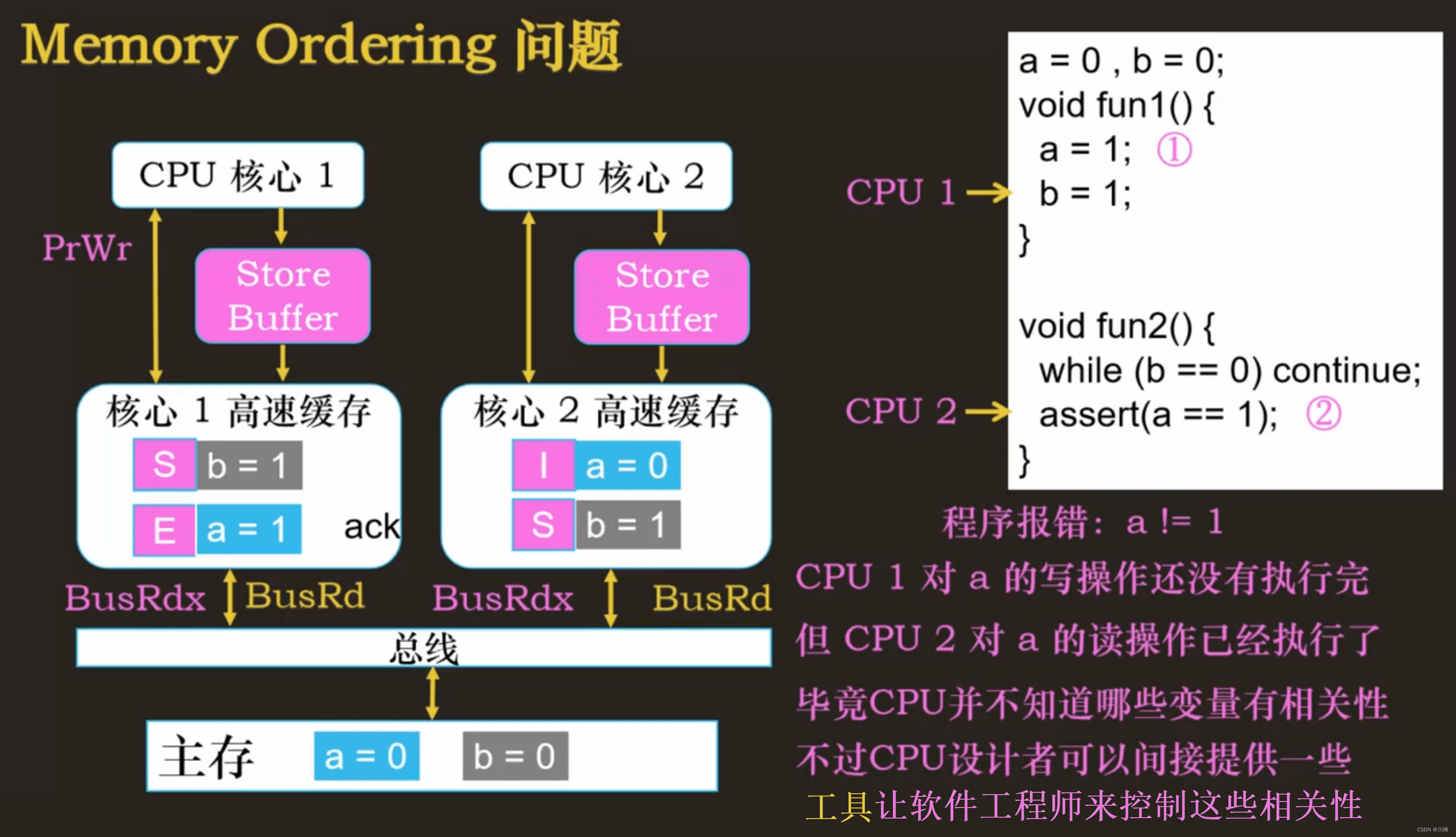
写内存屏障 - Store Memory Barrier
屏障之后的写操作必须等待屏障之前的写操作完成才可以执行。

引入 Store Buffer 的目的:提升 CPU 写操作的性能,导致 Store Buffer 与高速缓存中的数据不一致,CPU 每次先从 Store Buffer 读数据,没有的话再去高速缓存,可以解决数据不一致问题,但是解决不了 