了解一些最常见的事件指标
在当今永不停机的世界中,中断和技术事件比以往任何时候都更加重要。故障和停机期间会带来现实后果,错过截止时间、付款逾期、项目延迟。
这就是为什么公司必须量化和跟踪有关正常运行时间、停机期间以及团队解决问题的速度和有效性的指标。
业界最常跟踪的一些指标包括 MTBF(故障前平均时间)、MTTR(平均恢复、修复、响应或解决时间)、MTTF(平均故障时间)和 MTTA(平均确认时间),这一系列指标旨在帮助技术团队了解事件发生的频率以及团队从这些事件中恢复的速度。
许多专家认为,这些指标本身其实没有那么有用,因为它们不会问一些更难的问题,比如如何解决事件、哪些有效、哪些无效,以及问题升级或降级的方式、时间和原因。
另一方面,MTTR、MTBF 和 MTTF 可以作为良好的基线或基准,启动对话,引发更深层次的重要问题。
专业人士如何应对重大事件
获取我们免费提供的事件管理手册。了解 Atlassian 用于管理重大事件的各种工具和技术。
获取手册
关于 MTTR 的免责声明
我们在谈论 MTTR 时,很容易假设它是一个含义单一的指标。但事实是,它可能代表了四种不同的衡量标准。R 可以代表修复、恢复、响应或解决,虽然这四个指标确实重叠,但它们都有自己的含义和细微差别。
因此,如果您的团队正在谈论跟踪 MTTR,最好弄清楚他们在说哪个 MTTR 以及他们是如何定义的。在您开始跟踪成功和失败之前,您的团队需要同步了解您正在跟踪的内容,并确保每个人都知道他们在说同样的事情。
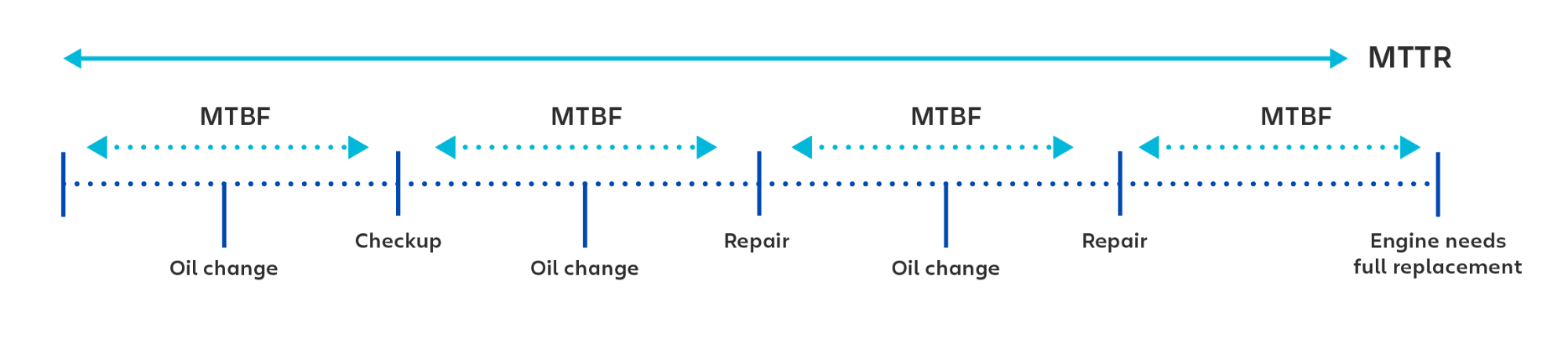
MTBF:平均故障间隔时间
平均故障间隔时间是多少?
MTBF(平均故障间隔时间)是技术产品两次可修复故障之间的平均时间。该指标用于跟踪产品的可用性和可靠性。两次故障之间的时间越长,系统就越可靠。
大多数公司的目标是尽可能保持较高的 MTBF,两次问题之间间隔数十万小时(甚至数百万小时)。
如何计算平均故障间隔时间
MTBF 是使用算术平均值计算的。基本上,这意味着从您要计算的时间段(可能是六个月、一年、也许五年)中提取数据,然后将该时段的总运行时间除以故障次数。
因此,假设我们评估的是 24 小时的时间段,在两次不同的事件中有两个小时的停机期间。我们的总正常运行时间为 22 小时。除以二,等于 11 个小时。所以我们的 MTBF 是 11 个小时。
由于该指标用于跟踪可靠性,因此 MTBF 不考虑定期维护期间的预期停机时间。相反,它侧重于意外的中断和问题。
平均故障间隔时间的起源
MTBF 来自航空业,在该行业,系统故障不仅会导致高昂的成本,甚至还会危及人的生命。从那以后,这种首字母缩略语已遍及各种技术和机械行业,尤其是经常用于制造业。
如何以及何时使用平均故障间隔时间
MTBF 对于想要确保获得最可靠的产品、驾驶最可靠的飞机或为工厂选择最安全的制造设备的买家很有帮助。
对于内部团队而言,它是一种有助于确定问题和跟踪成功与失败的指标。它还可以帮助公司就客户何时应该更换部件、升级系统或维护产品提出明智的建议。
MTBF 是衡量可修复系统故障的指标。对于需要更换系统的故障,人们通常使用术语 MTTF(平均故障时间)。
例如,汽车发动机。计算发动机计划外维护之间的时间时,应使用 MTBF(平均故障间隔时间)。计算更换整台发动机之间的时间时,应使用 MTTF(平均故障时间)。
MTTR:平均修复时间
平均修复时间是多少?
