一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(三)步骤三、在Hive中建基础库维度表并加载MySQL中的维度表数据
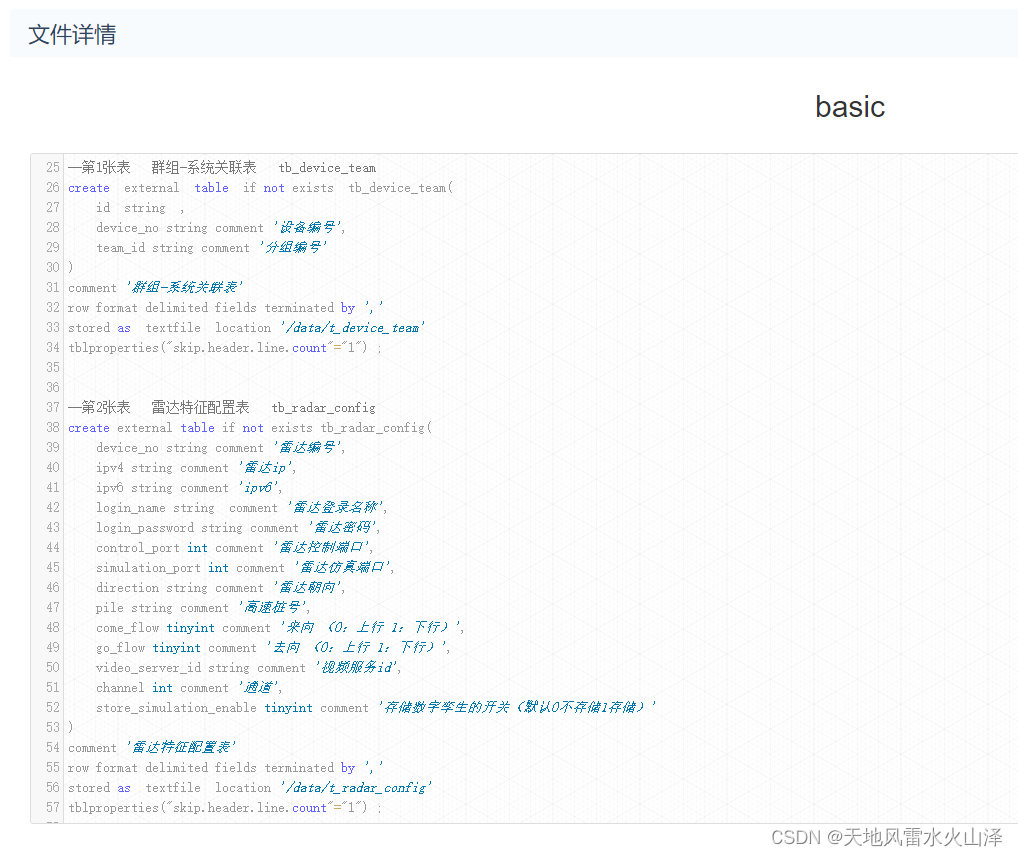
1、Hive基础库维度表的建库建表语句
--如果不存在则创建hurys_dc_basic数据库
create database if not exists hurys_dc_basic;
--使用hurys_dc_basic数据库
use hurys_dc_basic;
--第1张表 群组-系统关联表 tb_device_team
create external table if not exists tb_device_team(
id string ,
device_no string comment '设备编号',
team_id string comment '分组编号'
)
