vMAP: Vectorised Object Mapping for Neural Field SLAM

vMAP 是一个物体级稠密图 neural SLAM,每一个物体都用一个 mlp 来表征,而不需要 3D 先验。当 RGB-D 相机在没有任何先验信息的情况下时,vMAP 会即时检测物体 instance,并将其动态地添加到地图中。
基于 vectorised training,vMAP 可以优化单个场景中多达 50 个单独的物体,并以 5Hz 的地图更新速度进行高效训练。
一、简介
物体级的模型通常是最好的,但关键在于,要对场景中的对象进行分割、分类以及重建,需要了解多大程度的先验信息。如果没有先验,通常只能重建出来观察到的物体部分,还有像 CAD 和 类别级形状空间模型虽然能获取物体先验,但是仅限于有对应物体的模型存在。
这个工作证明了在实时运行过程中,通过矢量化训练,大量独立的 MLP 物体模型可以在单个 GPU 上同时进行高效优化。
与在整个场景的单一神经场模型中使用类似数量的权重相比,通过对物体进行单独建模,我们可以实现更准确、更完整的场景重建。通过多个独立的物体级网络,能重建出最多 50 个物体的场景,每个物体只需 40KB 的学习参数。
二、相关
Neural Field SLAM
iMAP 首次借助 RGB-D 传感器的深度测量数据逐步训练的简单 MLP 网络可以实时表示房间大小的三维场景。iMAP 经常能重建未观察到的物体背面。当添加语义信息(如 SemanticNeRF 和 iLabel)时,神经场的这些连贯性特性就会特别显现出来。为了使隐式表征更具可扩展性和效率,有些工作常与传统的体积表征相融合。
Object Representations with Neural Fields
然而,从 Neural Field 中获取单个物体表征非常困难,因为网络参数与特定区域之间的对应关系难以确定。为了解决这个问题,DeRF 对场景进行了空间分解,并为每个分解部分专门设计了更小的网络。KiloNeRF 将场景分解为数千个体素,每个部分由一个微小的 MLP 表示,并使用定制的 CUDA 内核对其进行并行训练,以加快 NeRF 的速度。与 KiloNeRF 不同,vMAP 将场景分解为具有语义意义的对象。
