前言:Hello大家好,我是小哥谈。本门课程将介绍人工智能相关概念,重点讲解机器学习原理机器基本算法(监督学习及非监督学习)。使用python,结合sklearn、Pycharm进行编程,介绍iris(鸢尾花)数据集,建立AI模型并评估其表现。本节课主要面向刚毕业高中生、大学生、硕士生等对AI行业充满向往的同学们!🌈
 前期回顾:
前期回顾:
Python实现机器学习(上)— 基础知识介绍及环境部署
目录
🚀1.数据预处理
💥💥1.1 iris数据集介绍
💥💥1.2 iris数据加载及展示
🚀2.模型训练
🚀3.模型评估

🚀1.数据预处理
💥💥1.1 iris数据集介绍
Iris (鸢尾花)数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含3类共150条记录,每类各50个数据,每条记录都有4项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。🌴
通俗地说,iris数据集属于监督式学习的应用,是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征,我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。🌱
采用iris数据集的原因主要是该数据集简单而且有代表性。🍄

💥💥1.2 iris数据加载及展示
具体代码如下:
# iris数据加载
from sklearn import datasets
iris = datasets.load_iris()
# 展示iris数据
print(iris.data)
print(iris.feature_names)
print(iris.target_names)
# 确认数据类型
print(type(iris.data))
# 确认维度
print(iris.data.shape)运行结果如图所示:
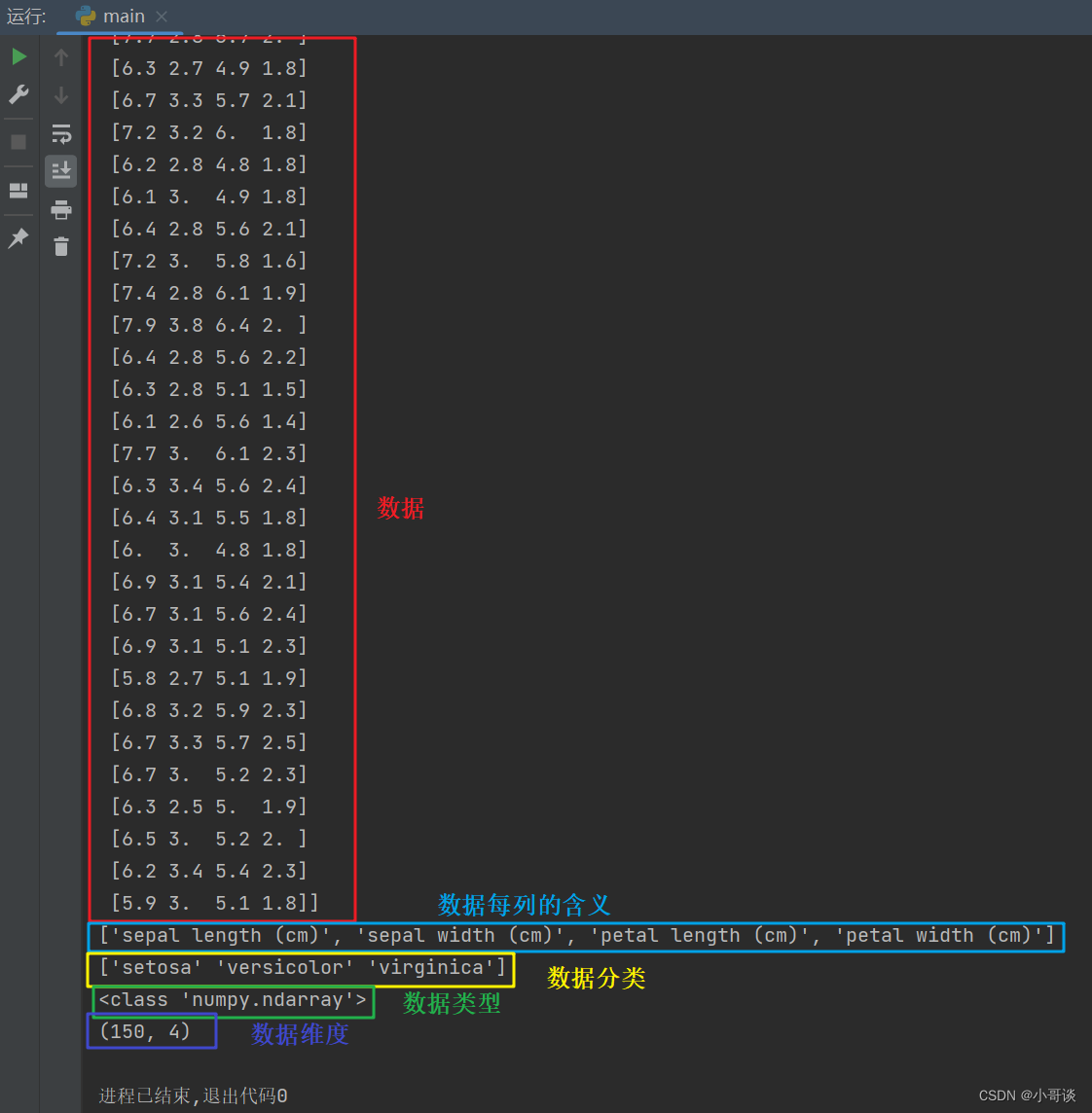
结果说明:
🍀(1)每行数据为一个样本;
