算法架构:
目标检测:yolov5
目标跟踪:OCSort
其中, Yolov5 带有详细的训练步骤,可以根据训练文档,训练自己的数据集,及其方便。
另外后续 目标检测会添加 yolov7 、yolox,目标跟踪会添加 ByteTrack、deepsort等经典算法,代码主要部分添加了详细注释,方便自己学习。
一、简介
本文将详细介绍如何使用深度学习中的YOLOv5和OCTrack算法实现车辆、行人等多目标的实时检测和跟踪,并利用PyQt5设计了简约的系统UI界面。在界面中,您可以选择自己的视频文件进行检测和跟踪,也可以通过电脑自带的摄像头进行实时处理。此外,您还可以更换自己训练的yolov5模型,进行自己数据的跟踪。
该系统界面优美,检测精度高,功能强大。它具备多目标实时检测、跟踪和计数功能,同时可以自由选择感兴趣的跟踪目标。
本博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考。您可以在文末的下载链接中获取完整的代码资源文件。以下是本博文的目录:
目录
- 一、简介
- 二、效果展示
- 三、环境安装
- 四、YOLOV5介绍
- yolov5模型的训练步骤
- 五、OCtrack介绍
- 六、下载链接
二、效果展示
三、环境安装
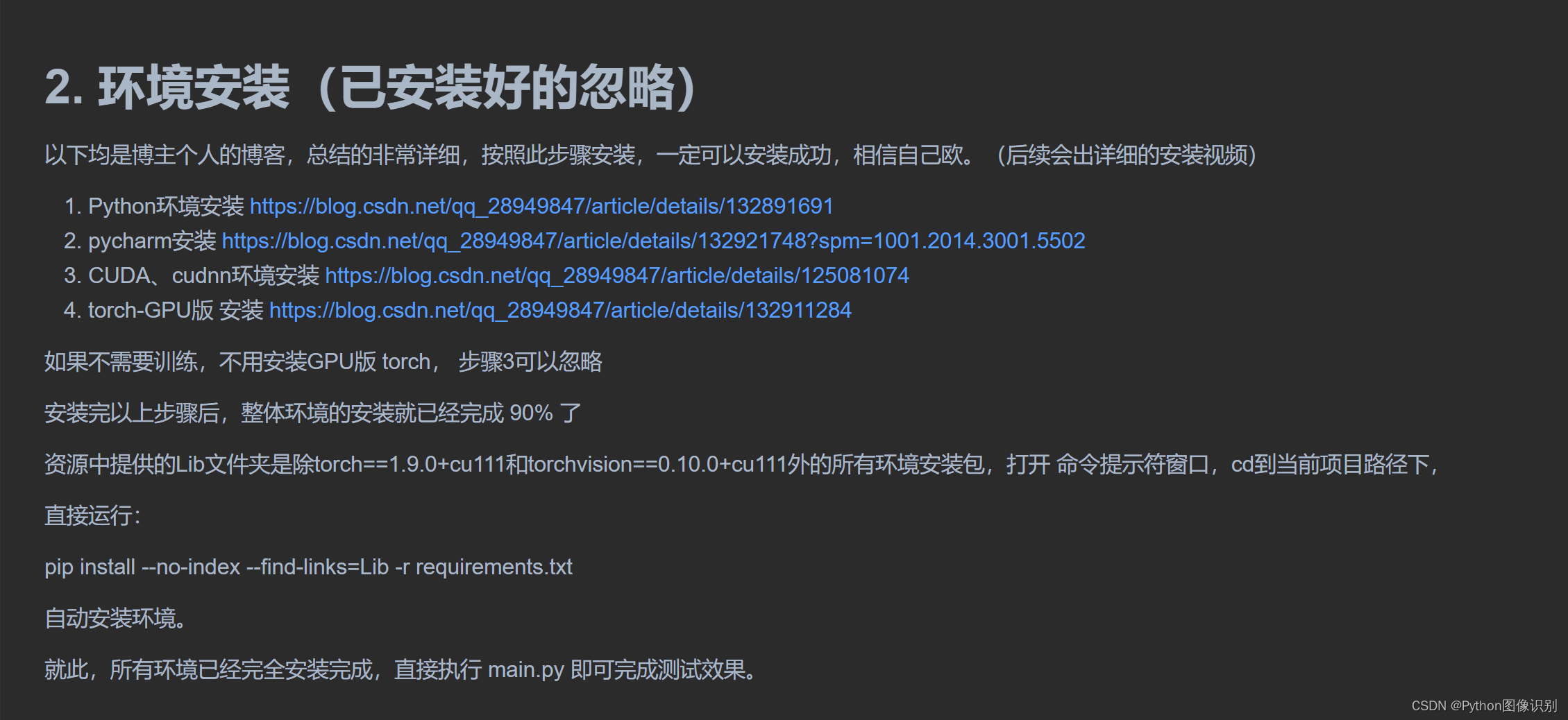
以链接下均是博主个人的博客,总结的非常详细,按照此步骤安装,一定可以安装成功,相信自己欧。(后续会出详细的安装视频)
见 代码资源中 README.md 文件中 环境安装部分,以下是文档截图:
四、YOLOV5介绍
从实际效果来看YOLOv5已经相当优秀,是发展的比较完备、使用比较广泛的一个版本;而更重要的是YOLOv5的调用、训练和预测都十分方便。YOLOv5的另一个特点就是它为不同的设备需求和不同的应用场景提供了大小和参数数量不同的网络。
以下是YoloV5改进的部分(不完全):
(1)主干部分:使用了Focus网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。该结构在YoloV5第5版之前有所应用,最新版本中未使用。
(2)数据增强:Mosaic数据增强、Mosaic利用了四张图片进行拼接实现数据中增强,根据论文所说其拥有一个巨大的优点是丰富检测物体的背景!且在BN计算的时候一下子会计算四张图片的数据!
