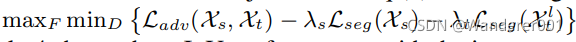【Mysql】SpringBoot整合Sharding-JDBC实现读写分离、分库分表
- (一)介绍Sharding-JDBC
- (1)什么是Sharding-JDBC
- (2)Sharding-JDBC的源码是如何实现对JDBC增强的
- (3)Sharding-JDBC的分片原理
- (4)Sharding-JDBC的相关配置
- (二)分库分表
- (1)概念介绍
- 【1】分库分表
- 【2】分片
- 【3】数据节点
- 【4】逻辑表
- 【5】真实表
- 【6】分片键
- 【7】分片算法
- 【8】分片算法和分片策略的关系
- 【9】分片策略
- 【10】分布式主键
- 【11】广播表
- 【12】绑定表
- (2)分库分表方案
- 【1】垂直切分
- 【2】水平切分
- 【3】分库分表带来的问题
- (3)Sharding-Jdbc分库分表实现原理
- (4)Sharding-Jdbc分库分表案例
- (三)读写分离
- (4)Sharding-Jdbc读写分离案例
(一)介绍Sharding-JDBC
(1)什么是Sharding-JDBC
ShardingSphere-Jdbc定位为轻量级Java框架,在Java的Jdbc层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,可理解为增强版的Jdbc驱动,完全兼容Jdbc和各种ORM框架。
现在的 ShardingSphere 不单单是指某个框架而是一个生态圈,这个生态圈Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这三款开源的分布式数据库中间件解决方案所构成。
ShardingSphere 的前身就是 Sharding-JDBC,所以它是整个框架中最为经典、成熟的组件,先从 Sharding-JDBC 框架入手学习分库分表。
(2)Sharding-JDBC的源码是如何实现对JDBC增强的
(1)增强前的访问数据库代码
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("application.xml");
DataSource dataSource = ctx.getBean("dataSource", DataSource.class);
Connection connection = dataSource.getConnection();
String sql = "select id, name, price, publish, intro from book where id = 111";
PreparedStatement ps = connection.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
// handle ResultSet...
Sharding jdbc是基于JDBC协议实现的,当我们获得dataSource时,这个dataSource是Sharding jdbc自己定义的一个SpringShardingDataSource类型的数据源,该数据源在返回getConnection()及prepareStatement()时,分别返回ShardingConnection和ShardingPreparedStatement的实例对象。然后在executeQuery()时,ShardingPreparedStatement做了这样的一件事:
(1)根据逻辑sql,经过分库分表策略逻辑计算,获得分库分表的路由结果SQLRouteResult;
(2)SQLRouteResult中包含真实的数据源以及转换后的真正sql,利用真实的数据源去执行获得ResultSet;
(3)将ResultSet列表封装成一个可以顺序读的ResultSet对象IteratorReducerResultSet。
class ShardingPreparedStatement implements PreparedStatement {
@Override
public ResultSet executeQuery() throws SQLException {
List<SQLRouteResult> routeResults = routeSql(logicSql);
List<ResultSet> resultSets = new ArrayList<>(routeResults.size());
for (SQLRouteResult routeResult : routeResults) {
PreparedStatement ps = routeResult.getDataSource().getConnection.prepareStatement(routeResult.getParsedSql());
ResultSet rs = ps.executeQuery();
resultSets.add(rs);
}
return new IteratorReducerResultSet(resultSets);
}
.....
