读高性能MySQL(第4版)笔记09_创建高性能索引(下)
news2026/2/16 8:59:55
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1011264.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

用Python实现链式调用
嗨喽,大家好呀~这里是爱看美女的茜茜呐 我们在使用Django的models查询数据库时,可以看到有这种写法:
form app.models import XXX
query XXX.objects.all()
query query.filter(name123, age456).filter(salary999)在这种写法里面…
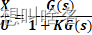
matlab根轨迹绘制
绘制根轨迹目的就是改变系统的闭环极点,使得系统由不稳定变为稳定或者使得稳定的系统变得更加稳定。
在使用PID控制器的时候,首先要确定的参数是Kp,画成框图的形式如下: 也就是想要知道Kp对系统性能有哪些影响,此时就…

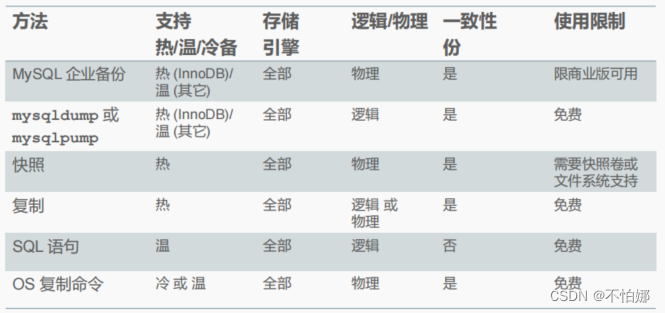
【MySQL】mysql中有哪几种类型的备份技术?它们各自有什么优缺点?
为什么要备份?备份类型(从类型的角度)备份技术(从技术手段的角度)不同备份方法的比较感谢 💖 为什么要备份?
