JUC、线程池相关内容
文章目录
- JUC、线程池相关内容
- 一、 什么是线程池
- 1.1 为什么要使用线程池
- 二、 JDK 自带的线程池
- 2.1 newFixedThreadPool方法
- 2.2 newSingleThreadPool方法
- 2.3 newCachedTreadPool方法
- 2.4 newScheduleTreadPool方法
- 2.4.5 Executors Demo
- 2.5 newWorkStealingTreadPool方法
- 2.5.1 使用ForkJoinPool测试
一、 什么是线程池
1.1 为什么要使用线程池
1.在开发中,为了提升程序的执行效率,我们需要将也写业务采用多线程的方式去执行 , 或者将一个很大的任务拆分为几个小块分别执行
1.1 例如一次请求需要分别查询三张数据表的数据 那么我们就可以使用线程分别去执行查询三张表数据 最后做一次汇总即可 (这样比单个线程串行执行效率可能会高很多)
1.2 再或者 发送短信业务、发送邮件业务 , 使用异步执行这种逻辑操作(其实就是构建一个线程去执行)
1.3像上边这种 执行异步任务时需要新建线程 , 任务执行完毕后再被销毁 , 这样的话会对系统造成一些额外的开销。
而且还无法进行统计等操作
需要一个线程的管理中心来管理这些线程,这样也可以将业务和管理线程部分充分解耦合,也可以实现统计功能
1.4 简单理解线程池就是 : 在Java集合中存储了大量的线程对象,每次需要执行异步任务时则不需要创建线程,直接从集合中拿到线程执行方法即可
2.在线程池构建初期,可以将需要执行的任务提交到线程池中。会根据一定的机制来执行这个任务
2.1 可能提交的任务直接被执行
2.2 任务可以被暂时存储起来,等到有空闲的线程时再来处理该任务
2.3 任务也可能被拒绝,无法执行 (线程池中的任务数量是有一定限制的)
3.JDK提供的线程池中 记录了每个线程处理了多少个任务,以及这个线程池处理了多少个任务,同时还可以针对任务执行前后做一些钩子函数的实现(类似AOP业务增强)
3.1 可以在任务的执行前后记录一些日志信息,这样就可以统计线程池的数据了
二、 JDK 自带的线程池
JDK中基于Executors提供了很多类型的线程池 , 都是基于ThraedPoolExecutor来创建的
2.1 newFixedThreadPool方法
这个方法创建的线程池的特点是
线程数量是固定的线程池
/**
* 使用时 选哟指定一个长度nThreads 来作为这个固定长度线程池的入参 , nThreads就是线程池中线程的个数
*
* 构建好当前线程池后、线程个数是已经固定好了的,但是里边的线程是懒加载的(构建时线程还未创建出来,随着任务的提交才会将线程在线程池中构建出来)
* 如果线程没构建,线程会带着任务被创建和执行,如果线程都已经构建好了 但是没有线程可以空闲执行此任务那么此任务就放到阻塞队列中 等待被空闲线程拿取执行
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
2.2 newSingleThreadPool方法
/**
* 看名字就知道是一个单例线程池 , 线程池内部只有一个线程在执行
*
* 如果任务涉及到顺序消费,那么就可以使用这个线程池
*
*/
public static ExecutorService newSingleThreadExecutor() {
// 包装内部的线程池对象
return new FinalizableDelegatedExecutorService
// 内部依然是使用 ThreadPoolExecutor 构建线程 只不过外部还有一层包装
// 任务放到阻塞队列的顺序就是工作线程处理的顺序 所以这个线程池可以处理顺序处理的业务操作
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- FinalizableDelegatedExecutorService 包装类
static class FinalizableDelegatedExecutorService
extends DelegatedExecutorService {
FinalizableDelegatedExecutorService(ExecutorService executor) {
super(executor);
}
// 当前对象被GC干掉之前要执行该方法finalize()
// shutdown方法 将当前线程池停止、并且干掉工作工作线程
// 但是GC是不确定性的 finalize 是无法保证一定会执行完毕 , 所以一定要手动结束线程池
protected void finalize() {
super.shutdown();
}
}
2.3 newCachedTreadPool方法
看名字像是一个缓存的线程池
/**
* 当第一次提交任务到线程池中,会构建一个工作线程
* 当这个工作线程执行完成之后 60s没有任务需要执行后 会自动结束
* 如果在60s内有任务进来需要执行,那么这个线程会拿到这个任务去执行
* 如果后续提交任务时没有空闲的线程可以执行该任务 , 那么就会创建工作线程去执行任务(同样是上边的60秒逻辑)
*
* 特点: 只要任务提交到这个缓存的线程池中,那么一定是有工作线程来处理该任务的(没有就创建)
* 也不是每次都创建一个新的线程,而是有线程可以执行任务那么就不用创建新的了
*
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
2.4 newScheduleTreadPool方法
看名字直到 这个方法创建的是一个能执行定时任务的线程池,这个线程池可以 以一定周期执行某个任务,或者延迟多久执行任务
/**
* ScheduledThreadPoolExecutor 这个类 继承了 ThreadPoolExecutor
* 所以本质上还是正常的线程池 , 在原来的线程池的基础上 添加了定时任务的功能
* - 延时执行任务的原理是基于DelayQueue
* - 周期性执行任务-是任务执行完之后再次把当前任务添加到线程池中
*
*
*/
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());
}
- 还有一个单例的定时任务线程池
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
2.4.5 Executors Demo
