云计算与大数据——Spark的安装和配置
Spark的简单介绍:
Apache Spark是一个基于内存的分布式计算框架,它提供了高效、强大的数据处理和分析能力。与传统的Hadoop MapReduce相比,Spark的主要优势在于其能够将数据集缓存在内存中,从而大大减少了磁盘I/O操作,提高了数据处理速度。
Spark提供了多种编程接口,包括Scala、Java、Python和R等,同时还提供了交互式Shell,易于使用和快速调试。Spark的核心是分布式的RDD(Resilient Distributed Datasets),它对数据进行了抽象和封装,方便了数据的处理和管理。
Spark还可与多种数据存储系统集成,包括Hadoop HDFS、Apache Cassandra、Amazon S3等。同时,Spark还提供了多种高级库和工具,如Spark SQL、Spark Streaming、MLlib等,方便进行数据查询、流式处理和机器学习等任务。
总之,Spark已经成为了目前最受欢迎的大数据计算框架之一,广泛应用于数据处理、机器学习、实时数据处理等领域。

安装和配置
在安装和配置Spark之前,要确保Hadoop 已经成功安装,并正常启动。没有部署好hadoop的可以查看之前的文章。
云计算与大数据——部署Hadoop集群并运行MapReduce集群(超级详细!)
Spark安装在 HadoopMaster节点上。下面的所有操作都在HadoopMaster节点上进行。
1)解压并安装Spark
本文章所需要的spark安装包已上传到个人博客主页→资源处,有需要的小伙伴可以自行下载。
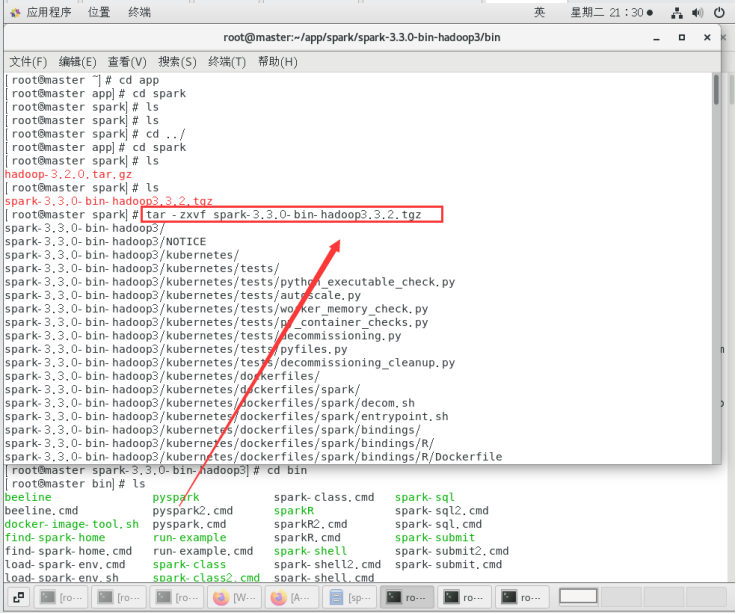