🍀(2)每行数据代表不同样本同一属性下对应的数值;
🍀(3)每列数据对应的属性值(图中最后一行);
该项目归根结底为一个分类问题,是对应结果为类别(非连续性)的监督式学习问题,每个预测的数值即是结果数据(或称为:目标、输出、标签)。
进行数据预处理的四个关键点:
🍀(1)区分开属性数据和结果数据;
🍀(2)属性数据和结果数据都是可量化的;
🍀(3)运算过程中,属性数据和结果数据的类型都是Numpy数组;
🍀(4)属性数据和结果数据的维度是对应的(由结果可知,数据为150行4列)。
🚀2.模型训练
本项目的本质为一个分类问题,即根据数据集目标的特征或者属性,划分到已有的类别中。常用的分类算法有:K近邻算法(KNN)、逻辑回归、决策树、朴素贝叶斯等。🍃
本项目采用的是KNN算法。KNN(k-NearestNeighbor)又被称为近邻算法,它的核心思想是:物以类聚,人以群分。✅
假设一个未知样本数据x需要归类,总共有ABC三个类别,那么离x距离最近的有k个邻居,这k个邻居里有k1个邻居属于A类,k2个邻居属于B类,k3个邻居属于C类,如果k1>k2>k3,那么x就属于A类,也就是说x的类别完全由邻居来推断出来。🌳
具体代码如下:
# 确认维度
#print(iris.data.shape)
# 样本数据与结果分别赋值到“x”和“y”
x = iris.data
y = iris.target
# 确认样本和输出数据维度
#print(x.shape)
#print(y.shape)
# 建模四步骤
"""
1.调用需要使用的模型类
2.模型初始化(创建一个模型实例)
3.模型训练
4.模型预测
"""
# 创建实例
knn = KNeighborsClassifier(n_neighbors=1)
# 模型训练
knn.fit(x,y)
# 模型预测
print(knn.predict([[1,2,3,4]]))
运行结果如图所示:
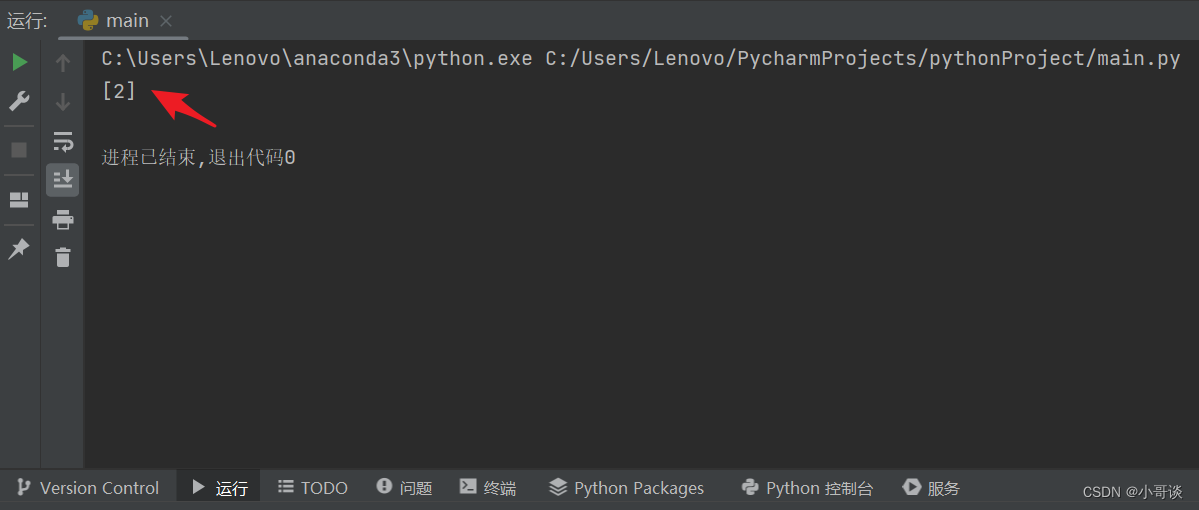
结果表示第3类。🎈🎈🎈
🚀3.模型评估
在模型评估的时候,必须保证已将数据分为训练集和测试集,使用训练集数据进行模型的训练,使用测试集数据进行预测,从而评估模型表现。✅