数据库或它所在的平台可能会出现问题,这时候数据库中的数据可能就遭到了…

春秋云镜 CVE-2014-4577
春秋云镜 CVE-2014-4577 wordpress插件 wp-amasin-the-amazon-affiliate-shop < 0.97 LFI
靶标介绍
wordpress插件 wp-amasin-the-amazon-affiliate-shop < 0.97 存在路径穿越漏洞,使得可以读取任意文件。
启动场景 漏洞利用
exp
http://url/wp-content/…

【Transformer系列】深入浅出理解Embedding(词嵌入)
一、参考资料
一文读懂Embedding的概念,以及它和深度学习的关系
论文
[1] Attention is All you Need
二、Embedding相关介绍
Embedding,直译是词嵌入、嵌入层。
1. 引言
2. one-hot编码
假设,中文有10个字 “星 巴 克 喜 欢 瑞 幸 的…
LinuxFTP云盘-文件服务系统
目录
1.项目介绍
2.项目运行展示
3.实现思路
服务端:
客户端:
4.相关调用函数
socket():创建一个网络通信端点原型:int socket(int domain, int type, int protocol);
atoi():将字符串转变成整型数据原型&…
黑马JVM总结(八)
(1)StringTable面试题 1.8 1.6时 (2)StringTable的位置
