文章目录
- 查准率 查全率 F1 score
- GridSearchCV
- 概述
- score参数的修改
- classification report
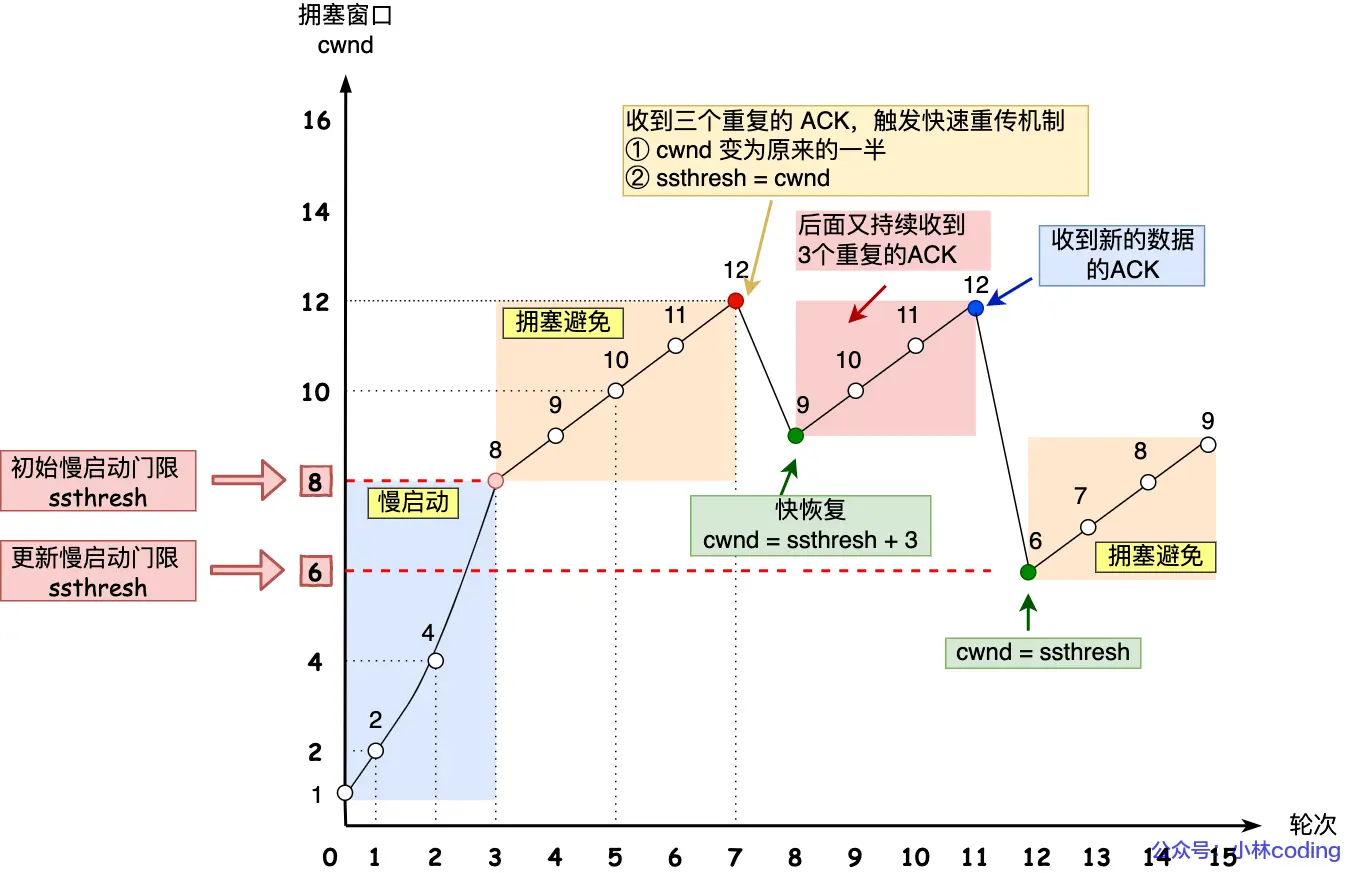
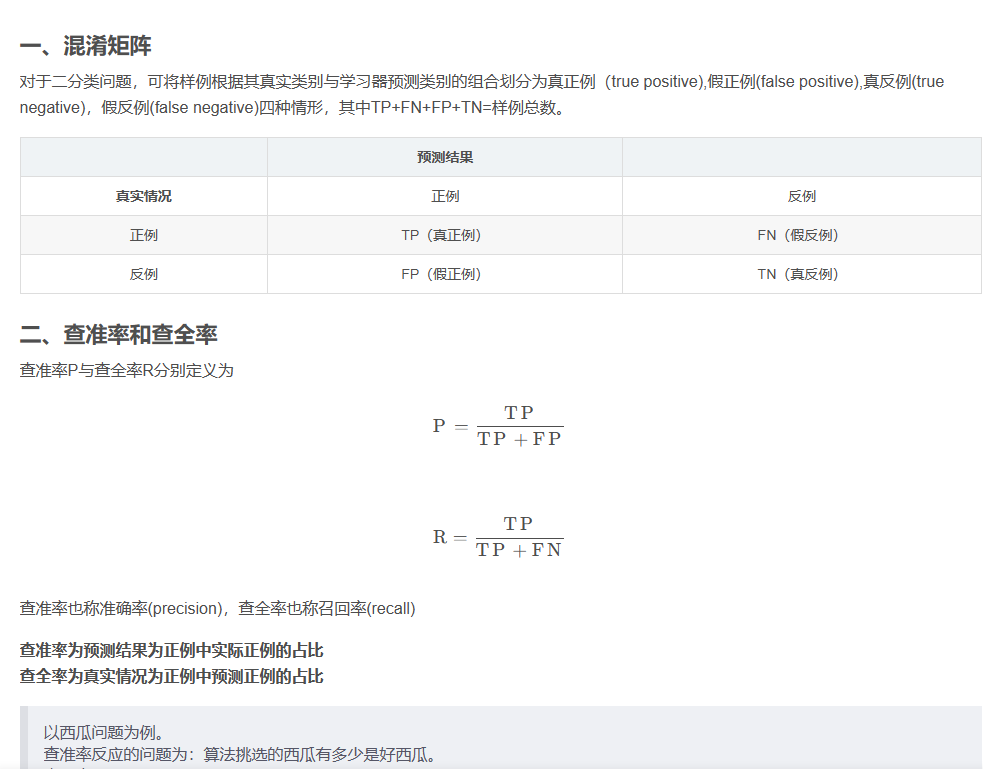
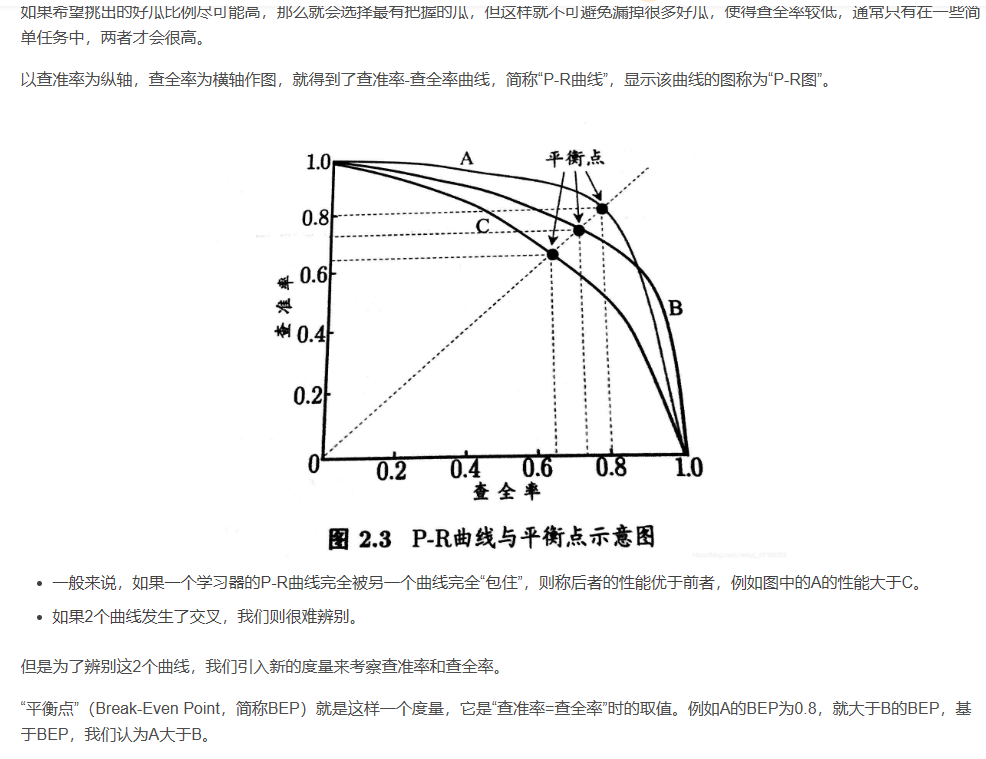
目标: 综合考虑查准率和查全率,来确定最佳模型参数。
查准率 查全率 F1 score
https://blog.csdn.net/qq_47180202/article/details/119780943

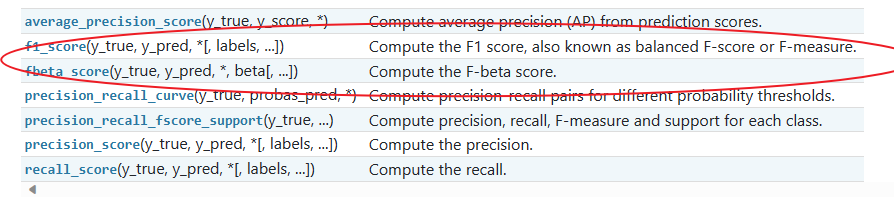
from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
metrics.precision_score(y_true, y_pred)
metrics.recall_score(y_true, y_pred)
metrics.f1_score(y_true, y_pred)
metrics.fbeta_score(y_true, y_pred, beta=0.5)
metrics.fbeta_score(y_true, y_pred, beta=1)
metrics.fbeta_score(y_true, y_pred, beta=2)
metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5)
import numpy as np
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