Memory Ordering 引起的问题 (内存访问顺序和程序设置的顺序不一致)。
读内存屏障
CPU 执行的任何的 load 操作都需要等到失效队列中所有标记信息完成对 cacheline 的操作之后才能进行。
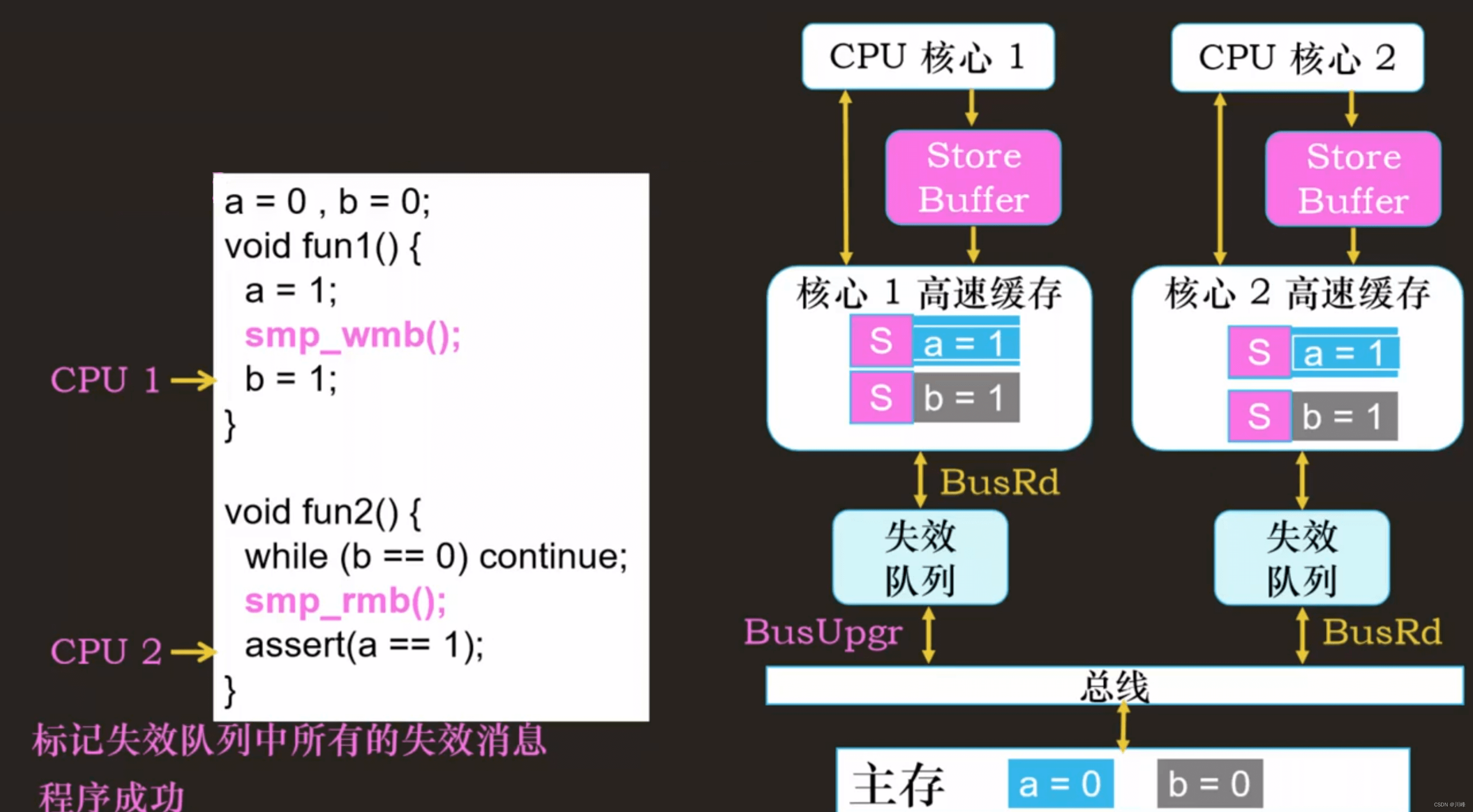
内存屏障总结
-
写内存屏障:解决 CPU 写操作乱序问题,或者叫存储 (Store) 操作乱序问题
