MySQL- 索引事务
文章目录
- MySQL- 索引事务
- 索引
- 操作
- ==索引原理==
- 事务
- 操作
- 并发执行
索引
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
通俗来看,我们可以把索引看成是书本的目录~
数据库使用select查询的时候:
- 先遍历表
- 把当前的行给带入到条件中,看条件是否成立
- 条件成立,这样的行就保留,不成立就跳过
但是如果表的数据比较大,那么这样遍历的成本就非常高了~
因此,索引也就孕育而生了~
索引属于是针对 查询操作 引入的优化条件,可以通过索引来加快查询的速度,避免针对表进行遍历。
- 索引是能提高查询速度的,但是也是有代价:
- 占用更多的空间,生成索引,是需要一系列的数据结构,来存储道硬盘空间的
- 可能会降低插入修改删除的速度
操作
-
查看索引
show index from 表名; -
创建索引
create index 索引名字 on 表名(列名); -
删除索引
drop index 索引名 on 表名;
注意:主键、unique、外键 都是会创建索引~
下面我们给出例子
mysql> create table student(id int, name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> show index from student;
Empty set (0.01 sec)
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student(id int primary key, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
-- 主键
mysql> show index from student;
此时我们的索引会以表格的形式展示出来:

一个索引是针对一个列来指定的。
只有针对这一列进行条件查询的时候,查询速度才能够被索引优化~
比如说:
表中的Column_name那一列,我们针对id创建索引,使用id进行条件查询,速度是很快的。
select * from student where id = 100;
但是如果是下面这种写法的话,他就不会走索引,而是仍然需要遍历表了
select * from student where name = '张三';
-- unique
create table student (id int unique, name varchar(20));

-- 外键
create table class(id int primary key, name varchar(20));
create table student(id int primary key, name varchar(20), classId int, foreign key(classId) references class(id));

一本书可以有多个目录
一个表也可以有多个索引
下面演示创建索引相关操作:
create index idx_student_name on student(name);
show index from student;

创建索引操作,其实…也是一个危险操作~
因为我们创建索引的时候,需要针对现有的数据,进行大规模的重新整理~
如果当前表是一个空表,或者数据不多,创建索引没啥问题,但是这个表很大,创建索引的话,很容易把数据库服务器给卡住。
一般来说,创建索引都是在创建表的时候就规划好了,一旦表已经使用很久,有很多数据,再想修改索引的话,就要慎重了~
但是有一种爱叫做硬爱,如果非要创建表的话,也是有技巧的~
做法:另外再搞一个机器,部署mysql服务器.也创建同样的表,并且把表上的索引创建好再把之前的机器上的数据给导入到新的mysql服务器上.(导入数据的过程就可以控制节奏)多花点时间导数据,都没事,不要影响到原来服务器正常的运转~~
而删除操作:
drop index 索引名 on 表名;
手动创建的索引,可以手动删除。
如果自动创建的索引(主键/外键,unique),是一定不能删除的~
删除索引操作也是一个危险操作!
索引原理
索引也是通过一定的数据结果来实现的。
索引原理的核心是利用B树或哈希表等数据结构,对要索引的列或字段进行排序和组织。当进行查询时,通过索引可以快速定位到符合查询条件的行,而不需要遍历整个数据表。这样可以大大减少数据库系统的IO操作和查询时间。
然而,索引也有一些限制和注意事项。
首先,创建索引会占用额外的存储空间。其次,当进行数据的插入、更新或删除操作时,索引也需要更新,这会带来一定的性能开销。因此,在创建索引时需要权衡存储空间和查询性能的需求。
但是,哈希表实际上还是不怎么适合数据库作为索引
-
对应哈希表来说,只能进行"精准匹配",无法进行范围查询,更无法进行模糊匹配
-
而红黑树来说,他是可以精准匹配的,也可以范围查询、模糊匹配
针对模糊匹配,是有一定的适用的
'孙%'可以一定程度匹配'%孙'这个就没办法了
因为字符串比大小,就是根据第一个字符比较的
这样需要注意的是:红黑树,也是二叉树.每一个节点,最多两个子树,树的分叉少(度),此时,表示同样数量的结果集合,树的高度就会更高.
