文章目录
- 1. MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
- 摘要和结论
- 引言:针对痛点和贡献
- 数据特点
- 2. Actor-Context-Actor Relation Network for Spatio-Temporal Action Localization
- 摘要和结论
- 引言:针对痛点和贡献
- 模型框架
- 实验
- 3. Relation Modeling in Spatio-Temporal Action Localization
- 摘要和结论
- 模型框架
- 长尾数据的学习策略
1. MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
[ICCV 2021] MultiSports:面向体育运动场景的细粒度多人时空动作检测数据集
摘要和结论
基于对现有数据集的分析,作者认为他们不能满足现实应用对时空动作检测技术的需求,需要提出一个新的数据集来推动这个领域的进步。
我们希望这个数据集满足以下特征:
- 多人:在同一场景下,不同的人做不同的细粒度动作,减少背景提供的信息。
- 分类:细粒度动作类别,定义准确,需要刻画人物本身动作,长时信息建模,人与人、与物、与环境的关系建模,推理。
- 时序:动作边界定义准确。
- 跟踪:运动速度快,形变大,存在遮挡
引言:针对痛点和贡献
痛点:

贡献:
提出了一个新数据集MultiSports。
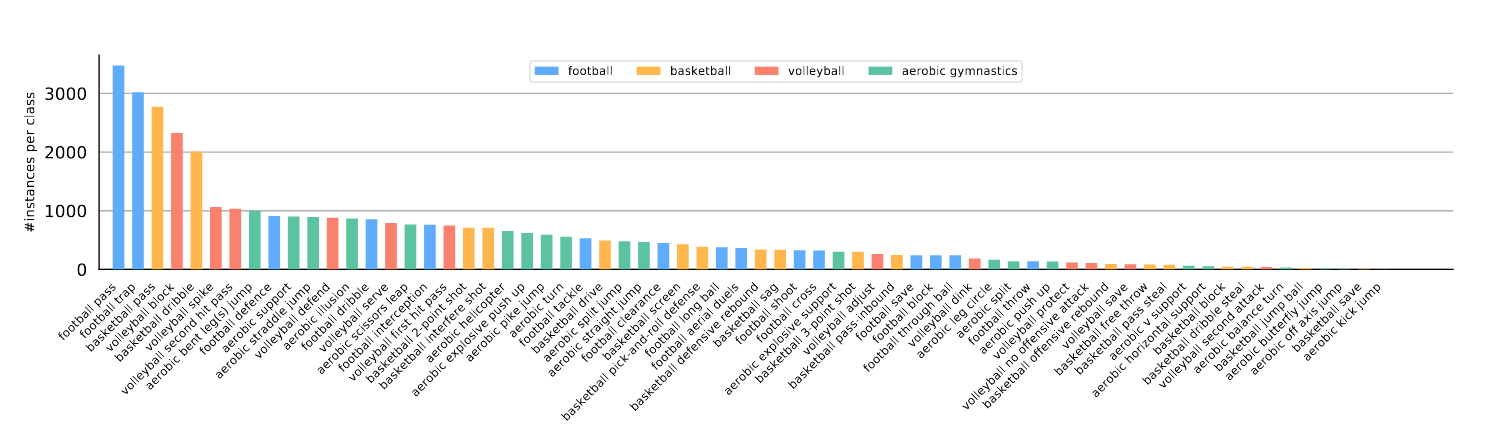