public class ExecutorsDemo {
public static void main(String[] args) {
// testNewFixedThreadPool();
// testSingleThreadPool();
// testCachedThreadPool();
testScheduledThreadPool();
}
private static void testNewFixedThreadPool(){
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
for (int i = 0; i < 3; i++) {
fixedThreadPool.execute(() -> {
System.out.println(Thread.currentThread().getName());
});
}
/*
pool-1-thread-1
pool-1-thread-2
pool-1-thread-1
程序并没有结束,需要手动关闭线程池
*/
}
private static void testSingleThreadPool(){
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "--" + "Singleton1");
}); executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "--" + "Singleton2");
}); executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "--" + "Singleton3");
}); executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "--" + "Singleton4");
});
/*
pool-1-thread-1--Singleton1
pool-1-thread-1--Singleton2
pool-1-thread-1--Singleton3
pool-1-thread-1--Singleton4
程序并没有结束,需要手动关闭线程池
*/
}
/**
* 测试缓存的线程池
*
* 使用此线程池 提交任务后一定有工作线程来处理该任务 如果有空闲的线程那么就使用空闲的线程处理 没有则创建新的线程来处理
*/
private static void testCachedThreadPool(){
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
final int j = i;
cachedThreadPool.execute(() -> {
// try {
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
System.out.println(Thread.currentThread().getName() + "--" + (j+1));
});
}
/*
每个任务的处理时间都是5s左右 处理结果
pool-1-thread-4--4
pool-1-thread-5--5
pool-1-thread-6--6
pool-1-thread-10--10
pool-1-thread-9--9
pool-1-thread-7--7
pool-1-thread-2--2
pool-1-thread-8--8
pool-1-thread-3--3
pool-1-thread-1--1
每个任务处理时间都是瞬间处理完成,注释掉休眠的代码
可以看到 当有空闲的线程时就不会再次创建新线程了
pool-1-thread-1--1
pool-1-thread-4--4
pool-1-thread-3--3
pool-1-thread-2--2
pool-1-thread-5--5
pool-1-thread-8--8
pool-1-thread-9--9
pool-1-thread-7--7
pool-1-thread-6--6
pool-1-thread-10--10
pool-1-thread-3--11
pool-1-thread-2--12
pool-1-thread-1--20
pool-1-thread-8--18
pool-1-thread-6--15
pool-1-thread-10--14
pool-1-thread-7--16
pool-1-thread-3--13
pool-1-thread-9--17
pool-1-thread-5--19
*/
cachedThreadPool.shutdown();
}
private static void testScheduledThreadPool(){
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10);
// 正常执行
scheduledExecutorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + ":正常执行-" + System.currentTimeMillis());
});
// 延迟执行
scheduledExecutorService.schedule(() -> {
System.out.println(Thread.currentThread().getName() + ":延时3s执行-" + System.currentTimeMillis());
} , 3 , TimeUnit.SECONDS);
// 周期执行
// 这个方法在计算下次任务执行时间时 , 是在开始执行任务时就已经计算好了
// 因此可以理解为 后续任务一直都是按照 period 参数时间间隔执行的 (不管这个任务的执行时间是多少)
/*
pool-1-thread-1:先计算下次任务时间-周期执行1671353434730
pool-1-thread-3:先计算下次任务时间-周期执行1671353437737
pool-1-thread-2:先计算下次任务时间-周期执行1671353440749
pool-1-thread-1:先计算下次任务时间-周期执行1671353443754
pool-1-thread-4:先计算下次任务时间-周期执行1671353446767
pool-1-thread-3:先计算下次任务时间-周期执行1671353449775
...