}
其中,分库分表策略的sql路由过程,我们将Sharding jdbc中的相关代码全部抽出来,放到一起来观看这个过程的实现:
// 环境准备
@SuppressWarnings("resource")
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("application.xml");
SpringShardingDataSource dataSource = ctx.getBean(SpringShardingDataSource.class);
Field field = SpringShardingDataSource.class.getSuperclass().getDeclaredField("shardingContext");
field.setAccessible(true);
ShardingContext sctx = (ShardingContext)field.get(dataSource);
ShardingRule shardingRule = sctx.getShardingRule();
String logicSql = "select id, name, price, publish, intro from book where id = ?";
List<Object> parameters = new ArrayList<>();
parameters.add(2000);
// sql解析
MySqlStatementParser parser = new MySqlStatementParser(logicSql);
MySQLSelectVisitor visitor = new MySQLSelectVisitor();
SQLStatement statement = parser.parseStatement();
visitor.getParseContext().setShardingRule(shardingRule);
statement.accept(visitor);
SQLParsedResult parsedResult = visitor.getParseContext().getParsedResult();
if (visitor.getParseContext().isHasOrCondition()) {
new OrParser(statement, visitor).fillConditionContext(parsedResult);
}
visitor.getParseContext().mergeCurrentConditionContext();
System.out.println("Parsed SQL result: " + parsedResult);
System.out.println("Parsed SQL: " + visitor.getSQLBuilder());
parsedResult.getRouteContext().setSqlBuilder(visitor.getSQLBuilder());
parsedResult.getRouteContext().setSqlStatementType(SQLStatementType.SELECT);
// 分库分表路由
SQLRouteResult result = new SQLRouteResult(parsedResult.getRouteContext().getSqlStatementType(), parsedResult.getMergeContext(), parsedResult.getGeneratedKeyContext());
for (ConditionContext each : parsedResult.getConditionContexts()) {
Collection<Table> tables = parsedResult.getRouteContext().getTables();
final Set<String> logicTables = new HashSet<>();
tables.forEach(a -> logicTables.add(a.getName()));
SingleTableRouter router = new SingleTableRouter(shardingRule,
logicTables.iterator().next(),
each,
parsedResult.getRouteContext().getSqlStatementType());
RoutingResult routingResult = router.route();
// sql改写 --> routingResult.getSQLExecutionUnits()
// ---> SingleRoutingTableFactor.replaceSQL(sqlBuilder).buildSQL()
// 结果合并
result.getExecutionUnits().addAll(routingResult.getSQLExecutionUnits(parsedResult.getRouteContext().getSqlBuilder()));
}
// amendSQLAccordingToRouteResult(parsedResult, parameters, result);
for (SQLExecutionUnit each : result.getExecutionUnits()) {
System.out.println(each.getDataSource() + " " + each.getSql() + " " + parameters);
}
(1)准备环境。由于Sharding jdbc分库分表中ShardingRule这个类是贯穿整个路由过程,我们在Spring中写好Sharding jdbc的配置,利用反射获取一个这个对象。(Sharding jdbc版本以及配置,在文章最后列出,方便debug这个过程)
(2)sql解析。Sharding jdbc使用阿里的Druid库解析sql。在这个过程中,Sharding jdbc实现了一个自己的sql解析内容缓存容器SqlBuilder。当语法分析中解析到一个表名的时候,在SqlBuilder中缓存一个sql相关的逻辑表名的token。并且,Sharding jdbc会将sql按照语义解析为多个segment。例如,"select id, name, price, publish, intro from book where id = ?"将解析为,“select id, name, price, publish, intro | from | book | where | id = ?”。
(3)分库分表路由。根据ShardingRule中指定的分库分表列的参数值,以及分库分表策略,实行分库分表,得到一个RoutingResult 。RoutingResult 中包含一个真实数据源,以及逻辑表名和实际表名。
(4)sql改写。在SqlBuilder中,查找sql中解析的segment,将和逻辑表名一致的segment替换成实际表名。(segment中可以标注该地方是不是表名)
以上代码执行结果如下:
Parsed SQL result: SQLParsedResult(routeContext=RouteContext(tables=[Table(name=book, alias=Optional.absent())], sqlStatementType=null, sqlBuilder=null), generatedKeyContext=GeneratedKeyContext(columns=[], columnNameToIndexMap={}, valueTable={}, rowIndex=0, columnIndex=0, autoGeneratedKeys=0, columnIndexes=null, columnNames=null), conditionContexts=[ConditionContext(conditions={})], mergeContext=MergeContext(orderByColumns=[], groupByColumns=[], aggregationColumns=[], limit=null))
Parsed SQL: SELECT id, name, price, publish, intro FROM [Token(book)] WHERE id = ?