comment '群组-系统关联表'
row format delimited fields terminated by ','
stored as textfile location '/data/t_device_team'
tblproperties("skip.header.line.count"="1") ;
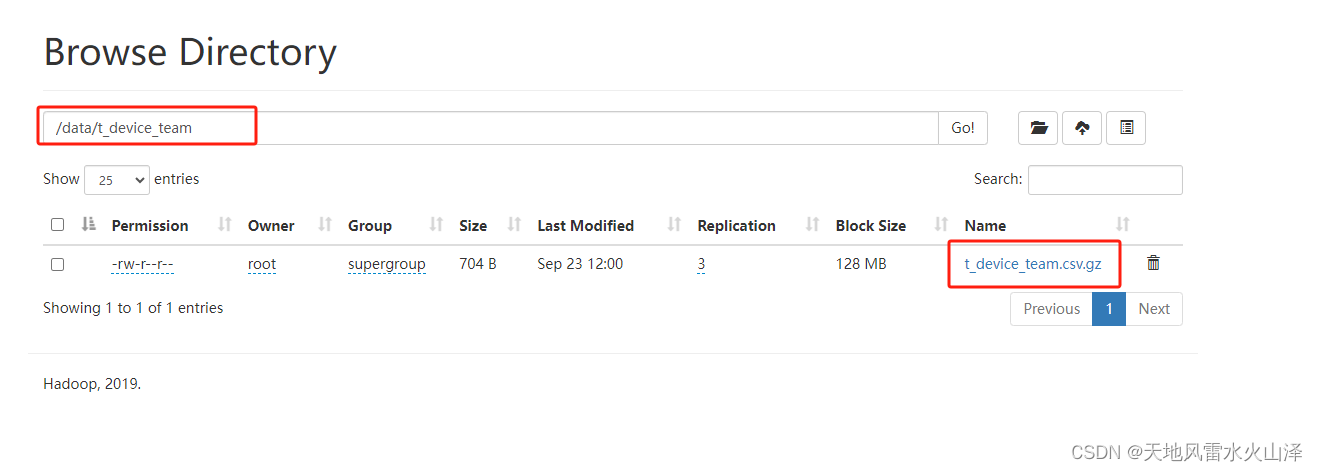
注意:由于维度表的数据量不大而且更新不频繁,所以建表语句直接加载文件夹中的数据
stored as textfile location '/data/t_device_team'
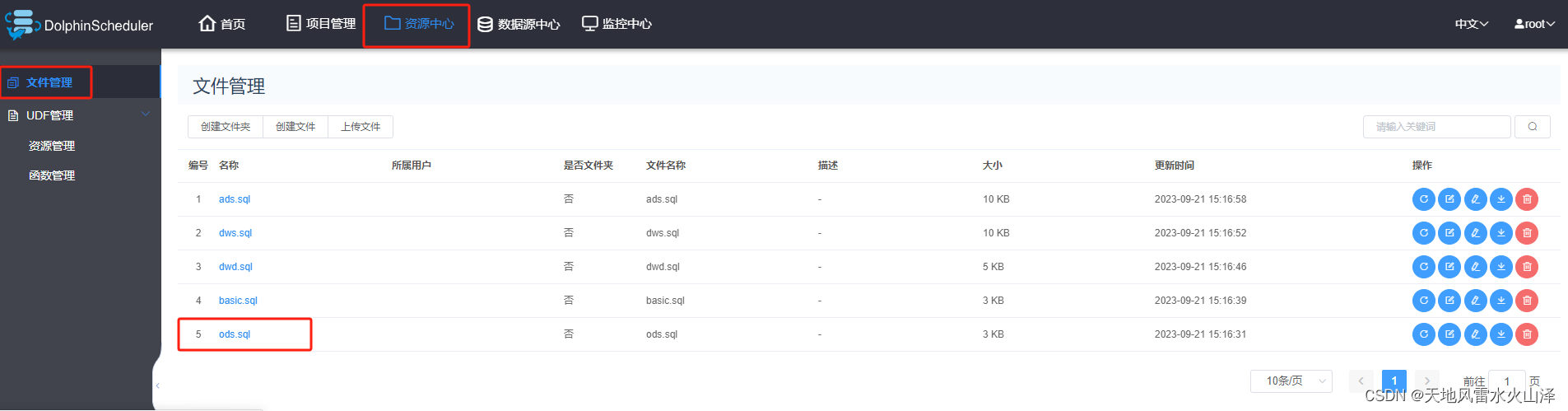
2、海豚执行基础库维度表的建表语句工作流
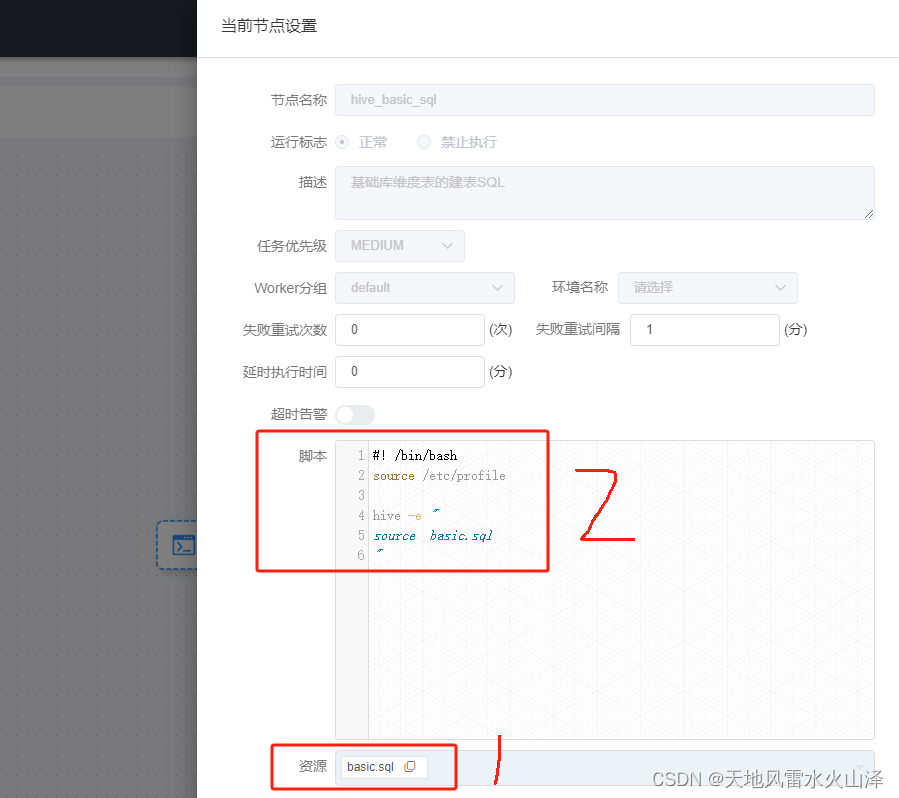
对于刚部署的服务器,由于Hive没有建库建表、而且手动建表效率低,因此通过海豚调度器直接执行建库建表的.sql文件
