文章目录
- 🍋引言
- 🍋xlrd库和xlwt库
- 🍋创建Excel文件
- 🍋通过Python代码向Excel写入数据
- 🍋案例实战
🍋引言
本节主要介绍一下在使用网络爬虫技术的时候,如何将数据存储到Excel中去
🍋xlrd库和xlwt库
xlrd(XL Read)是一个用于读取Excel文件的Python库。它支持.xls和.xlsx格式的文件,并可以提取文件中的数据、格式和元数据等信息。xlrd提供了许多功能,包括选择特定的工作表、获取单元格的值和样式、遍历工作表中的数据等。它是一个强大的工具,可用于数据分析、数据提取和数据处理等任务。
xlwt(XL Write)是一个用于创建和写入Excel文件的Python库。它支持.xls格式的文件,并允许用户创建新的工作表、添加数据、设置单元格样式等。xlwt提供了易于使用的API,使得创建和编辑Excel文件变得简单。它适用于各种应用场景,如生成报告、创建数据可视化或自动化数据处理等。
两个库的在线安装命令如下
pip install xlrd
pip install xlwt
🍋创建Excel文件
创建文件的代码较为简单,如下
import xlwt
workbook = xlwt.Workbook(encoding='utf8')
但是我们平时创建一个Excel文件的时候下面会有表格(sheet),所以我们不光要创建Excel对象,而且需要创建若干sheet表格,具体代码如下
sheet1 = workbook.add_sheet('sheet1')
sheet2 = workbook.add_sheet('sheet2')
sheet3 = workbook.add_sheet('sheet3')
创建完表格后,最后一步就是保存
workbook.save(r"C:\Users\Administrator\Desktop\期中成绩.xls")
这个绝对路径,教大家一个查看方法,按住shift,鼠标右键
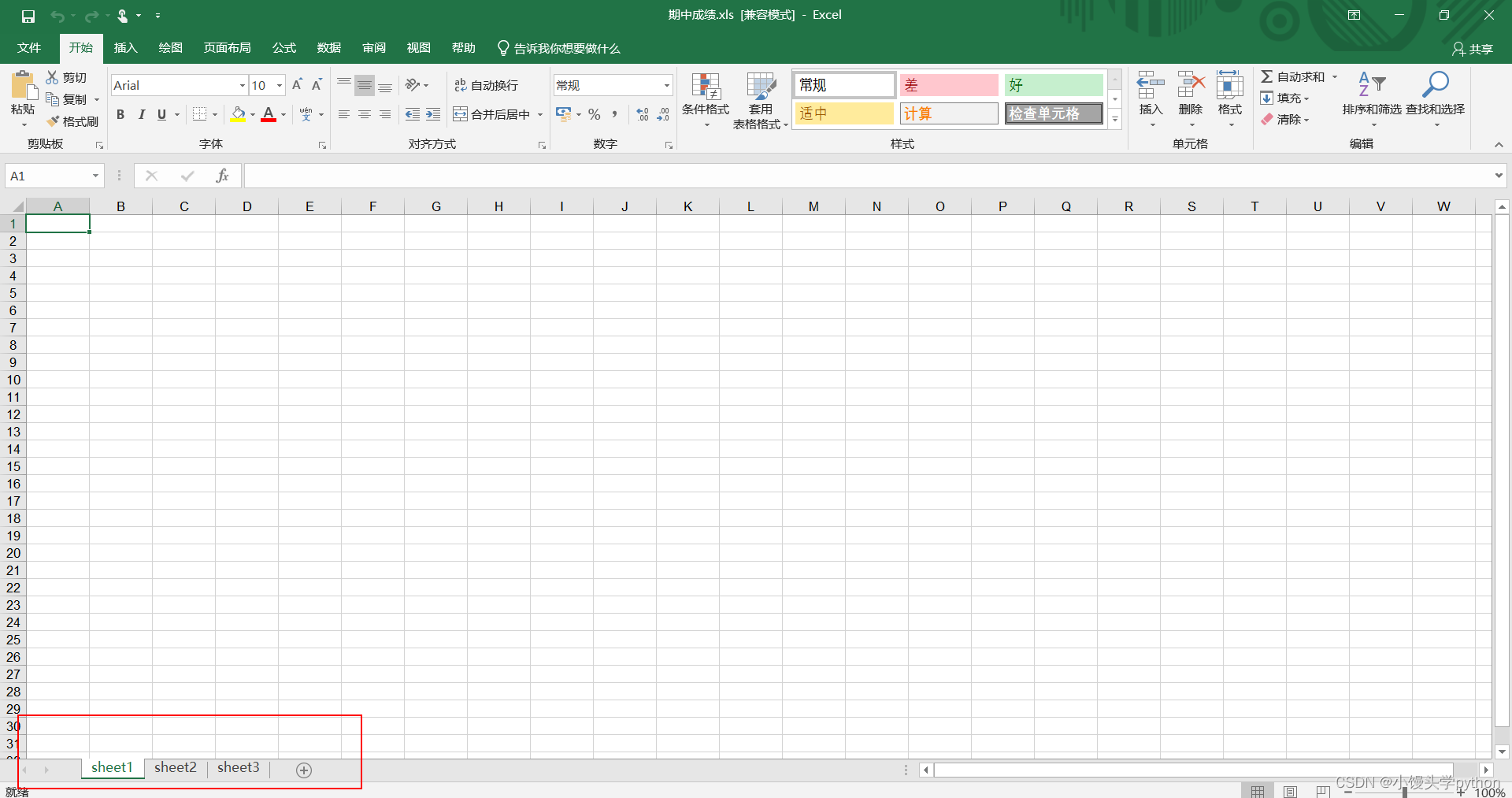
运行代码后在桌面就会出现一个Excel文件