dataSource1 SELECT id, name, price, publish, intro FROM book_00 WHERE id = ? [2000]
dataSource2 SELECT id, name, price, publish, intro FROM book_02 WHERE id = ? [2000]
dataSource1 SELECT id, name, price, publish, intro FROM book_02 WHERE id = ? [2000]
dataSource2 SELECT id, name, price, publish, intro FROM book_01 WHERE id = ? [2000]
dataSource0 SELECT id, name, price, publish, intro FROM book_00 WHERE id = ? [2000]
dataSource0 SELECT id, name, price, publish, intro FROM book_01 WHERE id = ? [2000]
dataSource2 SELECT id, name, price, publish, intro FROM book_00 WHERE id = ? [2000]
dataSource1 SELECT id, name, price, publish, intro FROM book_01 WHERE id = ? [2000]
dataSource0 SELECT id, name, price, publish, intro FROM book_02 WHERE id = ? [2000]
实际上,我们可以用更通俗易懂的代码表示sql改写的这个过程:
String logicSql = "select id, name, price, publish, intro from book where id = 111";
MySqlStatementParser parser = new MySqlStatementParser(logicSql);
SQLStatement statement = parser.parseStatement();
MySQLSimpleVisitor visitor = new MySQLSimpleVisitor();
statement.accept(visitor);
String logicTable = "book";
String realTable = "book_00";
String token = "\\$\\{" + logicTable + "\\}";
String sqlBuilder = visitor.getAppender().toString();
String sql = sqlBuilder.replaceAll(token, realTable);
System.out.println(sqlBuilder);
System.out.println(sql);
MySQLSimpleVisitor代码如下:
public class MySQLSimpleVisitor extends MySqlOutputVisitor {
public MySQLSimpleVisitor() {
super(new StringBuilder());
}
@Override
public boolean visit(SQLExprTableSource x) {
StringBuilder sb = new StringBuilder();
sb.append("${");
sb.append(x.getExpr().toString()).append('}');
print(sb.toString());
if (x.getAlias() != null) {