为了表示多个物体,ObjectNeRF 和 ObjSDF 将预先计算的实例掩码作为额外输入,并将可学习的物体激活码作为物体表征的条件。但这些方法仍然是 offline 的,并将物体表征与主场景网络结合在一起优化网络权重。vMAP 对物体进行单独建模,能够停止和恢复对任何物体的训练,而不会受到物体间的干扰。
以 CodeNeRF 为基础,本文展示了可在实时系统中同时训练构成整个场景的多个独立神经场模型,从而准确、高效地呈现多物体场景。
三、方法
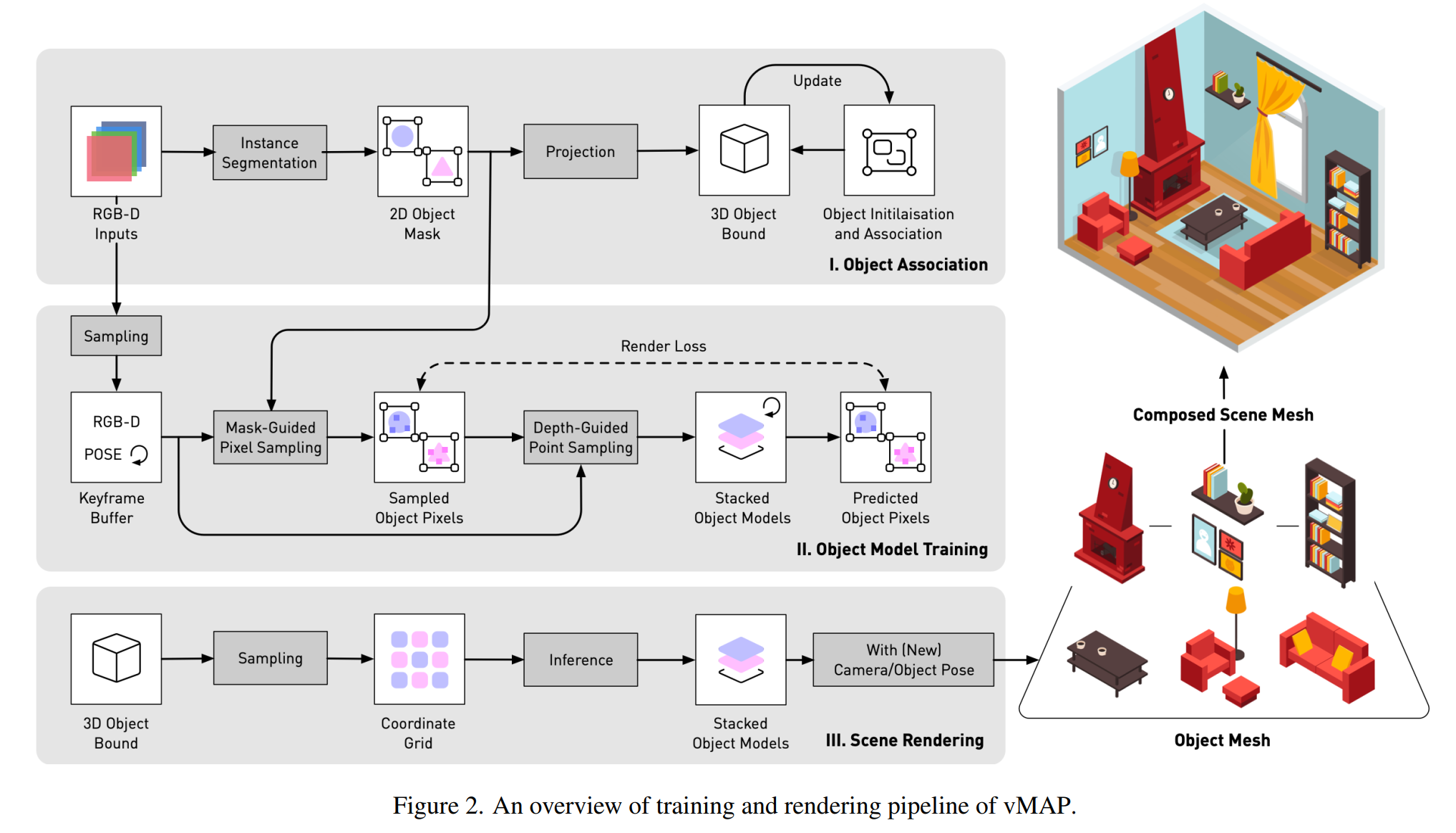
3.1 Vectorised Object Level Mapping
Object Initialisation and Association
首先,每帧图像都与标注的对象掩码相关联,这些对象掩码要么是数据集提供的,要么是通过现成的 2D 实例分割网络预测的。由于这些预测的对象掩码在不同帧之间没有时间上的一致性,因此我们根据两个标准在前一帧和当前实时帧之间进行对象关联:
- 语义一致性:当前帧中的对象被预测为与前一帧中的对象属于同一语义类别;
- 空间一致性:当前帧中的对象与前一帧中的对象在空间上接近,以它们的平均 IoU 来衡量。
如果满足这两个标准,我们就认为它们是同一个物体实例,并用相同的模型来表示它们。否则初始化一个新的模型并加入到栈中。
对于帧中的每个物体,通过其 3D 点云估计其边界,并以其深度图和相机位姿为参数。相机跟踪由 ORB-SLAM3 提供。如果在新帧中检测到相同的物体实例,就会将之前帧中的 3D 点云合并到当前帧中,并重新估计边界。因此,这些物体边界会随着更多的观察结果动态更新。
Object Supervision
为了最大限度地提高训练效率,只对 2D 物体 bbox 内的像素进行物体级监督。对于物体 mask 内的像素,我们鼓励使用辐射场,并通过深度和颜色损失对其进行监督。否则,我们会鼓励辐射场为空。
每个物体实例都从自己独立的关键帧缓冲区中采样像素。因此可以灵活地停止或恢复任何物体的训练,物体之间不会产生干扰。
Vectorised Training
KiloNeRF 用多个小型网络来表示神经场,可以提高训练效率。在 vMAP 中同样采用这种思路,用一个稍大的网络来表示物体,这样就可以将这些小物体模型堆叠在一起,再利用 functorch 中高度优化的矢量化操作进行矢量化训练。由于多个对象模型是 batch 后同时训练的,而不是按顺序训练,因此优化了 GPU 资源的使用。