(3)多正样本匹配:在之前的Yolo系列里面,在训练时每一个真实框对应一个正样本,即在训练时,每一个真实框仅由一个先验框负责预测。YoloV5中为了加快模型的训练效率,增加了正样本的数量,在训练时,每一个真实框可以由多个先验框负责预测。
一、整体结构解析
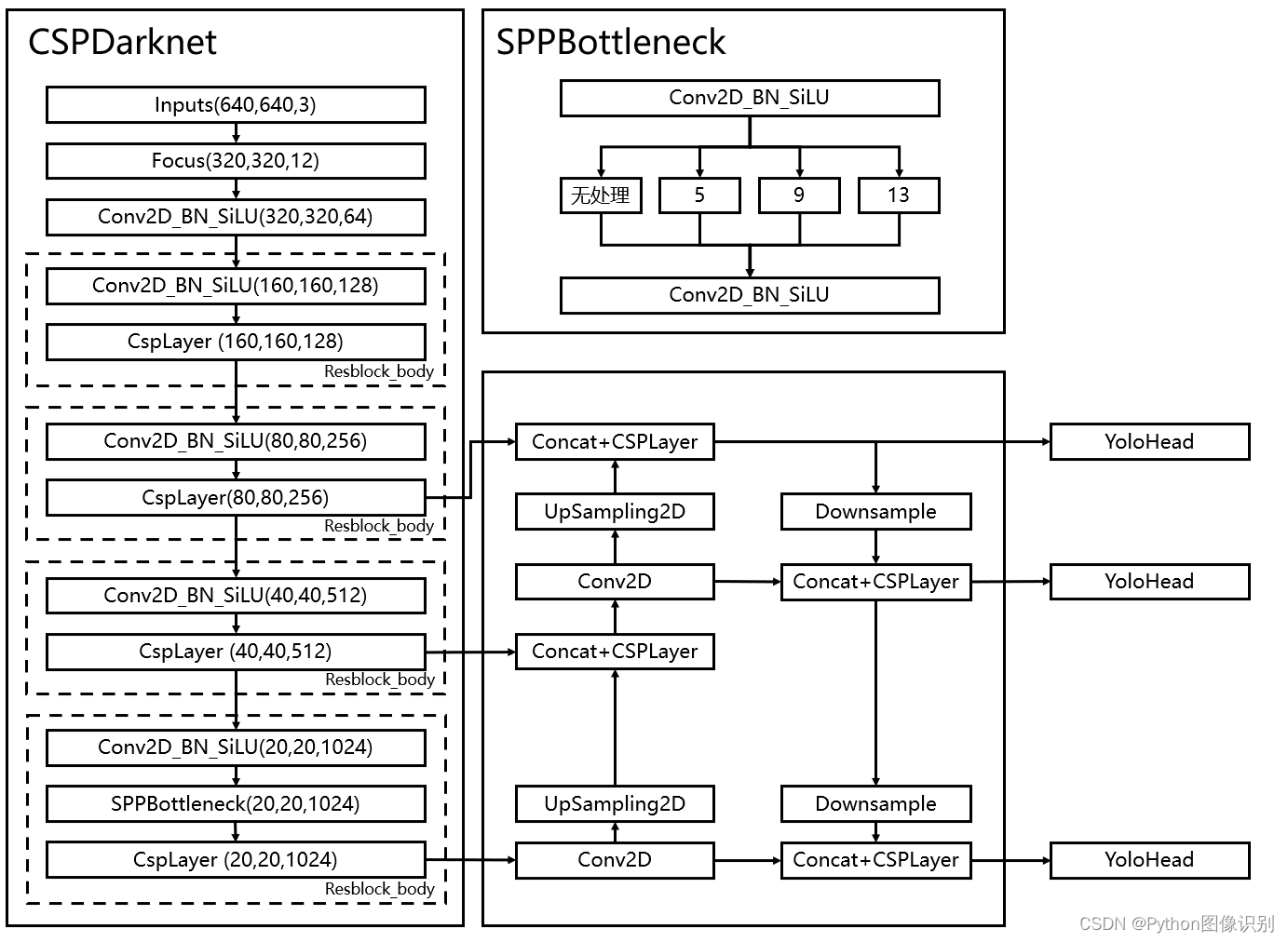
和之前版本的Yolo类似,整个YoloV5可以依然可以分为三个部分,分别是Backbone,FPN以及Yolo Head。
Backbone可以被称作YoloV5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet,输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN可以被称作YoloV5的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV5里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
Yolo Head是YoloV5的分类器与回归器,通过CSPDarknet和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。与以前版本的Yolo一样,YoloV5所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YoloV5网络所作的工作就是 特征提取-特征加强-预测特征点对应的物体情况。
yolov5模型的训练步骤
我们以 VOC 数据格式进行训练,如果自己的数据集是其他格式,可以通过https://blog.csdn.net/qq_28949847/article/details/130246098这篇博客进行格式转换。
1. 准备数据集(以VOC.yaml数据集为例)
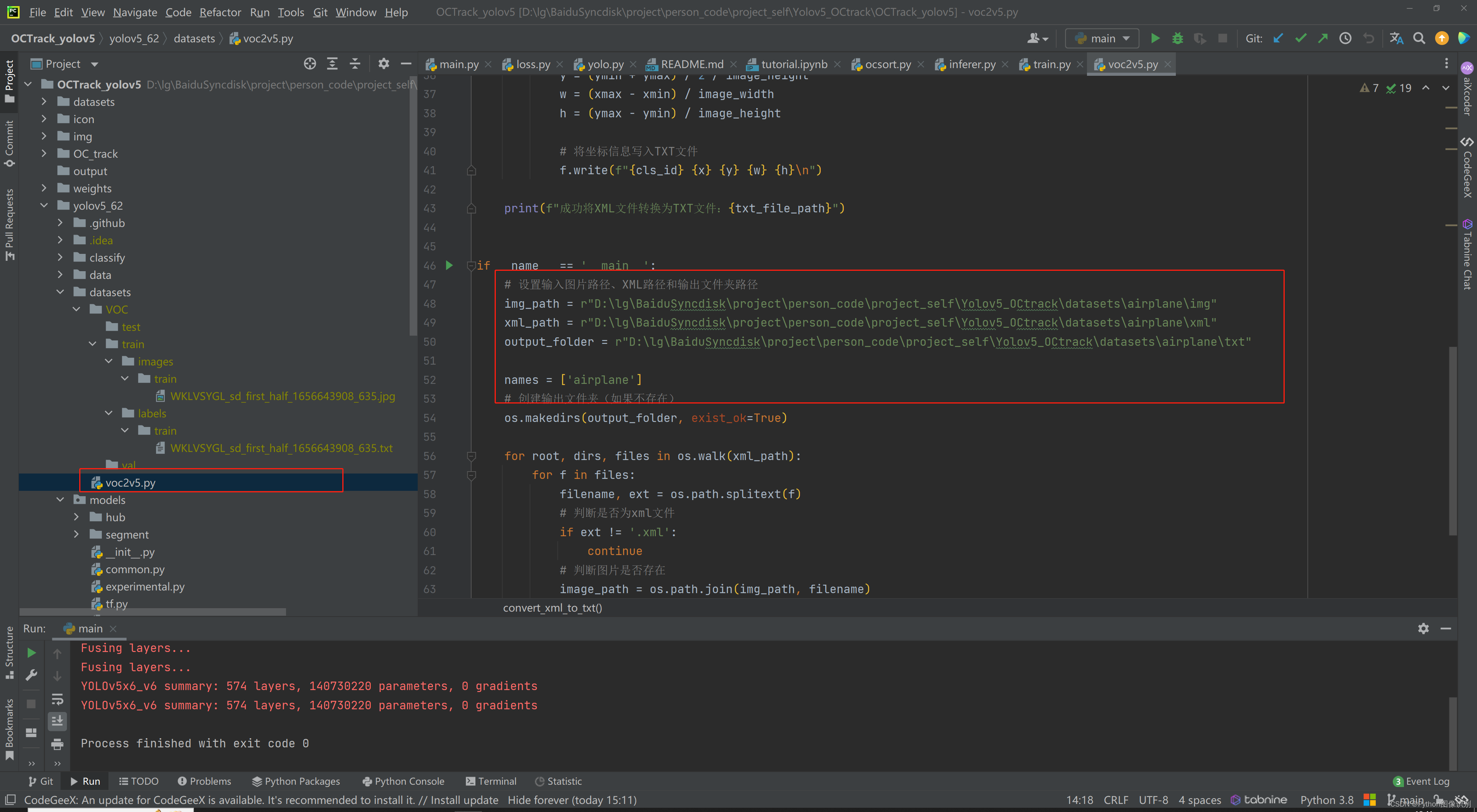
2. 使用datasets文件夹下的voc2v5.py 将xml文件转为txt文件