-
读内存屏障:解决 CPU 读操作乱序问题,或者叫加载(Load) 操作乱序问题
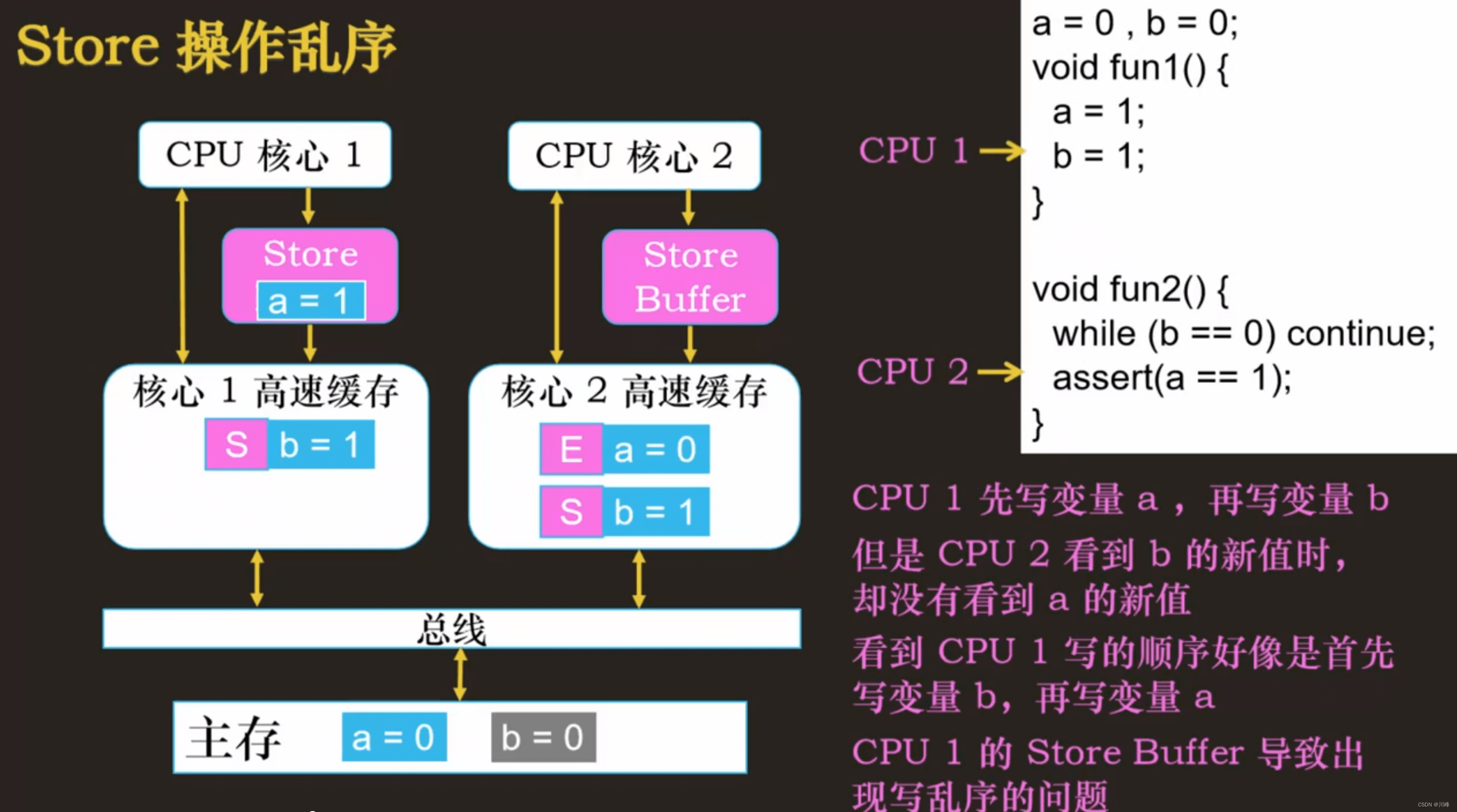

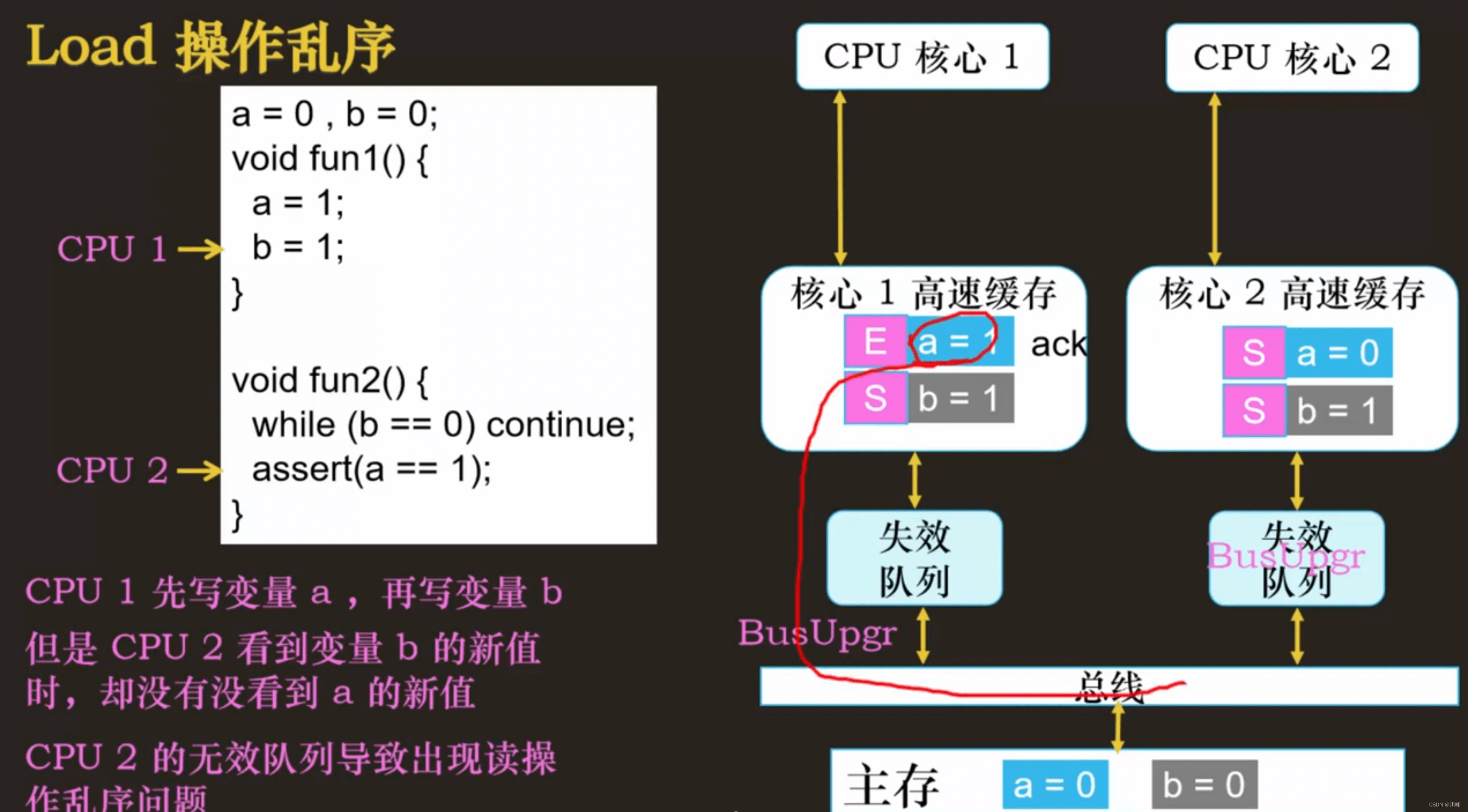

内存屏障 (memory barriar) 指令
- 写内存屏障:
smp_wmb()汇编指令:sfence(x86 ) - 读内存屏障:
smp_rmb()汇编指令:lfence(x86 ) - 读写内存屏障:
smp_mb()汇编指令:mfence(x86 )
屏障之前的读 / 写操作必须在屏障之后的读 / 写操作之前被执行。
锁内存总线
lock 前缀的底层实现
- 在多处理器下,为了保证一些操作的原子性,需要在这些操作前加上
lock,比如:lock addl ....,lock cmpxchg,lock inc ....