3.2 Neural Implicit Mapping
Depth Guided Sampling
仅根据 RGB 数据训练的神经场无法保证建立精确的物体几何模型,vMAP 利用 RGB-D 传感器提供的深度图,来为学习密度场提供先验。具体来说,沿每条射线采样 Ns 和 Nc 个点,其中 Ns 个点以物体表面 ts(来自深度图)为中心的正态分布采样,方差为 dσ = 3cm,Ns越多物体越准确;Nc 个点在相机 tn(临近边界)和物体表面 ts 之间均匀采样,采用分层抽样方法。当深度测量无效时,物体表面 ts 将被远边界 tf 取代:
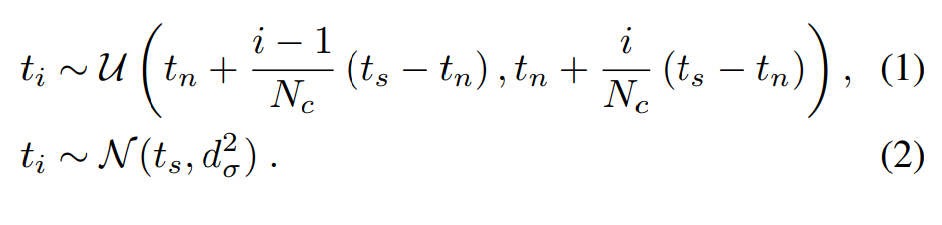
Surface and Volume Rendering
由于我们更关注 3D 表面重建而非 2D 渲染,因此我们在网络输入中省略了相机方向,并用二进制指标(无透明物体)来模拟物体可见度。与 UniSURF 相似,将 3D 点 xi 的占用概率参数化为 oθ (xi) ->[0, 1],θ是网络参数。因此,沿射线 r 中 xi 点的终止概率为 Ti = o (xi) ∏(1 − o (xj)),j<i ,表示在 xi 之前不存在 j < i 的占用样本 xj。相应的渲染占用率、深度和颜色定义如下:
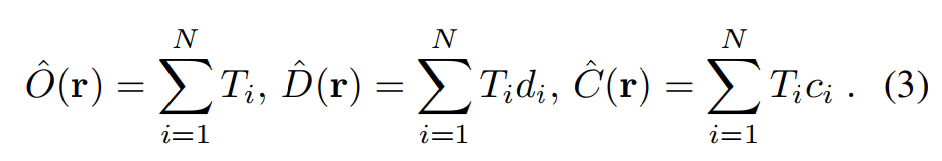
Training Objective
对于每个物体 k,只对该物体 bbox(用 Rk 表示)内的训练像素进行采样,并只对其 2D 对象 mask(用 Mk 表示)内的像素进行深度和颜色优化,Mk ⊂ Rk。对象 k 的深度、颜色和占用率损失定义如下:
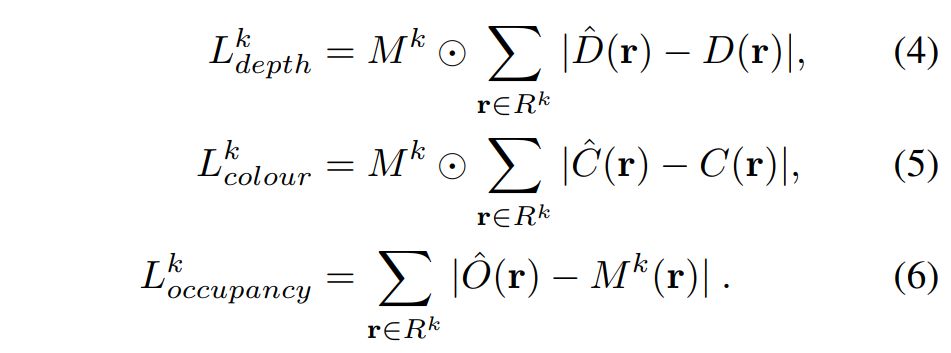
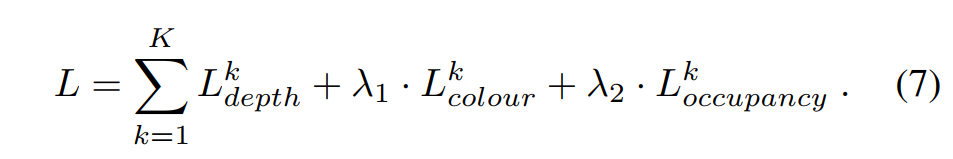
其中 λ1 = 5 、 λ2 = 10。
3.3 Compositional Scene Rendering
由于 vMAP 在一个完全分离的表示空间中表示物体,因此我们可以通过在其估计的 3D 物体边界内查询每个物体。在 2D 视图合成方面,使用 RayBox Intersection 算法计算每个物体的近边界和远边界,然后沿每条光线按照渲染深度排序,实现感知遮挡的场景级渲染。
四、实验
数据集的质量决定了系统的上限。
