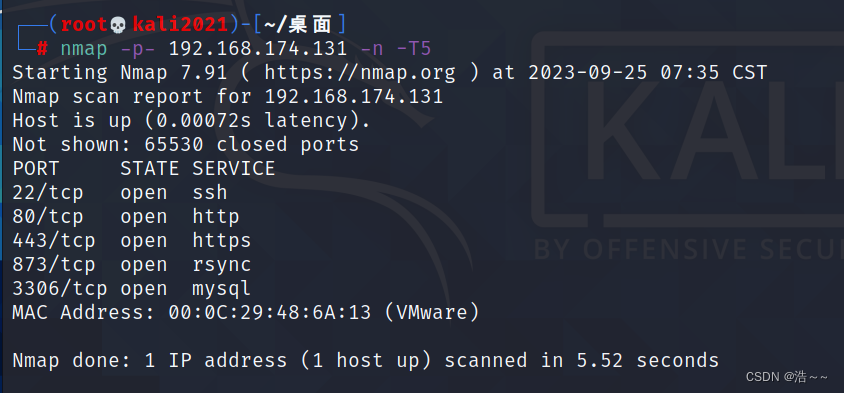
变量:名义型、有序型、连续型变量
名义型:普通事件类型,如糖尿病I型和糖尿病II型。
有序型:有顺序的事件类型,如一年级、二年级和三年级。
连续型:表示有顺序的数量,如年龄。
因子:名义型、有序型。
名义型会用123形容不同类型名称。
有序性会用1<2<3形容类型和顺序/程度。
用str(数据框)可以查看程度顺序。
stringAsFactors=FALSE:
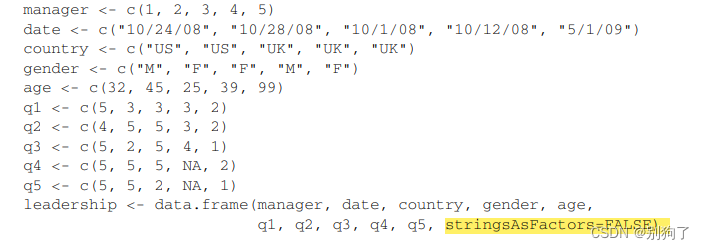
创建数据框的时候,会在data.frame的最后加一个stringsAsFactors=FALSE,是为了防止R把字符类型默认为因子。
标记为缺失值:
leadership$age[leadership$age==99] <- NA
将连续型,转化为有序型:
leadership$agecat[leadership$age <55] <- "young"
leadership$agecat[leadership$age >=55 & leadership$age <75] <- "middle aged"
leadership$age[leadership$age >= 75] <- "elder"
重命名列:
names(leadership)[6:10]<- paste("item",1:5,sep="")
删除所有有缺失值的行:
newdata <- na.omit(leadership)
类型转换:
as.类型()

剔除变量:
用名字剔除
myvars <- names(leadership) %in% c("q3","q4")
newdate <- leadership[!myvars]
筛选数据:
newdate <- leadership[leadership$age>30&leadership$gender=="M",]
随机抽样:
sample(),3表示抽3个,replace=FALSE表示无放回抽样。
mysample <- leadership[sample(1:nrow(leadership),3,replace=FLASE
SQL语句操作数据框:
加载sqldf包,library(sqldf)
library(sqldf)
newdf <- sqldf("select * from mtcars where crab=1 order by mpg",row.names=TRUE)


取平均值mean():
z <- mean(x, trim = 0.05, na.rm=TRUE)
trim的取值范围为0到0.5之间,表示在计算均值前需要去掉的异常值的比例。trim会在首尾分别去除N个异常值,其中N=样本数量*要去除的百分比(即是trim的值)
na.rm=TRUE <-- 把缺失值删除掉再计算。
中心化与标准化:
中心化:数值-均值
标准化:(数值-均值)/标准差
方差=标准差的平方
数据标准化的应用:
极差法:(原数据-极小值)/(极大值-极小值)*100
例如新的分数是140分满分,但是我们习惯于按照百分之去看分数。所以可以用极差法,将数值规制于百分制内,便于查看。