代码:https://github.com/fcjian/AeDet
项目地址:https://fcjian.github.io/aedet/
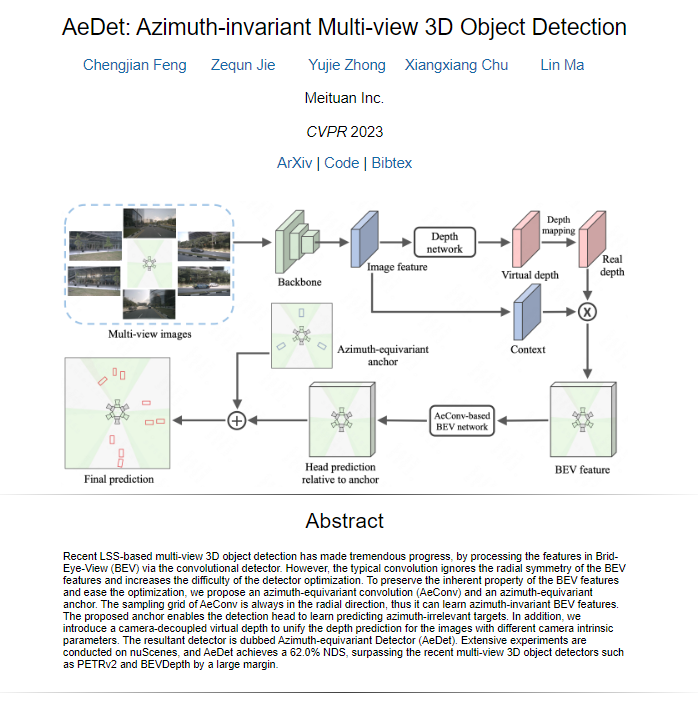
导读&动机
本篇论文探讨了自动驾驶领域中的多视图3D目标检测问题,特别关注了LSS(Lift-Splat-Shoot)方法的发展,该方法通过将图像特征从图像视图转换为鸟瞰图(Bird-Eye-View,BEV)来实现目标检测。然而,传统的卷积方法在BEV特征处理中忽视了BEV特征的径向对称性,导致了检测器的优化难度增加。
本文提出了一种新的Azimuth-equivariant Detector(AeDet),旨在通过建模BEV特征的径向对称性,实现方位不变的BEV感知。AeDet引入了方位等变卷积(Azimuthequivariant Convolution,AeConv)和方位等变锚点(Azimuthequivariant Anchor),用于统一BEV特征的表示和不同方位的目标预测。此外,还引入了一个与相机解耦的虚拟深度,以改善深度预测和深度网络的优化。在nuScenes数据集上进行的广泛实验表明,AeDet在对象方向和速度的准确性上取得了显著提高,并在NDS评估指标上实现了出色的性能,超越了最近的多视图3D目标检测方法。
本文的研究成果为自动驾驶领域的目标检测提供了有力的支持,有望推动自动驾驶技术的进一步发展。
本文贡献
设计了一个方位等变卷积(Azimuth-equivariant Convolution,AeConv)来统一不同方位下的表示学习,并提取了方位不变的BEV特征。
提出了一种新的方位角等变锚点(Azimuth-equivariant Anchor),它可以沿径向重新定义锚点,并统一了不同方位角的预测目标。
引入了虚拟深度的概念,通过将深度预测与相机的内部参数解耦,使深度网络更容易进行优化。
相关工作
单视图3D目标检测:许多工作尝试直接从单视图图像中预测3D边界框。这些方法包括使用估计的深度图来改善图像表示的方法,将2D结构化多边形逆向投影到3D长方体中,以及通过解耦3D目标属性来使FCOS在3D检测中工作等。还有一些方法通过伪LiDAR将图像的深度信息转换为LiDAR伪装来实现3D边界框的预测。
