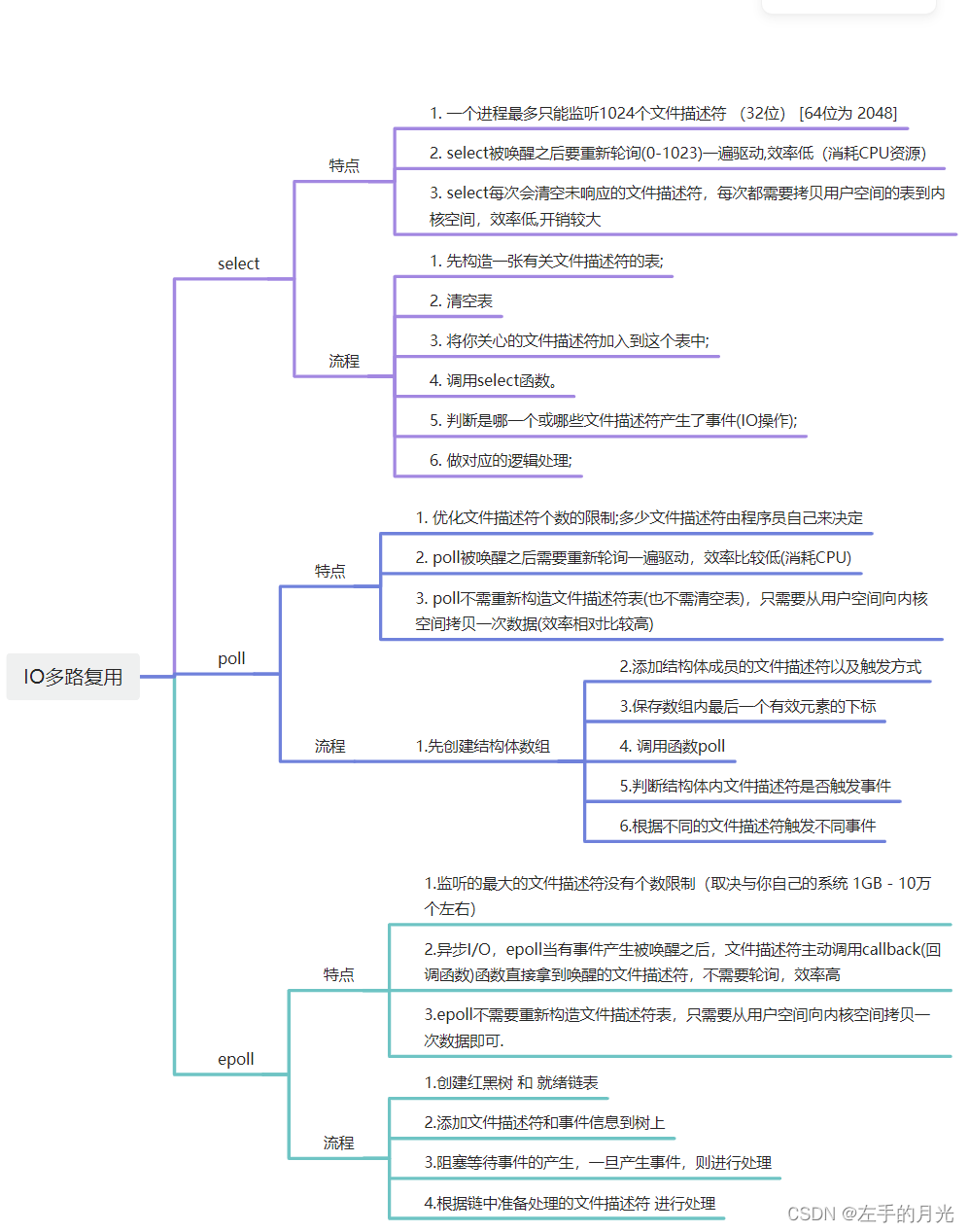
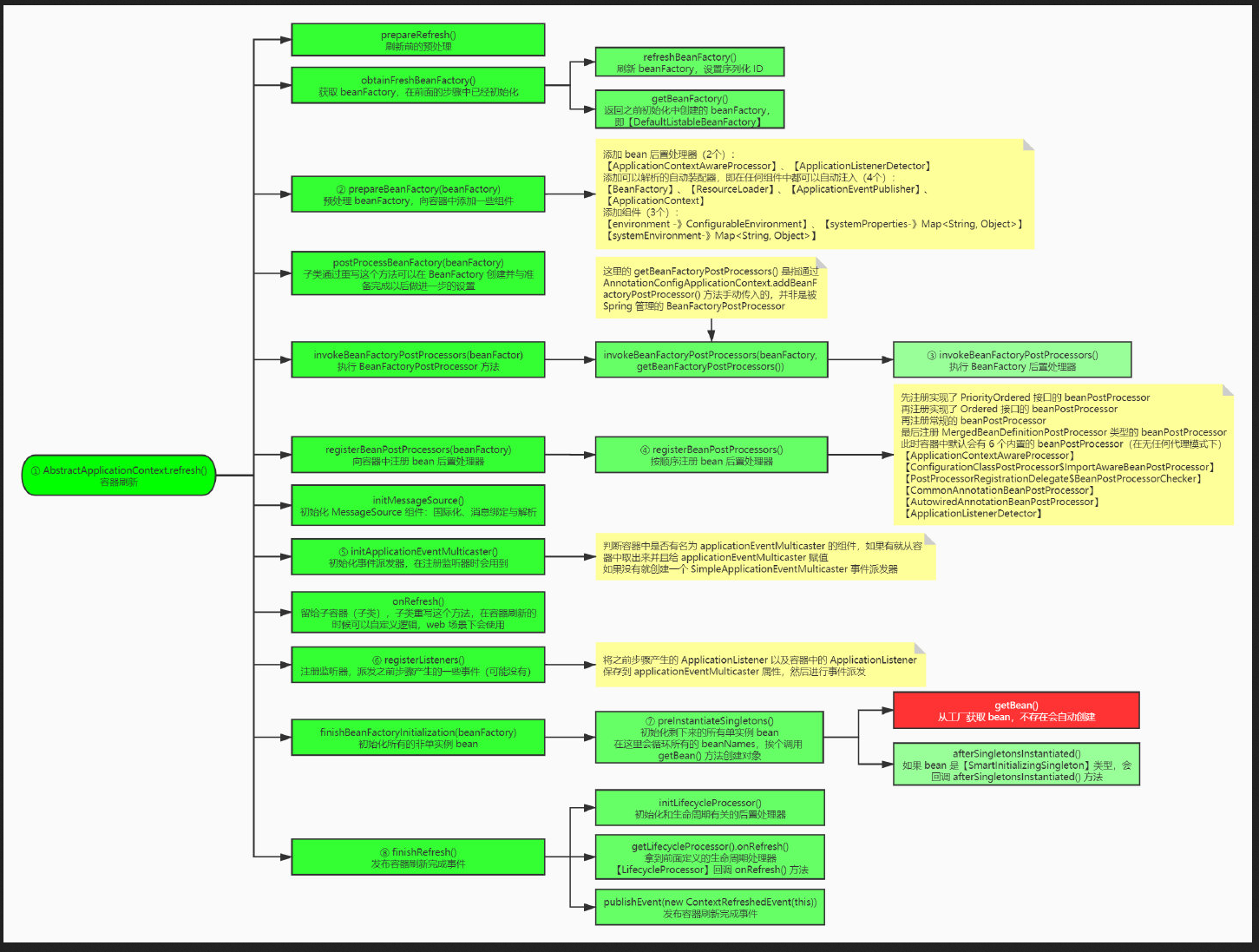
一、说明
本文详细论述,如何在tensorflow下,在mnist数据集合上进行GAN实现。包括:框架建立、数据集读出、生成器、鉴别器、代价函数、优化等具体步骤的代码实现。
二、GAN框架介绍
- 生成器:此组件负责生成新图像。
- 鉴别器:此组件评估生成的图像的质量。
我们将开发的使用 GAN 生成图像的一般架构如下图所示。以下部分简要介绍了如何读取数据库、创建所需的体系结构、计算损失函数和训练网络。此外,还提供了用于检查网络和生成新图像的代码。

三、读取数据集
MNIST数据集在计算机视觉领域占有重要地位,包括大量尺寸为28×28像素的手写数字。该数据集因其灰度、单通道图像格式而被证明是我们的 GAN 实现的理想选择。
随后的代码片段演示了如何使用 Tensorflow 中的内置函数来加载 MNIST 数据集。成功加载后,我们继续将图像归一化并重塑为三维格式。这种转换可以在GAN架构中高效处理2D图像数据。此外,还为训练和验证数据分配内存。
每个图像的形状定义为 28x28x1 矩阵,其中最后一个维度表示图像中的通道数。由于MNIST数据集包含灰度图像,因此我们只有一个通道。
在这个特定实例中,我们将潜在空间的大小(表示为“zsize”)设置为 100。此值可以根据特定要求或偏好进行调整。
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np
num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100
(train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
四、定义生成器

生成器 (D) 在 GAN 中起着至关重要的作用,因为它负责生成可以欺骗鉴别器的逼真图像。它是 GAN 中图像形成的主要组件。在本研究中,我们利用了发电机的特定架构,该架构包含一个全连接(FC)层并采用Leaky ReLU激活。但是,值得注意的是,生成器的最后一层使用TanH激活而不是LeakyReLU。进行此调整是为了确保生成的图像驻留在与原始 MNIST 数据库相同的间隔 (-1, 1) 内。
def build_generator():
gen_model = Sequential()
gen_model.add(Dense(256, input_dim=z_size))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(512))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(1024))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(np.prod(input_shape), activation='tanh'))
gen_model.add(Reshape(input_shape))
gen_noise = Input(shape=(z_size,))
gen_img = gen_model(gen_noise)
return Model(gen_noise, gen_img)
五、定义鉴别器