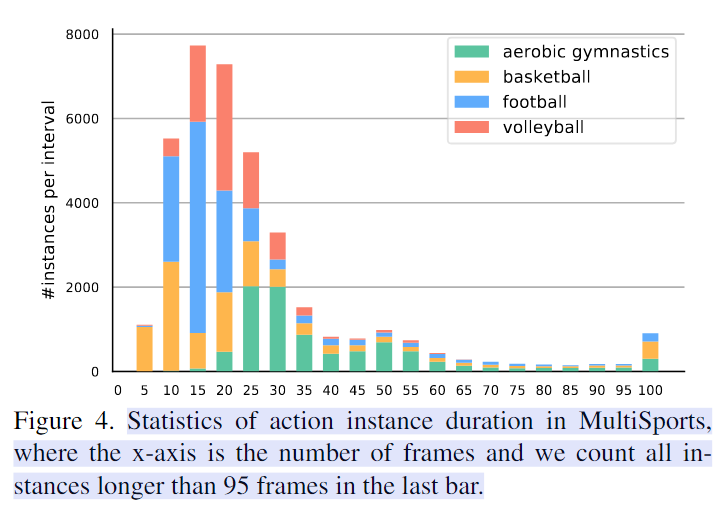
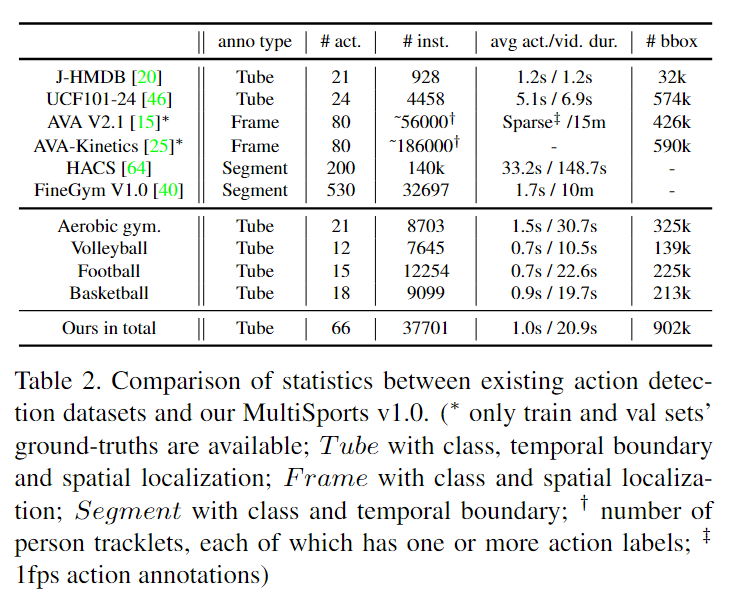
数据特点
2. Actor-Context-Actor Relation Network for Spatio-Temporal Action Localization
摘要和结论
最近的进展是通过对实体之间的直接成对关系建模来实现的。在本文中,我们更进一步,不仅模拟了对之间的直接关系,而且还考虑了建立在多个元素上的间接高阶关系。
设计了一个 Actor-Context-Actor 关系网络 (ACAR-Net),它建立在一个新的高阶关系推理算子和一个 Actor-Context 特征库的基础上,以实现时空动作定位的间接关系推理。
引言:针对痛点和贡献
痛点:
- 以前的工作使用图神经网络 (GNN) 隐式建模参与者和上下文对象之间的高阶交互 。然而,在这些方法中,需要额外的预先训练的对象检测器,只使用定位的对象作为上下文
- 这些方法中的高阶关系仅限于仅从上下文对象中推断出来,这可能会错过动作分类的重要环境或背景线索。
贡献: - 推理操作使用 Actor-Context Feature Bank (ACFB) 进行扩展。
模型框架
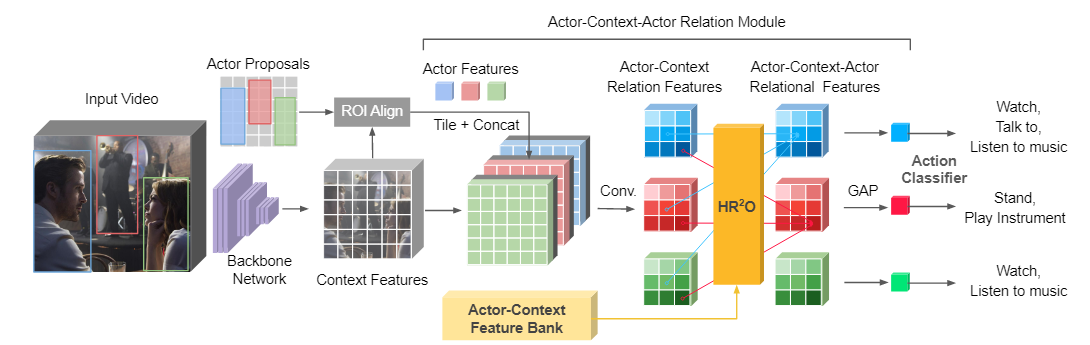
- 该框架是基于一个现成的人体检测器(例如 Faster R-CNN )和一个视频骨干网络(例如 I3D)。然后,建议的 ACAR 模块使用长期 Actor-Context 特征库处理人物和上下文特征,以进行最终动作预测。
