Transformers学习笔记2. HuggingFace数据集Datasets
- 一、简介
- 二、操作
- 1. 下载数据集
- 2. 常用函数
- (1)排序
- (2)打乱顺序
- (3)选择函数
- (4)过滤
- (5)切分数据集
- (6)分桶
- (7)列重命名
- (8)列删除
- (9)数据集转换
- (10)map函数
- (11)数据的保存和加载
- 3. 评价指标 Evaluate
- (1)加载
- (2)从社区加载模块
- (3)列出可用模块
- (4)模块属性
- (5)计算,直接调用函数计算
- (6)计算单个或一批指标
- (7)可视化
一、简介
Datasets库是Hugging Face的一个重要的数据集库。 当需要微调一个模型的时候,需要进行下面操作:
- 下载数据集
- 使用Dataset.map() 预处理数据
- 加载和计算指标
可以在官网来搜索数据集:
https://huggingface.co/datasets
二、操作
1. 下载数据集
使用的示例数据集:
from datasets import load_dataset
# 加载数据
dataset = load_dataset(path='seamew/ChnSentiCorp', split='train')
print(dataset)
打印结果:
Dataset({
features: ['text', 'label'],
num_rows: 9600
})
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1}
2. 常用函数
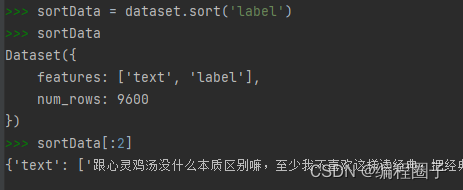
(1)排序
sortData = dataset.sort('label')
(2)打乱顺序
shuffleData = sortData.shuffle(seed=20);
(3)选择函数
从数据集中取出某些指定的部分。
dataset.select([0,1,2,3])
(4)过滤
def filter(data):
return data['text'].startswith('1')
b = dataset.filter(filter)

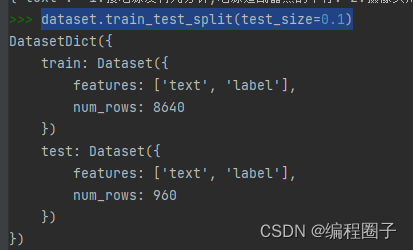
(5)切分数据集
dataset.train_test_split(test_size=0.1)
把数据集切分,10%为测试集。
(6)分桶
把数据集均数若干份,取其中的第几份。
dataset.shard(num_shards=5, index=0)
(7)列重命名
c = a.rename_column('text', 'newColumn')
(8)列删除
d = c.remove_columns(['newColumn'])
(9)数据集转换
set_format函数用来实现与其它库数据格式的转换;
# 转为PyTorch数据集格式
dataset.set_format(type='torch', columns=['label'])
# 转为Pandas格式
dataset.set_format(type='pandas', columns=['label'])
(10)map函数
遍历数据,对每个数据进行处理
def handler(data):
data['text'] = 'Prefix' + data['text']
return data
datasetMap = dataset.map(handler)
(11)数据的保存和加载
dataset.save_to_disk('./')

from datasets import load_from_disk
dataset = load_from_disk('./')
3. 评价指标 Evaluate
安装Evaluate库:
pip install evaluate
(1)加载
import evaluate
accuracy = evaluate.load("accuracy")
(2)从社区加载模块
element_count = evaluate.load("lvwerra/element_count", module_type="measurement")
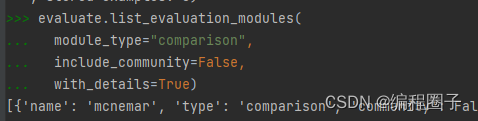
(3)列出可用模块
evaluate.list_evaluation_modules(
module_type="comparison",
include_community=False,
with_details=True)
(4)模块属性
| 属性 | 描述 |
|---|---|
| description | 评估模块说明 |
| citation | 用于引用的 BibTex 字符串(如果可用)。 |
| features | 定义输入格式的对象的特征 |
| inputs_description | 说明 |
| homepage | 模块的主页 |
| license | 模块的许可证 |
| codebase_urls | 模块代码链接 |
| reference_urls | 其他引用网址 |
(5)计算,直接调用函数计算
# 评估值正确率有一半
accuracy.compute(references=[0,1,0,1], predictions=[1,0,0,1])
# 输出
{'accuracy': 0.5}
(6)计算单个或一批指标
for ref, pred in zip([0,1,0,1], [1,0,0,1]):
accuracy.add(references=ref, predictions=pred)
accuracy.compute()
输出:
{'accuracy': 0.5}
批添加:
for refs, preds in zip([[0,1],[0,1]], [[1,0],[0,1]]):
accuracy.add_batch(references=refs, predictions=preds)
accuracy.compute()
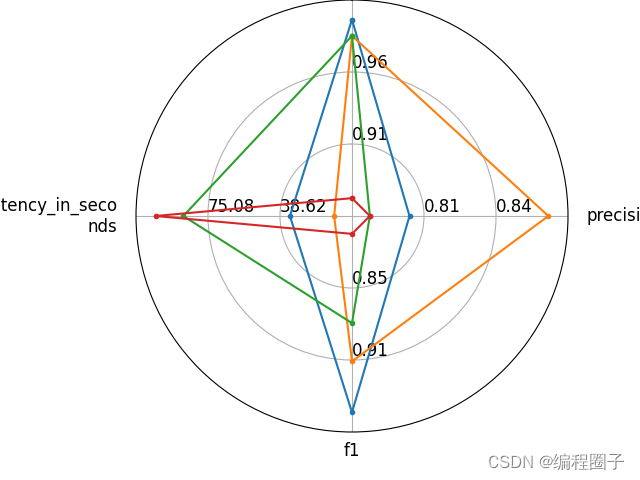
(7)可视化
import evaluate
from evaluate.visualization import radar_plot
data = [
{"accuracy": 0.99, "precision": 0.8, "f1": 0.95, "latency_in_seconds": 33.6},
{"accuracy": 0.98, "precision": 0.87, "f1": 0.91, "latency_in_seconds": 11.2},
{"accuracy": 0.98, "precision": 0.78, "f1": 0.88, "latency_in_seconds": 87.6},
{"accuracy": 0.88, "precision": 0.78, "f1": 0.81, "latency_in_seconds": 101.6}
]
model_names = ["Model 1", "Model 2", "Model 3", "Model 4"]
plot = radar_plot(data=data, model_names=model_names)
plot.show()



![[附源码]计算机毕业设计Node.js博客管理系统(程序+LW)](https://img-blog.csdnimg.cn/2b85fbc5b8f64af5b101c3734ae68603.png)


![zibll子比主题6.7用户徽章功能详解及配置教程[V6.7新功能]](https://img-blog.csdnimg.cn/e018a39f6bbf43ec96b4fbb37770d183.png)
![[3D数据深度学习] (PC/服务器集群cluster)CPU内存/GPU显存限制及解决办法](https://img-blog.csdnimg.cn/b38416df2ed745a295158705344273c7.png)