作者:肖迪(墨诩)

一、前言
这个季度主推安全月构筑&夯实稳定性底盘,就组织了组里的同学对核心业务链路进行了稳定性的摸排。在摸排过程中,不断有个声音在问你摸排出来的问题就是全部问题么?你加的监控加全了么?你的技改方案考虑全了么?(这个声音主要来自左耳,因为我leader坐在我的左边,哈哈哈哈)所以我们一直在思考和对焦,如何体系化的进行稳定性建设,横向有方法论的指导与沉淀,纵向可以跟踪各个业务线的过程和结果,于是就有了下面这张图。
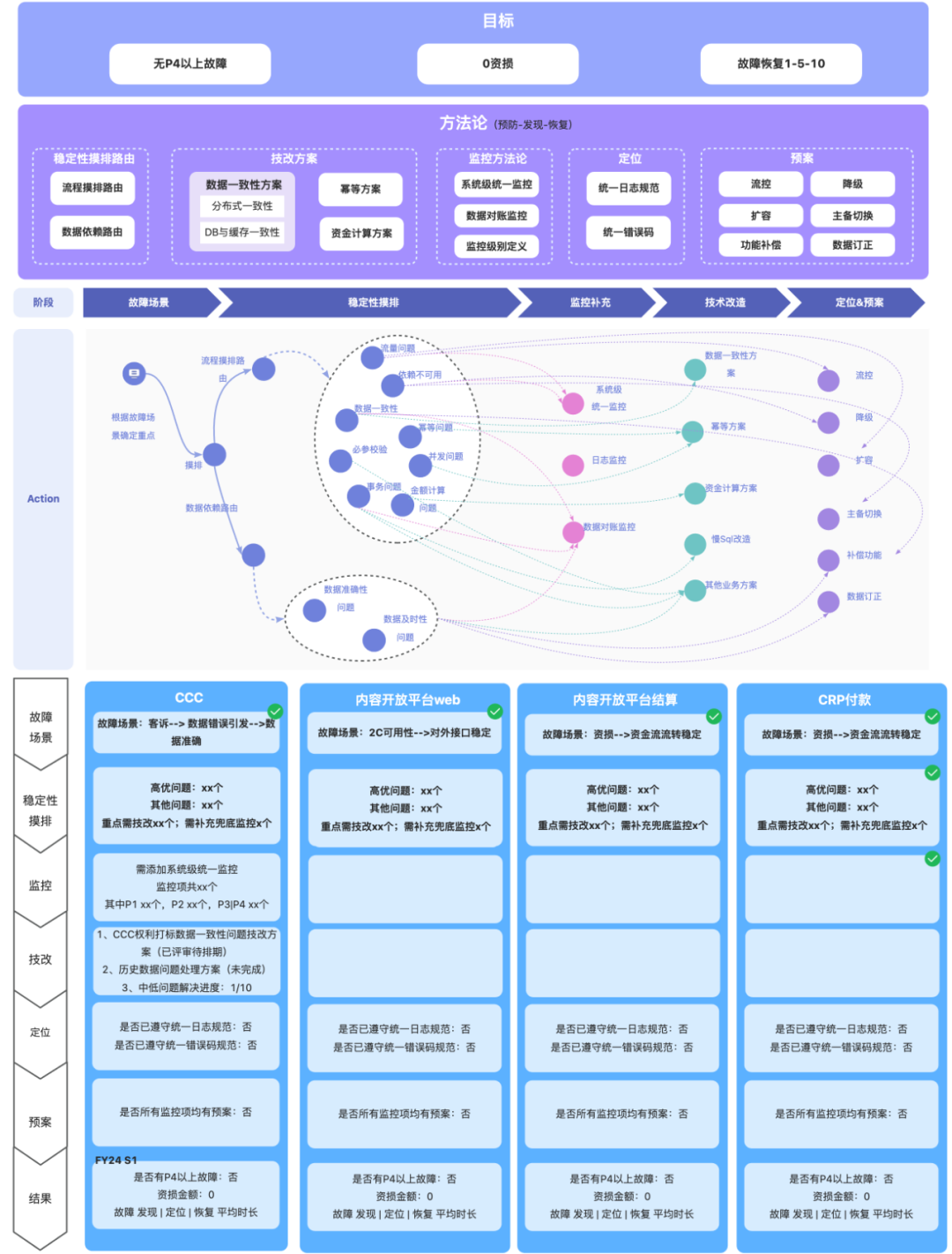
这张图主要分为四个部分,一、确定目标,是一切开始的前提;二、方法论部分用于沉淀稳定性建设的理论方法,支撑后续的动作;三、动作路由,对应方法论部分希望可以用一张图把建设路径讲清楚;四、拿结果,对应各个阶段进行进度跟踪,保证可以拿到最后的结果。方法论部分会主要以如何摸排为主回答前面的三个问题。
二、确定目标
做稳定性摸排的第一原则是要假设任何地方都可能出问题,但只有原则的直接影响就是,摸排过程中会觉得“都是问题,又可能都不是问题”。所以,做摸排的第一件事就是要确定目标,有了目标才有重点和优先级。