tar -zxvf spark-3.3.0-bin-hadoop3.3.2.tgz安装包
使用下面的命令,解压Spark 安装包:
tar -zxvf spark-3.3.0-bin-hadoop3.3.2.tgz
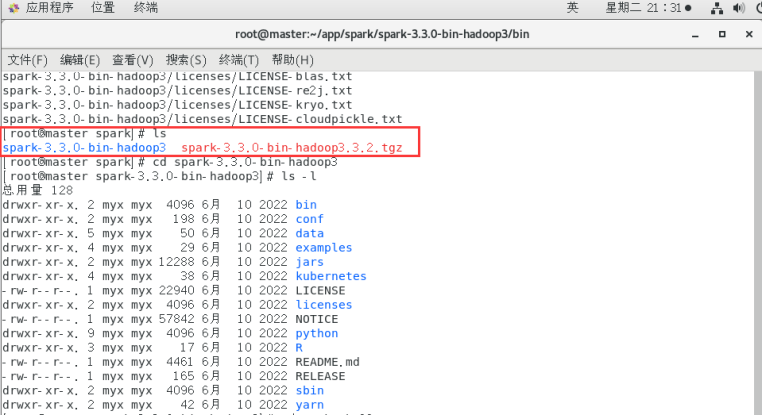
执行ls -l命令后的界面如下图所示,这些内容是Spark包含的文件。
cd bin
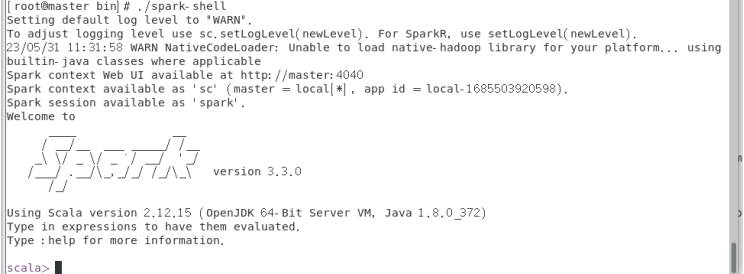
./spark-shell
执行spark-shell命令后的界面如图所示。
配置Hadoop环境变量
在Yarn上运行Spark需要配置环境变量
Vim ~/.bashrc
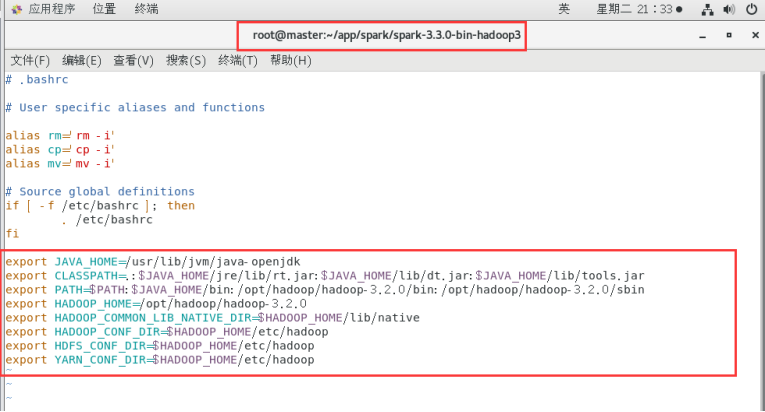
修改内容后保存退出。
Source ~/.bashrc
使配置生效。

验证spark安装
进入Spark安装主目录,执行如下命令。
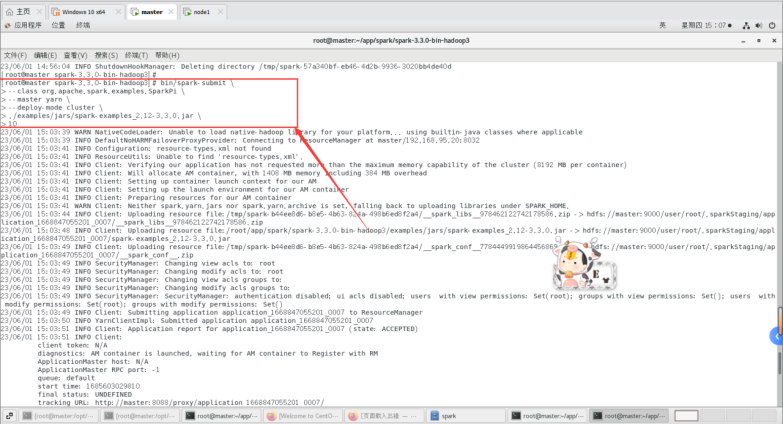
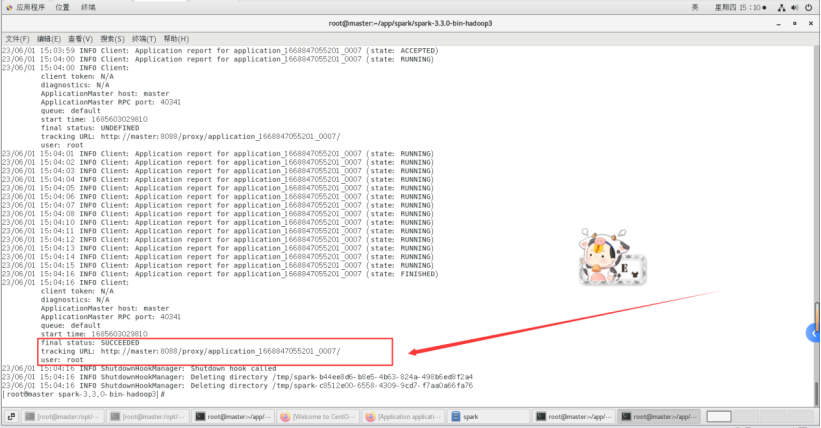
1.Spark 在YARN上运行,以集群模式启动Spark应用程序
这里指定使用 YARN 集群管理器作为主节点。
先执行这个命令:
bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode cluster \
> ./examples/jars/spark-examples_2.12-3.3.0.jar \
> 10
bin/spark-submit:启动 Spark 应用程序提交工具。