分离训练集和测试集的作用:
🍀(1)可以实现在不同的数据集上进行模型训练和预测;
🍀(1)建立数学模型的目的是对新数据的预测,基于测试数据计算的准确率能够更有效地评估模型表现。
具体代码如下所示:
# iris数据加载
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
# 展示iris数据
#print(iris.data)
#print(iris.feature_names)
#print(iris.target_names)
# 确认数据类型
#print(type(iris.data))
# 确认维度
#print(iris.data.shape)
# 样本数据与结果分别赋值到“x”和“y”
x = iris.data
y = iris.target
# 确认样本和输出数据维度
#print(x.shape)
#print(y.shape)
# 建模四步骤
"""
1.调用需要使用的模型类
2.模型初始化(创建一个模型实例)
3.模型训练
4.模型预测
"""
# 创建实例
#knn = KNeighborsClassifier(n_neighbors=1)
# 模型训练
#knn.fit(x,y)
# 模型预测
#print(knn.predict([[1,2,3,4]]))
knn5 = KNeighborsClassifier(n_neighbors=5)
knn5.fit(x,y)
y_pred = knn5.predict(x)
#print(y_pred)
#print(y_pred.shape)
# 准确率:正确预测的比例
# 用于评估分类模型的常用指标
# 准确率计算
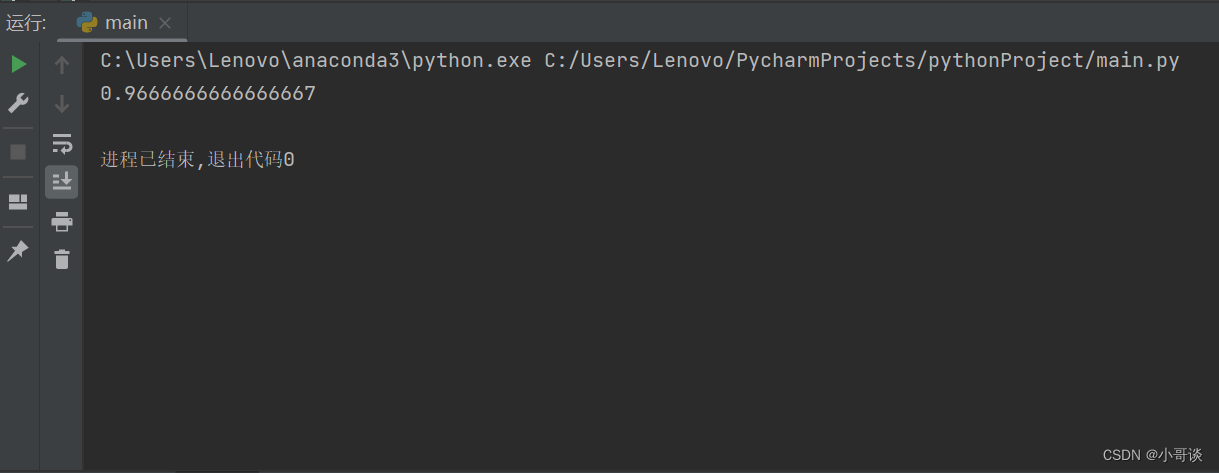
print(accuracy_score(y,y_pred))运行结果如图所示:
通过以上案例可知,人工智能就其本质而言,是机器对人的思维信息过程的模拟,让它能像人一样思考。根据输入信息进行模型结构、权重更新,以实现最终优化。🌟🌟🌟