所以综合来说:数据库引入的索引是一个改进的树形结构,B+树.(N叉搜索树)
在了解B+树之前,我们还需要了解B树(B-树)
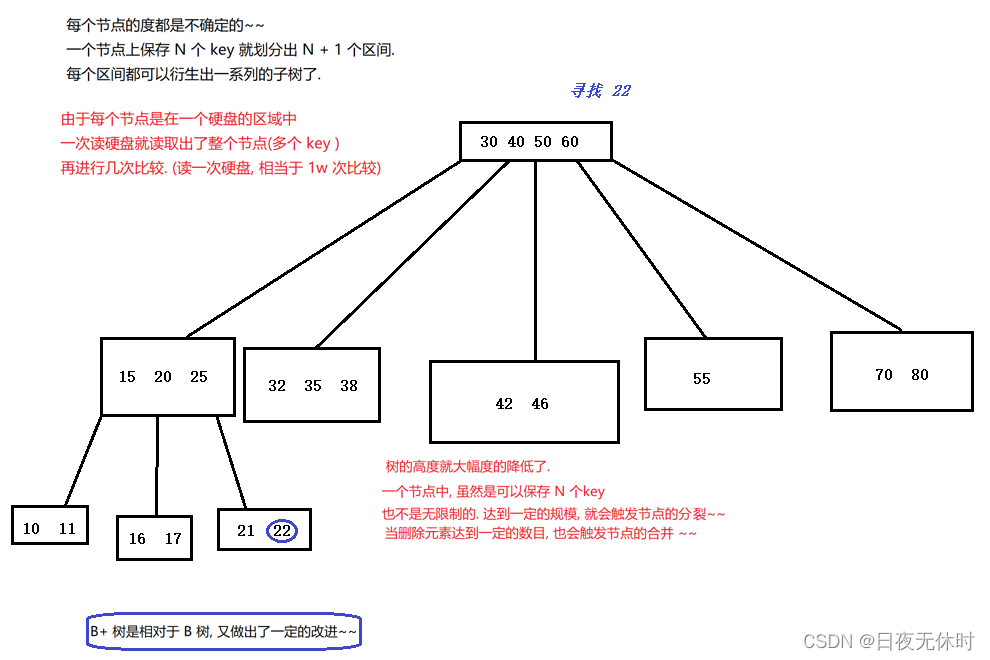
B树(N叉搜索树):
- 每个节点上有M个key,划分出了M+1个区间
- 进行查询的时候,就可以直接从根节点出发,判定当前要查的数据在节点上的哪个区间中,决定下一步往哪里走
- 进行添加/删除元素可能就涉及到节点的拆分和节点的合并
B+树是B树的改进,针对数据库量身定做的。
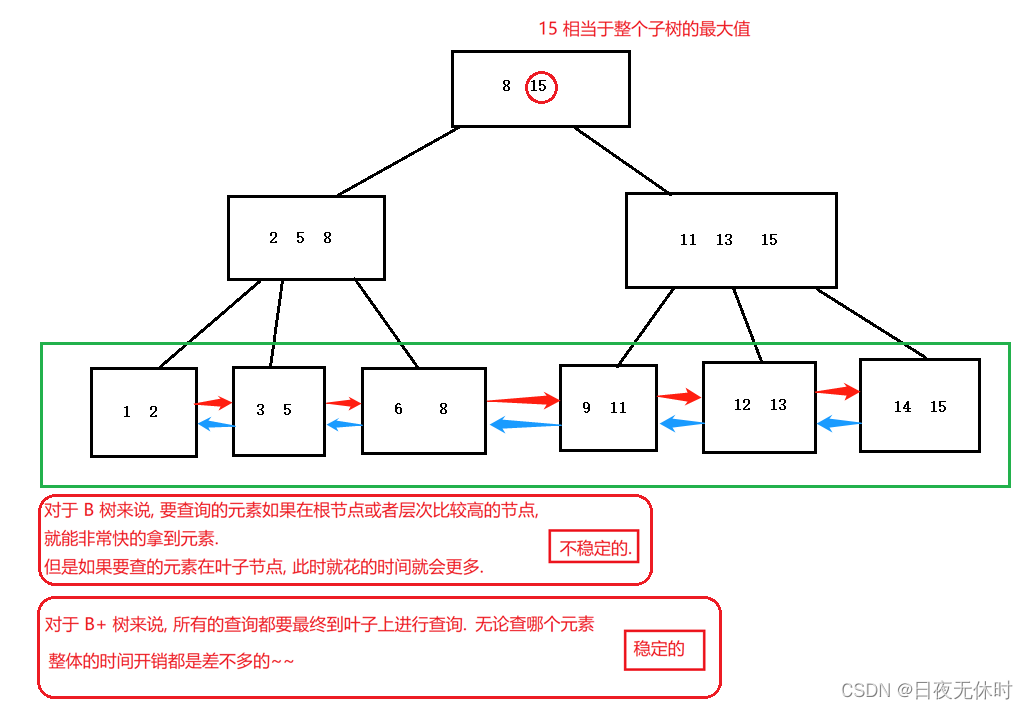
B+树
-
B+树也是一个N叉搜索树,一个节点上存在N个key,划分成N个区间
-
每个节点上N个key中,最后一个,就相当于当前子树的最大值
-
父节点上的每个key都会以最大值的身份在子节点的对应区间中存在(key可能会重复出现)叶子节点这一层,包含了整个树的数据全集
-
B+树会使用 链表 这样的结构,把叶子节点串起来
此时就可以非常方便地完成数据集合的遍历,并且也可以很方便地从数据集合中按照范围取出一个“子集”
相对于B树以及哈希、红黑树
B+树的优点如下:
-
N叉搜索树,树的高度是有限的,降低IO次效
-
非常擅长范围查询
-
所有查询最终都是要落到叶子节点.查询和查询之间的时间开销是稳定的
不会出现这次特别快,下次特别慢的情况 -
由于叶子节点是全集,会把行数据只存储在叶子节点上,
非叶子节点只是存储一个用来排序的key (比如存个id)数据库里是按行组织数据的.
创建索引的时候是针对这一列进行创建~~这一行数据,内容是比较多的
而这一个id则内容是比较少的
叶子节点会非常占用空间非叶子节点,则占不了多少空间,这些非叶子节点是缓存到内存中