print(' ');
print(x.getAlias());
}
for (int i = 0; i < x.getHintsSize(); ++i) {
print(' ');
x.getHints().get(i).accept(this);
}
return false;
}
}
结果如下:
SELECT id, name, price, publish, intro
FROM ${book}
WHERE id = 111
SELECT id, name, price, publish, intro
FROM book_00
WHERE id = 111
(3)Sharding-JDBC的分片原理
(4)Sharding-JDBC的相关配置
(二)分库分表
(1)概念介绍
【1】分库分表
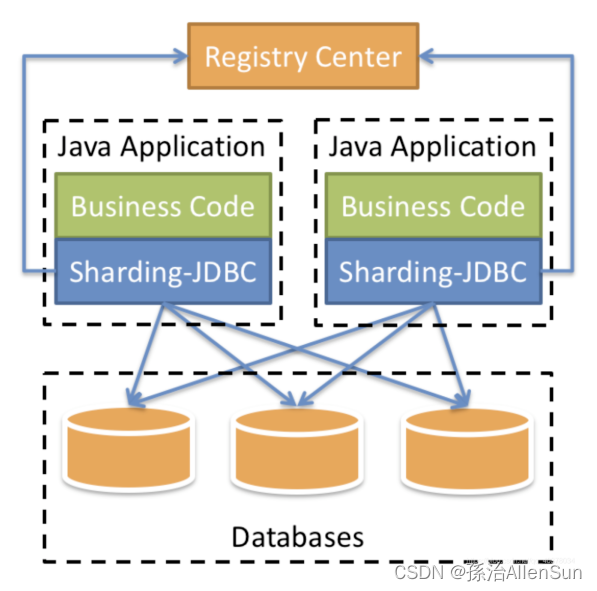
水平拆分:同一个表的数据拆到不同的库不同的表中。可以根据时间、地区或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表
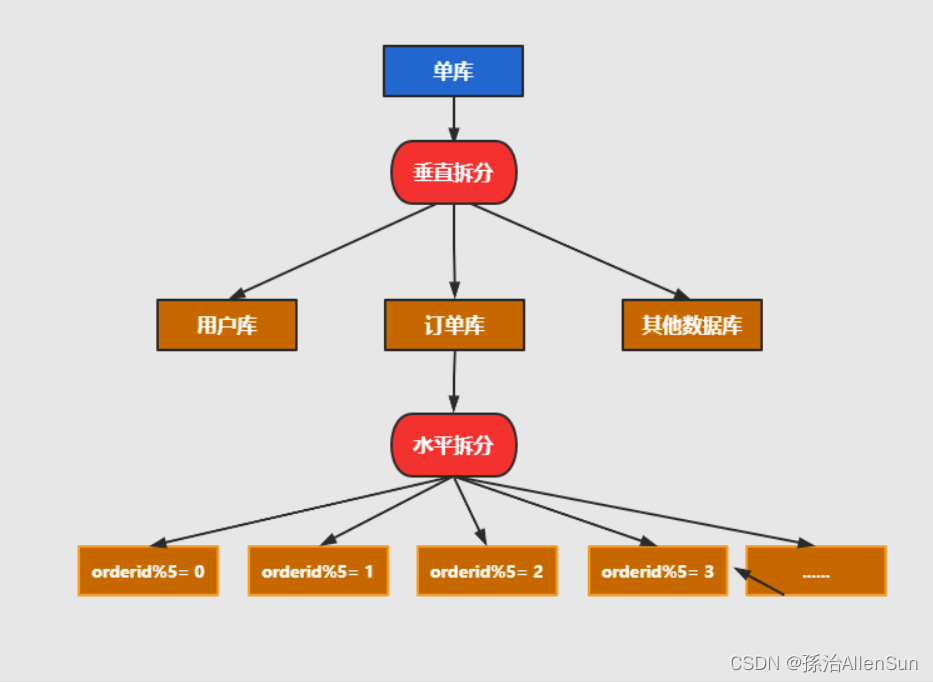
【2】分片
一般在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片将原本一张数据量较大的表例如 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过分库策略、分片策略将数据分散到不同的数据库、表内。
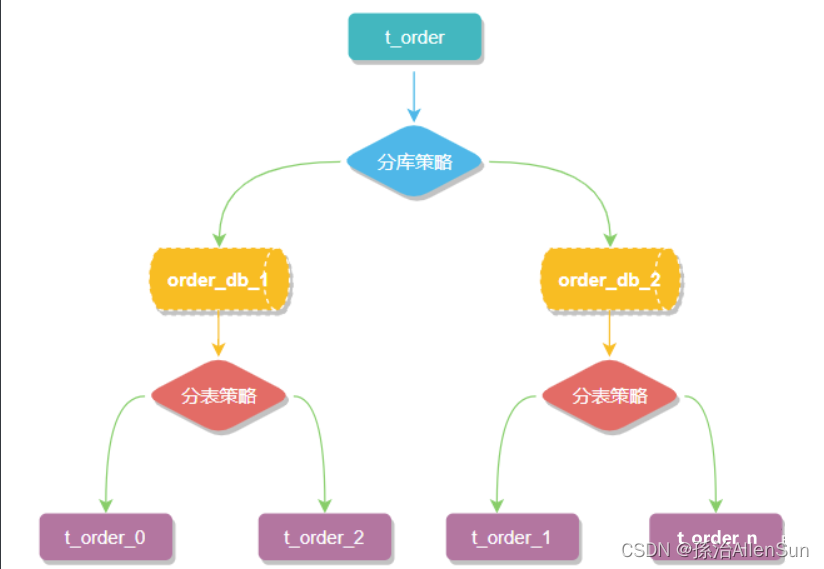
【3】数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
【4】逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。
比如将订单表 t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。
此时会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。
【5】真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
【6】分片键
用于分片的数据库字段。将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。
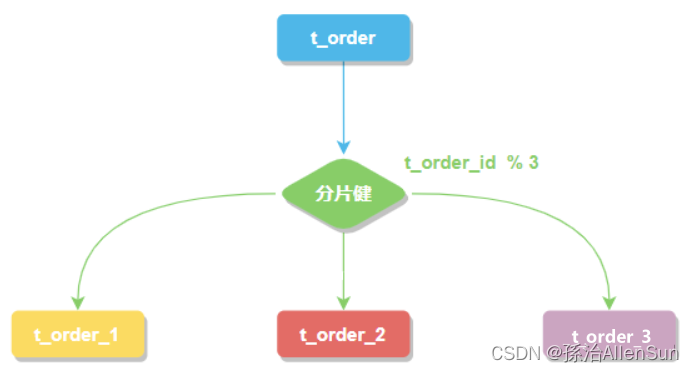
这样以来同一个订单的相关数据就会存在同一个数据库表中,大幅提升数据检索的性能,不仅如此 sharding-jdbc 还支持根据多个字段作为分片健进行分片。
【7】分片算法
上边提到可以用分片健取模的规则分片,但这只是比较简单的一种,在实际开发中还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。
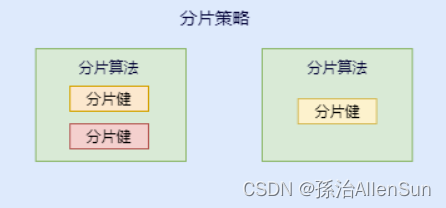
【8】分片算法和分片策略的关系
注意:sharding-jdbc 并没有直接提供分片算法的实现,需要开发者根据业务自行实现。
sharding-jdbc 提供了4种分片算法。
(1)精确分片算法
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
(2)范围分片算法
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
(3)复合分片算法
复合分片算法(ComplexKeysShardingAlgorithm)用于多个字段作为分片键的分片操作,同时获取到多个分片健的值,根据多个字段处理业务逻辑。需要在复合分片策略(ComplexShardingStrategy )下使用。