–class org.apache.spark.examples.SparkPi:指定要运行的 Java 类,这里使用了 Spark 官方提供的计算 pi 数值的例子程序 SparkPi。
–master yarn:设置 Spark 应用程序的主节点 URL,这里指定使用 YARN 集群管理器作为主节点。
–deploy-mode cluster:指定应用程序的部署模式。在这种模式下,Spark 驱动程序将在 YARN 集群中启动,并协调整个应用程序。另一种可选的部署模式是 client 模式,其中驱动程序会直接在提交命令的客户端上启动。
./examples/jars/spark-examples_2.12-3.3.0.jar:指定要提交的应用程序代码包的位置和名称。在这个例子中,使用了 Spark 的示例程序提供的 JAR 文件。
指定运行 Spark 应用程序时要传递给它的参数。在这个例子中,将计算 pi 数值的精度设置为 10。
启动脚本调用的是spark-submit,所以直接看bin/spark-submit脚本,跟spark-shell一样,先检查是否设置了${SPARK_HOME},然后启动spark-class,并传递了org.apache.spark.deploy.SparkSubmit作为第一个参数,然后把前面Spark-shell的参数都传给spark-class
–master 指定master节点
–class 指定执行的类
–executor-memory executor内存大小
–total-executor-cores 总的executor 数目
不对核心数目做限制的时候,是最快的。只有两个核心的时候,很慢。
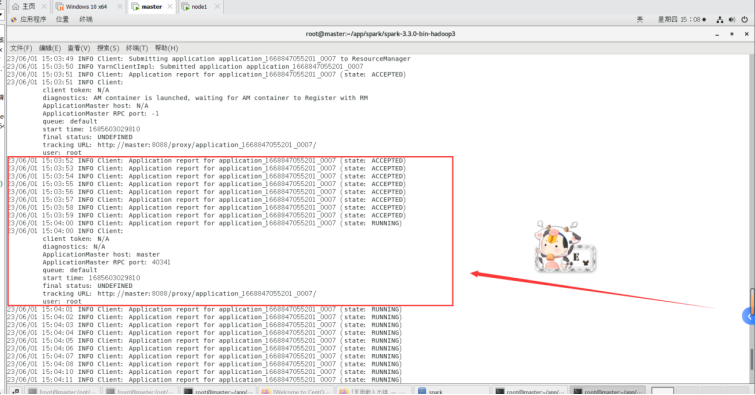
运行截图如下:
2.然后我们再这里设置为本地模式local并使用两个 CPU 核心启动。
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] --num-executors 2 --driver-memory 1g --executor-memory 1g --executor-cores 1 ./examples/jars/spark-examples_2.12-3.3.0.jar 10
其中
bin/spark-submit:启动 Spark 应用程序提交工具。
–class org.apache.spark.examples.SparkPi:指定要运行的 Java 类,这里使用了 Spark 官方提供的计算 pi 数值的例子程序 SparkPi。
–master local[2]:设置 Spark 应用程序的主节点 URL,这里设置为本地模式并使用两个 CPU 核心。实际上,Spark 可以连接到许多不同类型的集群管理器(例如 YARN、Mesos 或 Kubernetes)作为主节点。
–num-executors 2:设置 Spark 应用程序要使用的执行器数量。在本地模式下,这通常应该小于或等于计算机的 CPU 核心数。
–driver-memory 1g:设置驱动程序进程可以使用的内存量。 Spark 驱动程序负责协调整个应用程序,并将结果返回给客户端或保存到磁盘中。
–executor-memory 1g:设置每个执行器进程可以使用的内存量。执行器进程是 Spark 在集群中实际执行计算任务的工作者。
–executor-cores 1:设置每个执行器进程可以使用的 CPU 核心数量。