多视图3D目标检测:现代3D目标检测框架通常可以分为基于LSS(Lift-Splat-Shoot)和基于查询的方法。LSS-based方法首先将图像特征从图像视图投影到BEV,然后通过BEV-based检测器处理BEV特征。基于查询的方法则通过将对象查询投影到图像视图并对图像特征进行采样,使用transformer进行3D目标检测。这些方法分别有不同的特点和方法,但都在多视图3D目标检测方面取得了进展。
单视图深度估计:单视图深度估计旨在从单幅图像中预测深度信息。这一领域的工作包括使用有监督学习方法、无监督学习方法以及半监督学习方法等。这些方法通常需要使用与深度信息相关的监督信号来进行训练,例如使用对应的地面真实深度、立体图像对、稀疏深度信息等。
本文方法
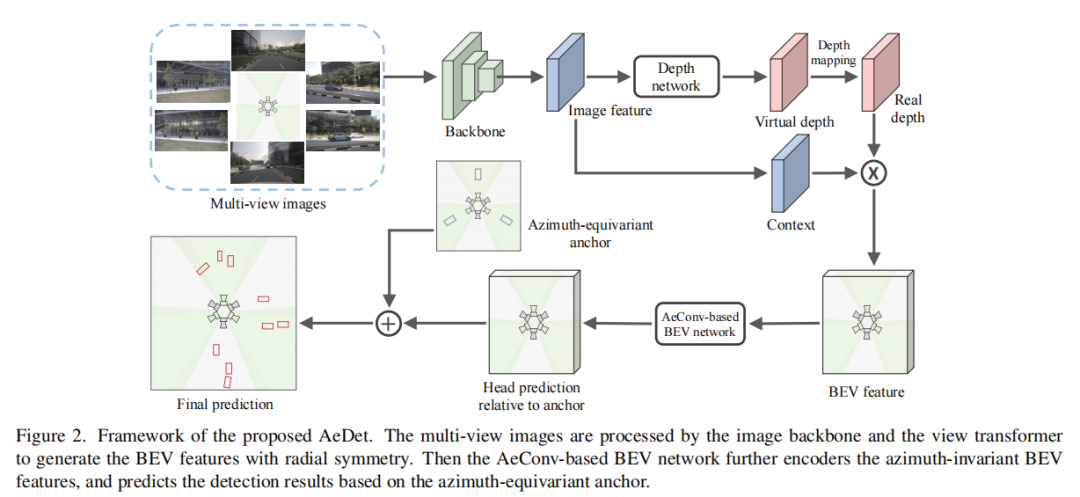
学习方位不变的BEV特征
提出了Azimuth-equivariant Convolution(AeConv),一种方位等变卷积方法,用于提取径向方向上方位不变的BEV表示。
AeConv的核心思想是根据摄像机方位,以摄像机的焦点作为中心点,在每个位置旋转卷积的采样网格,以便在不同方位下学习相同的BEV特征表示。
具体步骤如下:
以摄像机的焦点作为中心点。在这个方位系统中,顺时针方向从BEV开始被定义为方位α,而自我方向则被定义为参考方向,其方位为0。
然后,针对每个位置的方位,使用一个旋转操作,将常规卷积的采样网格R旋转到一个新的采样网格Rrot。这个旋转过程由下式给出:
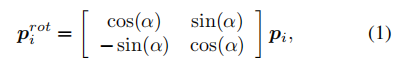
接下来,使用基于新采样网格的卷积操作,将新的特征图y计算为:
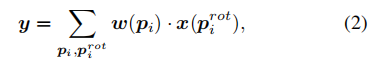
AeConv的旋转采样网格始终位于摄像机的径向方向(如图3a所示),这意味着无论在不同的方位下,AeConv都能够对相同的图像样本学习相同的BEV特征,从而实现方位无关的特征表示。
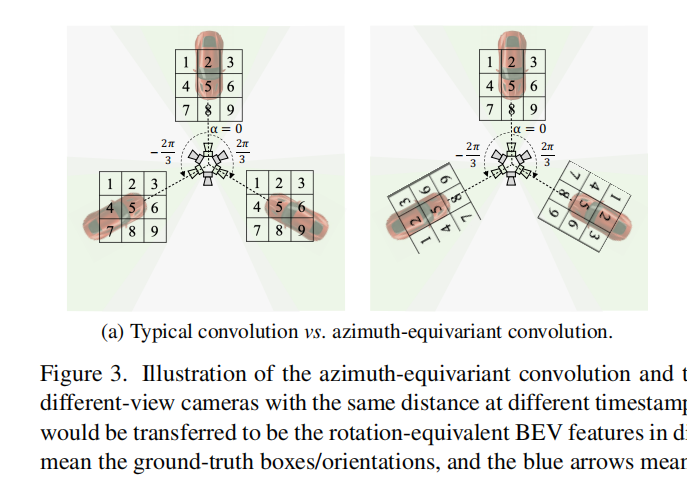
在多摄像头自动驾驶系统中,不同摄像头的位置不同,导致了不均匀的方位系统。为了使多视图的BEV特征具有统一的方位不变性,文章建议使用摄像机的平均中心点作为方位系统的近似中心点。
因此,文章构建了一个基于AeConv的BEV网络,通过将传统的卷积操作替换为提出的AeConv操作,实现了对沿径向方向具有方位不变性的BEV特征的提取。这一改进大大简化了BEV网络的优化过程,使其在多视图环境下更加稳健和高效。