可以看出时间差距大概就是 1s 左右
*/
// scheduledExecutorService.scheduleAtFixedRate(() -> {
// try {
// Thread.sleep(3000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// System.out.println(Thread.currentThread().getName() + ":先计算下次任务时间-周期执行" + System.currentTimeMillis());
// },2 , 1 , TimeUnit.SECONDS);
// 而这个方法是在这个任务执行完之后才计算下次的执行时间的 (因此任务的执行时间不同 下次任务执行的时间也固定)
/*
pool-1-thread-9:执行完方法后才计算下次运行时间-周期执行1671353571901
pool-1-thread-9:执行完方法后才计算下次运行时间-周期执行1671353575913
pool-1-thread-9:执行完方法后才计算下次运行时间-周期执行1671353579925
pool-1-thread-9:执行完方法后才计算下次运行时间-周期执行1671353583944
pool-1-thread-9:执行完方法后才计算下次运行时间-周期执行1671353587971
pool-1-thread-5:执行完方法后才计算下次运行时间-周期执行1671353591977
...
可以看出任务执行了3s 然后又延迟了1s后才执行的任务
*/
scheduledExecutorService.scheduleWithFixedDelay(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":执行完方法后才计算下次运行时间-周期执行" + System.currentTimeMillis());
},2 , 1 , TimeUnit.SECONDS);
}
}
2.5 newWorkStealingTreadPool方法
这个创建线程池的方式和之前的线程池有非常大的区别 , 之前的 定长、单例、缓存、定时任务都基于ThreadPoolExecutor实现
而这个 newWorkStealingThreadPool 是基于 FormJoinPool实现
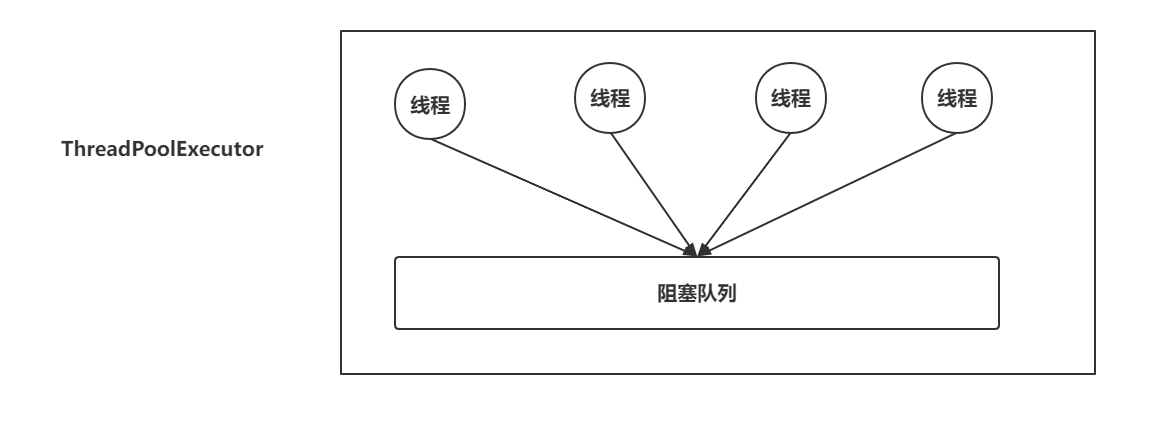
ThreadPoolExecutor特点:
1.在ThreadPoolExecutor中只有一个阻塞队列存放、读取 当前任务
ForkJoinPool特点:
1.从名字就可以看出一些内容 Fork(拆分)、Join(聚合) , ForkJoinPool可以将一个大任务分成多个小任务并放到当前线程的阻塞队列中,其他空闲线程也可以去处理有任务的线程的阻塞队列中的任务(充分发挥线程资源)
2.ForkJoinPool最大的特点就是 为了不让线程池内部的其他工作线程闲下来、而比较重要的就是任务的拆分(分而治之)
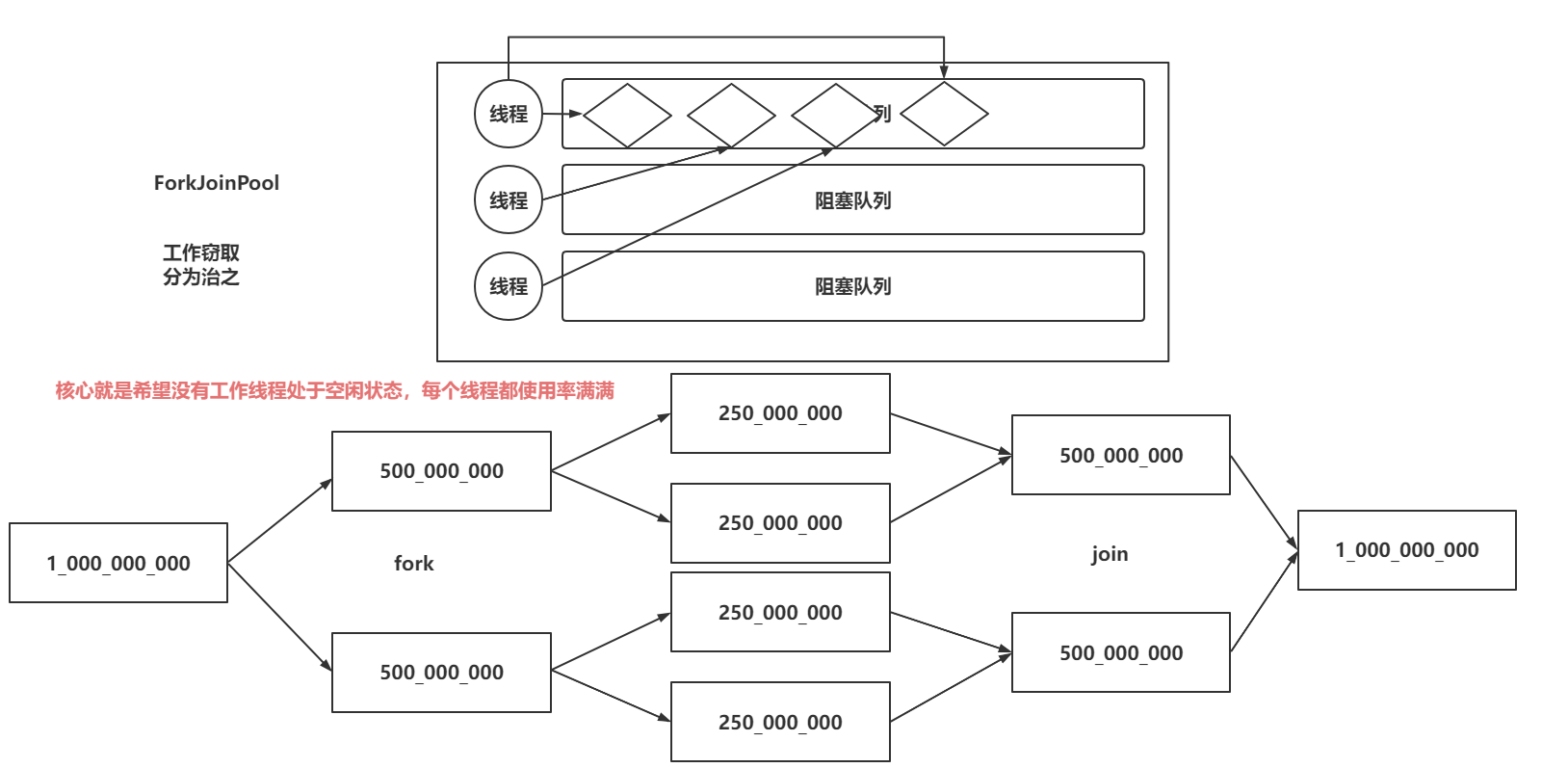
- Executors中使用ForkJoinPool的创建方式
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
