1、 数据融合的算法
数据融合的算法当中,需要对每一个格点i进行逐个计算,公式如下
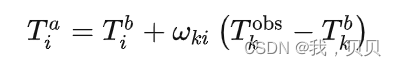
2、出现的问题
但是随着背景场的空间分辨率的提高,格点数急剧增加。如空间分辨率为0.01°的话,那么15°✖15°的空间范围内就有1500✖1500个格点。那么在进行逐个格点计算的过程中,就非常耗时间。
3、编程
我先按照逐点计算并赋值给DataArray的点的思路进行编程。代码如下:
##对dataarray的每个点进行赋值
def change(da):
for i in range(len(da.i.values)):
for j in range(len(da.j.values)):
da.loc[i,j] = i+j+3
time.sleep(0.01)
import numpy as np
import xarray as xr
import time
if __name__ == '__main__':
#构造一个dataarray
n_wei = 1500
data = np.random.rand(n_wei, n_wei)
i = list(range(n_wei))
j = list(range(n_wei))
da = xr.DataArray(data, coords=[i, j], dims=["i", "j"])
print(da)
###直接计算
st0 = time.time()
change(da)
print('不并行用时:',time.time()-st0,'秒')
总共用时606秒。
4、Threading
然后为了能够节省时间,想要把逐点计算的第一层循环,即i循环分为好几个并行任务使用并行计算。我在这里使用了threading库,代码如下:
import math
def chunks(arr, m): #把list arr分成m份,每份分给一个并行进程
n = int(math.ceil(len(arr) / float(m)))
return [arr[i:i + n] for i in range(0, len(arr), n)]
#对每个[ilist,j]纬度的dataarray进行change。
def start(da,ilist):
for i in ilist:
change(da,i)
##对dataarray的每个点进行赋值
def change(da,i):
for j in range(len(da.j.values)):
da.loc[i,j] = i+j+3
import numpy as np
import xarray as xr
import threading
import time
import os
#可能应该用multiprocessing而不是threading
if __name__ == '__main__':
n_wei = 1500
data = np.random.rand(n_wei, n_wei)
i = list(range(n_wei))
j = list(range(n_wei))
da = xr.DataArray(data, coords=[i, j], dims=["i", "j"])
print(da)
########开始并行
st = time.time()
#计算核数
max_cpu = os.cpu_count()
#设置并行数量
para_n = max_cpu
#把 i 行分为para_n个
para_list = chunks(list(range(n_wei)),para_n)
#设置并行任务
threads = []
for n in range(para_n):
tmp = threading.Thread(target =start,args = (da,para_list[n]) ) ###用threading
threads.append(tmp)
tmp.start()
for t in threads:
t.join()
#查看结果
print(da)
print('thread总线程数:',para_n,'用时:',time.time()-st,'秒')
总共用时648秒。
为啥用了threading以后反而更慢了呢?我觉得原因可能像这个博文所示。
5、改用array进行赋值
然后,有朋友建议用array进行循环赋值,会比用dataarray进行循环赋值要快。
那么,就试试,直接循环代码如下:
##对dataarray的每个点进行赋值
def change(da):
for i in range(da.shape[0]):
for j in range(da.shape[1]):
da[i,j] = i+j+3
import numpy as np
import xarray as xr
import threading
import time
import multiprocessing
from multiprocessing import Pool
if __name__ == '__main__':
#构造一个dataarray
n_wei = 1500
data = np.random.rand(n_wei, n_wei)
###直接计算
st0 = time.time()
change(data)
print('不并行用时:',time.time()-st0,'秒')
用时0.48秒!