MTTR(平均修复时间)是修复系统(通常是技术或机械)所需的平均时间。这包括修复时间和任何测试时间。直到系统恢复完全正常运行,此指标才会停止计时。
如何计算平均修复时间
您可以通过将任何给定时间段内的总修复时间相加,然后将该时间除以修复次数来计算 MTTR。
因此,假设我们正在考虑一周内的修复。在这段时间里,发生了十次中断,系统修复花了四个小时。四小时等于 240 分钟。240 除以 10 等于 24。这意味着在这种情况下,平均修复时间为 24 分钟。
平均修复时间的限制
平均修复时间并不总是与系统中断本身的时间相同。某些情况下,修复会在产品故障或系统中断后的几分钟内开始。在其他情况下,在问题出现、检测到问题和开始修复之间会有一段时间间隔。
此指标在跟踪维护人员修复问题的速度时最有用。它并不是要识别系统警报问题或修复前延迟,这两者也是评估事件管理计划成败的重要因素。
如何以及何时使用平均修复时间
MTTR(平均恢复时间)是支持和维护团队用来保持维修按计划进行的一项指标。目标是通过提高维修流程和团队的效率来尽可能降低这个数字。
MTTR:平均恢复时间
平均恢复时间是多少?
MTTR(平均恢复时间)是从产品或系统故障中恢复所需的平均时间。这包括整个中断时间——从系统或产品出现故障到其恢复完全运行为止。
正如 DevOps 研究与评估 (DORA) 指出的那样,这是一项关键的 DevOps 指标,可用于衡量 DevOps 团队的稳定性。
如何计算平均恢复时间
平均恢复时间是通过将特定时间段内的所有停机期间相加并除以事件数来计算的。因此,假设我们的系统 24 小时内在两次不同的事件中停机了 30 分钟。30 除以二等于 15,所以我们的 MTTR 是 15 分钟。
平均恢复时间的限制
此 MTTR 用于衡量您的完整恢复流程的速度。它有您想要的那么快吗?它与您的竞争对手相比如何?
这是一个高级指标,可帮助您确定是否有问题。但是,如果您想诊断问题出在流程的哪里(是您的警报系统有问题吗?团队在修复上花了太长时间吗?有人响应修复请求的时间太长吗?),您将需要更多的数据。因为故障和恢复之间会发生很多事。
问题可能出在您的警报系统上。故障和警报之间有延迟吗?警报发送给正确人员所需的时间是否超过了应有的时间?
问题可能出在诊断上。您能很快弄清楚问题出在哪里吗?有没有可以改进的流程?
或者问题可能出在修复上。您的维护团队是否尽其所能?如果他们占用了大部分时间,是什么难住了他们?
您需要比 MTTR 更深入地研究才能回答这些问题,但平均恢复时间可以为诊断恢复流程是否存在需要您更深入研究的问题提供一个出发点。
如何以及何时使用平均恢复时间
MTTR 指标非常适合评估整体恢复流程的速度。
MTTR:平均解决时间
平均解决时间是多少?
MTTR(平均解决时间)是完全解决故障所需的平均时间。这不仅包括检测故障、诊断问题和修复问题所花费的时间,还包括确保故障不会再次发生所花费的时间。
该指标将处理修复的团队的责任扩展到长期提高绩效。这是灭火与灭火然后对房屋进行采取防火措施之间的区别。
这个 MTTR 与客户满意度之间有很强的相关性,因此需要重点注意。
如何计算平均解决时间
要计算此 MTTR,请将要跟踪的时间段内的完整解决时间相加,然后除以事件数。
因此,如果您的系统 24 小时内在单个事件中共停机了两个小时,而团队又花了两个小时进行修复以确保系统中断不会再次发生,那么解决问题总共花了四个小时。这意味着您的 MTTR 是四个小时。
关于跟踪平均解决时间的说明
请记住,MTTR 通常是使用工作时间计算的(因此,如果您有一天在工作时间结束时从问题中恢复过来,第二天早上第一时间花时间修复潜在问题,那么您的 MTTR 将不包括离开办公室的 16 个小时)。如果您有多个地点的团队全天候工作,或者您的待命员工在下班后工作,那么定义如何跟踪这个指标的时间很重要。
如何以及何时使用平均解决时间
MTTR 通常用于讨论计划外事件,而不是服务请求(通常是计划内的)。
MTTR:平均响应时间
平均响应时间是多少?