整体的目标,应该所有业务都大体相同,“无Px以上故障”,“0资损”,“故障恢复1-5-10”。但针对不同的业务和不用应用的职责会有不同的目标偏重,比如2C业务的目标更偏重服务稳定性,2B业务的目标更偏重数据一致性,涉及到资金流转的业务目标更偏重资损。
所以在摸排之前一定要确定自己负责的业务应用的目标是什么,可以和GOC的同学拉通所有的故障场景,这样摸排的优先级会更清晰。有了重点目标之后,就可以分清楚哪些是核心链路,并且在摸排的过程中也可以将摸排出的问题标出优先级,有助于我们后续更快更有效的加监控和技改。
以我们自身的业务来举例,我们团队叫内容资产,是负责优酷百亿级别内容引入资产的管理和价值挖掘。三块主业务是内容版权管理的CRP,内容权利管理的CCC,以及内容引入的开放平台。CRP管理版权信息流和资金流,所以重点目标是0资损;CCC的数据会影响下游端侧是否有播放权利,内容播放不了可能会引发客诉,所以重点目标是避免数据不准确导致的客诉;开放平台的用户是合作商算是半2C,所以重点目标是服务可用。
CRP的第一重点是0资损,所以可能引发资损场景的就是核心链路;可能引发资损的问题优先级为高;2B业务的重点在于数据的准确性,所以可能导致数据不准确的问题优先级为重;其他的比如易用性问题、不影响前俩项的服务不可用问题等等可以列为低。
三、方法论
3.1 你摸排出来的问题就是全部问题么?
