目录
一、课程设计题目
基于TF-IDF的文本分类
二、课程设计设置
1. 操作系统
2. IDE
3. python
4. 相关的库
三、课程设计目标
1. 掌握数据预处理的方法,对训练集数据进行预处理;
2. 掌握文本分类建模的方法,对语料库的文档进行建模;
3. 掌握分类算法的原理,基于有监督的机器学习方法,训练文本分类器。
四、课程设计内容
1. 数据采集和预处理
a. 数据采集
b. 数据清洗
c. 文本预处理:分词、去除停用词、移除低频词
2. 特征提取和文本向量模型构建
a. 词袋模型
b. TF-IDF(本次实验中选取该方法)
c. Word2Vec
3. 分类模型训练
a. 数据划分
b. 模型训练
c. 模型调参:网格搜索
d. 模型评估:计算准确率、精确率、召回率、F1值、混淆矩阵
五、实验结果分析
一、课程设计题目
基于TF-IDF的文本分类
二、课程设计设置
1. 操作系统
Windows 11 Home
2. IDE
PyCharm 2022.3.1 (Professional Edition)
3. python
3.6.0
4. 相关的库
| jieba | 0.42.1 |
| numpy | 1.13.1 |
| pandas | 0.24.0 |
| requests | 2.28.1 |
| scikit-learn | 0.19.0 |
| tqdm | 4.65.0 |
conda create -n DataMining python==3.6 pandas scikit-learn tqdm requests jieba三、课程设计目标
1. 掌握数据预处理的方法,对训练集数据进行预处理;
2. 掌握文本分类建模的方法,对语料库的文档进行建模;
3. 掌握分类算法的原理,基于有监督的机器学习方法,训练文本分类器。
四、课程设计内容
1. 数据采集和预处理
a. 数据采集
①数据来源:
GitHub - SophonPlus/ChineseNlpCorpus: 搜集、整理、发布 中文 自然语言处理 语料/数据集,与 有志之士 共同 促进 中文 自然语言处理 的 发展。搜集、整理、发布 中文 自然语言处理 语料/数据集,与 有志之士 共同 促进 中文 自然语言处理 的 发展。 - GitHub - SophonPlus/ChineseNlpCorpus: 搜集、整理、发布 中文 自然语言处理 语料/数据集,与 有志之士 共同 促进 中文 自然语言处理 的 发展。![]() https://github.com/SophonPlus/ChineseNlpCorpus
https://github.com/SophonPlus/ChineseNlpCorpus
②数据选择:
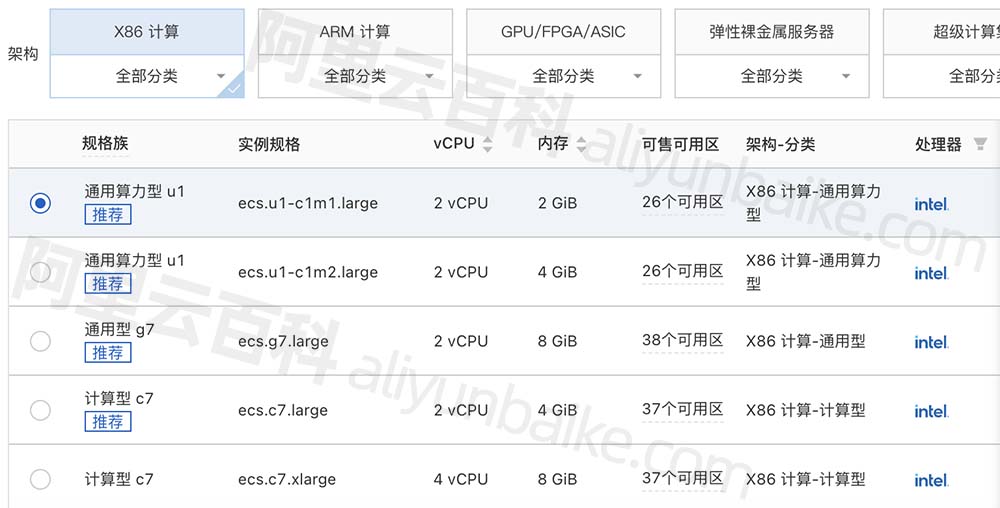
waimai_10k .csv为某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条,其中:
| 字段 | 说明 |
| label | 1 表示正向评论,0 表示负向评论 |
| review | 评论内容 |
b. 数据清洗
数据清洗是指去除数据中不需要的内容,例如空格、数字、特殊符号等。
data = data.fillna('') # 用空字符串填充缺失值
data = data.apply(lambda x: x.strip()) # 去除文本开头和结尾的空白字符
data = data.apply(lambda x: x.replace('\n', ' ')) # 将换行符替换为空格
data = data.apply(lambda x: re.sub('[0-9]', '', x)) # 去除数字
data = data.apply(lambda x: re.sub("[^a-zA-Z\u4e00-\u9fff]", ' ', x)) # 去除非汉字和字母的非空白字符c. 文本预处理:分词、去除停用词、移除低频词
①文本分词
研究表明中文文本特征粒度为词粒度远远好于字粒度,目前常用的中文分词算法可分为三大类:基于词典的分词方法、基于理解的分词方法和基于统计的分词方法。
②去停用词
停用词(Stop Word)是一类 既普遍存在又不具有明显的意义的词,在中文中例如:"吧"、 "是"、 "的"、 "了"、"并且"、"因此"等。这些词的用处太普遍,去除这些词,对于文本分类来说没有什么不利影响,相反可能改善机器学习效果。
③移除低频词
低频词就是在数据中出现次数较少的词语。此类数据实际上是具有一定的信息量,但是把低频词放入模型当中运行时,它们常常保持他们的随机初始状态,给模型增加了噪声。
# 文本预处理
data = data.apply(lambda x: ' '.join(jieba.cut(x))) # 使用jieba分词
# 停用词列表
stopwords = ["吧", "是", "的", "了", "啦", "得", "么", "在", "并且", "因此", "因为", "所以", "虽然", "但是"]
data = data.apply(lambda x: ' '.join([i for i in x.split() if i not in stopwords])) # 去停用词
# 移除低频词
word_counts = Counter(' '.join(data).split())
low_freq_words = [word for word, count in word_counts.items() if count < 3]
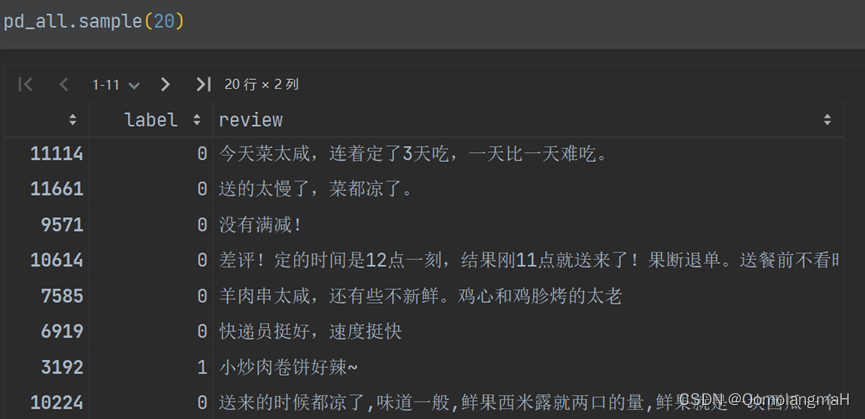
data = data.apply(lambda x: ' '.join([word for word in x.split() if word not in low_freq_words]))④实验结果
2. 特征提取和文本向量模型构建
