目录
- 前言
- 背景介绍
- 问题1
- 问题1解决方法
- 问题2
- 问题2 解决方法
- 总结
前言
本文记录了在使用QtCreator开发时遇到的一个错误,导致编译时出现大量的“未知标识符”,经过一番努力最终解决了这个问题,特在此记录。
背景介绍
Qt项目在麒麟V10 系统下运行正常,现需要在一台新的Wibdows系统PC机上安装开发环境,在装完Qt开发环境后,测试一切正常,准备同步项目源代码。源码在自己搭建的GitLab服务器上,所以我又安装了git最新的客户端(https://git-scm.com/download/win)和小乌龟git管理工具(https://tortoisegit.org/download/)。配置好git的账号信息后,把代码clone到本地准备编译。
问题1
用QtCreator打开项目进行编译,此时在问题对话框中出现大量的未知标识符错误。通过与其他windows系统下的项目文件比较发现是行尾不同,报错的PC上代码文件的行尾是LF,而其他正常的则是CRLF。
问题1解决方法
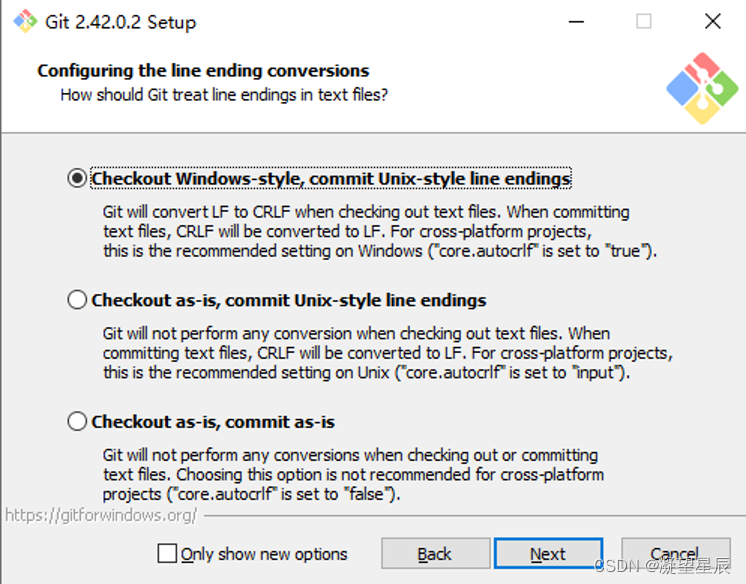
通过对比发现是win系统下的文件行尾有问题,这让我想起了在安装git时的一个配置项的选择,就是上图所示的行尾配置引导页,我选的是第三个 “Checkout as-is,commit as-is”。项目在麒麟V10系统下正常编译运行,其文件行尾是LF,该行尾在Windows下无法识别,导致编译报错。于是果断卸载git并重新安装,选择上图中第一个选项作为行尾配置。 把之前clone的代码删除后重新clone 后再次编译,不再有大量未知标识符的报错。
问题2
虽然没有了大量未知标识符的错误,但是还有几个错误提示是class 定义有问题,多一个括号或少一个括号之类的问题,经过对比发现是文件编码格式问题,报错的文件编码为UTF-8 而正常的文件格式是UTF-8 BOM。
问题2 解决方法
首先了解下UTF-8与UTF-8 BOM的区别:
UTF-8是一种通用的Unicode字符编码方式,使用可变长度的编码来表示Unicode字符。它可以表示几乎所有的Unicode字符,包括ASCII字符和非ASCII字符。UTF-8编码中的每个字符使用1到4个字节表示,具体字节长度取决于字符的Unicode码位。
