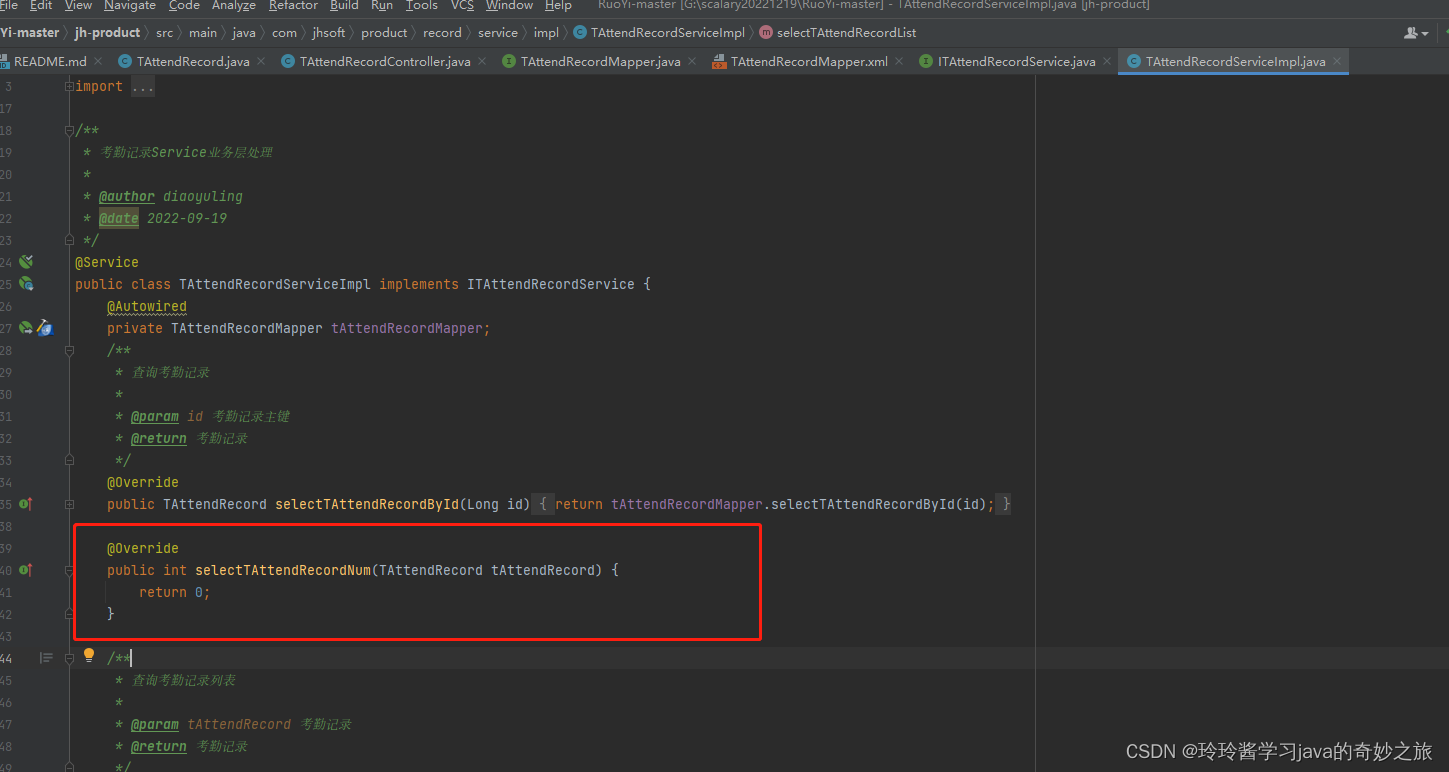
K近邻算法通过计算被分类对象与训练集对象之间的距离,确定其k个临近点,然后使用这k个临近点中最多的分类作为分类结果。

如上图,当K=3时,它会被分类为 Class B。因为K=3时,3个临近点里有2个是B类的。
同理,K=7时它会被分类为 Class A,因为K=7时,7个临近点里4个是A类的。
KNN算法一个比较不好的缺点是K值由人主观决定。因为这样有一个问题,你取的K值不同,对于某些点的分类结果就不同,比如上图分别取k=3和k=7会得到不同的结果。
K值不能取太小,比如K=1的情况,此时容易被错误的样本干扰,造成过拟合等问题。当然,K值也不能取太大,越大分类效果越差。

如上图所示,当k=1的时候,决策边界变得非常不光滑,换句话说,模型的决策规则非常复杂,容易造成过拟合。
简而言之:k越小,模型越容易过拟合;k越大,越容易欠拟合。
所以K值应该取一个不大不小的奇数
![C. The Third Problem(MEX,思维,组合数)[Codeforces Round #804 (Div. 2)]](https://img-blog.csdnimg.cn/288fa3c217684ccaa6e1c3a830f3fa79.png)