- ACAR 模块有两个主要操作。 (1) 它首先编码演员之间的一阶演员-上下文关系和时空上下文的空间位置。基于参与者-上下文关系,我们进一步集成了一个高阶关系推理算子( H R 2 O ) ( HR ^2 O)(HR 2 O),用于对一阶关系对之间的交互进行建模,这些一阶关系是以前的方法大多忽略的间接关系。 (2) 我们的推理操作通过 Actor-Context Feature Bank (ACFB) 进行了扩展。该库包含不同时间戳的参与者-上下文关系,并且可以提供比现有的仅包含参与者特征的长期特征库[46]更完整的时空上下文。
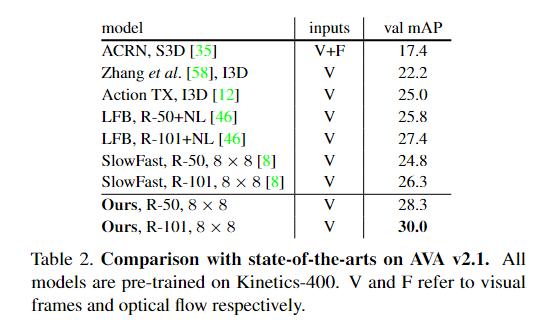
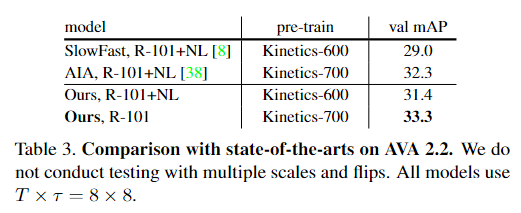
实验
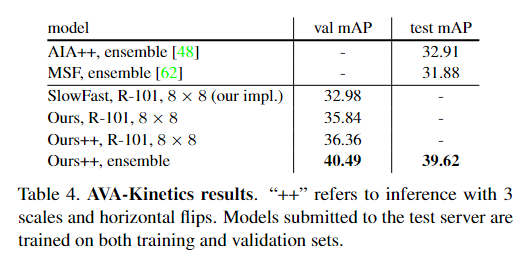
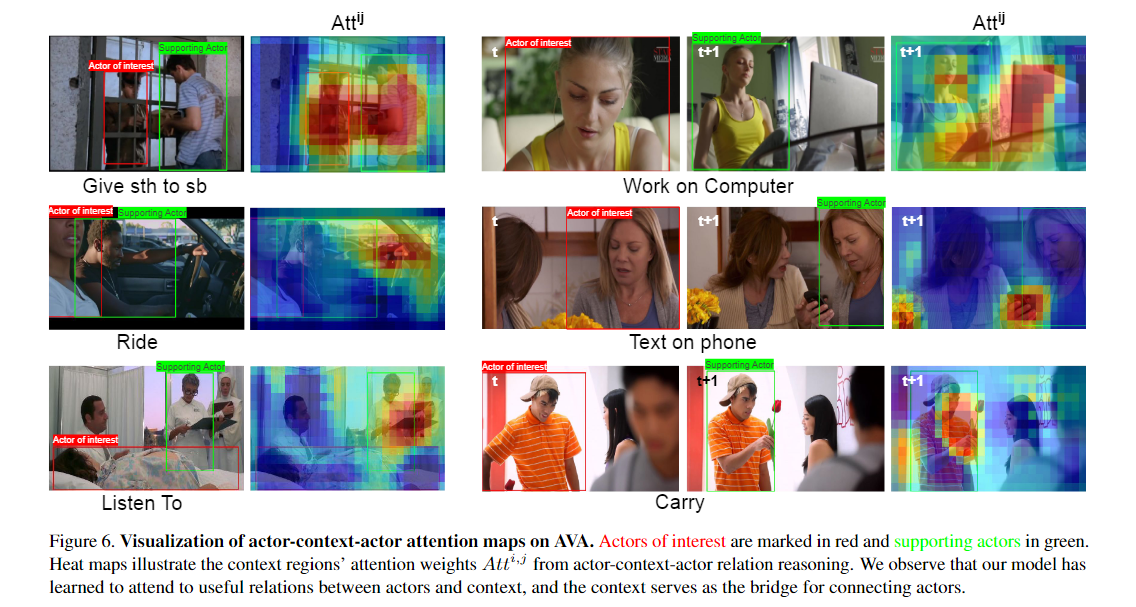
热图说明了来自参与者-上下文-参与者关系推理的上下文区域的注意力权重 Atti,j。我们观察到我们的模型已经学会了关注参与者和上下文之间的有用关系,上下文是连接演员的桥梁。
3. Relation Modeling in Spatio-Temporal Action Localization
摘要和结论
- 我们的解决方案利用多种类型的关系建模 Relation Modeling 方法进行时空动作检测
- 并采用端到端集成多种关系建模的训练策略对两个大规模视频数据集进行训练。
- 还研究了记忆库学习和长尾分布的微调,以进一步提高性能。
模型框架