MTTR(平均响应时间)是从首次收到产品或系统故障警报开始,到从产品或系统故障中恢复所需的平均时间。这不包括警报系统中的任何延迟时间。
如何计算平均响应时间
要计算此 MTTR,请将从警报到产品或服务完全恢复正常运行时的全部响应时间相加。然后除以事件数。
例如:如果您在一周 40 个小时的工作时间内发生了四起事件,并且在这些事件上总共花费了一个小时(从警报到修复),则该周的 MTTR 为 15 分钟。
如何以及何时使用平均响应时间
在衡量团队在抵御系统攻击方面的成功时,通常将此 MTTR 用于网络安全。
MTTA:平均确认时间
平均确认间隔时间是多少?
MTTA(平均确认时间)是从触发警报到开始处理问题所花费的平均时间。此指标可用于跟踪团队的响应能力和警报系统的有效性。
如何计算平均确认时间
要计算您的 MTTA,请将警报和确认之间的时间相加,然后除以事件数。
例如:如果您有 10 个事件,而所有 10 个事件的警报和确认之间总共有 40 分钟,则将 40 除以 10 得出平均值 4 分钟。
如何以及何时使用平均确认时间
MTTA 在跟踪响应速度方面很有用。您的团队是否受警报疲劳困扰并且响应时间过长?此指标将帮助您标记问题。
MTTF:平均故障时间
平均故障时间是多少?
MTTF(平均故障时间)是技术产品两次不可修复得故障之间的平均时间。例如,如果 X 品牌的汽车发动机在完全失效且必须更换之前平均为 500,000 小时,则发动机的 MTTF 将达为 500,000。
该计算用于了解系统通常会持续多长时间,确定新版本的系统性能是否优于旧版本,并向客户提供有关预期使用寿命以及何时安排系统检查的信息。
如何计算平均故障时间
平均故障时间是算术平均值,因此您可以通过将正在评估的产品的总运行时间相加,然后将该总运行时间除以设备数量来计算。
例如:假设您在计算灯泡的 MTTF。Y 品牌的灯泡在烧坏之前平均能持续多长时间?假设您有四个灯泡的样本需要测试(如果您想要具有统计学意义的数据,那您需要的远不止于此,但为了简单的数学目的,我们保持这个小值)。
灯泡 A 持续 20 个小时。灯泡 B 持续 18 个小时。灯泡 C 持续 21 个小时。灯泡 D 持续 21 个小时。总共 80 个小时。除以四,MTTF 为 20 个小时。

平均故障时间问题
通过灯泡这种例子可以看出,MTTF 是一个很有意义的指标。我们可以运行灯泡直到最后一个灯泡出现故障,然后利用这些信息得出关于灯泡弹性的结论。
但是,当我们测量那些不会很快出现故障的东西时会发生什么?那些本来可以使用很多年的东西。对于这些情况,尽管经常使用 MTTF,但它并不是一个很好的指标。因为在大多数情况下,我们不是在产品出现故障之前一直运行产品,而是要在规定的时间长度内运行产品,并测量有多少产品出现故障。
例如:假设我们正在尝试获取 Z 品牌平板电脑上的 MTTF 统计数据。希望平板电脑能用很多年。但是 Z 品牌可能只有六个月时间来收集数据。因此,他们对 100 台平板电脑进行了六个月的测试。假设一台平板电脑恰好在六个月期限出现故障。
因此,我们计算总使用时间(六个月乘以 100台平板电脑),得出 600 个月。只有一台平板电脑出现故障,所以我们将其除以一,那么我们的 MTTR 将为 600 个月,也就是 50 年。
Z 品牌的平板电脑每台能平均使用 50 年吗?不太可能。因此,在这样的情况下,指标会被分解。
如何以及何时使用平均故障时间
当您尝试评估寿命较短的产品和系统(例如灯泡)的平均寿命时,MTTF 很好用。它也仅适用于评估全部产品故障的情况。如果您要计算需要修复的事件之间的间隔时间,可以使用 MTBF(平均故障间隔时间)。
MTBF vs. MTTR vs. MTTF vs. MTTA
那么,在跟踪和改善事件管理方面,哪种衡量标准更好呢?