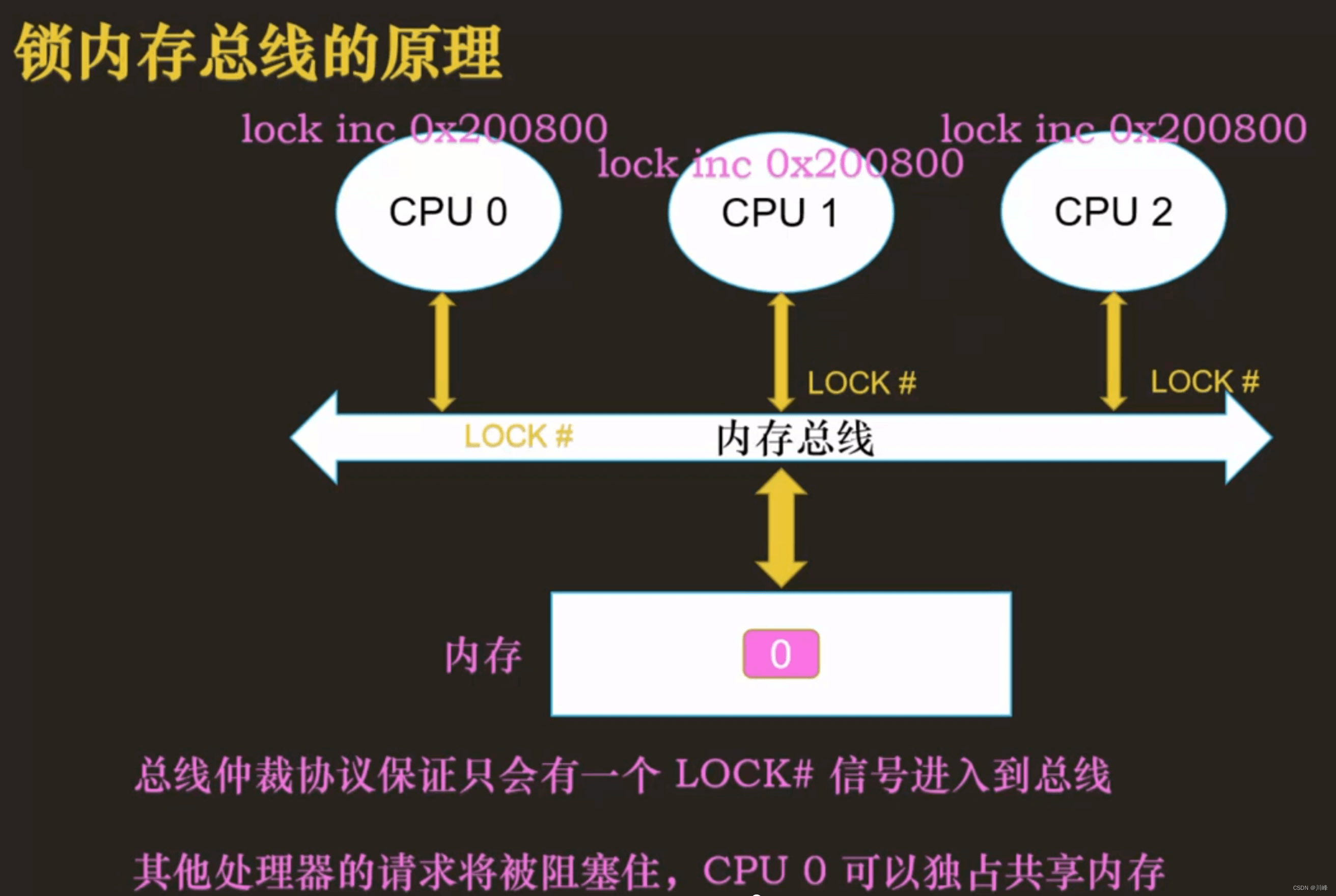
锁内存总线的缺点:其他处理器不能访问其他的内存地址中的数据了,所以锁内存总线的开销挺大的。
锁缓存行
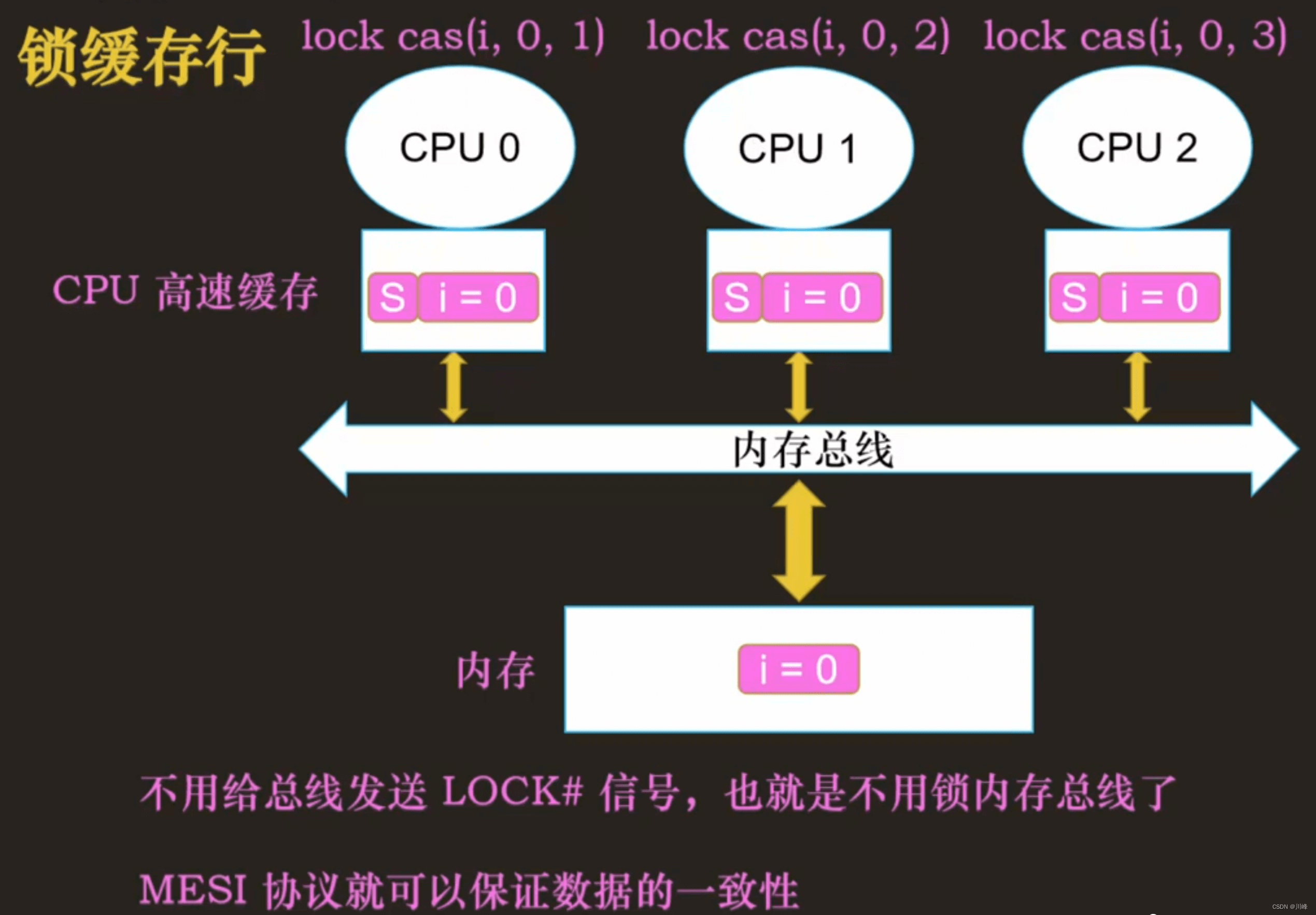

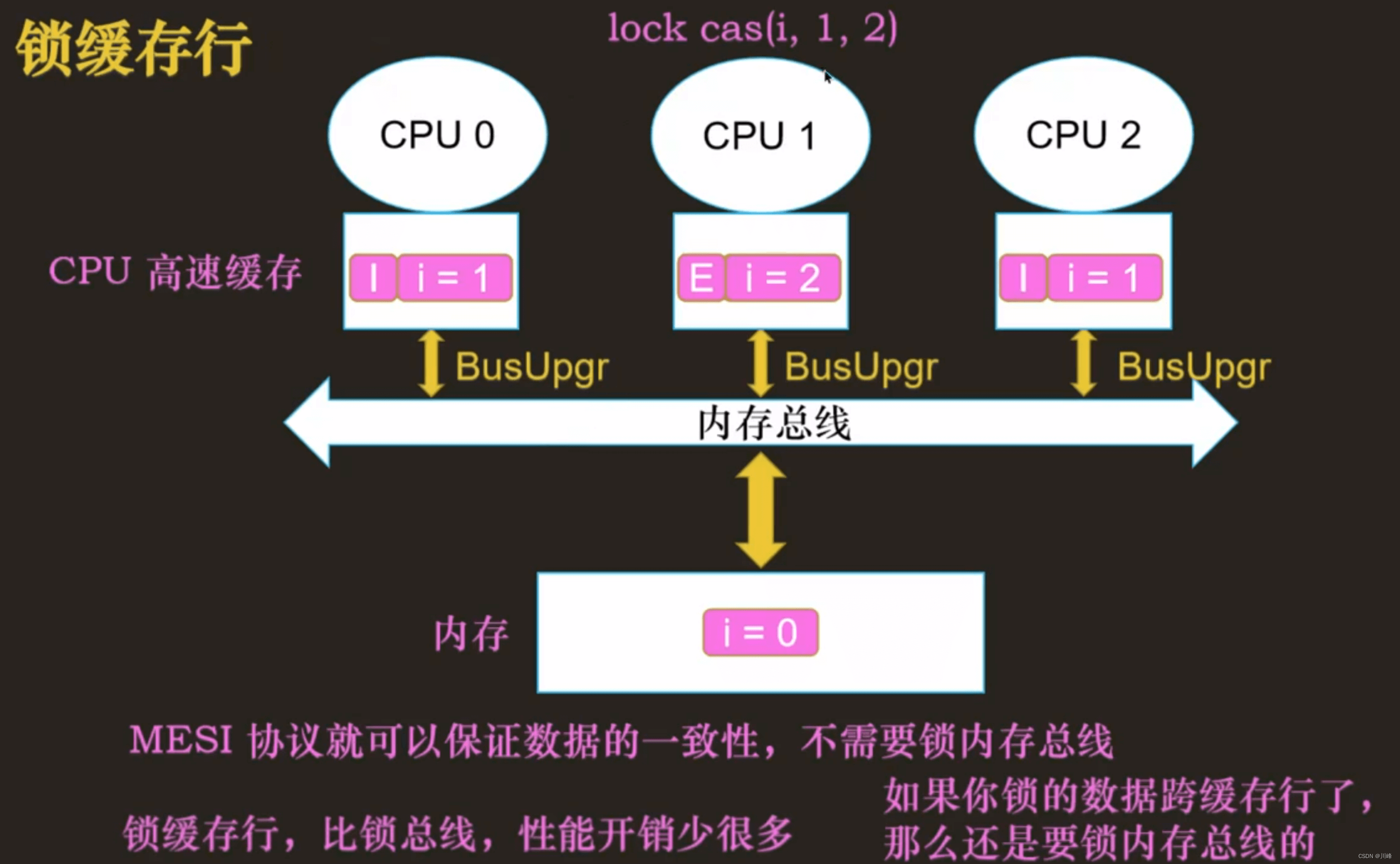
总结
-
Memory Ordering 问题:内存访问顺序和程序设置顺序不一致(指令重排序)
-
写内存屏障:解决 CPU 写操作乱序,或者叫存储(Store)操作乱序问题,屏障之后的写操作必须等屏障之前的写操作完成之后才可以执行
-
读内存屏障:解决 CPU 读操作乱序,或者叫加载(Load)操作乱序问题,屏障之后的读操作必须等屏障之前的读操作完成之后才可以执行
-
底层汇编指令前面加 lock 前缀可以起到内存屏障的作用,带有 lock 前缀的指令是原子操作
-
lock 在底层的实现原理是让某个 CPU 核心“锁定”内存总线,从而独占共享内存,但是此时其他 CPU 核心就不能访问内存数据了,所以锁内存总线的开销是很大的
-
MESI 协议是锁缓存行的协议,它从硬件层面保证缓存行的数据一致,无需锁内存总线,锁缓存行比锁内存总线的开销小