(1)海豚的资源中心加建库建表的SQL文件
(2)海豚配置基础库维度表的建表语句的工作流(不需要定时,一次就行)

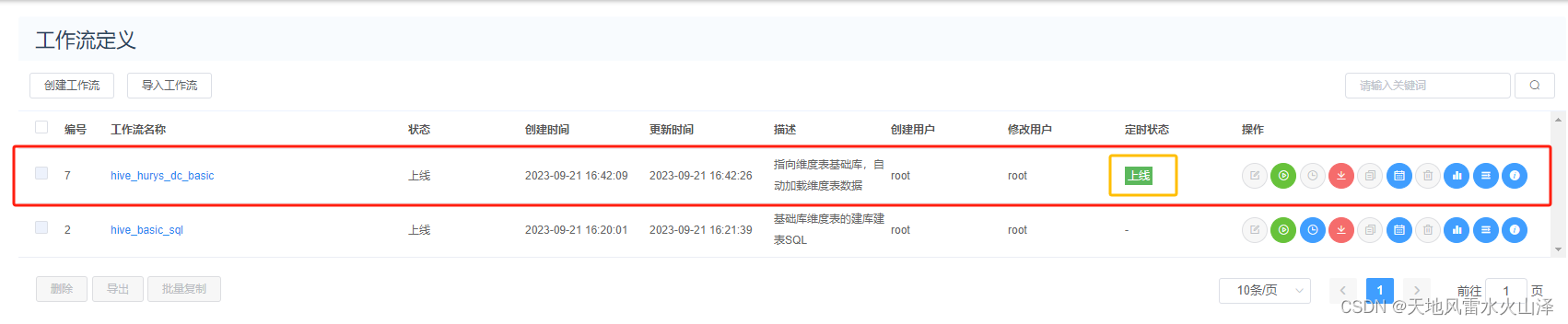
3、海豚配置基础库维度表每日加载MySQL数据的工作流
(1)海豚基础库维度表加载数据的工作流配置(需要定时,每日一次)
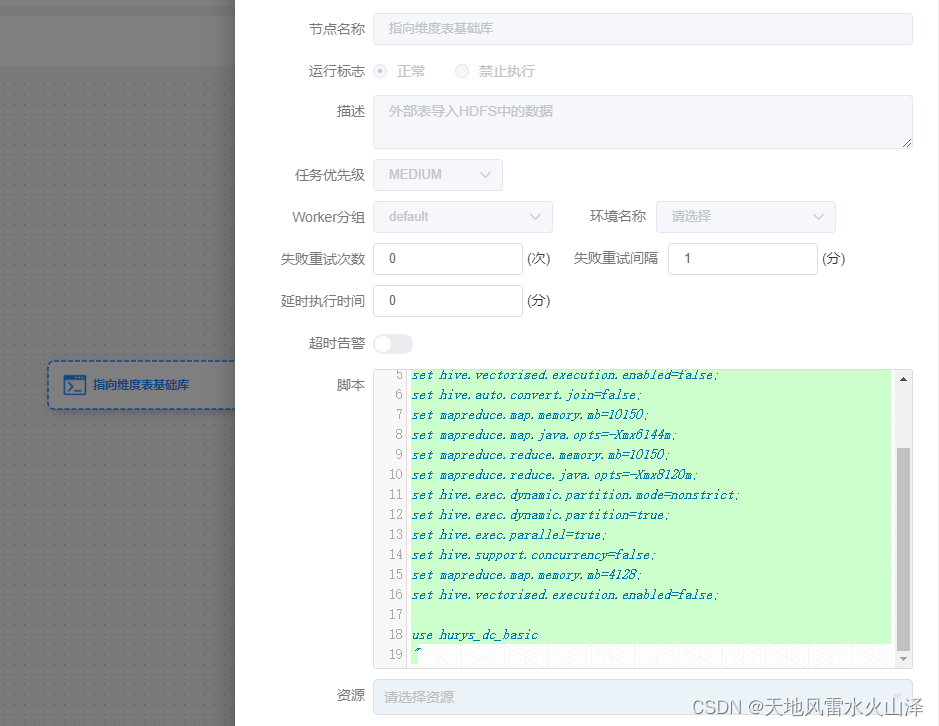
#! /bin/bash
source /etc/profile
hive -e "
set hive.vectorized.execution.enabled=false;
set hive.auto.convert.join=false;
set mapreduce.map.memory.mb=10150;
set mapreduce.map.java.opts=-Xmx6144m;
set mapreduce.reduce.memory.mb=10150;
set mapreduce.reduce.java.opts=-Xmx8120m;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
set hive.exec.parallel=true;
set hive.support.concurrency=false;
set mapreduce.map.memory.mb=4128;
set hive.vectorized.execution.enabled=false;
use hurys_dc_basic
"
(2)工作流定时任务设置(注意与其他工作流的时间间隔)

(3)注意点
3.3.1 由于建表语句直接指向文件夹路径stored as textfile location '/data/t_device_team',因此每次加载文件数据时直接使用基础库即可use hurys_dc_basic,数据就会自动加载到外部表中
剩余数仓部分,待续!