这是稳定摸排面临的第一个问题,面临这个问题的时候我们必须得承认,没有任何银弹可以干掉一切妖魔鬼怪,顺带带走“黑天鹅”。但如何把我们认知范围内的隐患全部找到,应该是可以有一套方法论的。
在团队最开始做摸排的时候,为了解决这个问题我根据经验拉了一个很长的list,希望在排查代码的时候可以辅助找到所有的问题。这种方法有俩个问题:第一个“如果没有优先级那么所有问题都是低优先级”,假设每一行代码都有可能出现问题就会不知道从哪开始,而且工作量巨大;第二个“只有结果没有过程”,在实际过问题列表的时候,没有办法判断是否是全部问题。
可见上述的方法不是一个可靠高效的方法,我们需要一种可以指导过程并推导出完整结果的方法论。
流程摸排路由
整个流程摸排路由中,我们需要三张图:核心链路图、流程时序图、问题路由图
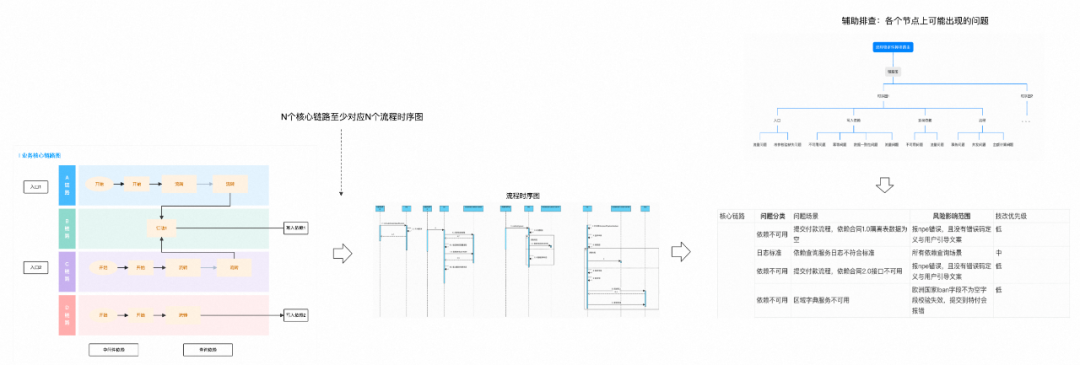
核心链路图
摸排的原则是假设每一行代码都可能出问题,但我们不可能一次性全部摸排完成,那应该高优的摸排的代码是哪些?这个就是需要从我们最开始确定的目标开始推导,可能会发生重点问题的流程就是高优排查的范围。以CRP举例,CRP的第一重点是0资损,那涉及到资损的付款流程就是我们要高优排查的模块,其中实际的审批付款流程是需要高优排查的,付款列表等不会产生资损可以优先级放低。
根据推导我们找到了核心链路,转化成业务的核心链路图,图中要重点产出:1、N条核心链路;2、各链路的调用入口;3、链路过程中的中间件以及查询依赖;4、写入依赖。
