FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence, NIPS, 2020
要点:
1、首先,基于 “弱增强的未标记样本的模型预测” 生成伪标签;接着,对于给定的样本,只有模型预测的置信度高时,伪标签才会被再训练;最后,通过输入同一样本的强增强版本进行伪标签预测的训练;
2、SSL方法:为未标记图像生成一个人工标签,并将未标记图像作为输入训练模型来预测人工标签;
(1)伪标签:即self-training,使用模型生成的类预测作为人工标签;
(2)一致性正则化:随机修改输入或模型的函数后,利用模型的预测分布获得一个人工标签;
主流方法:两个方向上加上日益复杂的机制
3、本文的方法:一致性正则化+伪标记
(1)人工标签基于弱增强的未标记样本产生,并进一步作为将同一样本的强增强版本做输入时的 target;
(2)弱增强:翻转、移位
(3)强增强:Cutout、CTAugment、RandAugment,产生给定图像的严重扭曲版本
(4)伪标记:仅当模型预测出某个高置信度的类别时才保留人工标签
主要创新点:一致性正则化和伪标记的结合,并且在执行一致性正则化的时候,使用单独的弱增强和强增强
相关工作
一致性正则化:
1、基于“输入同一图像的扰动版本,模型应输出相似的预测”这一假设,利用未标记样本;
2、模型基于以下的损失函数,联合标准的监督分类损失和未标记数据进行训练;
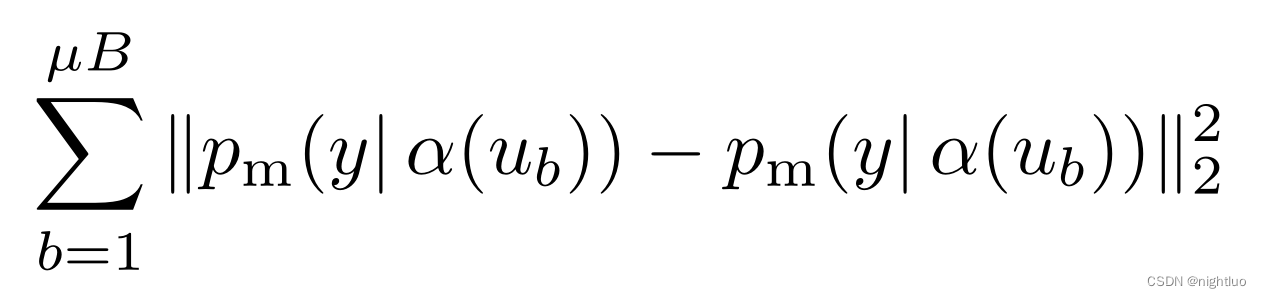
伪标记:
1、基本思想:利用模型本身为未标记数据打上伪标记的人工标签;
2、使用硬标签(the argmax of the model's output)作为伪标记的人工标签;
3、再训练最大类别概率大于预定阈值的人工标签;
图表:
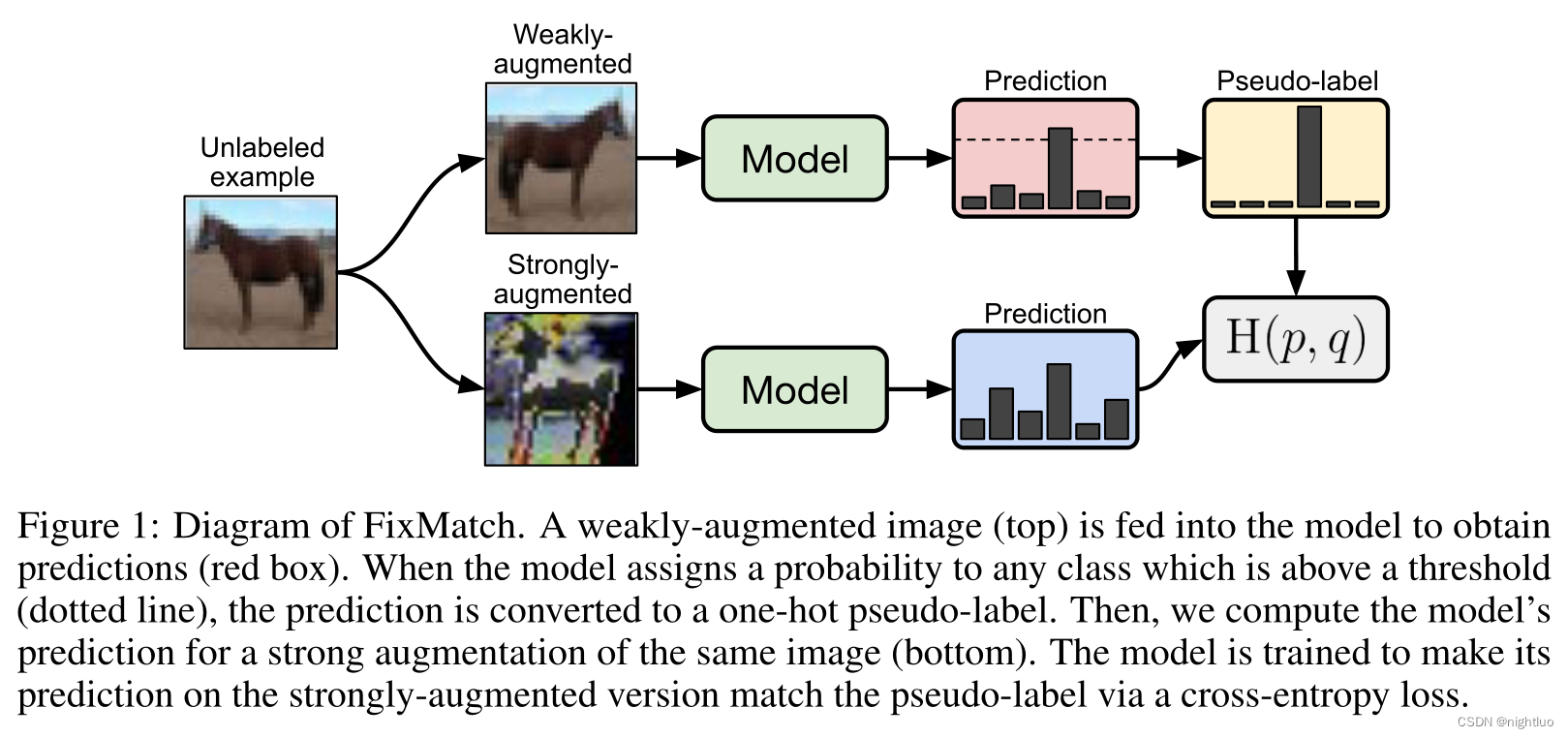
FixMatch的流程图:
1、将弱增强图像输入model获得预测;
2、预测概率高于阈值,预测转化为one-hot的伪标签;
3、将强增强图像输入model获得预测;
4、模型训练目标:强增强版本通过交叉熵损失match伪标签。
代码:
https://github.com/google-research/fixmatch