在生成对抗网络(GAN)中,鉴别器(D)通过评估真实性和可能性来执行区分真实图像和生成图像的关键任务。此组件可以被视为二元分类问题。为了完成这项任务,我们可以采用简化的网络架构,包括全连接层(FC)、泄漏ReLU激活和辍学层。值得一提的是,鉴别器的最后一层包括一个FC层,然后是Sigmoid激活。Sigmoid 激活函数产生所需的分类概率。
def build_discriminator():
disc_model = Sequential()
disc_model.add(Flatten(input_shape=input_shape))
disc_model.add(Dense(512))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(256))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(1, activation='sigmoid'))
disc_img = Input(shape=input_shape)
validity = disc_model(disc_img)
return Model(disc_img, validity)
六、计算损失函数
为了确保 GAN 中良好的映像生成过程,确定适当的指标来评估其性能非常重要。通过损失函数定义此参数。
鉴别器负责将生成的图像分为真假,并给出真实的概率。为了实现这种差异,鉴别器的目标是在呈现真实图像时最大化函数 D(x),在呈现虚假图像时最小化 D(G(z))。
另一方面,生成器的目的是通过创建可能被误解的逼真图像来愚弄鉴别器。在数学上,这涉及缩放 D(G(z))。但是,仅依靠此组件作为损失函数会导致网络对错误的结果过于自信。为了解决这个问题,我们使用损失函数的对数(D(G(z))。
GAN生成图像的总体成本函数可以表示为最小游戏:
min_G max_D V(D,G) = E(xp_data(x))(log(D(x))] + E(zp(z))(log(1 – D(G(z)))])
这种GAN训练需要良好的平衡,并且可以作为两个对手之间的比赛。每一方都试图通过玩 MinMax 游戏来影响和超越对方。
我们可以使用二进制交叉熵损失来实现生成器和鉴别器。
对于生成器和鉴别器的实现,我们可以利用二进制交叉熵损失。
# discriminator
disc= build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
z = Input(shape=(z_size,))
# generator
img = generator(z)
disc.trainable = False
validity = disc(img)
# combined model
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
七、优化损耗
为了促进网络的训练,我们的目标是让GAN参与MinMax游戏。此学习过程围绕通过使用梯度下降优化网络权重展开。为了加速学习过程并防止收敛到次优损失环境,采用了随机梯度下降(SGD)。
鉴于鉴别器和生成器具有不同的损耗,单个损失函数无法同时优化两个系统。因此,使用每个系统的单独损失函数。
def intialize_model():
disc= build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
generator = build_generator()
z = Input(shape=(z_size,))
img = generator(z)
disc.trainable = False