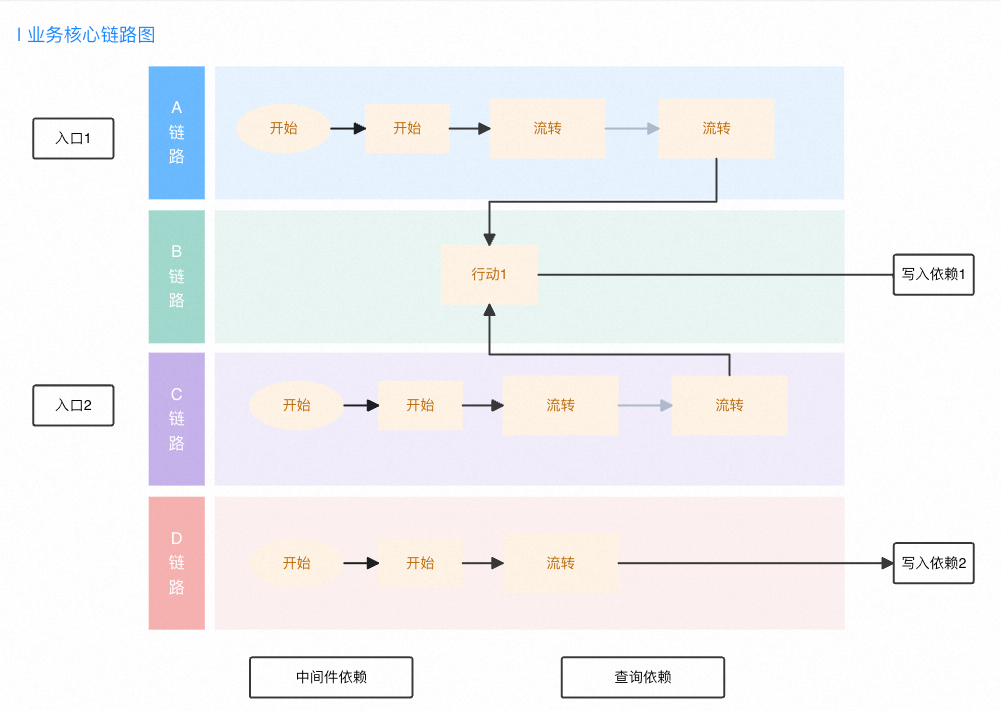
流程时序图
有了核心链路图之后,我们就确定了优先摸排的范围,然后就要实际梳理代码,产出核心链路对应的流程时序图。时序图要保证俩件事情:1、N个核心链路至少要对应N个流程时序图,保证不会漏掉;2、在流程时序图中,对于RPC调用和关键实体的操作要重点关注,不要漏掉。
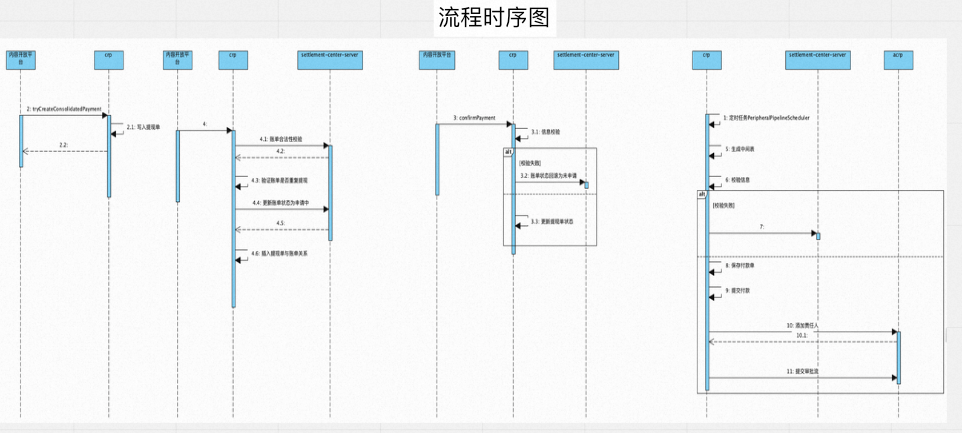
问题路由图
经过前俩步的推导,找到了核心链路中的关键节点,接下来只需要根据关键点的类型,路由到可能出现的问题进行重点排查。调用入口出要注意流量问题、核参校验问题、幂等问题;写入依赖需要注意不可用问题、幂等问题、数据一致性问题等;流程过程中要注意事务问题、并发逻辑问题以及会带来资损的金额计算问题等。

有了这三张图,我们就可以将每一行代码都进行全量问题的摸排判断,缩减为核心流程中关键节点对应的各自类型的问题摸排判断;并且过程中有了核心链路和关键节点的推导,可以保证不会带来摸排遗漏。在组内review的时候,上面三个图也可以提供是否“全”的判断依据。
3.2 你加的监控加全了么?
解决了摸排问题不全的问题,面临的第二个问题就是我们加全了么?监控作为发现问题的主要手段,在日常运维工作中非常重要,如果可以尽早发现就可以及时止血。常用的监控手段有数据对账和日志监控俩种,数据对账常用于信息流与资金流流转的数据一致性监控,日志监控常用于系统流程异常的监控。那我们又如何保证我们的监控是全面和有效的?
