最近在研究Llama大模型的本地化部署和应用测试过程中,为了给大家提供更多的应用方式,研究了如何利用python快速搭建各种应用访问服务,一般来说,我们开发完成的软件模块为了体现价值,都需要对外提供服务,最原始的方式就是将源码或编译好的类库提供给需要使用的客户进行引入使用,但对于大模型的应用来说,这种方式显然不行,一个是由于模型太大,需要更多的存储资源和计算资源等,客户侧一般没有相应的资源,一个是由于部署运行环境的复杂性和可运维性,导致这种应用方式的成功率和可移植性较低,因此,目前比较多的是以下三种方式,主要有终端Terminal、Web应用服务和Rest服务等。下面就逐个举例说明。
一、终端Terminal服务
这种方式需要在客户端安装相应的Terminal工具,比如putty,xterm等,同时需要给客户开放bash用户,并将需要执行的服务打包成sh命令或python命令,存放到用户的env下,否则会找不到命令,但这种方式的优点是软件模块对应的服务返回直接迅速,基本不延迟,用户很快能拿到相应的信息,但只能手动或半自动化操作使用。大模型预测的示例如下
运行命令:python llama2Test2.py Chinese-Llama-2
输出结果:大模型服务会根据用户的prompt反馈相应结果,详见下图。

二、Web应用服务
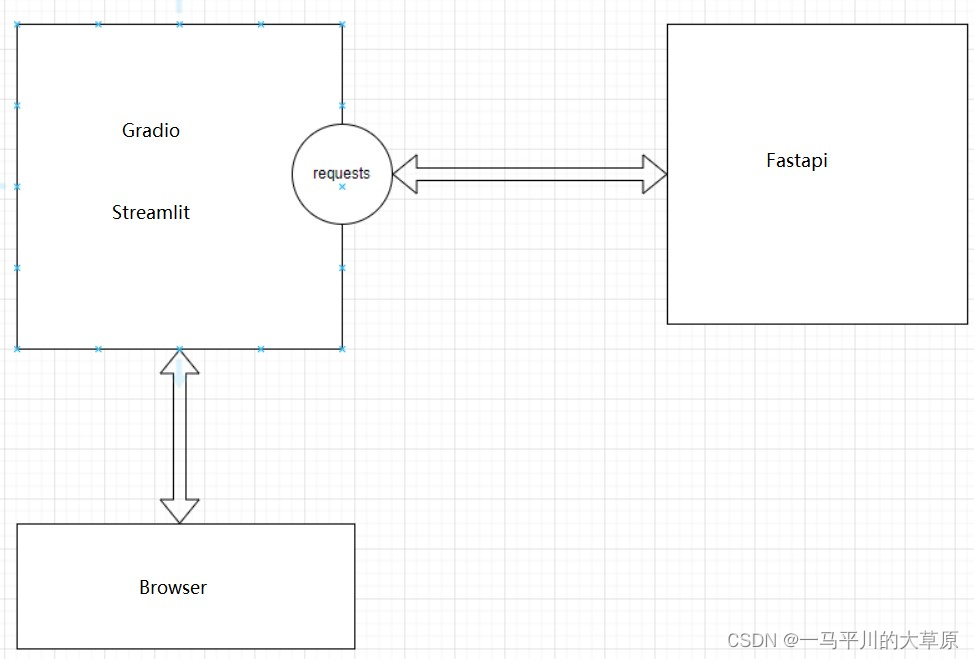
这种方式对客户的要求最低,耦合性最小,特别是面向那种初级用户来说,比如做一个前期的原型demo,这种方式最多,在传统的信息系统建设过程中,一般采用原型设计软件代替,比如Axure,但在机器学习和大模型应用测试过程中,由于python的强大,主要通过Gradio和Streamlit框架来实现,这些框架都支持快速的界面设计,用户登录验证和ip过滤等等,有些后端的服务没办法实现时,再结合Fastapi框架,封装相应的Rest接口,实现两者的组合使用,也就是说Gradio和Streamlit更接近Browser,是前端的后侧或者后端的对外应用访问接口,Fastapi是纯后端,实现复杂的计算处理和大数据解析及分片操作,二者关系见下图所示,大模型问答反馈的应用测试详见下图。
#Gradio方式
import gradio as gr
from transformers import AutoModel, AutoTokenizer,AutoModelForCausalLM,TextStreamer
from transformers.generation.utils import GenerationConfig
if __name__ == "__main__":
model_path = "model/" + sys.argv[1]
# 获得模型
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
#
with gr.Blocks() as demo:
headStr="""<h1 align="center">"""
headStr =headStr+modelName+"</h1>"
gr.HTML(headStr)
# gr.HTML("""<h1 align="center">chatglm-6b</h1>""")
chatbot = gr.Chatbot()
with gr.Row():
with gr.Column(scale=4):
with gr.Column(scale=12):
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
container=False)
with gr.Column(min_width=32, scale=1):
submitBtn = gr.Button("Submit", variant="primary")
with gr.Column(scale=1):
emptyBtn = gr.Button("Clear History")
max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
history = gr.State([])
past_key_values = gr.State(None)
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history, past_key_values],
[chatbot, history, past_key_values], show_progress=True)
submitBtn.click(reset_user_input, [], [user_input])
emptyBtn.click(reset_state, outputs=[chatbot, history, past_key_values], show_progress=True)
demo.queue().launch(server_name="0.0.0.0", server_port=7860, inbrowser=True, auth=("llm-oil", "ABCD234"))
#Streamlit方式
from transformers import AutoModel, AutoTokenizer
import streamlit as st
from streamlit_chat import message
import streamlit_authenticator as stauth