./examples/jars/spark-examples_2.12-3.3.0.jar:指定要提交的应用程序代码包的位置和名称。在这个例子中,使用了 Spark 的示例程序提供的 JAR 文件。
我们在这里指定运行 Spark 应用程序时要传递给它的参数。
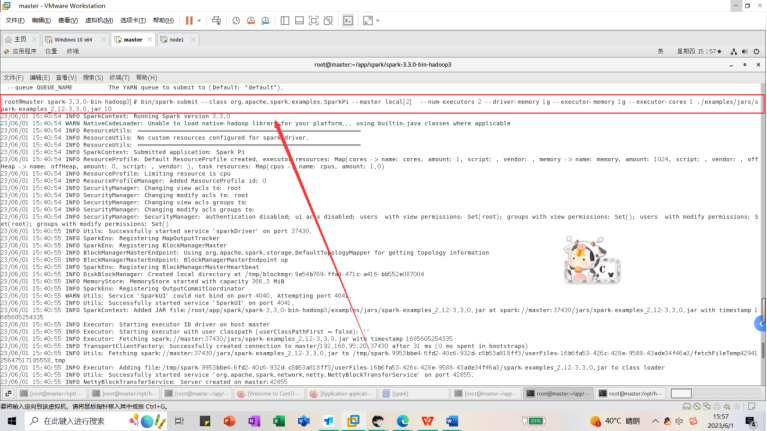
运行正常出现的界面信息:
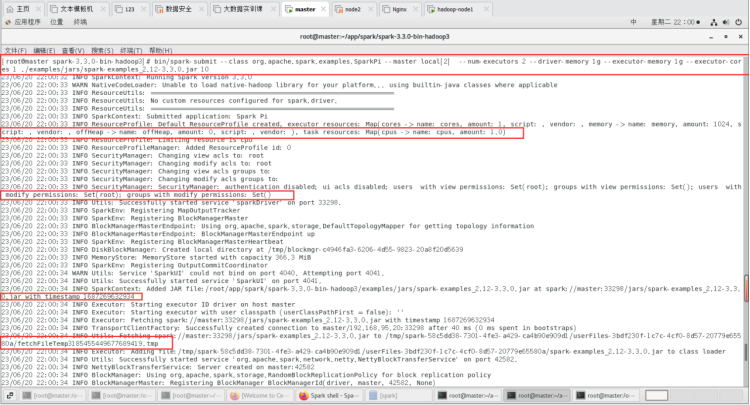
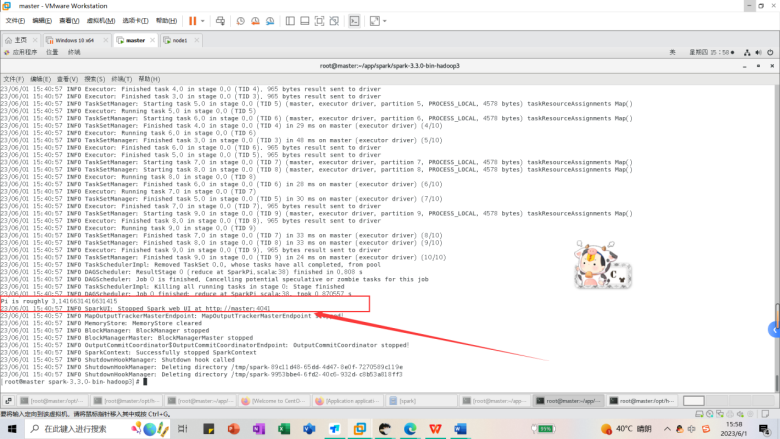
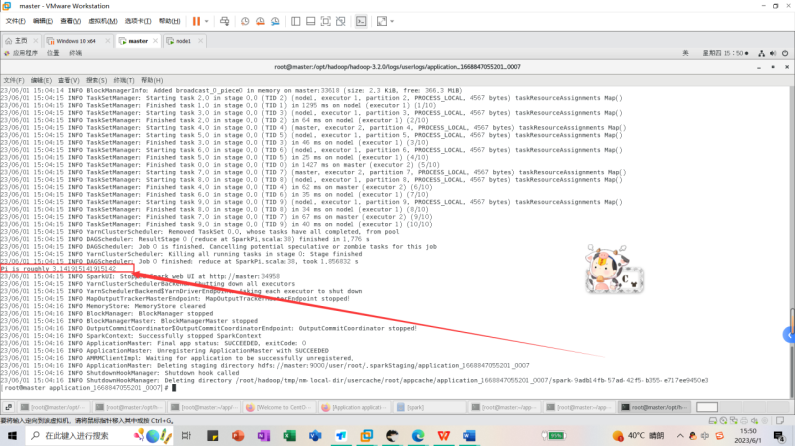
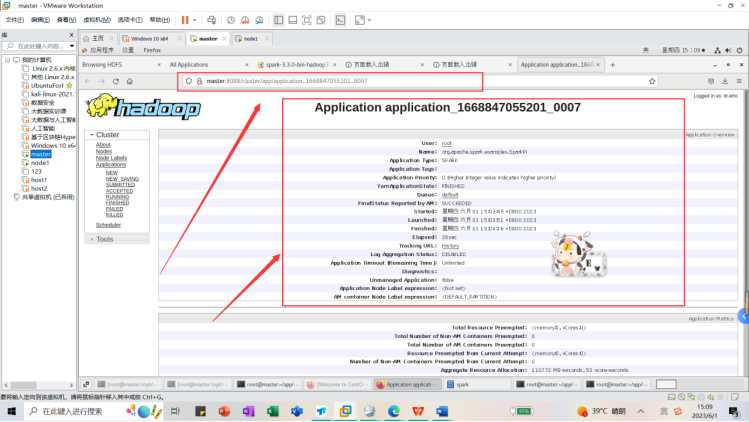
新建一个终端,进入到hadoop目录下的userlogs日志文件,找到了我们的spark应用结果日志文件,可以在里面找到计算结果和相关信息。
cd $HADOOP_HOME/logs/userlogs
ls
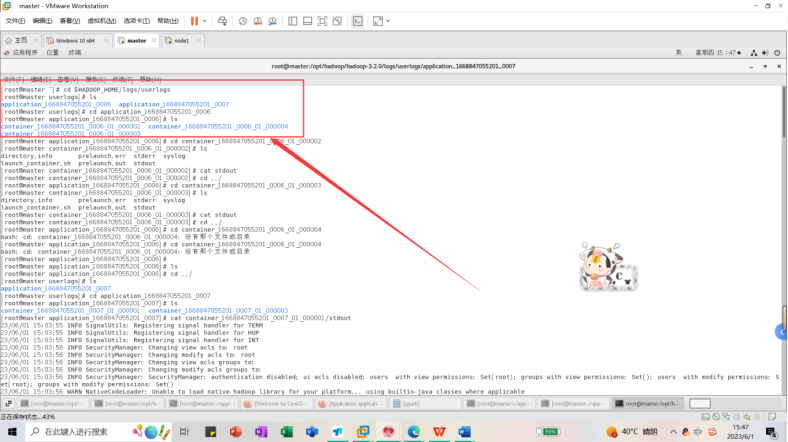
cd application_1668847055201_0007
ls

查看执行结果文件信息
cat container_1668847055201_0007_01_000001/stdout
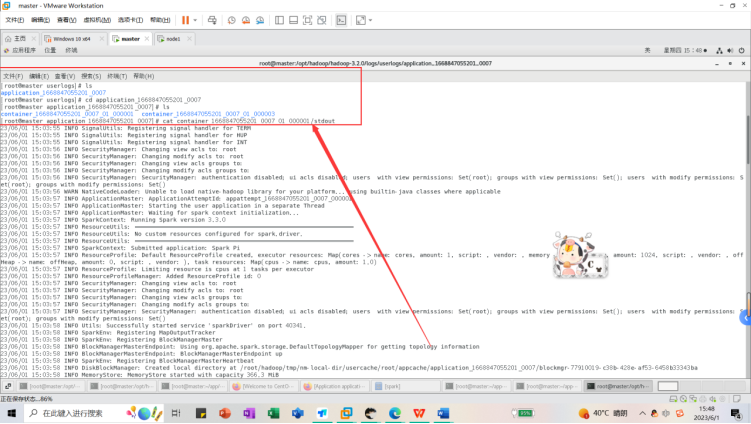

其中计算结果和相关运行信息如下图所示。我们可以看到Spark 应用程序成功地计算出了 pi 数值的近似值,并将结果打印到了控制台上。结果中的 Pi is roughly 3.1416631416631415 表示计算出的 pi 的近似值为 3.1416631416631415。