数据依赖路由
数据对账是为了发现信息和资金流转过程中的数据不一致问题,但业务单据的字段少则几十多则上百,到底应该加哪些字段的监控,对账的触发点应该怎么设置?还是三张图推导:场景用例图、数据模型依赖图、状态机列表。
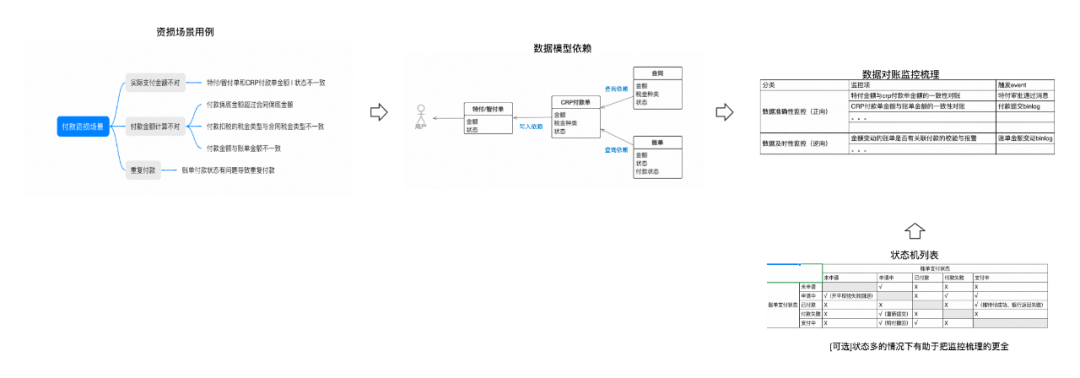
场景用例图
首先还是要从目标出发进行推导,找到所有重点问题可能发生的场景,将场景用例画到脑图中。重点是要涵盖所有的问题场景,以及问题场景中所涉及的业务实体与字段。
以我们自身的业务场景为例,版权资产的付款是优酷内容引入的资金链出口,容易产生资损场景。资损场景主要实际支付金额不对、付款金额计算不对、重复付款三个场景。
付款金额计算不对:
1、CRP付款单提交的时候,要保证付款的金额不能超过合同保底金额
2、......
实际支付金额不对:.......
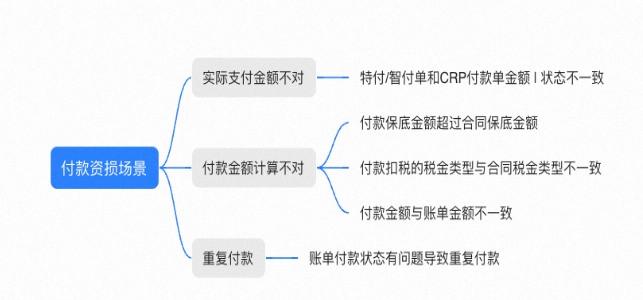
通过上面的梳理就可以得到第二张图
数据模型依赖图
还是沿用上面的例子,根据上图所有场景的描述中可以推导出所有涉及的业务实体的依赖关系以及关键字段,这些就是我们需要做数据对账的核心字段。核心字段有了就要解决第二个问题,触发对账的event应该是什么?多数情况下我们只会去按照业务流程走向正向的添加监控,比如以提交CRP付款单为event,触发单据金额与合同金额的对账。