只需修改下方红框位置处的参数, 具体含义见注释。
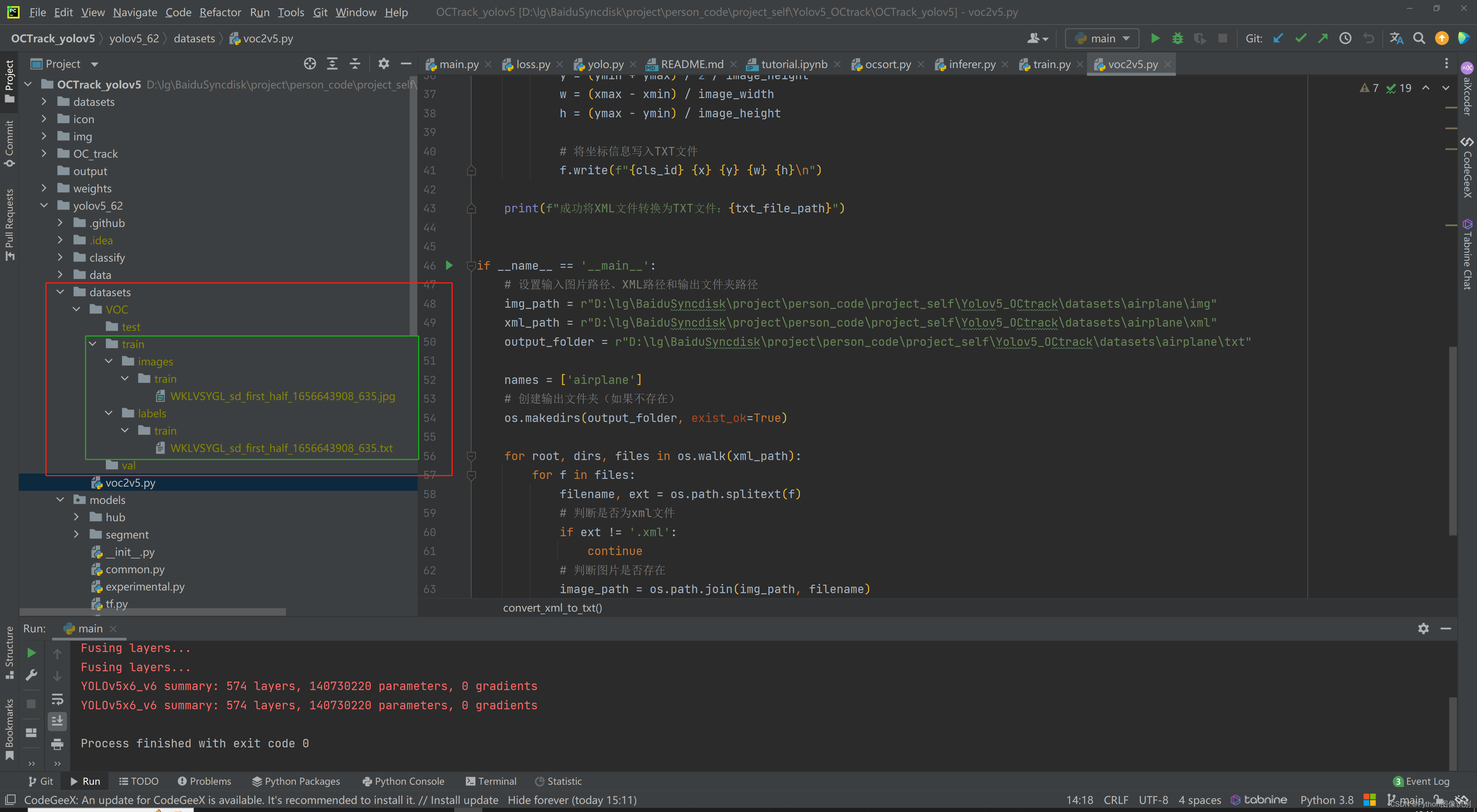
3. 参照datasets文件夹下创建的示例,创建文件夹结构,并将数据集放入在对应的文件夹下,截图如下:
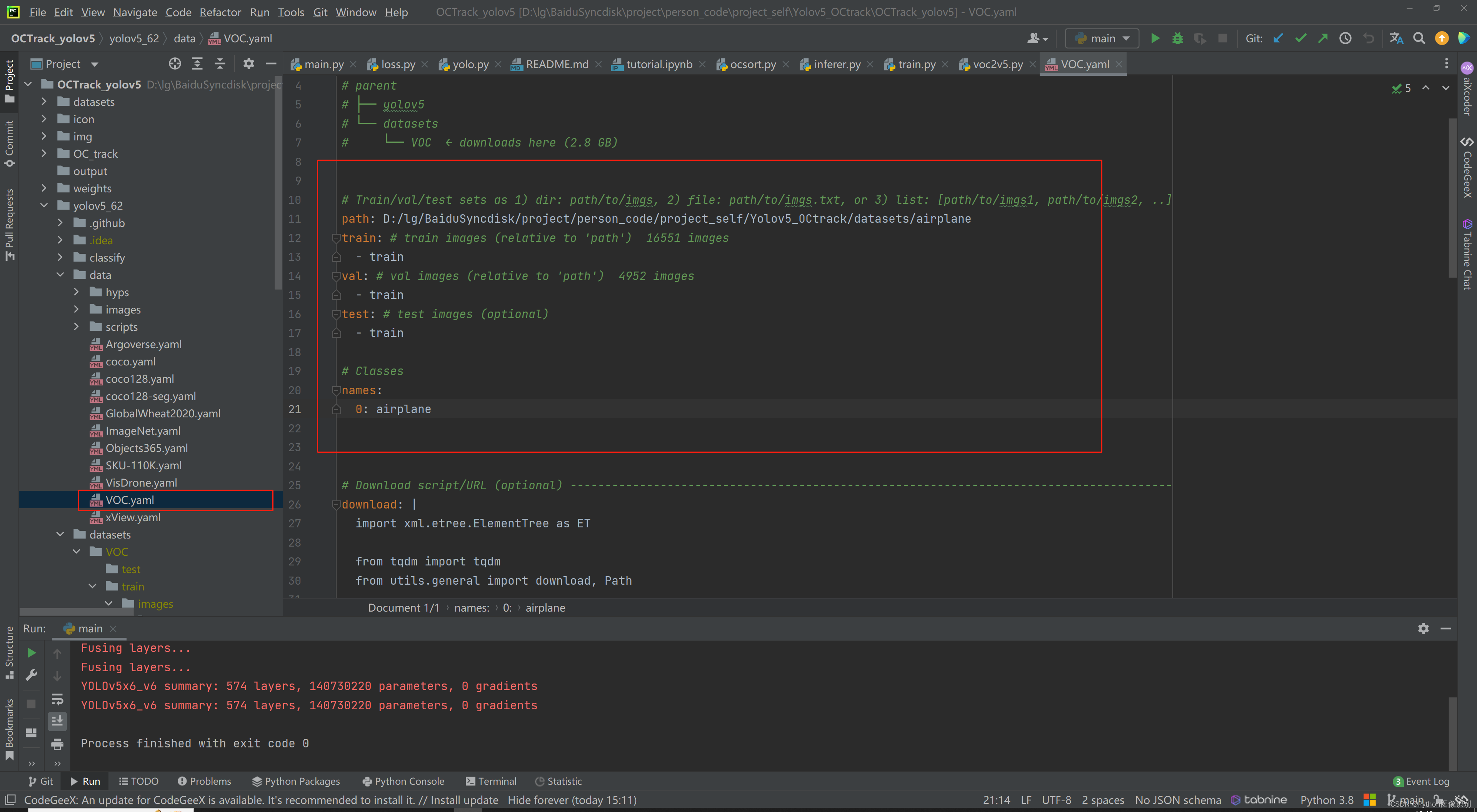
4. 修改 data文件夹下的VOC.yaml
# 数据集路径
path: D:/lg/BaiduSyncdisk/project/person_code/project_self/Yolov5_OCtrack/datasets/airplane
train: # train数据集
- train
val: # val 数据集
- train
test: # test 数据集
- train
# 修改为自己的类
names:
0: airplane
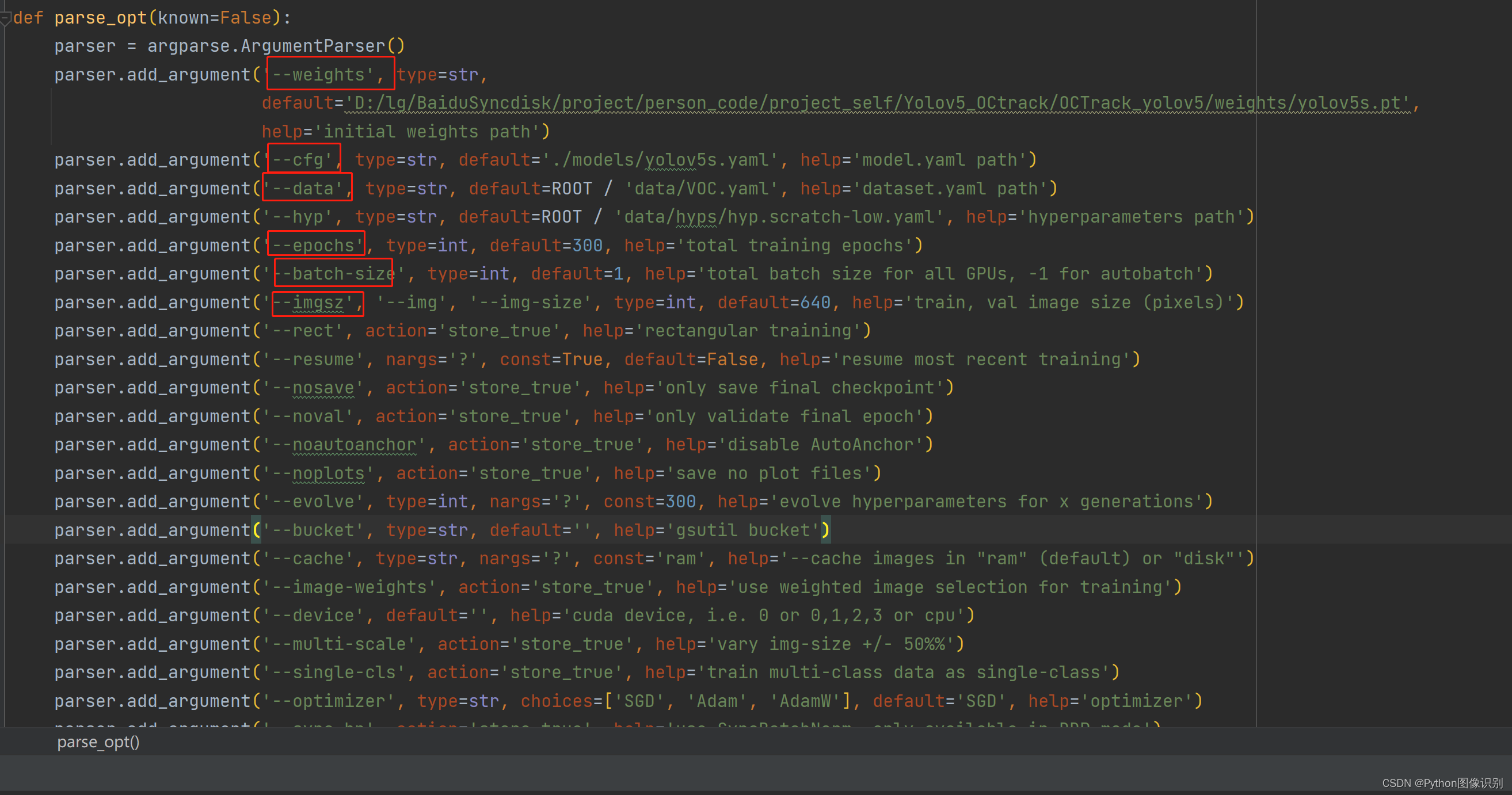
5. 根据自己的需求,修改 train.py文件夹下的参数,主要是以下画红框的这几个
6. 修改完参数后,点击运行即可训练
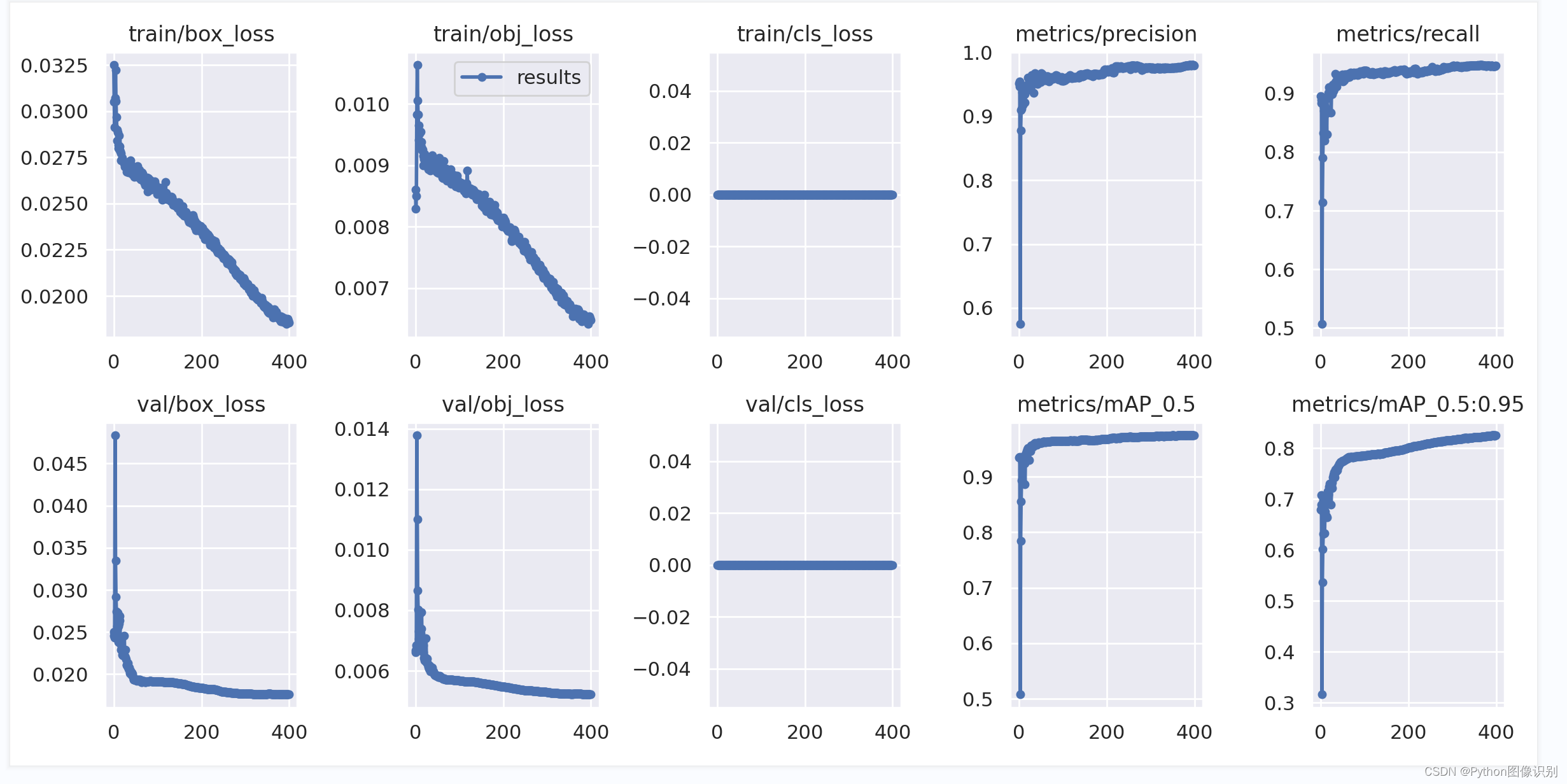
7. 训练结果(模型、PR曲线、数据分布情况、训练loss变化过程等)保存在 runs 文件夹下
五、OCtrack介绍
我们这里不做详细的原理介绍了,大部分的博客都已对其原理进行了详细介绍。我们主要对代码进行了详细的注释,有助于帮助我们更好的理解代码。其核心主要是两个类 OCSort 和 KalmanBoxTracker, 下面代码对其进行了详细的注释:
class OCSort(object):
def __init__(self, det_thresh, max_age=50, min_hits=-1,
iou_threshold=0.3, delta_t=3, asso_func="diou", inertia=0.2, use_byte=False):
"""
初始化OCSort对象,并设置关键参数。
参数:
- det_thresh: float,目标检测结果的阈值