实例分割选择 Detic,位姿估计部分选择 ORB-SLAM3。
metrics:Accuracy, Completion, Completion Ratio ,这种场景级指标严重偏向于重建墙壁和地板等大型物体。因此,我们通过平均每个场景中所有物体的度量值,额外提供了这些物体级度量值。
矢量化训练极大地提高了优化速度,尤其是当我们训练大量对象时。 有了矢量化训练,即使我们训练多达 200 个对象,每个优化步骤也不会超过 15 毫秒。

为了并行训练多个模型,我们最初尝试的方法是为每个对象启动一个进程。然而,由于每个进程的 CUDA 内存开销,我们只能生成非常有限数量的进程,这大大限制了对象的数量。
物体级表征是高度可压缩的,只需很少的参数就能高效、准确地进行参数化。
除了用单个 MLP 表示每个对象外,我们还将多对象映射视为多任务学习问题,探索了共享 MLP 设计[27, 34]。在这里,每个物体都与一个可学习的潜在代码相关联,这个潜在代码被视为网络的条件输入,并与网络权重共同优化。虽然我们尝试过多种多任务学习架构 [13, 19],但早期实验(图 9 中表示为 vMAP-S)表明,这种共享 MLP 设计的重建质量略有下降,而且与堆叠式 MLP 相比,训练速度没有明显提高。
作者还尝试了 shared MLP,即将多物体mapping视为多任务学习问题,但可能会导致不理想的训练特性:
i) 网络权重和所有对象编码在共享表示空间中纠缠在一起,一起进行优化;
ii) 在训练过程中,共享 MLP 的容量是固定的,因此随着对象数量的增加,表示空间可能不够用。
五、结论
我们目前的系统依赖于现成的实例掩码检测器,而这种检测器并不一定在时空上保持一致。虽然数据关联和多视角监督可以部分缓解这种模糊性,但合理的全局约束会更好。由于物体是独立建模的,因此可以对动态物体进行持续跟踪和重构,以完成下游任务,如机器人操纵。为了将我们的系统扩展到单目稠密图,可以进一步整合深度估计网络或更高效的神经渲染方法。
通过对分离的预训练特征字段进行调节来改变对象的形状或纹理。
参考:
[1] UniSURF: https://arxiv.org/pdf/2104.10078.pdf
[2] https://github.com/kxhit/vMAP
[3] vMAP: https://arxiv.org/pdf/2302.01838.pdf