【Y 码力】: 是由 YMatrix 研发团队负责的栏目,栏目专注介绍数据库的底层原理、实现细节,以及YMatrix 研发团队不断探索中的工程实践。我们希望栏目能够成为数据库技术的显微镜,同时也能够成为大家了解 YMatrix 研发团队的一扇窗。
摘要
谈到 WAL ,我们总是第一个想到故障恢复,除了能够提供宕机时的数据恢复能力,WAL 其实也被设计用来提高数据库的性能。本文会从基本原理出发,介绍 WAL 是如何提高数据库的性能的。
作者:王任远|YMatrix MXUI 研发工程师
1. WAL 是什么?
WAL 全称是 Write ahead log。顾名思义,WAL 首先是一个日志(log),作为操作日志,记录了数据库中对数据的操作;另外日志的写入发生在数据写入之前,也就是说,任何一个对数据的操作,会由 WAL 首先记录下来,然后数据才会被记录到相应的文件中。
2. WAL 让写入更复杂?
我们先来简单讨论数据写入时的逻辑:
当没有 WAL 的时候,任何写入的的过程可以被朴素的认为只包含 1 步,每次插入/更新都是一个完整的简单操作:
- 将更新后的数据直接保存至磁盘
当 WAL 引入后,变成了3步:
- 操作日志保存到硬盘
- 更新后的数据写入内存(读取时,若一条数据在内存中存在,则会优先读取内存中的数据,而不是硬盘上的内容)
- *在恰当的时机(checkpoint) ,将内存中的最新数据存储至磁盘,并清空之前的日志以及内存

该流程仅为演示基本逻辑步骤,在数据库内核的实现中,整个流程的实现要复杂的多。
扩展阅读;
- 英文视频介绍:https://www.youtube.com/watch?v=h9n5taRDvfE
- The Internals of PostgreSQL:https://www.interdb.jp/pg/pgsql09.html
看起来写入的过程由一步变成三步,变得更加复杂了,可是我们为什么说 WAL 能够提高性能呢?
3. 顺序读写 VS 随机读写
数据库中的数据是会被频繁操作的,因此,我们描述的的写入过程会被频繁的重复,在这个讨论前提下,WAL 能够带来磁盘 IO 操作的优化,从而带来性能的明显提升。
首先关于磁盘的写入过程,我们先有一个基本的认知:
- 先寻址,再写入
硬盘好比一个作业本,如果我们需要在某一页写入一行内容,那么一共分为两步:
- 翻到指定的页
- 写入内容
我们考虑两种不同的行为:
A. 如果我们需要在其中的 1, 100,1000页上添加内容,我们执行的过程是:
- 翻到对应的页码
- 添加1行内容
- 重复1、2 三次
B. 如果我们仅需要在最后一页上顺序添加三行,那么我们只需要:
- 翻到对应的页码
- 添加3行内容
由于对于一个数据库内会存在很多张表,那么当数据库更新表数据时,实际写入的位置,会根据表的不同对应到不同的磁盘位置,行为近似于 A;而写入 WAL 的过程,由于总是按照时间在末尾追加,其行为近似于 B。
A 对应的随机读写,而 B 对应顺序读写。顺序读写明显减少了“翻页”操作,因此从原理上,性能远高于随机读写。
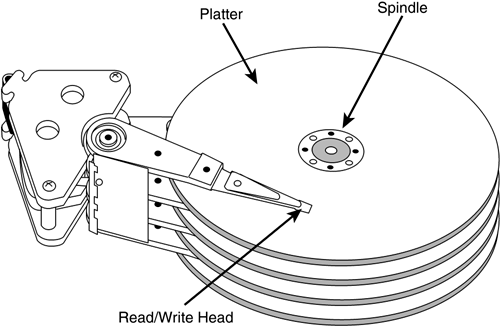
在机械硬盘时代,寻址意味着着磁盘(platter) 的旋转,使磁头(read/write head) 对应到数据所在的准确位置,是一个物理操作,其开销可想而知。而每次读写一个块时,首先就需要通过这些物理操作找到正确位置,然后才能进行进一步的读写,传输工作,因此,顺序读写相比随机读写减少了。

在 SSD 时代,由于机械部件的消失,寻址时不再需要移动磁盘、磁头,这就使得每次读写操作时,“响应速度” 大幅提升,从而大幅提升了随机读写的性能,但从上图的测评我们仍然可以看到,顺序读写的速度仍然明显高于随机读写,当面对密集读写操作时,性能差异就会变得更加“肉眼可见”。
4. 减少随机读写
当没有 WAL 时:
由于数据存储在硬盘不同的位置,可能每写一条,就要重新寻址,开销大。
当引入了 WAL:
- 由于 WAL 是日志,根据时间不断追加,因此属于硬盘友好的顺序写入,开销小。
- 更新后的数据先写入内存(脏页),以保证数据立即可用,开销很小。
此时一直都没有触发过写磁盘的操作,因此用户可以感知到明显的性能提升。
最后,要保证新数据被持久化,执行。
3. *在恰当的时机存储至磁盘(刷盘),
完成后记录删除这个时间点之前的
WAL 文件以循环利用空间,开销大。
因此,我们只要精细的控制步骤 3,让步骤 3 以较低的频率发生。
- 积攒够一批再写,降低执行次数。
- 在刷盘过程中,将一批数据合理安排,大多数时候也能明显的降低随机写入,从而提升整体的性能。
思考:
问:数据最终都要落盘,如果内存里存了多个表的不同数据,那么刷盘时还是可以认为是随机写入,那么岂不是性能没有什么变化?
答:如果说我们添加内容的页数分别为 1,10,1,那么写入的时候就可以先写 2 个页码 1 的,再写页码 10 的,这样就减少了一次寻址, 也就是少了一次随机写入,从而提升了性能。
5. 刷盘的最佳策略
如上面所介绍的,刷盘时机的控制策略,会明显影响数据库的性能表现:
- 如果刷盘间隔太短,那么就起不到降低硬盘写入操作次数的效果。
- 如果刷盘间隔太长,又可能会导致 WAL 积累了太多操作,占用硬盘空间,同时脏页占用大量的内存,执行刷盘时由于要写入的数据量巨大从而导致占用大量硬盘带宽,影响其他操作。
YMatrix 中,刷盘操作的时机,主要由两种机制共同作用。
- 周期性触发:检查两次 checkpoint 操作的时间间隔,超过则刷盘。
- 阈值触发:发现 WAL 日志的大小达到阈值时,超过则刷盘。
运维思考:
- 周期性触发频率由参数 checkpoint_timeout 控制,默认值为 5 分钟。
- 阈值触发由参数 max_wal_size 控制,默认值为 4GB。
- 数据库进行启动/停止时也会进行刷盘操作。
两种机制结合,就可以保证:
- 负载正常时数据被定期被存储至磁盘。
- 负载高的数据能及时存储避免 WAL 和脏页积攒过多。
运维参考:
通过命令 CHCEKPOINT 可以立即触发刷盘。
-bash-4.2$
-bash-4.2$ psql postgres
psql (12)
Type "help" for help.
postgres=# CHECKPOINT;
CHECKPOINT小知识:
- WAL 在不同数据库中有不同的名字,在mysql 的 innodb 引擎中被称之为 Redo Log。
- WAL 由于完整保存了数据的操作记录,可以用来在多个集群或数据库系统间同步数据,通常 CDC (Change Data Capture) 方案(如 Flink 等)都使用他来同步数据。
- 当我们提到 xlog 的时候,指的即是WAL。上古时期,PostgreSQL 一部分地方(比如一些目录,参数和方法)使用了xlog 这个名称,到 PostgreSQL 10时,社区付出了大量努力将命名统一为 WAL。
附录
1. SSD的随机读写和顺序读写:https://www.zhihu.com/question/47544675/answer/2924069738
2. 三星970 PRO 1TB M.2 SSD评测:https://expreview.com/61492-2.html
3. Afraid of SSD? Will SSD kill the profession of database and SQL tuning specialists? https://use-the-index-luke.com/blog/2013-07/afraid-of-ssd
4. Wal and Xlog:https://www.enterprisedb.com/blog/wal-and-xlog
本文为 YMatrix 原创内容,未经允许不得转载。
欲了解更多超融合时序数据库相关信息,请访问 “YMatrix 超融合数据库”