- max_age: int,允许的跟踪器未更新的最大帧数,默认为30
- min_hits: int,跟踪器更新所需的最小帧数,默认为3
- iou_threshold: float,用于关联跟踪器和检测结果的IOU(交并比)阈值,默认为0.3
- delta_t: int,时间步长,默认为3
- asso_func: str,关联函数的名称,默认为"diou"
- inertia: float,跟踪器的惯性权重,默认为0.2
- use_byte: bool,是否使用字节级别的特征,默认为False
"""
self.max_age = max_age
self.min_hits = min_hits
self.iou_threshold = iou_threshold
# 存储跟踪器的列表
self.trackers = []
self.frame_count = 0
self.det_thresh = det_thresh
# 时间步长
self.delta_t = delta_t
self.asso_func = ASSO_FUNCS[asso_func]
# 跟踪器的惯性权重
self.inertia = inertia
self.use_byte = use_byte
# 跟踪器对象的计数器
KalmanBoxTracker.count = 0
self.label = {}
# 存储label 对应关系
self.idx_to_label = {}
def update(self, results, img_size):
"""
更新跟踪器状态。
参数:
- results: numpy数组,表示检测结果,格式为[[x1,y1,x2,y2,score],[x1,y1,x2,y2,score],...]
- img_size: 元组,表示图像的尺寸 (height, width)
要求:即使没有检测结果,每帧都必须调用此方法(对于没有检测结果的帧,请使用 np.empty((0, 5)))。
返回一个类似的数组,其中最后一列是对象的ID。
注意:返回的对象数量可能与提供的检测数量不同。