validity = disc(img)
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
return disc, Generator, and combined
指定所有必需的特征后,我们可以训练系统并优化损失。训练 GAN 生成图像的步骤如下:
- 加载图像并生成与加载的图像大小相同的随机声音。
- 区分上传的图像和产生的声音,并考虑真假的可能性。
- 产生另一个相同幅度的随机噪声,并作为发生器的输入。
- 在特定时间段内训练生成器。
- 重复这些步骤,直到图像令人满意。
def train(epochs, batch_size=128, sample_interval=50):
# load images
(train_ims, _), (_, _) = mnist.load_data()
# preprocess
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# training loop
for epoch in range(epochs):
batch_index = np.random.randint(0, train_ims.shape[0], batch_size)
imgs = train_ims[batch_index]
# create noise
noise = np.random.normal(0, 1, (batch_size, z_size))
# predict using a Generator
gen_imgs = gen.predict(noise)
# calculate loss functions
real_disc_loss = disc.train_on_batch(imgs, valid)
fake_disc_loss = disc.train_on_batch(gen_imgs, fake)
disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss)
noise = np.random.normal(0, 1, (batch_size, z_size))
g_loss = full_model.train_on_batch(noise, valid)
# save outputs every few epochs
if epoch % sample_interval == 0:
one_batch(epoch)
八、生成手写数字
使用 MNIST 数据集,我们可以创建一个实用程序函数,以使用生成器生成一组图像的预测。该函数生成随机声音,将其提供给生成器,运行它以显示生成的图像并将其保存在特殊文件夹中。建议定期运行此实用程序功能,例如每 200 个周期运行一次,以监视网络进度。实现如下:
def one_batch(epoch):
r, c = 5, 5
noise_model = np.random.normal(0, 1, (r * c, z_size))
gen_images = gen.predict(noise_model)
# Rescale images 0 - 1
gen_images = gen_images*(0.5) + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
在我们的实验中,我们使用 10 的批量大小训练了大约 000,32 个 GAN。为了跟踪训练进度,我们每 200 个时期保存一次生成的图像,并将它们存储在名为“images”的指定文件夹中。
