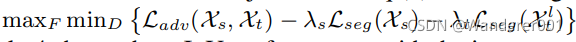题目描述:
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如:
‘a’ 对应 “.-” ,
‘b’ 对应 “-…” ,
‘c’ 对应 “-.-.” ,以此类推。
为了方便,所有 26 个英文字母的摩尔斯密码表如下:

给你一个字符串数组 words ,每个单词可以写成每个字母对应摩尔斯密码的组合。
例如,“cab” 可以写成 “-.-…–…” ,(即 “-.-.” + “.-” + “-…” 字符串的结合)。我们将这样一个连接过程称作 单词翻译 。
对 words 中所有单词进行单词翻译,返回不同 单词翻译 的数量。

解题思路:
我们先将明确问题将问题分解成如下待求解部分:
1.如何翻译一个单词的摩尔斯码;
2.如何对翻译后的个数进行统计;
针对问题1:
由于题目已经将26个字母的摩尔斯电码值以数组的形式给出来了,所以我们想到利用字母与小写字母a的ASCII码值之差转换为对应26个字母顺序电码索引的小技巧将其映射关系转化为一个散列表。
针对问题2:
我们最先想到的就是自己定义一个‘计数器’变量,然后“翻译”一个统计一个,但是我们通过示例1就可以看出,其实单词是有重复的,我们要统计的是不重复的单词个数如果我们像那样操作就避免不了又要进行一个去重操作!但是我们提到去重我们是可以联想到java语言Set集合中的HashSet集合的特性,帮助我们完成对重复单词的统计。操作如下:
定义一个HashSet集合,每当“翻译”完一个单词时就将其添加到HashSet集合中(若添加不成功即说明有重复。这样我们就变向的完成了去重操作),最后返回集合的长度。
代码:
class Solution {
//HashSet
//Time Complexity: O(N^2)
//Space Complexity: O(M) M为不重复单词个数
public int uniqueMorseRepresentations(String[] words) {
String[] morse = {".-","-...","-.-.","-..",".","..-.",
"--.","....","..",".---","-.-",".-..","--","-.","---",
".--.","--.-",".-.","...","-","..-","...-",".--","-..-",
"-.--","--.."};
Set<String> count = new HashSet<>();
for (String word : words) {
StringBuilder code = new StringBulider();
for (int i = 0; i < word.length(); i++) {
char letter = word.charAt(i);
code.append(morse[letter - 'a']);
}
count.add(code.toString());
}
return count.size();
}
}
总结:
通过本题目我们不难发现,如果我们要对一些存在重复元素进行统计时,我们可以尝试着利用HashSet去变向实现该操作(Java 语言)!!!

![[附源码]Python计算机毕业设计Django校园二手交易平台](https://img-blog.csdnimg.cn/8a38b79a04c645d8bbdab7c0bdb3c2bf.png)