precision, recall, threshold = precision_recall_curve(y_true, y_scores)
precision
recall
threshold
average_precision_score(y_true, y_scores)
GridSearchCV
概述
https://www.cnblogs.com/dalege/p/14175192.html
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics (官网,建议认真看)
score参数的修改
机器学习 scikit-learn GridSearchCV scoring 参数设置
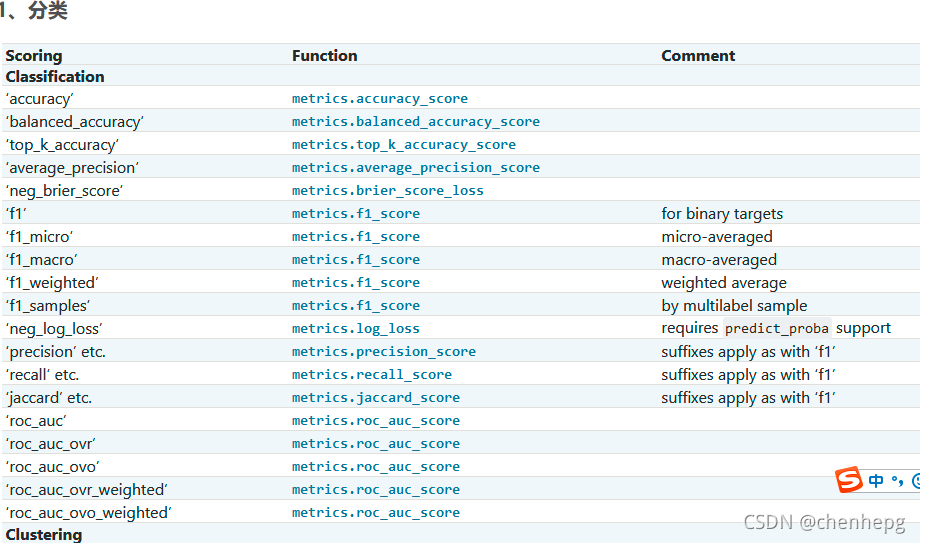
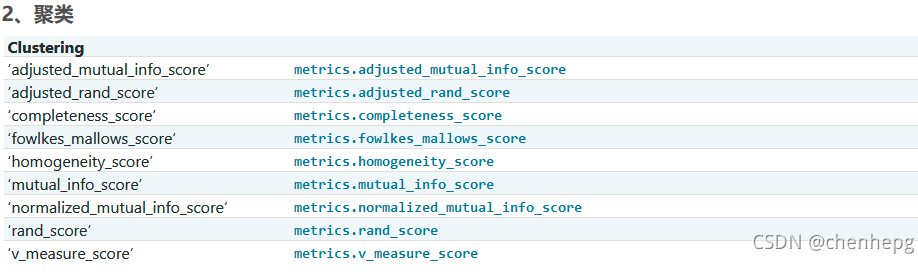
评价函数
###简单使用
- 单一score
from sklearn import svm, datasets
from sklearn.model_selection import cross_val_score
X, y = datasets.load_iris(return_X_y=True)
clf = svm.SVC(random_state=0)
cross_val_score(clf, X, y, cv=5, scoring='recall_macro')
-
多个评价函数
-
自定义评价函数
from sklearn.metrics import fbeta_score, make_scorer
ftwo_scorer = make_scorer(fbeta_score, beta=2)
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVC
grid = GridSearchCV(LinearSVC(dual="auto"), param_grid={'C': [1, 10]},
import numpy as np
def my_custom_loss_func(y_true, y_pred):
diff = np.abs(y_true - y_pred).max()
... return np.log1p(diff)
# score will negate the return value of my_custom_loss_func,
# which will be np.log(2), 0.693, given the values for X
# and y defined below.
score = make_scorer(my_custom_loss_func, greater_is_better=False)
X = [[1], [1]]
y = [0, 1]
from sklearn.dummy import DummyClassifier
clf = DummyClassifier(strategy='most_frequent', random_state=0)
clf = clf.fit(X, y)
my_custom_loss_func(y, clf.predict(X))
score(clf, X, y)
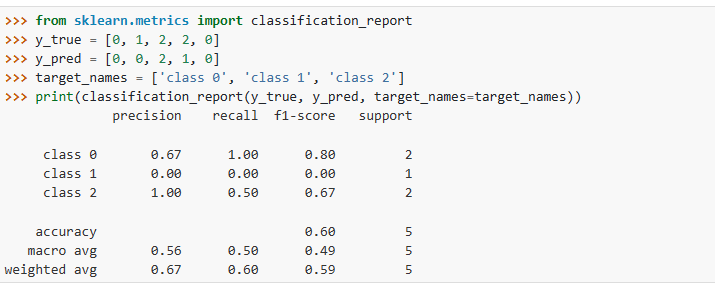
classification report
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 1, 0]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))