jvm1.6时StringTable是常量池的一部分,它随着常量池存储在永久代当中,在1.7、1.8中从永久代变成了堆中,为什么做这个更改呢?…

c语言每日一练(15)
前言:每日一练系列,每一期都包含5道选择题,2道编程题,博主会尽可能详细地进行讲解,令初学者也能听的清晰。每日一练系列会持续更新,上学期间将看学业情况更新。 五道选择题:
1、程序运行的结果…

家政服务接单小程序开发源码 家政保洁上门服务小程序源码 开源完整版
分享一个家政服务接单小程序开发源码,家政保洁上门服务小程序源码,一整套完整源码开源,可二开,含完整的前端后端和详细的安装部署教程,让你轻松搭建家政类的小程序。家政服务接单小程序开发源码为家政服务行业带来了诸…

【数据在内存中的储存】
1.整数在内存中的存储💻
在讲解操作符的时候,我们就讲过了下⾯的内容: 整数的2进制表⽰⽅法有三种,即原码、反码和补码 三种表⽰⽅法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”&…
C# Onnx Yolov8 Fire Detect 火焰识别,火灾检测
效果
项目 代码
using Microsoft.ML.OnnxRuntime.Tensors;
using Microsoft.ML.OnnxRuntime;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using Syste…
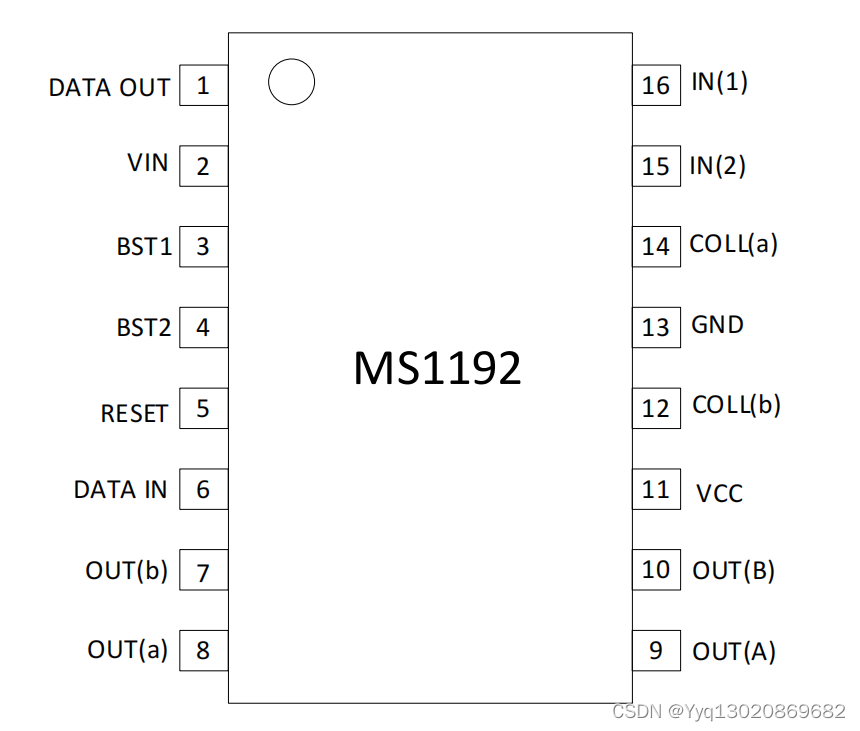
HBS 家庭总线驱动和接收芯片MS1192,应用于电话及相关设备、空调设备、安全设备、AV 装置
MS1192 是适用于 HBS 总线规范(日本电子工业协会) 的适配器芯片,具备发送、接收数据的功能。在发送接收 单元中,采用 AMI 编码方式,可使用双绞线进行互联,信 号传输采用差分方式。 芯片采用单电源…
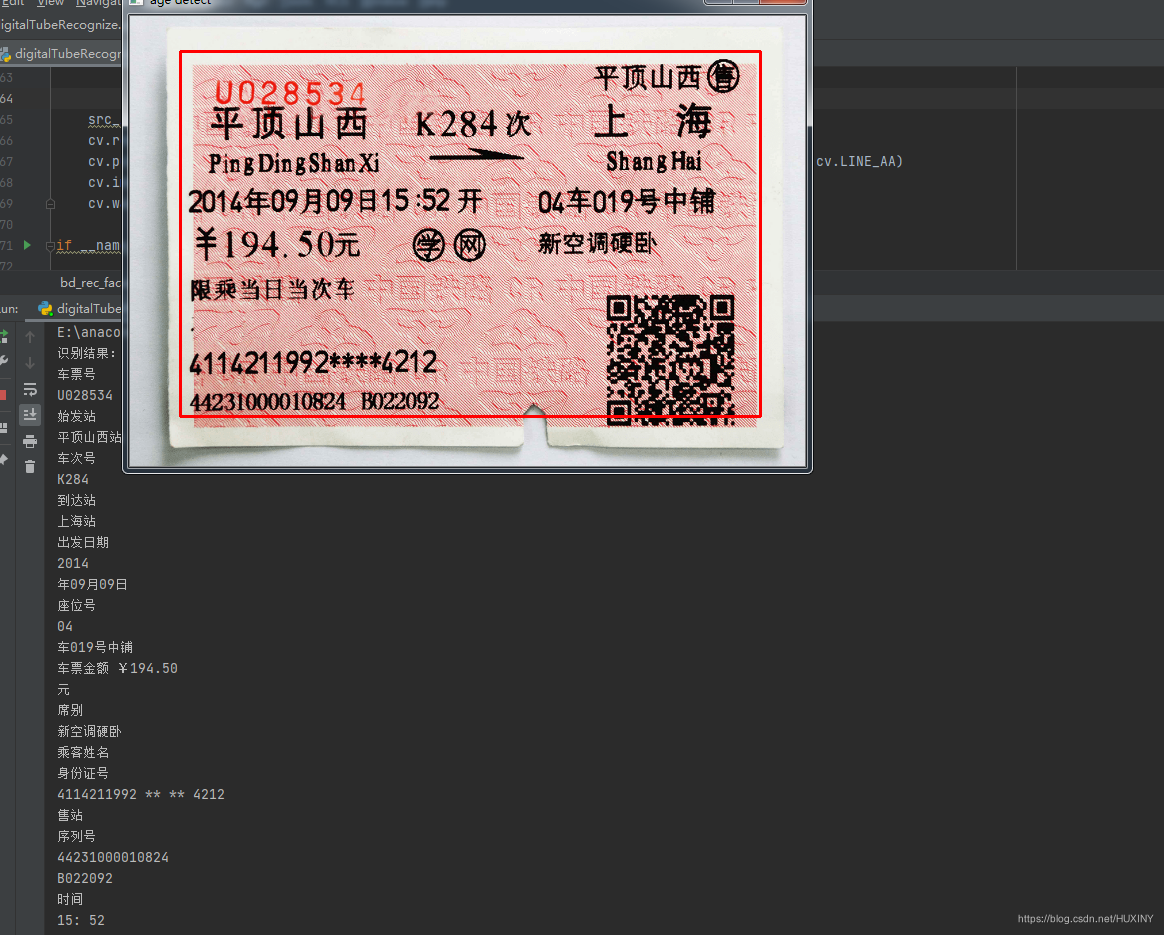
竞赛 基于机器视觉的火车票识别系统
文章目录 0 前言1 课题意义课题难点: 2 实现方法2.1 图像预处理2.2 字符分割2.3 字符识别部分实现代码 3 实现效果最后 0 前言
🔥 优质竞赛项目系列,今天要分享的是
基于机器视觉的火车票识别系统
该项目较为新颖,适合作为竞赛…
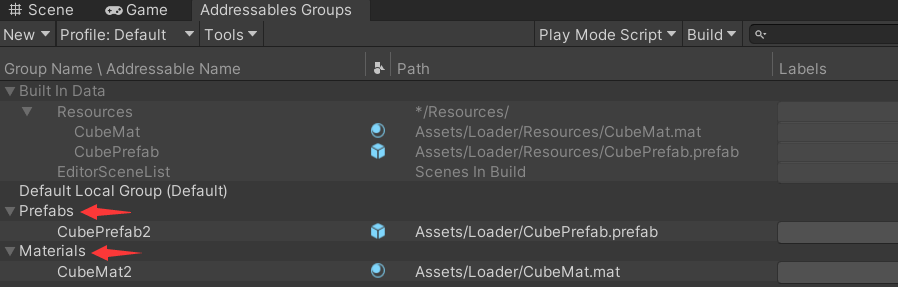
【Unity3D】资源管理
1 前言 Unity 中 资源管理方案主要有 Resources、TextAsset、ScriptableObject 、AssetDatabase、PlayerPrefs、Addressables、AssetBundle、SQLite,本文将介绍其中大部分方案。
2 Resources Resources 主要用于加载资源,被加载的资源需要放在 Resource…
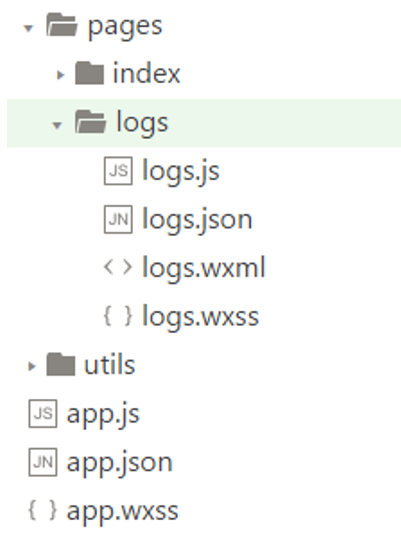