(4)Hint分片算法
Hint分片算法(HintShardingAlgorithm)稍有不同,上边的算法中都是解析SQL 语句提取分片键,并设置分片策略进行分片。但有些时候并没有使用任何的分片键和分片策略,可还想将 SQL 路由到目标数据库和表,就需要通过手动干预指定SQL的目标数据库和表信息,这也叫强制路由。
【9】分片策略
上边讲分片算法的时候已经说过,分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片键来完成的。
(1)标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN AND, >, <,>=,<= 条件分片,如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。
(2)复合分片策略
复合分片策略,同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
(3)行表达式分片策略
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
(4)Hint分片策略
Hint分片策略,对应上边的Hint分片算法,通过指定分片健而非从 SQL中提取分片健的方式进行分片的策略。
【10】分布式主键
数据分⽚后,不同数据节点⽣成全局唯⼀主键是⾮常棘⼿的问题,同⼀个逻辑表(t_order)内的不同真实表(t_order_n)之间的⾃增键由于⽆法互相感知而产⽣重复主键。
尽管可通过设置⾃增主键 初始值 和 步⻓ 的⽅式避免ID碰撞,但这样会使维护成本加大,乏完整性和可扩展性。如果后去需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
为了让上手更加简单,ApacheShardingSphere 内置了UUID、SNOWFLAKE 两种分布式主键⽣成器,默认使用雪花算法(snowflake)⽣成64bit的⻓整型数据。不仅如此它还抽离出分布式主键⽣成器的接口,方便实现自定义的自增主键生成算法。
【11】广播表
广播表:存在于所有的分片数据源中的表,表结构和表中的数据在每个数据库中均完全一致。一般是为字典表或者配置表 t_config,某个表一旦被配置为广播表,只要修改某个数据库的广播表,所有数据源中广播表的数据都会跟着同步。
【12】绑定表
绑定表:那些分片规则一致的主表和子表。比如:t_order 订单表和 t_order_item 订单服务项目表,都是按 order_id 字段分片,因此两张表互为绑定表关系。
那绑定表存在的意义是啥呢?
通常在业务中都会使用 t_order 和 t_order_item 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
而配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0 和 t_order_item_0 表关联即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
注意:在关联查询时 t_order 它作为整个联合查询的主表。所有相关的路由计算都只使用主表的策略,t_order_item 表的分片相关的计算也会使用 t_order 的条件,所以要保证绑定表之间的分片键要完全相同。
(2)分库分表方案
分库分表方案,不外乎就两种,一种是垂直切分,一种是水平切分。
垂直切分是根据业务来拆分数据库,同一类业务的数据表拆分到一个独立的数据库,另一类的数据表拆分到其他数据库。
【1】垂直切分
有一张Order表,表中有诸多记录,比如设计这么一张简单的表。
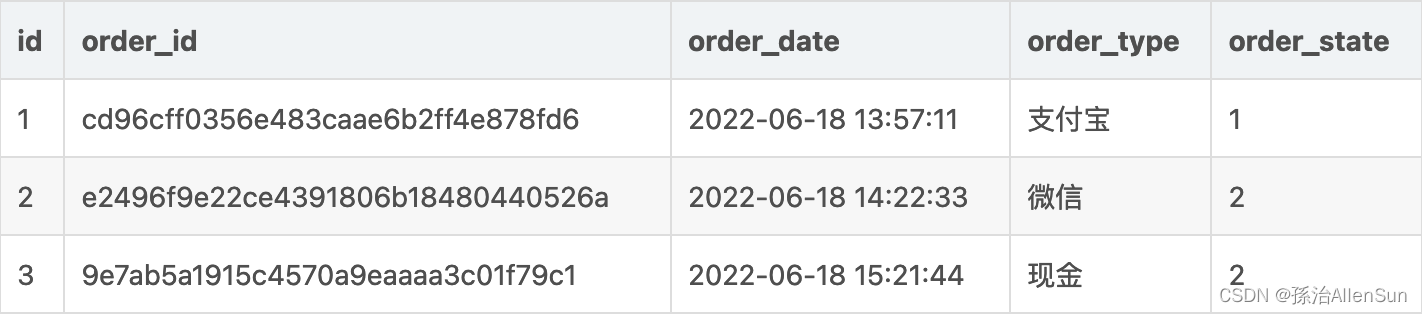 以上是简化版Order表,如果想要垂直切分,那么应该怎么处理?