用了threading的代码如下:
import math
def chunks(arr, m): #把list arr分成m份,每份分给一个并行进程
n = int(math.ceil(len(arr) / float(m)))
return [arr[i:i + n] for i in range(0, len(arr), n)]
#对每个[ilist,j]纬度的dataarray进行change。
def start(da,ilist,n_wei):
for i in ilist:
change(da,i,n_wei)
##对dataarray的每个点进行赋值
def change(da,i,n_wei=1000):
for j in range(n_wei):
da[i,j] = i+j+3
import numpy as np
import xarray as xr
import threading
import time
import os
#可能应该用multiprocessing而不是threading,但是multiprocessing不能在jupyter notebook里面用
if __name__ == '__main__':
n_wei = 1500
data = np.random.rand(n_wei, n_wei)
i = list(range(n_wei))
j = list(range(n_wei))
print(data)
###如果不并行
st0 = time.time()
start(data,i,n_wei)
print('不并行用时:',time.time()-st0,'秒')
########开始并行
st = time.time()
#计算核数
max_cpu = os.cpu_count()
#设置并行数量
para_n = max_cpu
#把 i 行分为para_n个
para_list = chunks(list(range(n_wei)),para_n)
#设置并行任务
threads = []
for n in range(para_n):
tmp = threading.Thread(target =start,args = (data,para_list[n],n_wei) ) ###用threading
threads.append(tmp)
tmp.start()
for t in threads:
t.join()
#查看结果
print(data)
print('总线程数:',para_n,'用时:',time.time()-st,'秒')
总共用时0.44秒!
啊,那是不是不用并行了,直接改用array循环赋值就行了?
然后,我把这个思路用在正式的数据融合计算中,结果发现,确实有节省时间,但是还是花费了很久,因为真正的数据融合计算中,每个格点的计算并不是像这个例子里面那么简单。
所以,我还是需要考虑并行计算的问题。接下来,参考和鲸社区的这个帖子进行并行计算的尝试。
6、multiprocessing和pool
首先有一点,jupyter notebook不支持multiprocessing,在jupyter notebook中使用multiprocessing只会卡住。
所以,只能用.py后缀名的文件使用Multiprocessing。
并且,为了测试Multiprocessing的并行计算是否节省了计算时间,在计算的时候,加上time.sleep(0.01)。
代码如下:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import math
def chunks(arr, m): #把list arr分成m份,每份分给一个并行进程
n = int(math.ceil(len(arr) / float(m)))
return [arr[i:i + n] for i in range(0, len(arr), n)]
# In[2]:
#对每个[ilist,j]纬度的dataarray进行change。
def start(da,ilist):
for i in ilist:
change(da,i)
# In[3]:
##对dataarray的每个点进行赋值
def change(da,i):
for j in range(da.shape[1]):
da[i,j] = i+j+3
time.sleep(0.1)
# In[ ]:
import numpy as np
import xarray as xr
import threading
import time
import multiprocessing
import os
from multiprocessing import Pool
#
#可能应该用multiprocessing而不是threading,但是multiprocessing不能在jupyter notebook里面用
if __name__ == '__main__':
n_wei = 1500
data = np.random.rand(n_wei, n_wei)
i = list(range(n_wei))
j = list(range(n_wei))
# print(data)
###如果不并行
st0 = time.time()
start(data,i)
print('不并行用时:',time.time()-st0,'秒')
########开始并行
data = np.random.rand(n_wei, n_wei)
st = time.time()
###
max_cpu = os.cpu_count()
#设置并行数量
para_n = max_cpu
#把 i 行分为para_n个
para_list = chunks(list(range(n_wei)),para_n)
#设置并行任务
threads = []
for n in range(para_n):
tmp = multiprocessing.Process(target =start,args = (data,para_list[n]) ) ###用multiprocessing
threads.append(tmp)
tmp.start()
for t in threads:
# print(threading.current_thread().name)
# t.setDaemon(True)
# t.start()
t.join()
#查看结果
# print(data)
print('总线程数:',para_n,'用时:',time.time()-st,'秒')
# #####用pool试试
data = np.random.rand(n_wei, n_wei)
st1 = time.time()
with Pool(max_cpu) as p:
p.apply_async(change, args = (data,range(n_wei)) )
p.close()
p.join()
# print(p,data)
print('用pool:',time.time()-st1,'秒')
得到的结果如下:












](https://img-blog.csdnimg.cn/8cbbb88757914a878b64b40005140de6.jpg)