6.2.3.1 根页面万年不动窝
B+ 树的形成过程是这样的:
- 每当为某个表创建一个 B+ 树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个 根节点 页面。最开始表中没有数据的时候,每个 B+ 树索引对应的 根节点 中既没有用户记录,也没有目录项记录。
- 随后向表中插入用户记录时,先把用户记录存储到这个 根节点 中。
- 当 根节点 中的可用空间用完时继续插入记录,此时会将 根节点 中的所有记录复制到一个新分配的页,比如 页a 中,然后对这个新页进行 页分裂 的操作,得到另一个新页,比如 页b 。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到 页a 或者 页b 中,而根节点 便升级为存储目录项记录的页。
要注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建立一个索引,那么它的 根节点 的页号便会被记录到某个地方,然后凡是 InnoDB 存储引擎需要用到这个索引的时候,都会从那个固定的地方取出 根节点 的页号,从而来访问这个索引。
6.2.3.2 内节点中目录项记录的唯一性
我们知道 B+ 树索引的内节点中目录项记录的内容是 索引列 + 页号 的搭配,但是这个搭配对于二级索引来说有点儿不严谨。还拿 index_demo 表为例,假设这个表中的数据是这样的:
| c1 | c2 | c3 |
| 1 | 1 | 'u' |
| 3 | 1 | 'd' |
| 5 | 1 | 'y' |
| 7 | 1 | 'a' |
如果二级索引中目录项记录的内容只是 索引列 + 页号 的搭配的话,那么为 c2 列建立索引后的 B+ 树应该长这样:
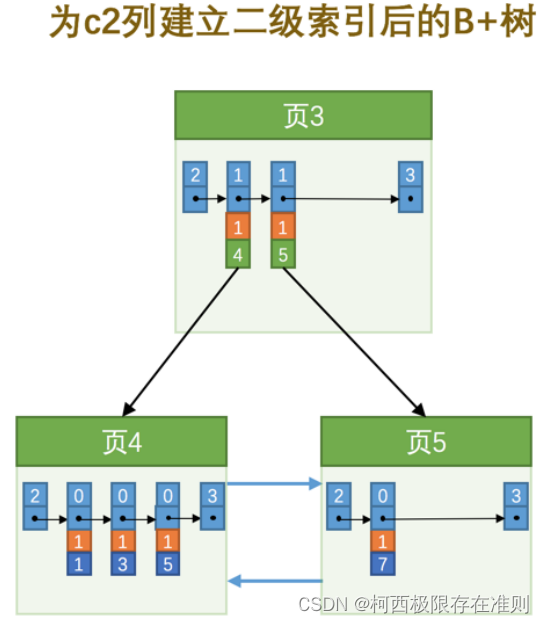
为了让新插入记录能找到自己在那个页里,我们需要保证在B+树的同一层内节点的目录项记录除 页号 这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
也就是我们把 主键值 也添加到二级索引内节点中的目录项记录了,这样就能保证 B+ 树每一层节点中各条目录项记录除 页号 这个字段外是唯一的。
6.2.3.3 一个页面最少存储2条记录
B+树本质上就是一个大的多层级目录,每经过一个目录时都会过滤掉许多无效的子目录,直到最后访问到存储真实数据的目录。InnoDB 的一个数据页至少可以存放两条记录。
6.2.4 MyISAM中的索引方案简单介绍
InnoDB 中索引即数据,也就是聚簇索引的那棵 B+ 树的叶子节点中已经把所有完整的用户记录都包含了,而 MyISAM 的索引方案虽然也使用树形结构,但是却将索引和数据分开存储:
- 将表中的记录按照记录的插入顺序单独存储在一个文件中,称之为 数据文件 。这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少记录就成了。我们可以通过行号而快速访问到一条记录。但是在插入数据的时候并没有刻意按照主键大小排序,所以我们并不能在这些数据上使用二分法进行查找。
- 使用 MyISAM 存储引擎的表会把索引信息另外存储到一个称为 索引文件 的另一个文件中。 MyISAM 会单独为表的主键创建一个索引,只不过在索引的叶子节点中存储的不是完整的用户记录,而是 主键值 + 行号 的组合。也就是先通过索引找到对应的行号,再通过行号去找对应的记录!
- 这一点和 InnoDB 是完全不相同的,在 InnoDB 存储引擎中,我们只需要根据主键值对 聚簇索引 进行一次查找就能找到对应的记录,而在 MyISAM 中却需要进行一次 回表 操作,意味着 MyISAM 中建立的索引相当于全部都是 二级索引 !
- 如果有需要的话,我们也可以对其它的列分别建立索引或者建立联合索引,原理和 InnoDB 中的索引差不多,不过在叶子节点处存储的是 相应的列 + 行号 。这些索引也全部都是 二级索引 。