以上是简化版Order表,如果想要垂直切分,那么应该怎么处理?
直接拆分成2个表,这时候就直接就一分为2 ,咔的一下拆分成两个表
Order1
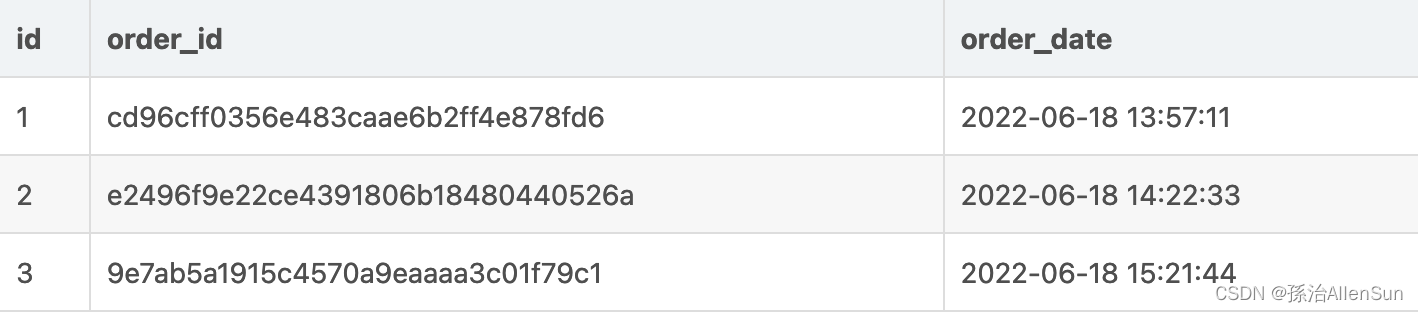 Order2
Order2

【2】水平切分
水平拆分数据库:将一张表的数据 ( 按照数据行) 分到多个不同的数据库。每个库的表结构相同,每个库都只有这张表的部分数据,当单表的数据量过大,如果继续使用水平分库,那么数据库的实例 就会不断增加,不利于系统的运维。这时候就要采用水平分表。
水平拆分表:将一张表的数据 ( 按照数据行) ,分配到同一个数据库的多张表中,每个表都只有一部分数据。
Order1

Order2

【3】分库分表带来的问题
(1)事务问题
首先,分库分表最大的隐患就是,事务的一致性, 当需要更新的内容同时分布在不同的库时,不可避免的会产生跨库的事务问题。
原来在一个数据库操 作,本地事务就可以进行控制,分库之后 一个请求可能要访问多个数据库,如何保证事务的一致性,目前还没有简单的解决方案。
(2)无法联表的问题
还有一个就是,没有办法进行联表查询了,因为,原来在一个库中的一些表,被分散到多个库,并且这些数据库可能还不在一台服务器,无法关联查询,所以相对应的业务代码可能就比较多了。
(3)分页问题
分库并行查询时,如果用到了分页,每个库返回的结果集本身是无序的,只有将多个库中的数据先查出来,然后再根据排序字段在内存中进行排序,如果查询结果过大也是十分消耗资源的。
(4)分库分表的技术
目前比较流行的就两种,一种是MyCat,另外一种则是Sharding-Jdbc,都是可以进行分库的,
MyCat是一个数据库中间件,Sharding-Jdbc是以 jar 包提供服务的jdbc框架。
Mycat和Sharding-jdbc 实现原理也是不同:
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分库分表分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
而Sharding-JDBC的原理是接受到一条SQL语句时,会陆续执行SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并 ,最终返回执行结果。
(3)Sharding-Jdbc分库分表实现原理
(4)Sharding-Jdbc分库分表案例
(1)分表案例
创建数据库及其对应的相同的两张表结构的表,先在MySQL上创建数据库,直接起名叫做order。然后分别创建两个表,分别是order_1和order_2。
这两张表是订单表拆分后的表,通过Sharding-Jdbc向订单表插入数据,按照一定的分片规则,主键为偶数的落入order_1表 ,为奇数的落入order_2表,再通过Sharding-Jdbc 进行查询。
添加依赖
配置文件
# 读写分离
server:
servlet:
encoding:
enabled: true
charset: UTF-8
force: true
spring:
application:
name: sharding-jdbc-simple
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: db1
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/order?characterEncoding=UTF-8&useSSL=false
username: root
password: root
sharding:
tables:
order:
actual-data-nodes: db1.order_$->{1..2}
key-generator:
column: order_id
type: SNOWFLAKE
# 分表策略
table-strategy:
inline:
sharding-column: order_id
algorithm-expression: order_$->{order_id % 2 + 1}
props:
sql:
show: true
mybatis:
configuration:
map-underscore-to-camel-case: true
偶数订单在表1中,奇数订单在表2中。