文本分类任务非常重要的一步就是特征提取,在文本数据集上一般含有数万甚至数十万个不同的词组,如此庞大的词组构成的向量规模惊人,计算机运算非常困难。特征提取就是要想办法选出那些最能表征文本含义的词组元素 ,不仅可以降低问题的规模,还有助于分类性能的改善。
特征选择的基本思路是根据某个 评价指标独立地对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、卡方统计量等。
a. 词袋模型
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档。就是把整个文档集的所有出现的词都丢进“袋子”里面,然后无序去重地排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档 。
b. TF-IDF(本次实验中选取该方法)
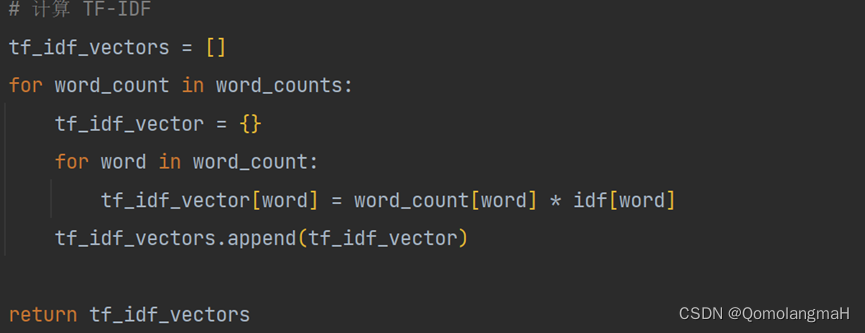
TF-IDF模型主要是用词汇的统计特征作为特征集,TF-IDF 由两部分组成:TF(Term frequency,词频),IDF(Inverse document frequency,逆文档频率)两部分组成,利用 TF 和 IDF 两个参数来表示词语在文本中的重要程度。

TF-IDF 方法的主要思路是一个词在当前类别的重要度与在当前类别内的词频成正比,与所有类别出现的次数成反比。可见 TF 和 IDF 一个关注文档内部的重要性,一个关注文档外部的重要性,最后结合两者,把 TF 和 IDF 两个值相乘就可以得到 TF-IDF 的值,即
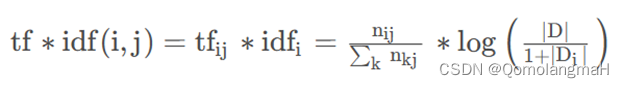
c. Word2Vec
Word2Vec是一种基于词向量的特征提取模型,该模型基于大量的文本语料库,通过类似神经网络模型训练,将每个词语映射成一个 定 维度的向量,维度在几十维到几百维之间,每个向量就代表着这个词语,词语的语义和语法相似性和通过向量之间的相似度来判断。
3. 分类模型训练
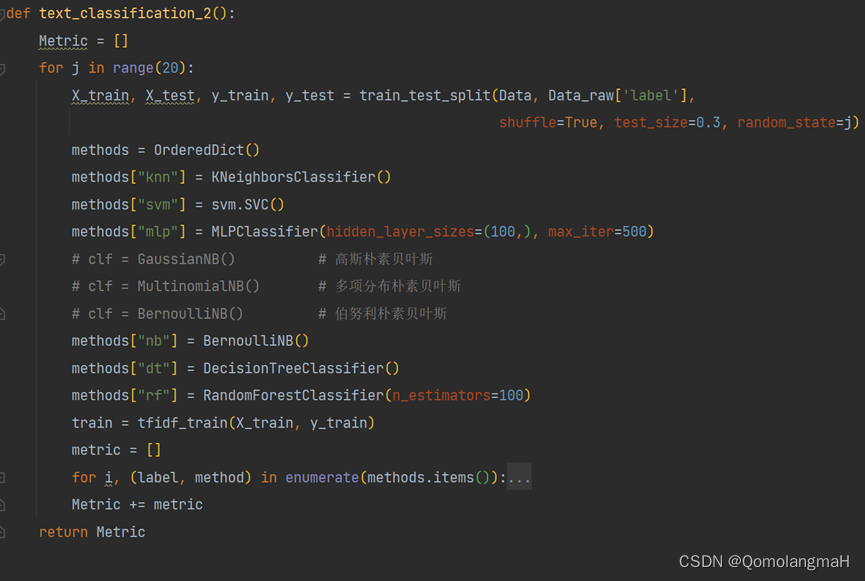
a. 数据划分
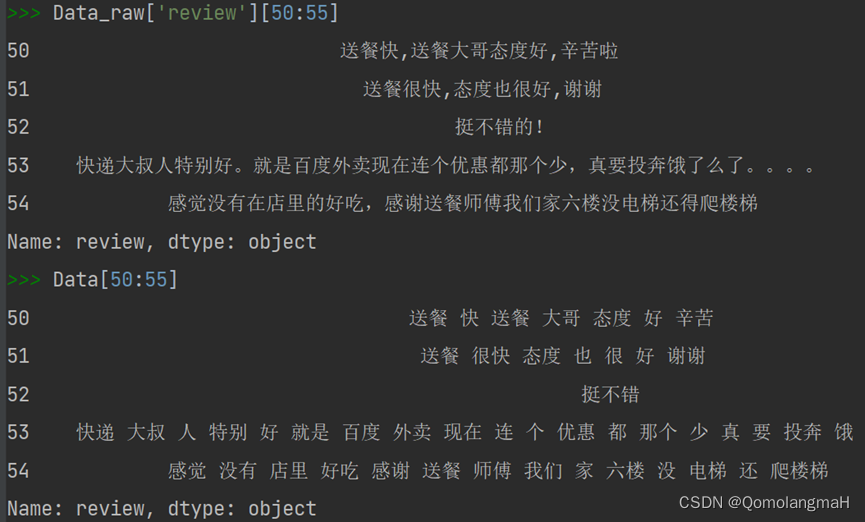
X_train, X_test, y_train, y_test = train_test_split(X, Data_raw['label'],shuffle=True, test_size=0.3, random_state=j)b. 模型训练
model = KNeighborsClassifier()
# model = svm.SVC()
# model = MLPClassifier(hidden_layer_sizes=(100,), max_iter=500)
# 训练模型
model.fit(tfidf_train, y_train)
