安装模块
pip install requests
在jupyter notebook里使用Shift+Tab查看
requests
requests库的主要方法
| 方法 | 解释 |
|---|---|
| requests.requset() | 构造一个请求,支持以下各种方法 |
| requests.get() | 获取HTML的主要方法 |
| requests.head() | 获取HTML头部信息 |
| requests.post() | 向HTML网页提交POST请求 |
| requests.put() | 向HTML网页提交PUT请求 |
| requests.patch() | 向HTML提交局部修改的请求 |
| requests.delete() | 向HTML提交删除请求 |
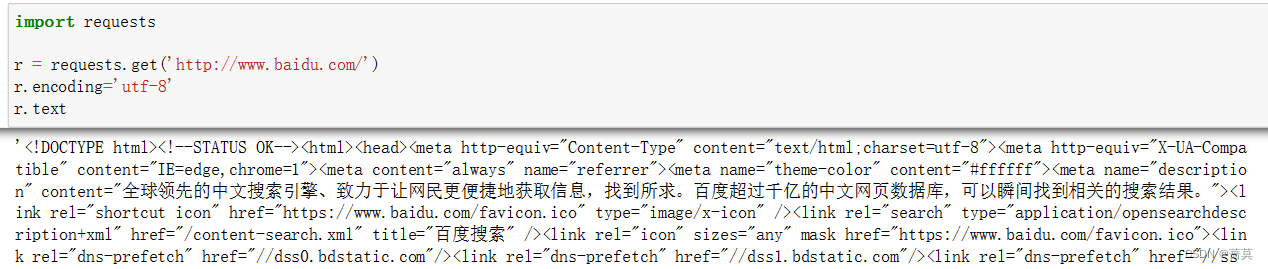
import requests
r = requests.get('http://www.baidu.com/')
r.encoding='utf-8'
r.text
.text属性可以获取以文本形式呈现出的网页源吗或其他结果
get和post请求
最常用
r = requests.get(url, params, **kwargs)
params:请求时需要提交的参数,字典格式(可选)
**kwargs参数
| 参数名称 | 描述 |
|---|---|
| params | 字典或字节序列,作为参数加到URL中 “?key1=value1&key2=value2” |
| data | 字典或文件对象,重点作为向服务器提供或提交资源时提交。 与params不同的是,data提交的数据不放在URL链接里,而是放在 与URL链接对应位置的地方作为数据来储存(可以接收一个字符串对象) |
| json | json格式的数据,可作为内容部分向服务器提交 kv={‘key1’:‘value1’} r=requests.request(‘POST’,‘https://httpbin.org/’,json=kv) |
| headers | 字典,是HTTP的相关词,对应了某个向URL访问时发起的HTTP的头字段 可以用该字段定义HTTP访问的HTTP头,来模拟任何想模拟的浏览器对URL发起访问 |
| cookies | 字典或CookieJar,从HTTP中解析cookie |
| auth | 元组,支持HTTP认证功能 |
| files | 字典,向服务器传输文件时使用的字段 fs={‘files’: open(‘data.txt’,‘rb’)} |
| timeout | 设定超时时间,超时产生timeout异常 |
| proxies | 字典,设置访问代理服务器 |
| allow_redirects | 开关,表示是否允许对URL进行复位,默认True |
| stream | 开关,指是否对获取内容进行立即下载,默认True |
| verify | 开关,用于认证SSL整数,默认True |
| cert | 用于设置保存本地SSL证书路径 |
发起请求后,被请求的服务器将会返回一个包含 服务器资源的response对象
响应对象内容
| 属性 | 说明 |
|---|---|
| status_code | HTTP请求的返回状态,200表示请求成功 |
| text | HTTP响应内容的str形式,即返回页面的内容 |
| encoding | 从HTTP Header中猜测的响应内容编码方式 |
| apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| content | HTTP响应内容的二进制形式 |
r = requests.get('https://httpbin.org/')
r.status_code # 200
r.encoding # 'utf-8'
r.apparent_encoding # 'Windows-1252'
访问目标网站,可以通过data或json方式传递参数
data = {'key1':'value1','key2':'value2'}
r = requests.get(url,data=data)
r.text
requests.post()一般用于表单提交,向指定url提交数据,可提交str、dict、文件等数据
# 向url post一个字典
payload = {'name':'zhangsan','age':'34'}
r = requests.post('http://httpbin.org/post',data=payload)
print(r.text)
# 向url post一个str,自动编码为data
r = requests.post('http://httpbin.org/post',data='helloworld')
print(r.text)

requests请求HTTPS协议的网址时,报错或得不到数据
一般是由SSL证书引起的,可以在使用requests的时候多加一个verift=False参数来忽略SSL验证
import requests
r = requests.get('https://fanyi.baidu.com/',verify=False)
r.text