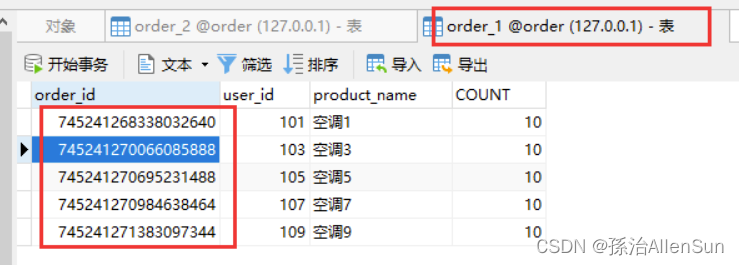
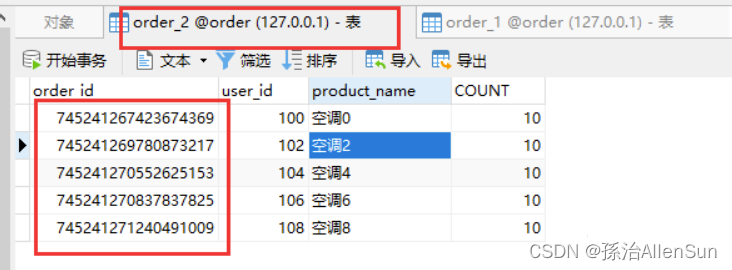
接下来就是直接执行查询,然后去查询对应表中的数据。给定1表和2表中的一个order_id 来进行 In 查询,看是否能正确返回想要的数据:

(2)分库案例
把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上,在上面装好数据库之后,就可以开始进行操作了。
建立数据库 order1 和 order2,然后创建相同表结构的表。
分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据源,否则操作db2。这样的分库策略,直接通过 user_id 的奇偶性,来判断到底是用哪个数据源,用哪个数据库和表数据的。
# 读写分离
server:
servlet:
encoding:
enabled: true
charset: UTF-8
force: true
spring:
application:
name: sharding-jdbc-simple
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: db1,db2
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/order1?characterEncoding=UTF-8&useSSL=false
username: root
password: root
db2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/order2?characterEncoding=UTF-8&useSSL=false
username: root
password: root
## 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据源,否则操作db2。
sharding:
tables:
order_info:
actual-data-nodes: db$->{1..2}.order_info
key-generator:
column: order_id
type: SNOWFLAKE
# 分库策略
database-strategy:
inline:
sharding-column: user_id
algorithm-expression: db$->{user_id % 2 + 1}
props:
sql:
show: true
mybatis:
configuration:
map-underscore-to-camel-case: true
(三)读写分离
(4)Sharding-Jdbc读写分离案例
加了些配置信息,SHARDINGSPHERE 会帮你自动切库,当你做增删改时,会直接操作主库,当你做查询操作时,会直接查询从库,这里数据库压力就可以平摊出来了而我们一般的系统都是增删改少,查询多,就可以多设置几个从库。
spring:
shardingsphere:
props:
sql:
show: true
datasource:
names: master,slave #对应下面主从库
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.1.12:3306/www?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.1.8:3306/www?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
masterslave:
load-balance-algorithm-type: round_robin #负载 轮询,当你有多个从库或者主库时
name: ms
master-data-source-name: master #设置主库
slave-data-source-names: slave #设置从库


![[附源码]Python计算机毕业设计Django校园二手交易平台](https://img-blog.csdnimg.cn/8a38b79a04c645d8bbdab7c0bdb3c2bf.png)