这样会覆盖到大部分的问题场景,但同时可能会忽略一些低频却又很重要的问题。比如CRP付款单已经提交触发正向的数据对账通过,但在资金流流转过程中,合同的金额变小且小于付款的金额,如果做不到及时通知并且干预,就会产生资损问题。
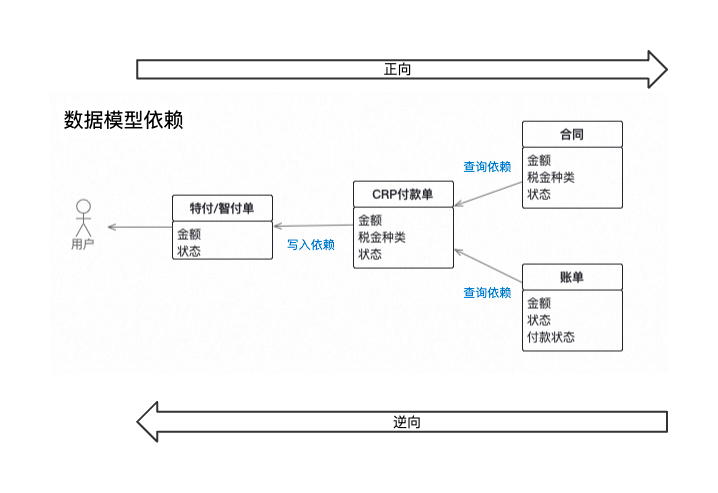
所以在添加监控的时候,除了根据业务走向的正向数据对账之外,也要考虑逆向的数据对账,并根据可能产生问题的严重程度进行有优先级的监控建设。
状态机列表
由于付款单据与付款凭证(账单)之间的状态流转有依赖关系,俩个单据自身的状态流转也有卡口规则,所以在实操过程中我们列了一个状态机列表,辅助数据对账准确无遗漏的落地。这个图非必选,但如果摸排的业务中同样有复杂的业务单据状态流转的依赖关系,建议画出此图辅助监控的添加。

系统级统一监控
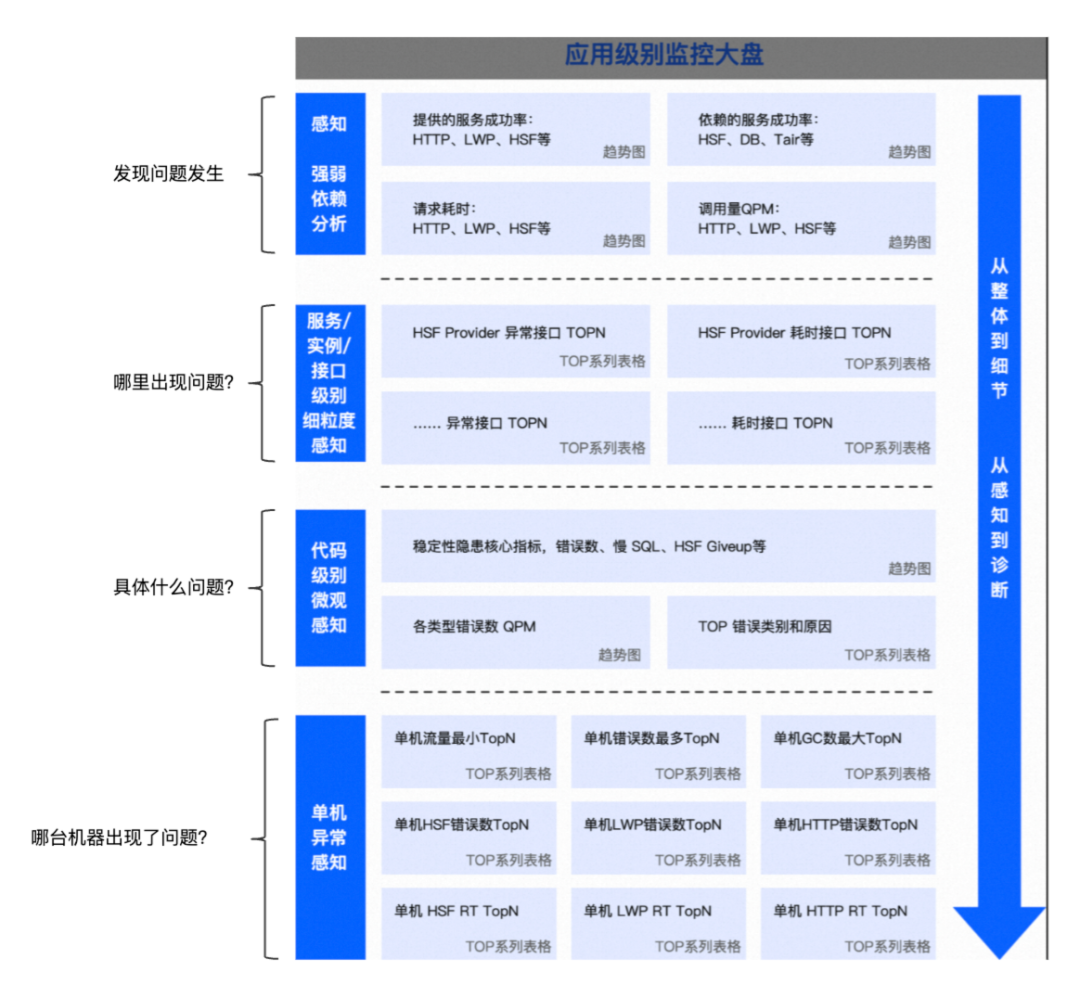
除了数据对账监控,另一个重要手段就是日志监控。加日志监控的时候通常会面临一个状况,就是加了监控也很难定位到问题。所以我们需要一个方法不仅可以发现问题发生,还能定位到具体是哪里出现问题,具体什么问题,甚至在多机器应用到底是哪台除了问题。这里我们借鉴了一位大佬的方法论,配置了一套从整体到细节,从感知到诊断的系统统一监控,可以很好的解决上面提到的问题。↓↓↓↓↓
3.3 你的技改方案考虑全了么?