UTF-8 BOM是一个特殊的字节序列,即字节顺序标记(Byte Order Mark),用于标识文本文件的字节顺序。它是由3个字节构成的特殊字符序列(0xEF, 0xBB, 0xBF),在文件开头作为文件头部的标记。BOM最初设计用于解决字节顺序的问题,主要在一些特定的编码方案中使用,如UTF-16和UTF-32。然而,在UTF-8中,BOM不是必需的,也不推荐使用。
UTF-8编码的文件通常不包含BOM。没有BOM的UTF-8文件被视为以UTF-8编码存储的纯文本文件。当打开这样的文件时,应用程序会默认使用UTF-8编码来解释其内容。
相比之下,带有BOM的UTF-8文件在文件开头包含BOM标记。当处理这样的文件时,应用程序可以通过检查BOM来确定文件的编码方式。BOM的存在可以帮助应用程序自动识别文件的编码。但是,某些应用程序可能对BOM敏感,可能会解释BOM字符本身,导致显示问题。
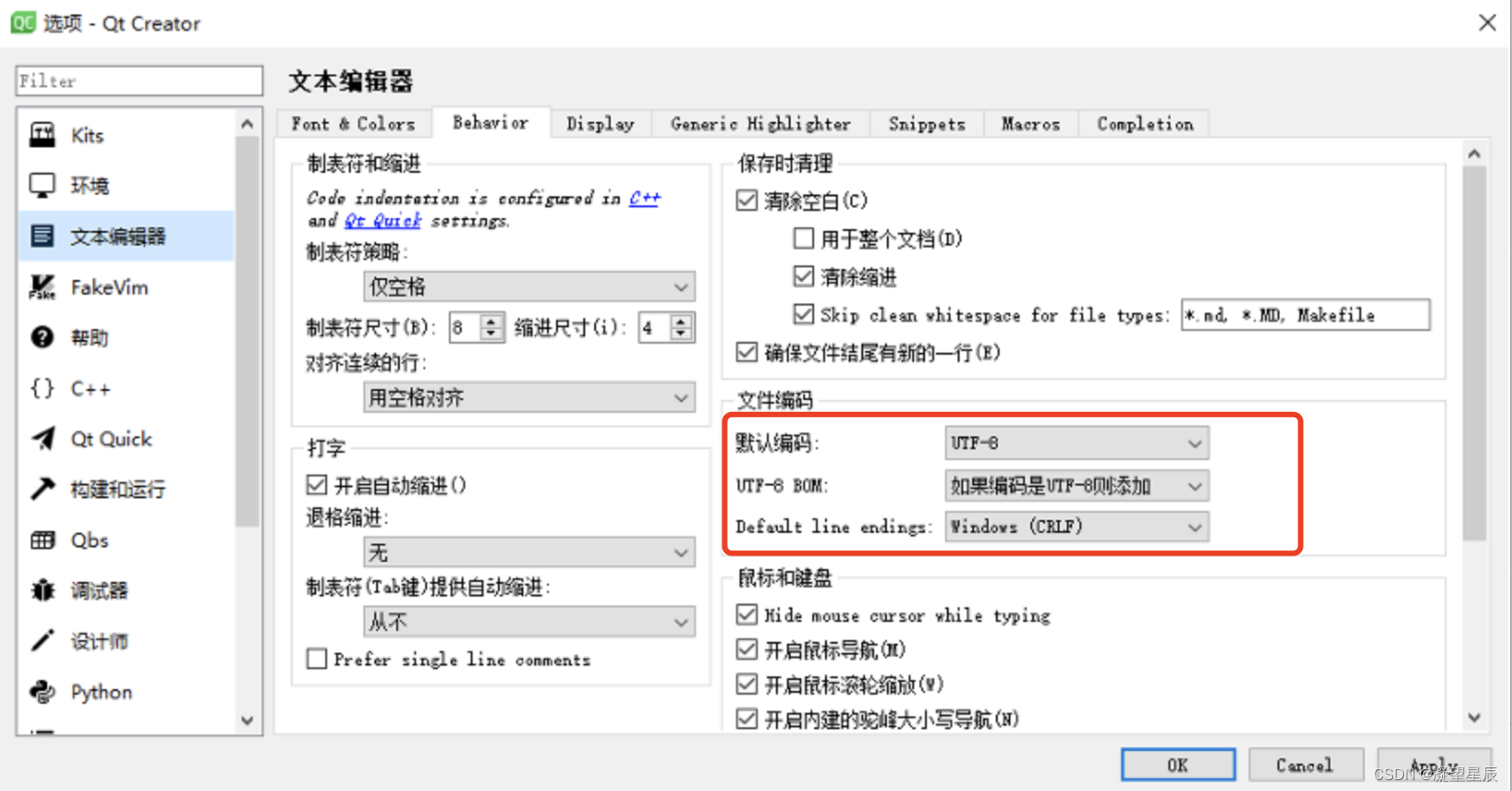
知道了UTF-8与UTF-8 BOM的区别,才明白是代码中含有中文字符导致编译失败的,解决这个问题只能是将代码中含有中文字符的文件格式转为UTF-8 BOM 。这一点可以通过修改QtCreator的配置实现,如下图所示。按下图配置后,在源码中随便敲几个空格然后保存,文件格式就变为UTF-8 BOM了。
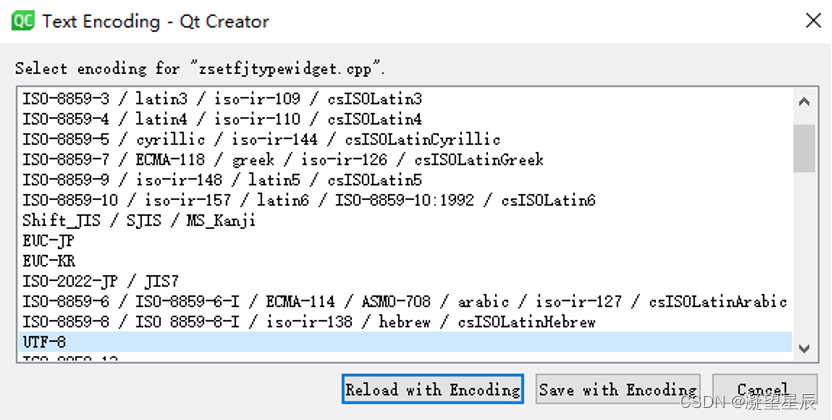
重新加载文件后,再次编译就一切正常了。下图是保存文件后按照新编码格式加载文件的示例:
总结
以上就是本文的所有内容了,如有疑问欢迎留言讨论!







](https://img-blog.csdnimg.cn/8cbbb88757914a878b64b40005140de6.jpg)




![[RF学习记录][ssh library][execute Command】关键字的返回值](https://img-blog.csdnimg.cn/72a23bafb56e49ebb956c7bf20bf051b.png)