# 测试模型
y_pred = model.predict(test_selected)c. 模型调参:网格搜索
网格搜索就是先定义一个超参数的取值范围,然后对这些超参数的所有可能组合进行穷举搜索。以svm为例
def svm_grid(X_train, y_train):
param_grid = [{
# 'C':
'kernel': ['linear', # 线性核函数
'poly', # 多项式核函数
'rbf', # 高斯核
'sigmoid' # sigmod核函数
# 'precomputed' # 核矩阵
], # 核函数类型,
'degree': np.arange(2, 5, 1), # int, 多项式核函数的阶数, 这个参数只对多项式核函数有用,默认为3
# 'gamma': np.arange(1e-6, 1e-4, 1e-5) # float, 核函数系数,只对’rbf’ ,’poly’ ,’sigmod’有效, 默认为样本特征数的倒数,即1/n_features。
# 'coef0' # float,核函数中的独立项, 只有对’poly’ 和,’sigmod’核函数有用, 是指其中的参数c。默认为0.0
}]
svc = svm.SVC(kernel='poly')
# 网格搜索
grid_search = GridSearchCV(svc,
param_grid,
cv=10,
scoring="accuracy",
return_train_score=True)
grid_search.fit(X_train, y_train)
# 最优模型参
final_model = grid_search.best_estimator_
return final_modeld. 模型评估:计算准确率、精确率、召回率、F1值、混淆矩阵
accuracy = metrics.accuracy_score(y_test, y_pred)
precision = metrics.precision_score(y_test, y_pred)
recall = metrics.recall_score(y_test, y_pred)
f1 = metrics.f1_score(y_test, y_pred)
confusion = metrics.confusion_matrix(y_test, y_pred)
metric.append([accuracy, precision, recall, f1])- 多次训练求出平均值:
五、实验结果分析
请下载本实验对应的代码及实验报告资源(其中实验分析部分共2页、787字)
包括完整实验过程分析(文本预处理、建模、分类器训练、手写TF-IDF参数分析等),以及分类器性能评估等。







![Vue3:proxy数据取值proxy[Target]取值](https://img-blog.csdnimg.cn/25751def82d94d66bd33bb0033f4e448.png)