"""
# img 大小
img_h, img_w = img_size[0], img_size[1]
# 当前帧数
self.frame_count += 1
# 将 目标检测结果[[label, conf, [x1, y1, x2, y2],...] 转为 [[x1,y1,x2,y2,score],[x1,y1,x2,y2,score],...]格式
output_results = []
for r_i, res in enumerate(results):
label, conf, bbox = res[:3]
if label not in self.label:
self.label[label] = 0 if len(self.label) == 0 else (max(self.label.values()) + 1)
self.idx_to_label = {v: k for k, v in self.label.items()}
cls = self.label[label]
output_results.append([bbox[0], bbox[1], bbox[2], bbox[3], conf, cls])
output_results = np.array(output_results) if len(output_results) else np.empty((0, 6))
# x1y1x2y2
bboxes = output_results[:, :4]
scores = output_results[:, 4]
classes = output_results[:, 5:6]
dets = np.concatenate((bboxes, np.expand_dims(scores, axis=-1), classes), axis=1)
# 选出self.det_thresh > score > 0.1阈值的数据,为低分数据, 设置 BYTE association 为 True 时会用到
inds_low = scores > 0.1
inds_high = scores < self.det_thresh
inds_second = np.logical_and(inds_low, inds_high)
dets_second = dets[inds_second]
# 选出 score > self.det_thresh 的数据
remain_inds = scores > self.det_thresh
dets = dets[remain_inds]
# 存储卡尔曼预测后的位置信息
trks = np.zeros((len(self.trackers), 5))
to_del = []
ret = []
# 对已经存在的self.trackers中的跟踪器进行卡尔曼位置预测
for t, trk in enumerate(trks):
# 根据trackers中的信息,进行卡尔曼位置预测
pos = self.trackers[t].predict()[0]
# 更新跟踪器的位置信息
trk[:] = [pos[0], pos[1], pos[2], pos[3], 0]
# 如果预测的位置出现NaN值(无效值)
if np.any(np.isnan(pos)):
# 将该跟踪器的索引添加到待删除列表中
to_del.append(t)
# 移除包含NaN等无效值的行
trks = np.ma.compress_rows(np.ma.masked_invalid(trks))
# 从跟踪器列表中删除无效的跟踪器, 逆序删除元素, 防止索引发送变化
for t in reversed(to_del):
self.trackers.pop(t)
# 获取跟踪器的速度
velocities = np.array([trk.velocity if trk.velocity is not None else np.array((0, 0)) for trk in self.trackers])
# 获取最后观察到的边界框
last_boxes = np.array([trk.last_observation for trk in self.trackers])
