目标:了解计算机中一些必备的尝试知识,了解常见名词背后的意义
1.python的运行方式
- 交互式运行
- 脚本式运行
2.进制
2.1 进制的转换
计算机中底层的所有数据都是0101010101的形式存在的
八进制无法直接转为2进制
- 十进制转其他进制
bin(25) # 10进制转为2进制
oct(25) # 10进制转为8进制
hex(25) # 10 进制转为16 进制
输出的结果都是字符串类型的结果
- 其他进制转为十进制
int('0b11001', base=2) 2进制转为10进制
int('0o31', base=8) 8进制转为10进制
int('0x19', base=16) 16进制转为10进制
由于计算机中本质上所有的东西都是二进制进行存储和操作的,所以产生了计算机的单位。
- b(bit),位
1,1位
10,2位
111,3位
1001,4位
- B(byte),字节
8位数是一个字节
10001000,1个字节
10001000 10001000 2个字节
- KB(kilobyte),千字节
1024个字节=1千字节
1kb=1024B=1024*8b
- M(Megabyte)兆
1024KB = 1M = 1024*1024 B 1024*1024*8 b
G(Gigbyte),千兆
1G = 1024 M =1024*1024KB = 1024*1024*1024 B = 1024*1024*1024*8 b
- T (Terabyte),万亿字节
1T = 1024G
4.编码
编码,文字和二进制之间的一个对照表
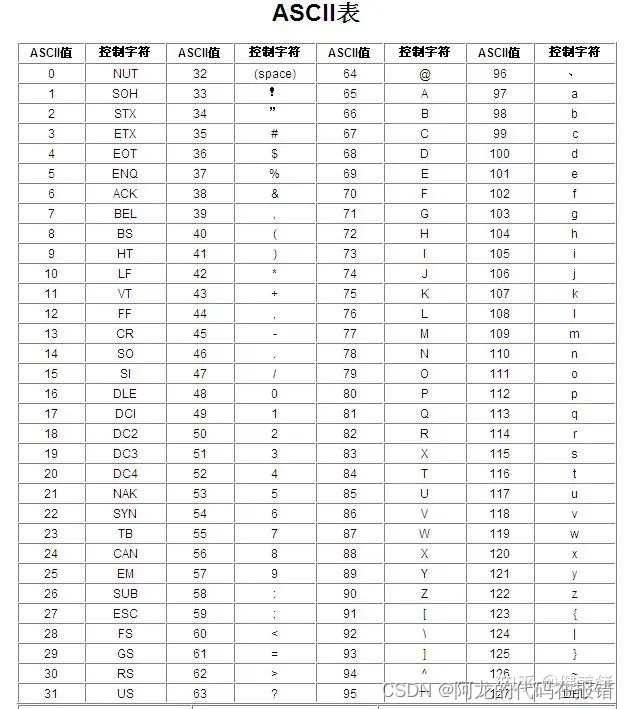
4.1 ASCII编码
ASCII规划使用一个字节表示字母与二进制对应关系
4.2 GB-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)
gbk 编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。
在与二进制做对应关系时,由如下逻辑:
- 单字节表示,用一个字节表示对应关系。2**8 =256
- 双字节表示,用两个字节表示对应关系。2**16 =65536种可能性
4.4 Unicode
Unicode 也被称为万国码,为全球的每个文字都分配了一个码位
- Ucs2
用固定的2个字节表示一个文字
- Ucs4
用固定的4个字节表示一个文字
无论是ucs2和ucs4都有一个问题就是浪费空间
文字 十六进制 二进制
冯 51AF 101000110101111
冯 51AF 01010001 10101111 ucs2
冯 51AF 00000000 00000000 01010001 10101111 ucs4
unicode的应用:在文件存储和网络传输时,不会直接使用Unicode,而在内存中会使用Unicode的
4.4 utf-8编码
包含所有的文字和二进制的对应关系,全球应用范围最为广泛的一种编码形式(站在巨人肩膀上工程名就)
本质上:utf-8是对Unicode编码的压缩,用尽量少的二进制与文字进行对应
Unicode码范围 UTF-8
0000 - 007F 用一个字节表示
0080 - 07FF 用两个字节表示
0800 - FFFF 用三个字节表示
10000 - 10FFFF 用四个字节表示
压缩流程
- 第一步:选择转换模版
码位范围(16进制) 转换模版
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxxx 10xxxxxx
10000 - 10FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
注意:一般中文都使用第三个模版(三个字节),这也就是大家说中文在UTF-8中会占三个字节的原因了
- 第二步:在模版中填入数据
冯 -》51AF-》101 000110 101111
根据模版去套入数据
1110xxxx 10xxxxxxx 10101111
1110xxxx 10000110 10101111
11100101 10000110 10101111
在utf-8 编码中"武"的编码为 11100101 10000110 10101111
4.5 Python中的编码
字符串(srt) "yujinlong" unicode 一般用于内存
字节(byte) utf-8 or gbk 一般用于文件和网络
text = 'yuijnlong2002'
data = text.encode('utf-8')
# 打开一个文件
file = open('yujinlong.txt', mode='wb')
# 写入字符串
file.write(data)
# 关闭文件
file.close()
![[XSCTF]easyxor](https://img-blog.csdnimg.cn/5ae276a2b4f741629aa1354e7cf4a914.png)