答案是全部。
虽然它们有时可以互换使用,但每个指标都提供了不同的见解。组合使用时,它们可以更完整地讲述您的团队在事件管理方面的成功程度以及团队可以改进的地方。
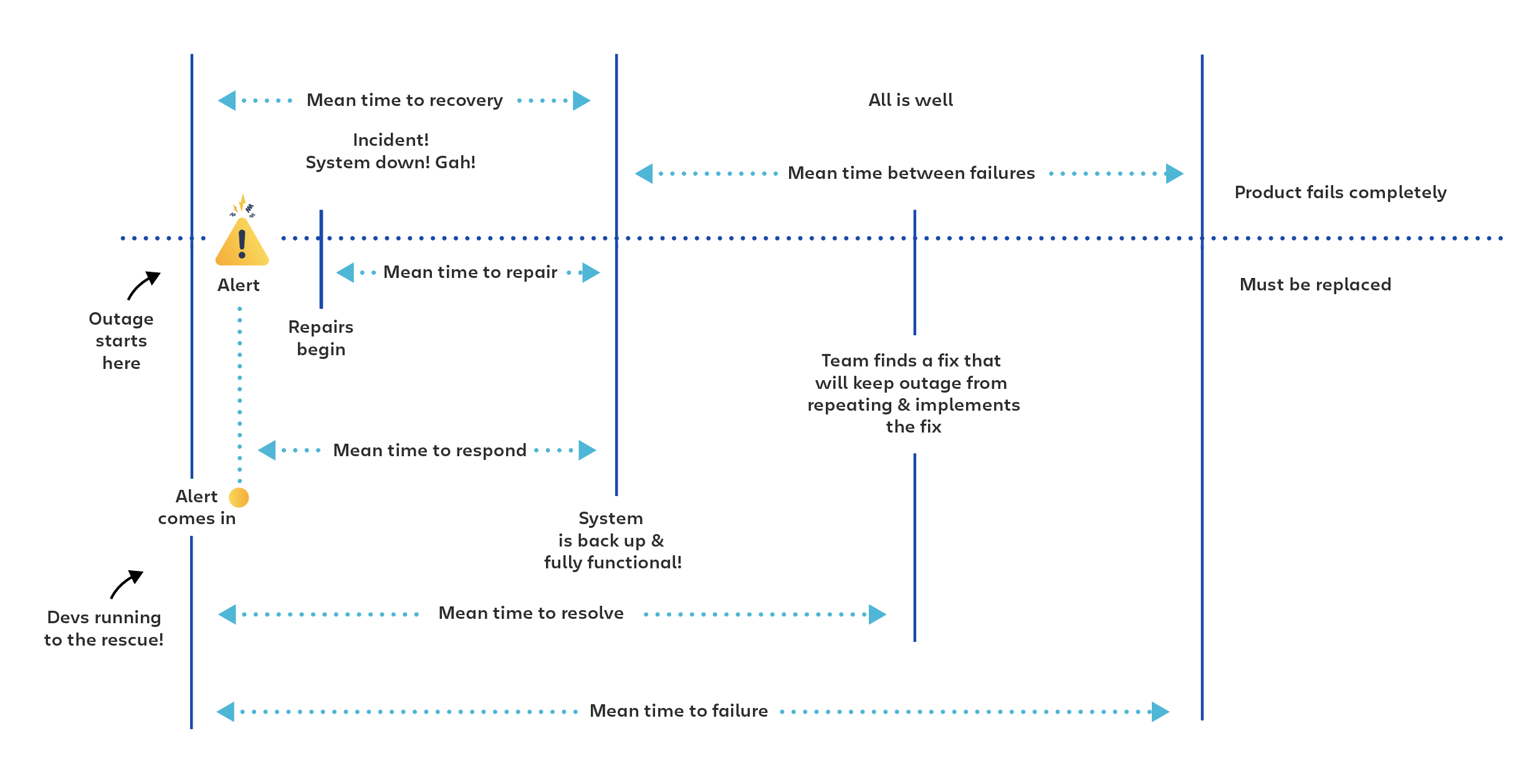
平均恢复时间告诉您系统能以多快的速度恢复运行。
加上平均响应时间,您就可以知道有多少恢复时间属于团队,多少属于您的警报系统。
再加上平均修复时间,您就能开始了解团队在修复和诊断上花了多少时间。
加上平均解决时间,您就会开始了解修复和解决问题的全部范围,而不仅仅是问题造成的实际停机期间。
再加入平均故障间隔时间,信息就会更详尽,显示您的团队在预防或减少未来问题方面的成功程度。
然后再加上平均故障时间,了解产品或系统的整个生命周期。
Jira Service Management 提供报告功能,因此您的团队可以跟踪 KPI 并监控和优化您的事件管理实践。