# 获取K个先前观察结果 ???
k_observations = np.array([k_previous_obs(trk.observations, trk.age, self.delta_t) for trk in self.trackers])
"""
第一次:
将目标检测得到的box同卡尔曼预测后的box进行级联匹配
"""
matched, unmatched_dets, unmatched_trks = associate(dets, trks, self.iou_threshold, velocities, k_observations,
self.inertia)
for m in matched:
# 根据最新匹配的box进行卡尔曼更新
self.trackers[m[1]].update(dets[m[0], :])
"""
# BYTE association
Second round of associaton by OCR
对未匹配的追踪器 同 低分的box进行2次匹配
"""
if self.use_byte and len(dets_second) > 0 and unmatched_trks.shape[0] > 0:
# 提取未匹配的追踪器
u_trks = trks[unmatched_trks]
# 计算低分检测结果和未匹配追踪器之间的IOU
iou_left = self.asso_func(dets_second, u_trks) # iou between low score detections and unmatched tracks
iou_left = np.array(iou_left)
# 检查最大的IOU是否超过阈值
if iou_left.max() > self.iou_threshold:
"""
注意:通过使用较低的阈值,例如 self.iou_threshold - 0.1,在MOT17/MOT20数据集上可能会获得更高的性能。
但出于简单起见,我们在这里保持阈值的一致性。
"""
# 使用线性分配算法进行匹配
matched_indices = linear_assignment(-iou_left)
# 存储待删除的追踪器索引
to_remove_trk_indices = []
# 遍历匹配的索引对
for m in matched_indices:
det_ind, trk_ind = m[0], unmatched_trks[m[1]]
# 如果IOU低于阈值,则跳过继续下一次迭代
if iou_left[m[0], m[1]] < self.iou_threshold:
continue
# 更新对应的追踪器状态
self.trackers[trk_ind].update(dets_second[det_ind, :])
# 将待删除的追踪器索引添加到列表中
to_remove_trk_indices.append(trk_ind)
# 从未匹配的追踪器中移除已匹配的部分
unmatched_trks = np.setdiff1d(unmatched_trks, np.array(to_remove_trk_indices))
# 对未匹配的检测结果和追踪器 进行第2次重新匹配
if unmatched_dets.shape[0] > 0 and unmatched_trks.shape[0] > 0:
# 提取未匹配的检测结果和追踪器
left_dets = dets[unmatched_dets]
left_trks = last_boxes[unmatched_trks]
# 计算未匹配的检测结果和追踪器之间的IOU
iou_left = self.asso_func(left_dets, left_trks)
iou_left = np.array(iou_left)
# 检查最大的IOU是否超过阈值
if iou_left.max() > self.iou_threshold:
"""
注意:通过使用较低的阈值,例如 self.iou_threshold - 0.1,在MOT17/MOT20数据集上可能会获得更高的准确度。
但出于简单起见,我们在这里保持阈值的一致性。
"""
# 使用线性分配算法进行重新匹配
rematched_indices = linear_assignment(-iou_left)
# 存储待删除的检测结果和追踪器的索引
to_remove_det_indices = []
to_remove_trk_indices = []
for m in rematched_indices:
det_ind, trk_ind = unmatched_dets[m[0]], unmatched_trks[m[1]]
# 如果IOU低于阈值,则跳过继续下一次迭代
if iou_left[m[0], m[1]] < self.iou_threshold:
continue
# 更新对应的追踪器状态,索引是一直对应的,所以此处可以直接更新
self.trackers[trk_ind].update(dets[det_ind, :])
# 将待删除的检测结果和追踪器索引添加到列表中
to_remove_det_indices.append(det_ind)
to_remove_trk_indices.append(trk_ind)
# 从未匹配的检测结果和追踪器中移除已匹配的部分
unmatched_dets = np.setdiff1d(unmatched_dets, np.array(to_remove_det_indices))
unmatched_trks = np.setdiff1d(unmatched_trks, np.array(to_remove_trk_indices))
# 没有匹配上的tracker,也就是在没有新的测量值时,传入None,冻结滤波器状态并保持先前的预测结果,但是里面的后验状态 self.x_post、后验协方差 self.P_post、残差 self.y 进行了更新
for m in unmatched_trks:
self.trackers[m].update(None)
# 对未匹配上的目标检测框,创建一个新的 KalmanBoxTracker 跟踪器对象
for i in unmatched_dets:
trk = KalmanBoxTracker(dets[i, :], delta_t=self.delta_t)
self.trackers.append(trk)
i = len(self.trackers)
for trk in reversed(self.trackers):
# 如果跟踪器的最近观测的总和小于0(即没有有效的观测)
if trk.last_observation.sum() < 0:
d = trk.get_state()[0]
else:
'''
使用最近的观测box还是卡尔曼滤波器的预测box是可选的,这里没有注意到显著的差异。
'''
# 跟踪器有最近的观测(last_observation),则将变量 d 设置为该观测的前四个元素(即边界框的box)
d = trk.last_observation[:4]
if (trk.time_since_update <= 3) and (trk.hit_streak >= self.min_hits or self.frame_count <= self.min_hits):
# +1 as MOT benchmark requires positive
ret.append(np.concatenate((d, [trk.id, trk.cls, trk.conf])).reshape(1, -1))
i -= 1
# 当超过 max_age 没有更新时,删除此跟踪信息
if trk.time_since_update > self.max_age:
self.trackers.pop(i)
outputs = []
if len(ret) > 0:
ret = np.concatenate(ret)
for idx, t in enumerate(ret):
x1, y1, x2, y2 = int(t[0]), int(t[1]), int(t[2]), int(t[3])
track_id = int(t[4])
cls = int(t[5])
det_conf = t[6]
class_name = self.idx_to_label[cls]
x1 = min(img_w - 1, max(0, x1))
x2 = min(img_w - 1, max(0, x2))
y1 = min(img_h - 1, max(0, y1))
y2 = min(img_h - 1, max(0, y2))
res = [x1, y1, x2, y2, class_name, det_conf, track_id]
outputs.append(res)
return outputs
class KalmanBoxTracker(object):
"""
这个类表示以bbox形式观察到的单个被跟踪对象的内部状态。
"""
count = 0
def __init__(self, bbox, delta_t=3, orig=False):
"""
使用目标检测框box初始化跟踪器。
参数:
- bbox:表示要跟踪的对象的初始边界框(目标检测框)。
- delta_t:时间间隔,用于估计速度,计算速度是用 当前的box - 倒数第delta_t的box。
- orig:一个布尔值,如果orig为False,则使用自定义的KalmanFilterNew作为卡尔曼滤波器模型,
否则使用filterpy库中的KalmanFilter。
"""
# 定义Kalman滤波器模型
if not orig:
from .kalmanfilter import KalmanFilterNew as KalmanFilter
self.kf = KalmanFilter(dim_x=7, dim_z=4)
else:
from filterpy.kalman import KalmanFilter
self.kf = KalmanFilter(dim_x=7, dim_z=4)
# 设置状态转移矩阵 7 * 7 矩阵,通过状态转移矩阵和当前状态的乘积,可以预测对象在下一个时间步的状态。
# 7个位置分别代表:cx(中心位置)、cy(中心位置)、宽度、高度、速度(水平)、速度(垂直)、加速度
# 当状态转移矩阵中的元素被设置为1时,表示在系统的状态转移过程中,对应状态之间的关系是线性的,并且该状态在时间推进时保持不变。
self.kf.F = np.array([[1, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 0, 1],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 1]])
# 设置观测矩阵
self.kf.H = np.array([[1, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0]])
self.kf.R[2:, 2:] *= 10.