2.5.1 使用ForkJoinPool测试
场景: 创建一个比较大的数组,然后把里面存满值,然后计算总和 , 对比单线程和ForkJoin的方式区别
public class ForkJoinPoolTest {
// 存放一亿个数据
static int[] nums = new int[100_000_000];
static {
// 初始化数组中的数据
for (int i = 0; i < nums.length; i++) {
nums[i] = (int)((Math.random()) * 10);
}
}
public static void main(String[] args) {
singletonThread();
System.out.println("======================");
forkJoinPool();
/*
输出结果:
单线程执行该任务
单线程执行该任务结果为:449964178-执行时间为:37905200
======================
ForkJoin执行该任务
ForkJoin执行该任务结果为:449964178-执行时间为:25882600
37905200
25882600
*/
}
/**
* 使用单线程执行任务
*/
private static void singletonThread(){
long start = System.nanoTime();
System.out.println("单线程执行该任务");
int result = 0;
for (int i = 0; i < nums.length; i++) {
result += nums[i];
}
long end = System.nanoTime();
System.out.println("单线程执行该任务结果为:" + result + "-执行时间为:" + (end - start));
}
/**
* 使用ForkJoinPool来拆分聚合任务
*
* ForkJoin中提交任务不推荐使用Runnable和Callable , 而是使用ForkJoinTask
* Runnable --> RecursiveAction 对应没有返回值
* Callable --> RecursiveTask 对应有返回值
*
*/
private static void forkJoinPool(){
ForkJoinPool forkJoinPool = (ForkJoinPool) Executors.newWorkStealingPool();
int result = 0;
System.out.println("ForkJoin执行该任务");
long start = System.nanoTime();
SumRecursiveTask sumRecursiveTask = new SumRecursiveTask(0, nums.length - 1);
ForkJoinTask<Integer> submit = forkJoinPool.submit(sumRecursiveTask);
try {