代码中的问题都定位到了,有些需要进行技术改造,对应不同的问题你的技术方案都考虑全了么?顺着这个问题,我整理了一张图稳定性摸排全链路(摸排->监控补充->技术改造->预案)的Action路由图,希望可以使团队同学在稳定性建设过程中有个体系化的指导。
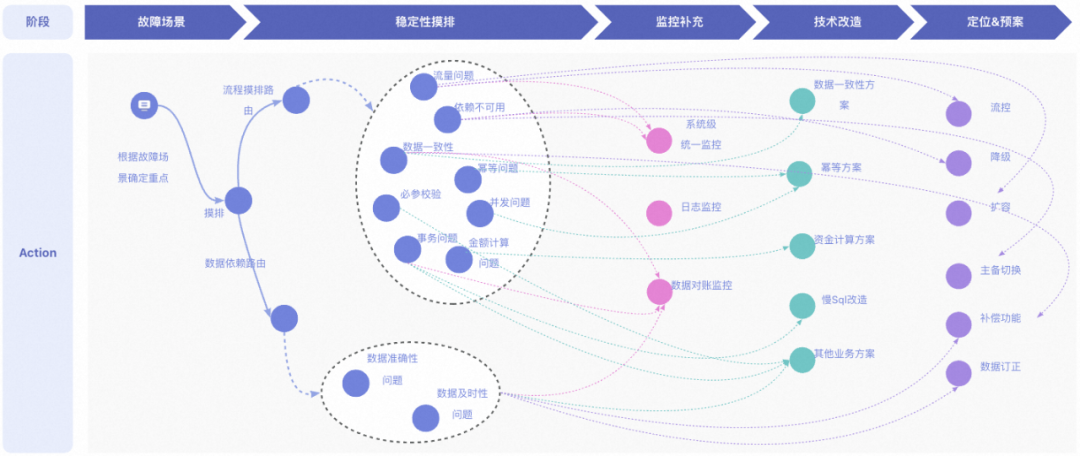
通用方案主要分为几类,数据一致性方案、幂等方案、防资损方案、慢sql改造方案,慢SQL改造都是基本功,不再赘述。
四、拿结果
这个部分不用多说,就是对应Action路由的各个阶段的过程结果监控,以及最终结果的达成。什么展现形式不重要,重点是要有跟进保证最终结果的达成。截止目前,我们团队在核心链路上共摸排出13个高优的问题,技改方案全部产出review排期解决中;和测试的同学配合新增监控42个,其中19个是摸排出来的;无P级bug,0资损。

五、最后
系统稳定性是保证我们拿到一切业务价值的基础,重要性不言而喻。稳定性建设其实是一个持续性的工作,最近一个财年交接了很多新的业务过来,所以集中做了一次突击摸排。工作多且杂,需要测试、产品、开发团队通力配合完成,过程中一起总结出来的一些方法论希望对大家有所帮助。