# 对不可观测的初始速度给予较高的不确定性
self.kf.P[4:, 4:] *= 1000.
self.kf.P *= 10.
self.kf.Q[-1, -1] *= 0.01
self.kf.Q[4:, 4:] *= 0.01
self.kf.x[:4] = convert_bbox_to_z(bbox)
self.conf = bbox[4]
self.time_since_update = 0
self.id = KalmanBoxTracker.count
KalmanBoxTracker.count += 1
self.history = []
self.hits = 0
self.hit_streak = 0
self.age = 0
"""
注意:[-1,-1,-1,-1,-1]是一个妥协的占位符,表示非观测状态,
对于函数k_previous_obs的返回值也是如此。虽然不够美观,但为了以快速和统一的方式支持生成观测数组,
如下所示:k_observations = np.array([k_previous_obs(...)]])。
"""
self.last_observation = np.array([-1, -1, -1, -1, -1]) # placeholder
self.observations = dict()
self.history_observations = []
self.velocity = None
self.delta_t = delta_t
self.cls = int(bbox[5])
def update(self, bbox):
"""
Args:
bbox (array or None): 观测到的边界框,可以是数组或 None。
Returns:
None
Notes:
- self.velocity的计算:
- 对于每个时间步 dt,从当前时间步 self.age 开始向前查找,找到与当前观测 bbox 相隔 delta_t 步的观测数据。
- 如果找不到与当前观测相隔 delta_t 步的观测数据,使用最近的观测数据作为之前的边界框。
"""
if bbox is not None:
if self.last_observation.sum() >= 0: # no previous observation
previous_box = None
for i in range(self.delta_t):
dt = self.delta_t - i
if self.age - dt in self.observations:
previous_box = self.observations[self.age - dt]
break
if previous_box is None:
previous_box = self.last_observation
# 估计跟踪速度方向,使用与当前观测的bbox相隔 delta_t 步的观测数据
self.velocity = speed_direction(previous_box, bbox)
# 插入新的观测数据
self.last_observation = bbox[:5]
self.conf = bbox[4]
self.observations[self.age] = bbox[:5]
# 重置自上次更新以来的时间步数和历史记录
self.time_since_update = 0
self.history = []
# 增加命中计数和命中连续次数
self.hits += 1
self.hit_streak += 1
# 根据最新匹配的 bbox,进行卡尔曼更新
self.kf.update(convert_bbox_to_z(bbox))
else:
self.kf.update(bbox)
def predict(self):
"""
对跟踪器的速度和宽度之和进行判断,如果其小于等于零,则将跟踪器的水平加速度置零。
具体解释如下:
self.kf.x[6] 表示状态向量中的第 7 个元素,即水平加速度。
self.kf.x[2] 表示状态向量中的第 3 个元素,即宽度。
self.kf.x[6] + self.kf.x[2] 表示跟踪器的水平加速度和宽度之和。
if self.kf.x[6] + self.kf.x[2] <= 0: 判断跟踪器的水平加速度和宽度之和是否小于等于零。
如果条件成立,即跟踪器的速度和宽度之和小于等于零,那么 self.kf.x[6] *= 0.0 将跟踪器的水平加速度置零,相当于将其速度减小为零或停止水平运动。
"""
# 判断速度和宽度之和是否小于等于零
if (self.kf.x[6] + self.kf.x[2]) <= 0:
# 若小于等于零,将水平加速度置零
self.kf.x[6] *= 0.0
# 利用卡尔曼滤波器进行状态预测
self.kf.predict()
# 增加跟踪器的age
self.age += 1
# 如果自上次更新以来经过的时间步数大于零
if self.time_since_update > 0:
# 将命中计数置零
self.hit_streak = 0
# 增加自上次更新以来的时间步数
self.time_since_update += 1
# 将当前状态向量 self.kf.x 转换为边界框信息,并添加到历史记录中
self.history.append(convert_x_to_bbox(self.kf.x))
# 返回历史记录中的最后一个边界框作为预测的边界框估计
return self.history[-1]
def get_state(self):
"""
Returns the current bounding box estimate.
"""
return convert_x_to_bbox(self.kf.x)
目标跟踪效果:
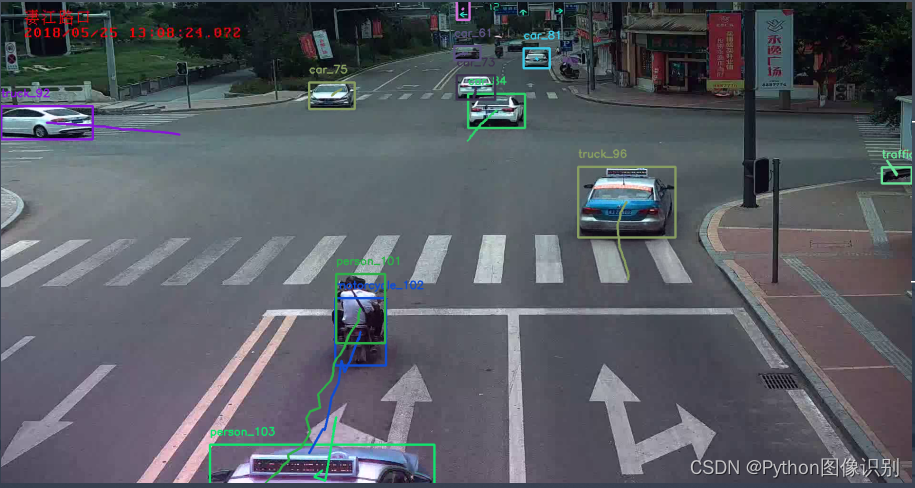
至此视频中多目标检测跟踪的代码实现部分介绍完毕,后面的博文中将给出训练程序以及UI界面的详细介绍,至于程序如何使用、依赖包安装、pycharm软件的安装过程将通过博主的B站视频进行演示介绍,敬请关注!
六、下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括模型权重,py, UI文件等,如下图),这里已打包上传至博主的面包多平台,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
面包多: