作者:田寄远
JCQ 全名 JD Cloud Message Queue,是京东云自研、具有 CloudNative 特性的分布式消息中间件。 JCQ 设计初衷即为适应云特性的消息中间件;具有高可用、数据可靠性、副本物理隔离、服务自治、健康状态汇报、少运维或无运维、容器部署、弹性伸缩、租户隔离、按量付费、云账户体系、授权等特性。
演进过程
2017 年中开始开发 JCQ 1.0 版本,2018 年 11 月正式 GA 上线对外售卖,1.0 版本中 Topic 受限于单台服务器限制,满足不了用户超大规格 topic 的需求。
2019 年 4 月 JCQ 2.0 正式上线,主要新增特性是 topic 扩缩容能力、热点 Topic 在 Broker 间的负载均衡、热点 Broker 的流量转移。
2019 年 7 月 JCQ 做了一次大的架构演进 —— 计算存储分离,大版本号为 JCQ 3.0, 于 2019 年底上线。计算存储分离对架构带来了比较明显的好处,解决了日常遇到许多的痛点问题。下文详细介绍此次演进带来的好处及解决的痛点问题。
升级影响范围尽可能小
在 JCQ2.0 中计算模块与存储模块处于同一个进程,升级计算模块势必将存储模块一起升级。而存储模块重启是比较重的动作,需要做的工作有:加载大量数据、进行消息数据与消息索引数据比对、脏数据截断等操作。往往修复计算模块一个小的 Bug,就需要做上述非常重的存储模块重启。而在现实工作中,大部分升级工作都是由于计算模块功能更新或 Bugfix 引起的。
为了解决这个问题, JCQ3.0 将计算模块、存储模块独立部署,之间通过 RPC 调用。各自升级互不影响。如下图所示:

计算节点 Broker 只负责生产消息、推送消息、鉴权、认证、限流、拥塞控制、客户端负载均衡等业务逻辑,属于无状态服务。比较轻量,升级速度快。
存储节点 Store 只负责数据写入、副本同步、数据读取。因为业务逻辑简单,功能稳定后,除优化外基本无需改动,也就无需升级。
成本降低
JCQ 是共享消息中间件,用户申请的是不同规格 TPS 的 Topic,并不感知 cpu、memory、disk 等硬件指标。 所以,JCQ 服务方需要考虑如何合理的使用这些硬件指标。
JCQ 是容器部署,有多种类型的组件,这些组件对硬件的需求也是多样化的,其中对资源消耗最多的是计算模块和存储模块。在 JCQ2.0 版本计算模块和存储模块部署在一起,选择机型时要兼顾 cpu、memory、disk 等指标,机型要求单一,很难与其他产品线混合部署。即使是同一资源池,也存在因为调度顺序,造成调度失败的情况。如一台机器剩余资源恰好能调度一个需要大规格磁盘的 A 容器,但是因为 B 容器先被调度到这台机器上,剩余资源就不够创建一个 A 容器,那这台机器上的磁盘就浪费了。
JCQ3.0 后,计算节点 Broker,与存储节点 Store 独立部署。这两个组件可以各自选择适合自己业务的机型,部署在相应资源池中;最终,可以做到与其他产品混合部署,共用资源池水位,而不用独自承担资源水位线。
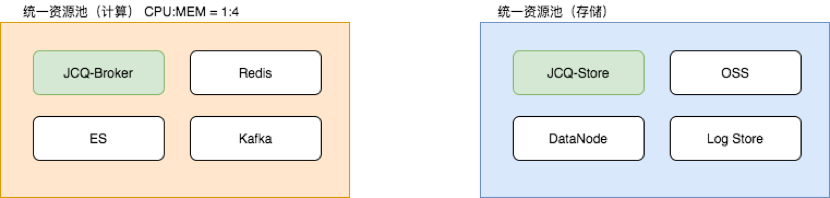
架构改进带来的成本降低
JCQ3.0 中计算节点 Broker 是无状态服务,主从切换比较轻量,能在秒级完成故障转移;且部署时考虑了物理设备反亲和,如跨 Rack、跨 AZ 部署。所以,可以在可用性、资源成本之间做一定的权衡;如可以使用 M:1 方式做高可用冷备,而不必 1:1 的比例高可用冷备,进而达到节省硬件资源的目的。
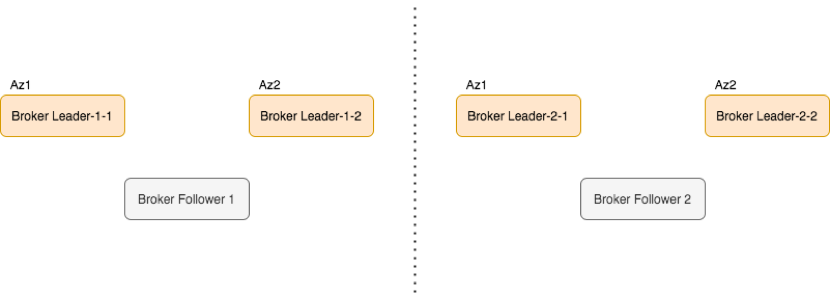
解决 Raft 性能问题
JCQ 1.0 设计之初就采用 Raft 算法,来解决服务高可用、数据一致性的问题。Message Log 与 Raft Log 有很多共同的特性,如顺序写、随机读、末端热数据。所以,直接用 Raft Log 当成 Message Log 是非常合适的。
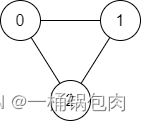
在 JCQ 演进中我们也发现了 Raft 本身的一些性能问题,如顺序复制、顺序 commit、有的流程只能用单线程处理等限制。针对这些问题,最直接有效的办法就是扩展 Raft 的数目、扩展单线程流程数目,在一定数量级内,并发能力随着 Raft Group 数目的增长,呈线性增长关系,称之 MultiRaft,如下图所示。
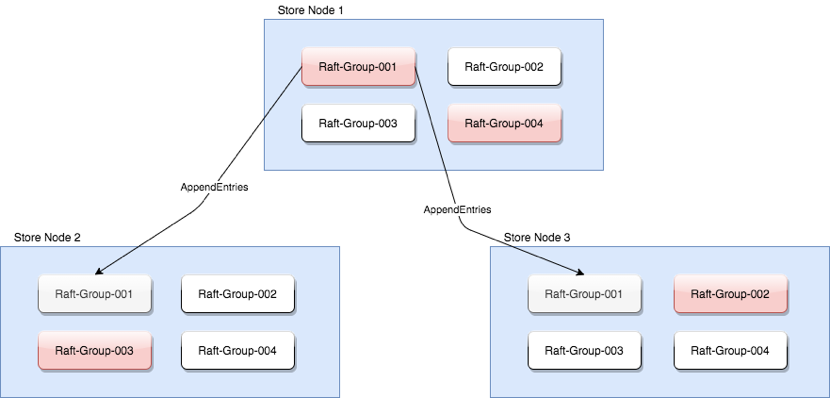
上图中,每个 StoreNode 节点是一个独立进程,内部有四组逻辑 RaftGroup(橙色的节点为 RaftGroup 的 Leader),各组 RaftGroup 之间是并行关系,可以做到 Group 间并行复制、并行 commit。
由于大量使用了 NIO,这些 RaftGroup 之间可以共享通信线程池,扩充 RaftGroup 数目并不会带来线程资源线性增长的问题。
快速故障恢复、轻量的负载均衡
在 JCQ3.0 中,Broker 为轻量的无状态服务,在主从切换、故障恢复方面相对 2.0 更为轻量,本身能更快的恢复对外服务能力。
同时,Broker 将 Producer、Consumer 的连接请求,抽象为 PubTask 和 SubTask,后文统称为 Task。Task 的概念非常轻量,仅描述 Client 与 Broker 的对应关系,由元数据管理器 Manager 统一调度、管理。转移 Task 只需要修改 Task 的内容,客户端重新连接新 Broker 即可。
一般来说,Broker 的主要瓶颈在于网络带宽。Broker 定期统计网络入口流量与出口流量,并上报给管理节点 Manager。Manager 根据入口流量、出口流量与带宽阈值进行裁决,发现超过阈值后,通过一定策略将相应的 Task 转移到较小负载的 Broker 上,并通知相应的 Producer 与 Consumer;Producer 与 Consumer 收到通知后,重新获取 Task 的路由信息,自动重连到新的 Broker 继续进行生产、消费。
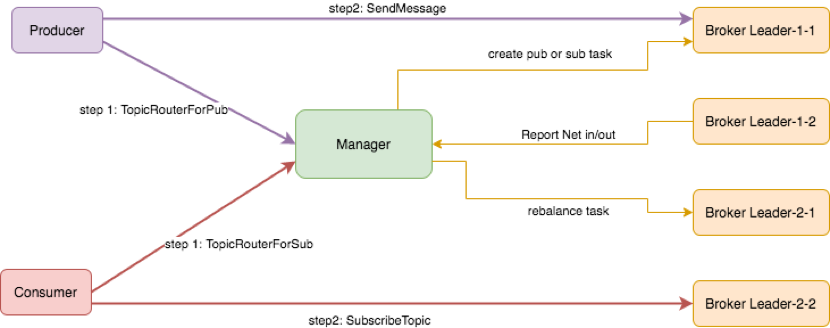
高扇出需求
设想一个场景,有一个大规格的 topic,创建了 n 个消费组。消费总 TPS 是生产总 TPS 的 n 倍。增加消费组,会导致消费总 TPS 线性增长。到达一定消费组规模后,单 Broker 由于网卡带宽的原因,无法满足这种高扇出的场景。单服务器是无法解决这个问题。
在 JCQ 3.0 可以将这些不同的消费组对应的 SubTask 分散到若干个 Broker 上,每个 Broker 负责一部分 SubTask,单 Broker 从 Store 预读消息,将数据推送给 Consumer。这样多个 Broker 共同完成所有消费组的消息流量,协作一起提供高扇出的能力。
支持多种存储引擎
消息中间件很大的特点是:大部分场景下,热数据都在末端,而回溯几天之前的消息这个功能是不常用的。所以,就有冷热数据之分。
JCQ 计算节点设计了一层存储抽象层 Store Bridge 可以接入不同的存储引擎,可以接入 Remote Raft Cluster,或者分布式文件系统 WOS、或者 S3。甚者可以将冷数据定期从昂贵的本地盘卸载到廉价的存储引擎上。
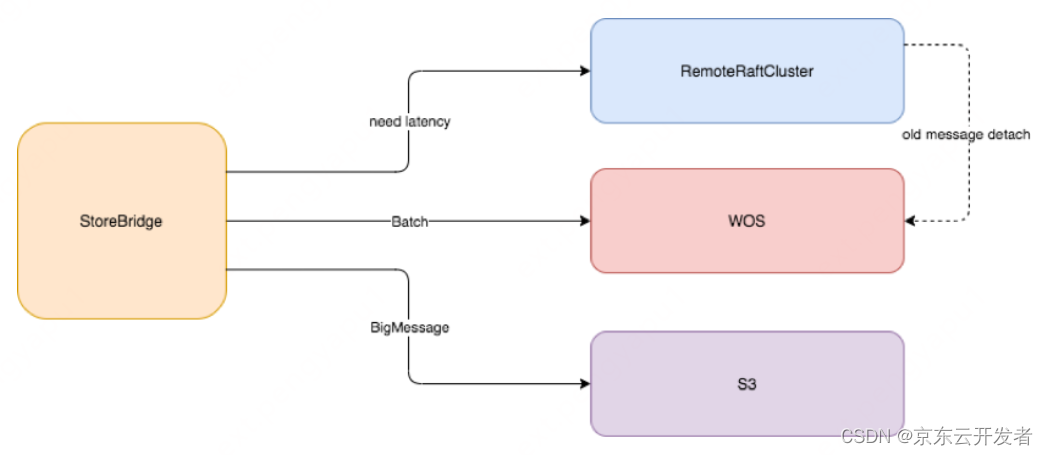
副作用
相对于 JCQ2.0,计算节点与存储节点之间的通信方式,由接口调用变为 RPC 调用,在延迟方面会有一定损失。经过测试,绝大部分延迟都在 1ms 左右,在大多数场景下 牺牲 1ms 左右的延迟并不会给业务带来太大的影响。
后续发展规划
JCQ 后续会主要在多协议兼容,按需自动扩缩容、云原生等方面演进。
多协议兼容
JCQ 协议为私有协议,在引导用户迁移方面有比较大的障碍。后续会抽离 JCQ Kernel,外部提供不同的协议接入层。方便用户从其他 MQ 接入 JCQ。目前已兼容 RocketMQ 协议,SQS 协议
自动扩缩容
JCQ 是共享消息中间件,但缺少 Serverless 自动扩缩容的特性。每逢大促,如 618,双 11,服贸会等重要活动。业务方很难预估自己的业务量峰值,或者估计不足,会造成 topic 限流等问题。如在保证 JCQ 服务本身能力情况下,能做到 topic 灵活的自动扩缩容,将对用户有极大的帮助,起到真正的削峰填谷作用。
云原生
支持在 kubernetes 环境部署与交付,提供原生的 Operator,能够快速的部署在 k8s 环境中,更好的交付私有云、混合云项目。





![[附源码]计算机毕业设计Python电商小程序(程序+源码+LW文档)](https://img-blog.csdnimg.cn/47e2a40a8e284b9dbc01cd30b64133e7.png)