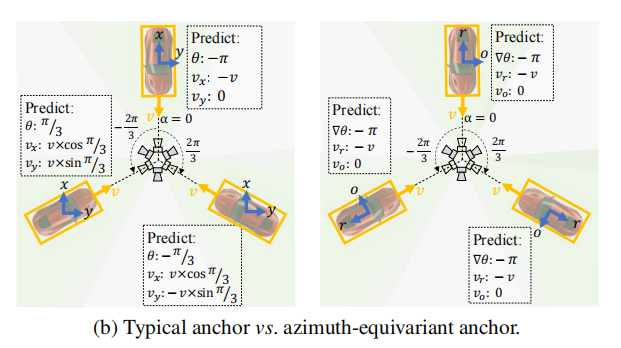
方位等变的锚点:
引入了Azimuth-equivariant Anchor(方位等变锚点),以实现不同方位下的统一目标预测。
与传统方法不同,AeDet的锚点预测相对角度而不是绝对目标方向,并预测相对于方位的角度以及径向和垂直方向的中心偏移和速度。
这种方位等变的锚点设计使得检测头可以在不同方位下进行相同的目标预测,减轻了预测任务的难度。
具体步骤如下:
锚点检测头在每个位置密集地定义锚点:
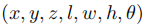
为了简化预测,文章设计了一种方位等变锚点,使检测头能够为相同图像的不同方位预测相同的目标,即不受方位影响。检测头可以预测物体方向相对于方位的相对角度以及沿一致方向的速度/中心偏移。
类似于AeConv,文章根据每个位置的方位定义了一个方位等变锚点:

然后,可以计算方位等变锚点与实际目标框之间的 box 残差(即预测目标)
方向残差是物体方向相对于方位的相对角度:

文章在方位等变锚点中预测了它们沿着锚点方向及其正交方向的值。新的中心偏移(∇r, ∇o)和速度(vr, vo)可以通过以下方式计算:
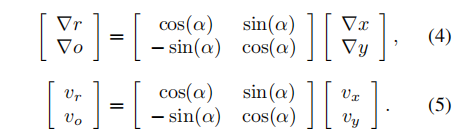
需要注意的是,方位等变锚点的方向始终沿着相机的径向。因此,检测头可以基于方位等变方向来预测物体的方向、中心偏移和速度,生成与方位无关的预测目标,如图3b所示。
相机解耦虚拟深度:
引入了相机解耦虚拟深度的概念,以简化多摄像头图像的深度预测。
通过一个相机解耦的深度网络,预测与摄像机的内部参数无关的虚拟深度。
使用虚拟深度与相机的内部参数之间的关系,将虚拟深度映射到真实深度,以获得准确的深度信息。
具体步骤如下:
虚拟深度预测:首先,文章利用一个解耦相机的深度网络来预测基于虚拟焦距的虚拟深度。这个虚拟深度是独立于相机的内在参数的。为了简化,文章采用了与BEVDepth相同的深度网络结构,但移除了其相机感知的注意模块。虚拟深度的分段尺寸(virtual bin size):

虚拟深度到真实深度的映射:虚拟深度可以根据经典的相机模型映射到真实深度。这意味着虚拟深度可以通过考虑相机的焦距等内在参数,将其转换为真实世界的深度:
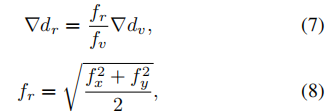
然而,由于不同相机具有不同的焦距,使用上述映射会导致多相机BEV特征在视图变换后具有不同的深度分辨率。为了解决这个问题,我们将变量分段大小映射到一个固定的大小。假设固定深度的分段大小定义为:
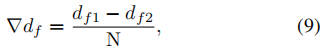
最终的目标是预测这N个固定深度区间的分类分数(sf)。作者通过以下公式将这些分数从虚拟深度分数(sv)转换为真实深度分数:
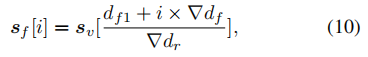
实验
实验结果
与SOTA的比较:
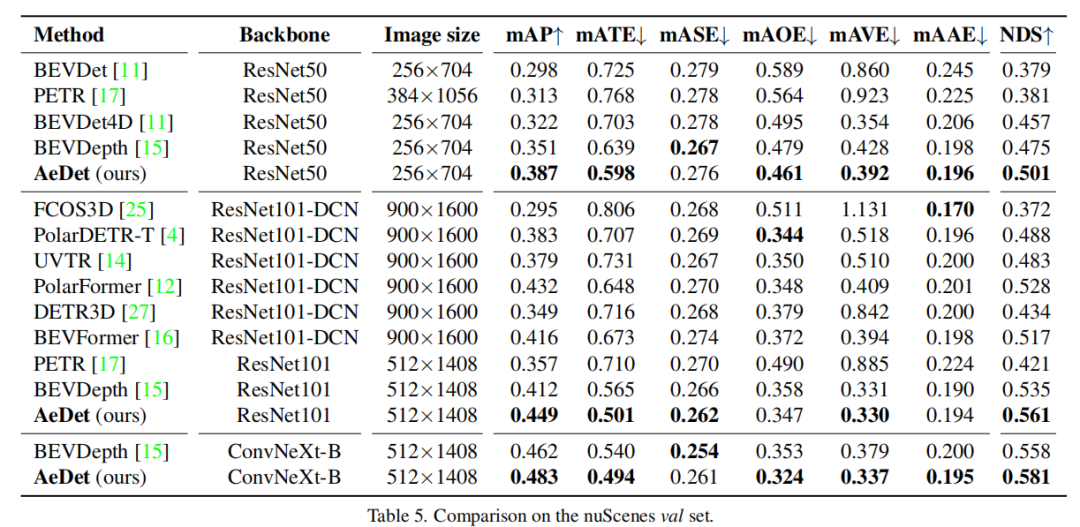
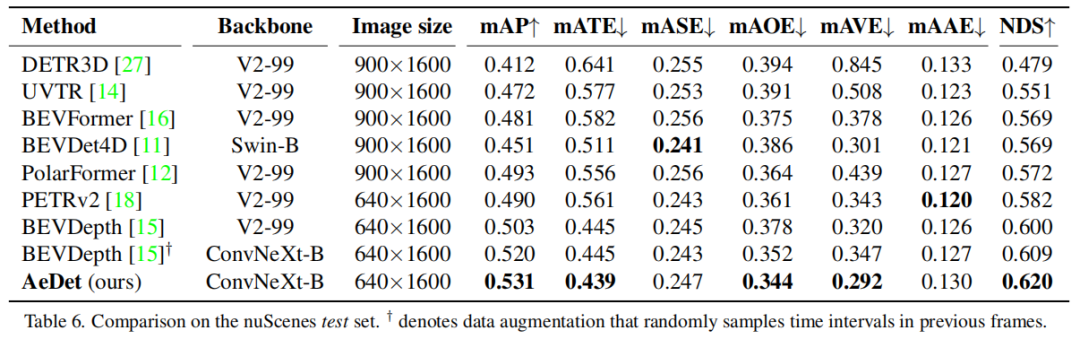
BEVDepth和AeDet在原始视图和旋转视图中的检测结果:

BEVDepth和AeDet在原始视图和旋转视图中的表现:

消融实验
AeDet中各组件的消融研究:
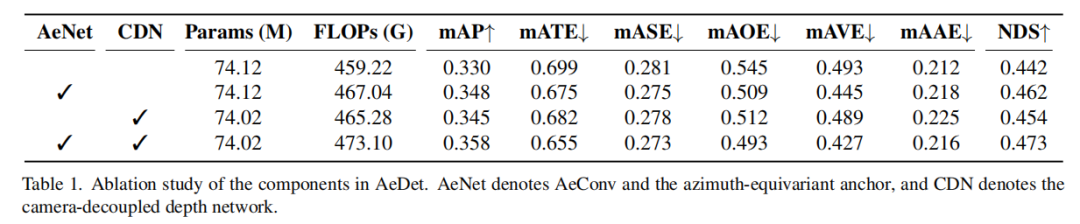
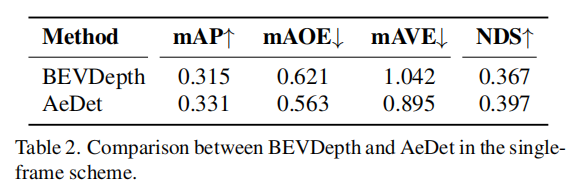
AeDet在单帧(single-frame)方案下的性能评估结果:
结论
提出了一种名为AeDet的检测器,旨在实现方位无关的3D物体检测。AeDet采用了多种创新性的技术,包括Azimuth-equivariant Convolution(AeConv)和azimuth-equivariant anchor,以实现方位不变性,并采用camera-decoupled virtual depth来统一深度预测。
在nuScenes数据集上,AeDet取得了显著的性能提升,达到了62.0%的NDS,超越了现有方法,特别是在物体的方向和速度预测方面取得了卓越的改进。
这项工作强调了AeConv和azimuth-equivariant anchor在提高3D物体检测性能方面的有效性,尤其是在多相机视图下。
总的来说,这篇论文为解决多相机环境下的3D物体检测问题提供了新的思路和方法,取得了令人瞩目的性能提升,为自动驾驶和环境感知领域的研究和应用提供了有价值的见解和工具。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