点进去也会发现有三个sheet表格
🍋通过Python代码向Excel写入数据
这里我们注意,在Excel中每个单元格的坐标是字母+数字的组合

但是在Python中并不是这样,具体可以参考下图
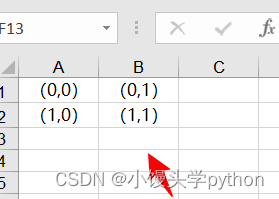
不同之处我们知道了,接下来上代码
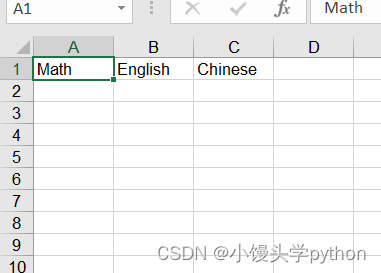
sheet1.write(0, 0, 'Math')
sheet1.write(0, 1, 'English')
sheet1.write(0, 2, 'Chinese')
运行后
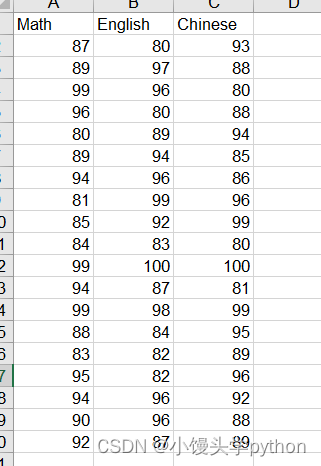
接下来我们可以简单的为单元个填充成绩,这里我们可以采用循环
for row in range(1, 20, 1):
for col in range(0, 3, 1):
sheet1.write(row, col, random.randint(80, 100))
运行结果如下
🍋案例实战
这里我们将某博的热搜作为实战对象,首先我们需要准备一个爬取此网站前期的准备
# 导入模块
import requests
from bs4 import BeautifulSoup
# 定义url和请求头
url = 'https://s.weibo.com/top/summary?display=0&retcode=6102'
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WW2kX-Z46lRbEGNeGGOqQzg; SINAGLOBAL=1879006065688.1335.1674544342950; UOR=,,www.baidu.com; SUB=_2AkMUum_nf8NxqwJRmP8cy2rkbYh1zQ_EieKi5p48JRMxHRl-yT9vqmEptRB6PzpBCFr8Nw9WHg85yXpbEGjv_BB4-91Q; _s_tentry=weibo.com; Apache=5265586173710.342.1689125693519; ULV=1689125693521:3:1:1:5265586173710.342.1689125693519:1675905464675"
}
# 发送请求
response = requests.get(url,headers=_headers)
content = response.content.decode('utf8')
# 实例化对象
soup = BeautifulSoup(content, 'lxml')
# 提取数据
tds = soup.find_all('td',class_="td-02")[1:]
weibos = []
for td in tds:
# 内容
event = td.find_all('a')[0].string # 只把对象里面的内容提取出来
# 热度
hot = td.find_all('span')[0].string
weibo = {
"event": event,
"hot": hot
}
weibos.append(weibo)
print(weibos)
上面我们采用bs4进行热搜的爬取
之后我们创建一个新的Excel表格,并将sheet表格命名为微博
workbook = xlwt.Workbook(encoding='utf8')
sheet1 = workbook.add_sheet('微博')
之后我们可以使用keys进行打印出我们需要的标题
print(weibos[0].keys())
运行结果如下
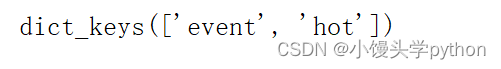
之后我们使用zip函数搭配for循环
keys = weibos[0].keys()
for i, key in zip(range(len(keys)),keys):
sheet1.write(0, i, key)
最后我们将爬取的数据导进去
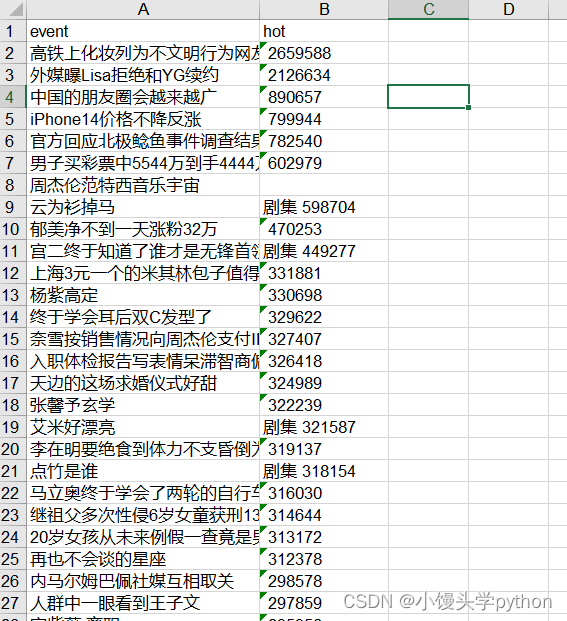
for row in range(1, len(weibos)+1, 1):
for col, key in zip(range(len(keys)), keys):
sheet1.write(row, col, weibos[row-1][key])
我来讲解一下上段代码:外循环主要是行循环,range里面主要len(weibos)要加一,要不然最后一个热搜导不进去;二层循环每次将event和hot分别插入Excel中
运行结果如下
下节我们介绍存储为CSV文件

挑战与创造都是很痛苦的,但是很充实。