result = submit.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("ForkJoin执行该任务结果为:" + result + "-执行时间为:" + (end - start));
}
/**
ForkJoinTask是个抽象类 他的两种计算结果在这使用带返回值的 RecursiveTask 构建实现类
实现的compute方法需要设置好 任务拆分、聚合的逻辑
针对当前场景 , 则让每个线程处理 5千万个数据
*/
private static class SumRecursiveTask extends RecursiveTask<Integer>{
/** start、end 指定线程 处理数组中哪一段的数据 */
private int start , end;
// 每个线程处理 两千万个数据 (步长) , 因此1亿数据 需要5个线程
private int threadComputeStep = 20_000_000;
public SumRecursiveTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int threadSum = 0;
int threadStep = end - start;
if (threadStep <= threadComputeStep){
// 可以处理任务
for (int i = start; i <= end; i++) {
threadSum += nums[i];
}
} else {
// 将任务拆分然后重新新计算 看能否计算 递归执行
int middle = (start + end) / 2;
// 数组左侧任务
SumRecursiveTask leftTask = new SumRecursiveTask(start, middle);
// 数组右侧任务
SumRecursiveTask rightTask = new SumRecursiveTask(middle + 1, end);
// 分别执行两个任务
leftTask.fork();
rightTask.fork();
// 拿到任务结果
threadSum = leftTask.join() + rightTask.join();
}
return threadSum;
}
}
}
- 总结:
- 最终发现这种累加的操作,采用分而治之的方式效率提升了很多
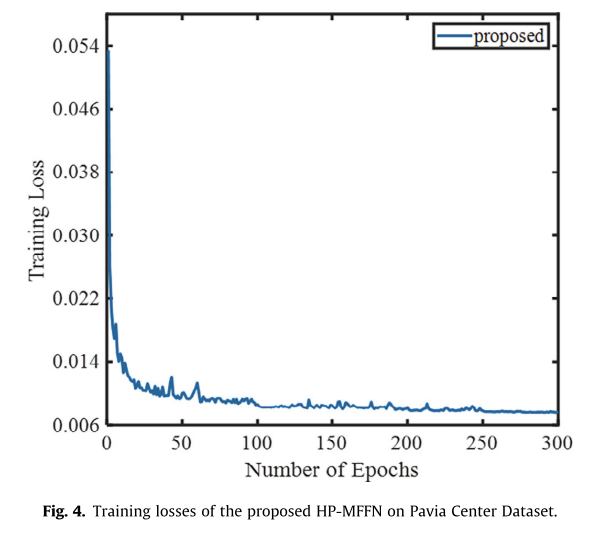
- 但也不是所有的任务都能拆分,前提是任务够大单个线程处理明显力不从心、耗时较长






![[附源码]计算机毕业设计Node.js博客管理系统(程序+LW)](https://img-blog.csdnimg.cn/2b85fbc5b8f64af5b101c3734ae68603.png)


![zibll子比主题6.7用户徽章功能详解及配置教程[V6.7新功能]](https://img-blog.csdnimg.cn/e018a39f6bbf43ec96b4fbb37770d183.png)
![[3D数据深度学习] (PC/服务器集群cluster)CPU内存/GPU显存限制及解决办法](https://img-blog.csdnimg.cn/b38416df2ed745a295158705344273c7.png)