首先采用现成的人体检测器来生成视频中的所有人体边界框。然后我们采用骨干模型来提取视觉特征,并通过 roi align 在每个人的特征图上构建关系模块。在关系模块之后,使用动作预测器为每个动作类别生成分数。
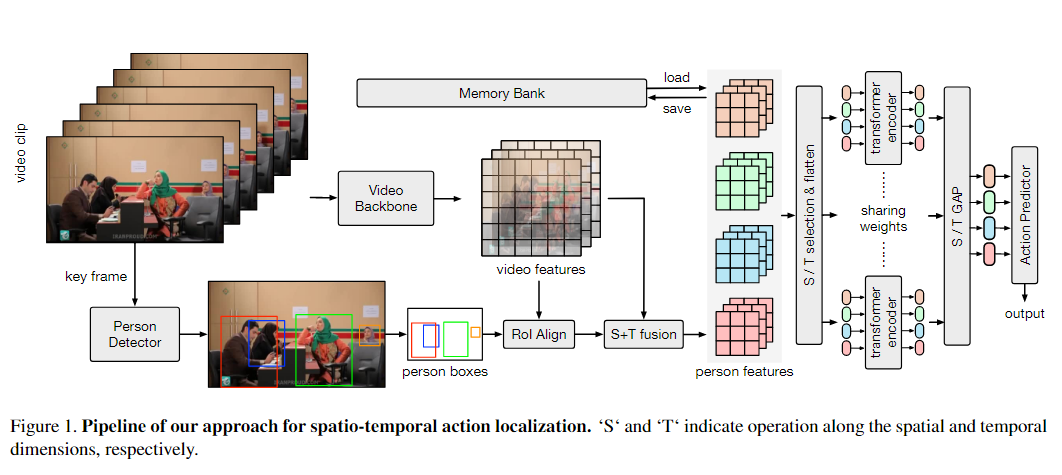
- 给定输入视频剪辑,提取该剪辑的关键帧并将其输入 2D 人物检测器,以生成该剪辑内的人物边界框。
- 整个视频剪辑按指定间隔采样为帧,并使用视频主干进行编码,例如SlowFast 和 CSN ,输出 3D 视频特征图。
- 然后,2D 人物框沿时间维度膨胀,并用于通过 3D RoI-Align 从特征图中提取人物特征。
- 池化的人物特征通过通道级联和卷积层进一步与视频特征图融合在一起。
- 为了对同一视频剪辑中的人物之间的隐藏关系进行建模,以提高动作预测的有效性,我们使用基于transformer的块将人物特征输入到我们的关系建模模块中。
- 为了指定空间和时间关系,我们从不同的人中选择沿相同空间或时间维度的特征。选定的特征被展平为一系列标记,并输入到transformer编码器块中,以通过注意机制对它们的关系进行建模。
- 最后,所有块在空间或时间维度上的输出标记被全局平均并输入全连接层以预测每个检测到的人的动作类别。
长尾数据的学习策略
我们考虑[11]中的解耦策略。训练过程被解耦为两个阶段。第一阶段遵循使用随机采样数据的正常训练策略。在第二阶段,我们冻结除最终分类器之外的所有模型,并使用类平衡数据采样进行训练。这样的策略有助于提高小类的表现。
[11] Decoupling Representation and Classifier for Long-Tailed Recognition