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained("model/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("model/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
return tokenizer, model
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
tokenizer, model = get_model()
def predict(container,input, max_length, top_p, temperature, history=None):
with container:
if len(history) > 0:
if len(history)>MAX_BOXES:
history = history[-MAX_TURNS:]
for i, (query, response) in enumerate(history):
message(query, avatar_style="big-smile", key=str(i) + "_user")
message(response, avatar_style="bottts", key=str(i))
message(input, avatar_style="big-smile", key=str(len(history)) + "_user")
st.write("AI正在回复:")
with st.empty():
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
temperature=temperature):
query, response = history[-1]
st.write(response)
return history
if __name__ == "__main__":
# auth=["llm-oil-local", "S6rJambM00Odn4LIEEix"]
container = st.container()
# create a prompt text for the text generation
prompt_text = st.text_area(label="用户命令输入",
height=100,
placeholder="请在这儿输入您的命令")
max_length = st.sidebar.slider(
'max_length', 0, 4096, 2048, step=1
)
top_p = st.sidebar.slider(
'top_p', 0.0, 1.0, 0.6, step=0.01
)
temperature = st.sidebar.slider(
'temperature', 0.0, 1.0, 0.95, step=0.01
)
if 'state' not in st.session_state:
st.session_state['state'] = []
if st.button("发送", key="predict"):
with st.spinner("AI正在思考,请稍等........"):
# text generation
st.session_state["state"] = predict(container,prompt_text, max_length, top_p, temperature, st.session_state["state"])运行命令:python llama2Test2.py Chinese-Llama-2 或者 streamlit run web_host02.py
输出结果:web服务会根据用户提交的prompt反馈相应结果,详见下图。

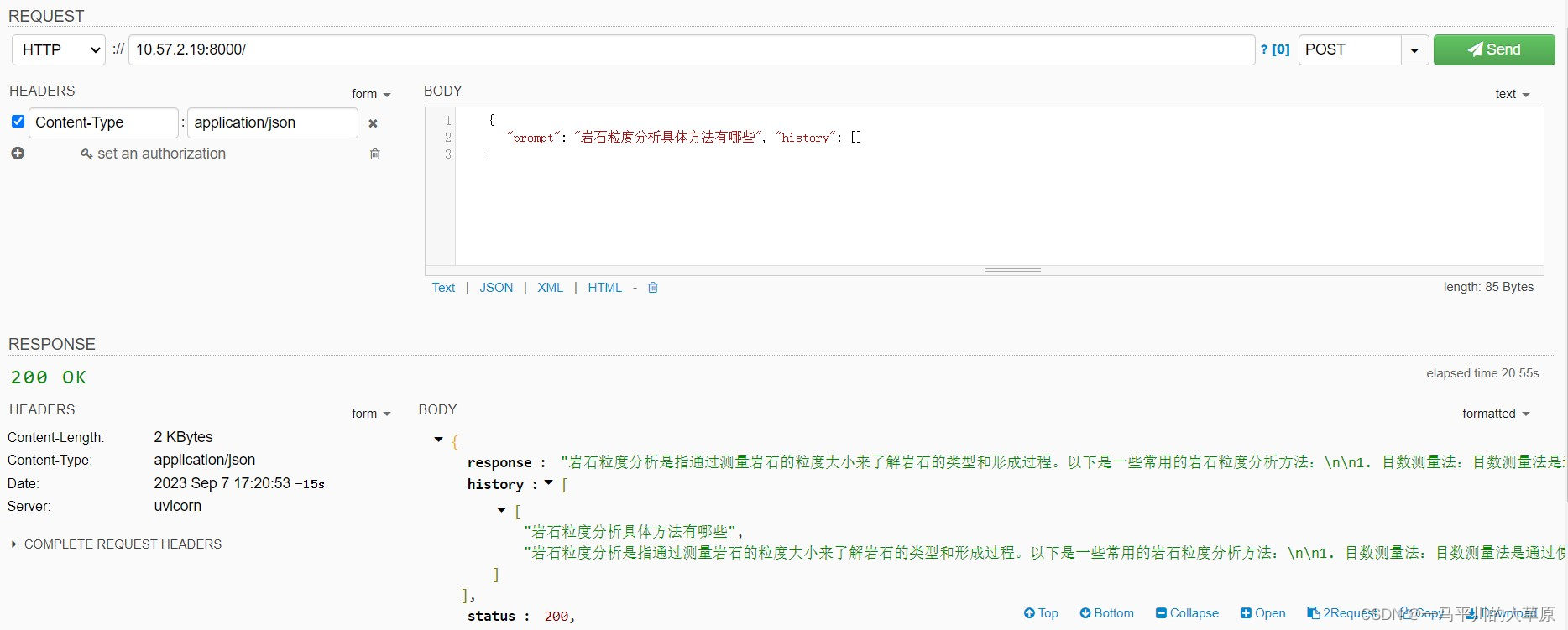
三、Rest接口服务
这种方式对客户的要求相对高一些,主要面向开发人员或前后端集成测试人员,实现前后端分离,耦合性小,实现方式主要基于Fastapi框架,封装相应的Rest接口,Fastapi是纯后端,实现复杂的计算处理和大数据解析及分片操作,正好满足大模型训练预测的结果反馈和智能科研工作辅助,服务端运行代码详见下图。
from fastapi import FastAPI, Request,status
from fastapi.responses import JSONResponse
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn, json, datetime
import torch
app = FastAPI()
if __name__ == '__main__':
model_path = "model/" + sys.argv[1]
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_4bit=model_path.endswith("4bit"),
torch_dtype=torch.float16,
device_map='auto'
)
model.eval()
uvicorn.run(app, host='0.0.0.0', port=9060, workers=1)运行命令:python restApi.py Chinese-Llama-2
输出结果:Rest服务会根据用户post提交的prompt数据(json格式)反馈相应结果,详见下图