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)现在,让我们检查不同阶段的GAN仿真结果:初始化,400个epoch,5000个epoch,以及10000个epoch的最终结果。
最初,我们从随机噪声作为生成器的输入开始。

经过 400 个 epoch 的训练,我们可以观察到一些进展,尽管生成的图像仍然与真实数字有很大不同。

在训练了 5000 个 epoch 之后,我们可以观察到生成的数字开始类似于 MNIST 数据集。

完成完整的 10,000 个 epoch 训练,我们获得以下输出。

这些生成的图像与用于训练网络的手写数字数据非常相似。重要的是要注意,这些图像不是训练集的一部分,完全由网络生成。
九、后续步骤
现在我们在GAN的图像生成方面取得了不错的效果,有很多方法可以进一步改进它。在此讨论范围内,我们可以考虑尝试不同的参数。以下是一些建议:
- 探索潜在空间变量的不同值z_size以查看它是否提高效率。
- 将训练周期数增加到 10,000 个以上。将训练持续时间增加一倍或三倍可能会显示改善或降级的结果。
- 尝试使用不同的数据集,如时尚 MNIST 或移动 MNIST。由于这些数据集具有与 MNIST 相同的结构,因此请调整我们现有的代码。
- 考虑尝试替代架构,如CycleGun,DCGAN等。修改生成器和鉴别器函数可能足以探索这些模型。
通过实施这些更改,我们可以进一步增强 GAN 的功能,并探索图像生成的新可能性。
这些生成的图像与用于训练网络的手写数字数据非常相似。这些图像不是训练集的一部分,完全由网络生成。
十、结论
总之,GAN是一个强大的机器学习模型,能够基于现有数据库生成新图像。在本教程中,我们展示了如何使用 Tensorflow 库作为示例和 MNIST 数据库来设计和训练一个简单的 GAN。
关键要点
- GAN由两个重要组件组成:一个生成器,负责从随机输入生成新图像,以及鉴别器,旨在区分真假图像。
- 通过学习过程,我们成功地创建了一组与手写数字非常相似的图像,如示例图像所示。
- 为了优化 GAN 性能,我们提供了匹配指标和损失函数,以帮助区分真假图像。通过在看不见的数据上评估 GAN 并使用生成器,我们可以生成新的、以前看不见的图像。
- 总体而言,GAN在图像生成方面提供了有趣的可能性,并且在机器学习和计算机视觉等多种应用中具有巨大潜力。
十一、常见问题
问题 1.什么是生成对抗网络 (GAN)?
答:生成对抗网络(GAN)是一种机器学习框架,可以生成具有类似于给定训练集的统计信息的新数据。将 GAN 用于多种类型的数据,包括图像、视频或文本。
问题 2.什么是创意模型?
一个。生成模型是一种机器学习算法,它基于一组输入数据生成新数据。将这些模型用于图像生成、文本生成和其他形式的数据合成等任务。
问题 3.什么是损失函数?
一个。损失函数是用于测量两组数据之间的差异的数学函数。在 GAN 的上下文中,通过优化定义生成数据和训练数据之间差异的损失函数来训练模型生成器,通常使用类记录和带注释的图像。
问题 4.CNN和Gan有什么区别?
答:CNN(卷积神经网络)和GAN(生成对抗网络)都是深度学习架构,但目标不同。GAN是生成模型,旨在生成类似于给定训练集的新数据,而CNN用于分类和识别任务。虽然可以通过将CNN配置为可变自动编码器(VAE)来将其用作生成模型,但CNN在判别训练方面表现良好,在计算机视觉中的图像分类任务中更有效。