微信小程序学习笔记1.0
第1章 微信小程序基础
1.1 微信小程序介绍
1.1.1 什么是微信小程序
微信小程序的特点:
① 微信小程序是不需要下载和安装的;
② 它可以完成App应用软件的交互功能;
③ 用户扫一扫或者搜一下就可以使用小程序;
④ 微信小程序…

什么是气象站?气象站的简介
气象站是一种用于收集、分析和处理气象数据的设备,能够为人们提供及时、准确的气象数据和决策支持。下面是对气象站的详细介绍:
气象站是一种用于气象观测的设备,它通过各种传感器和测量设备,对大气环境中的温度、湿度、气压、风…
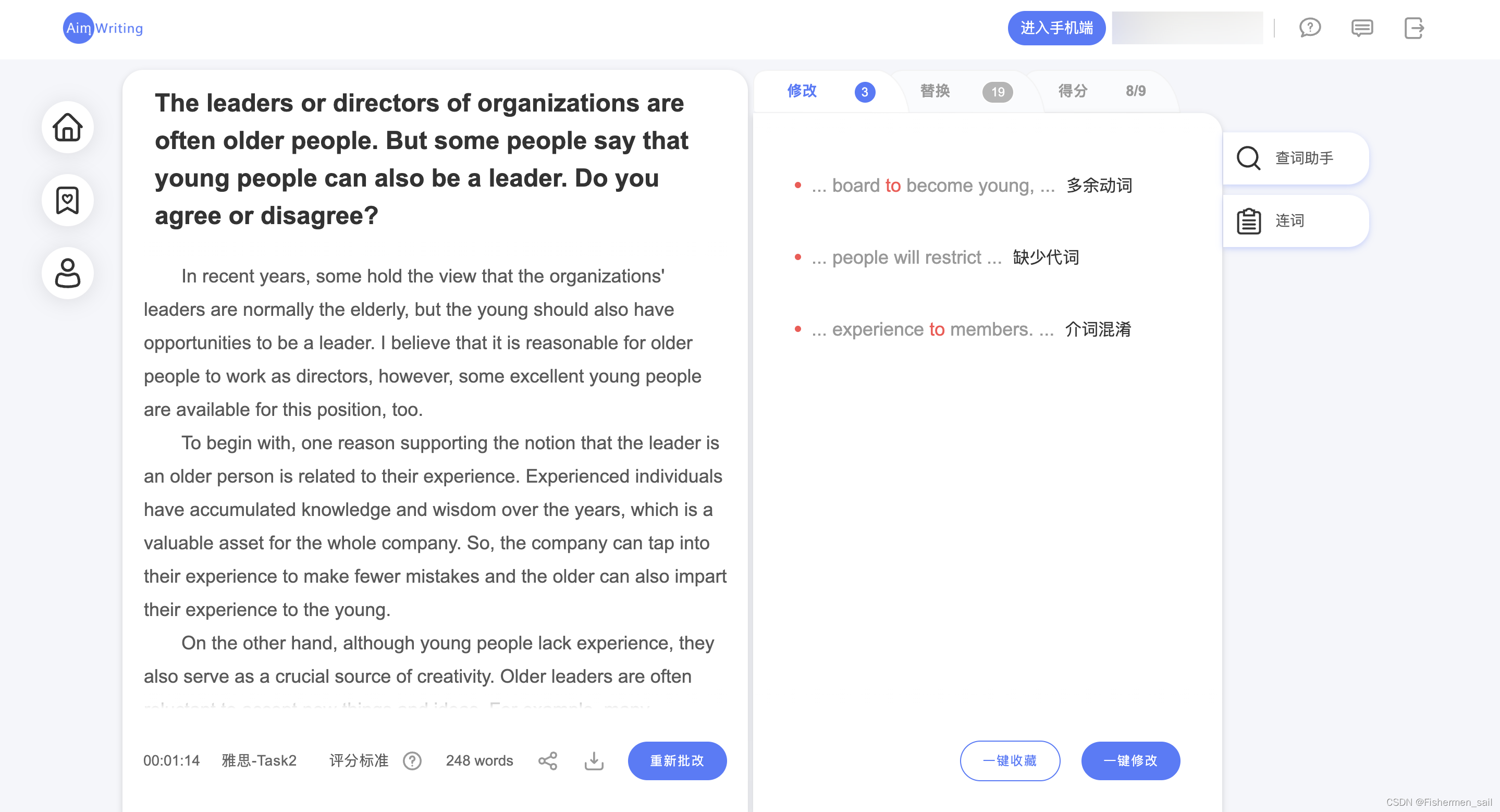
“微软爱写作”连词摘录
目录 前言连词1 引入2 承接3 最后4 因果关系5 转折关系6 并列关系7 递进关系8 比较关系(相同点)9 对照关系(不同点)10 举例关系11 例外关系12 强调关系13 条件关系14 归纳总结15 方位关系16 目的关系17 重申关系18 时间关系19 结果…
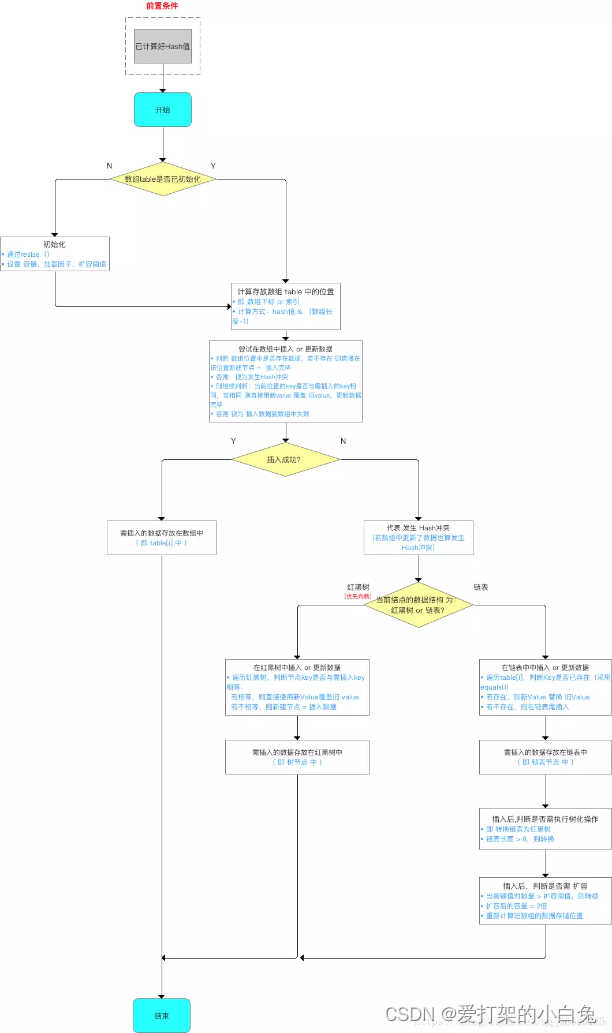
Java面试八股文宝典:初识数据结构-数组的应用扩展之HashMap
前言
除了基本的数组,还有其他高级的数据结构,用于更复杂的数据存储和检索需求。其中,HashMap 是 Java 集合框架中的一部分,用于存储键值对(key-value pairs)。HashMap 允许我们通过键来快速查找和检索值&…