不过(硬盘上还是要存这些非叶子节点的.但是当我们进行查询的时候就可以把这些非叶子节点加载到内存中,整体查询的比较过程就可以在内存中进行了又进一步的减少了IO访问次数)
至此,上述引入了一个比较典型的B+树来介绍索引的原理。、
但实际上,MySQL索引实现,也是有一些变数的,不只是只有B+树这一种情况
mysql内部有一个模块,存储引擎,存储引擎模块是提供了很多版本的实现的,Innodb当前最常用的mysql存储引擎 -> B+树.
事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
开发中经常会涉及一些场景,需要“一气呵成”地完成一些操作,比如说“转账”
account ( name, balance )
张三 1000
李四 1000
如果在执行以下操作执行一半,程序奔溃/数据库崩溃/机器断电
张三 -> 李四 转账500
张三账户-500
李四账户+500
此时,数据就会出现“不上不下”的中间状态
所以说:引入事务就是为了避免上述问题~
事务就可以把多个sql打包成一个整体
可以保证这些sql要么全都执行正确,要么就"一个都不执行”这里其实也不是说不是真的一个都没执行,必然得执行,才能知道失败~~只是看起来好像"一个都不执行一样”
此处在数据库中叫做“回滚”(rollback)
事务把这多个sql打包到一起,作为一个整体来执行。这样的特点,称为"原子性"
操作
-
开启事务:
start transaction单独执行的每个
sql,都是自成一个体系.此时这些sql之间是没有原子性的. -
执行各种
sql -
回滚或提交:
rollback/commit;commit也就代表事务结束了rollback主动触发回滚,一般是要搭配条件判断的逻辑来使用的sql里也能支持 条件、循环、变量、函数(但是日常开发一般不会这么写),更多的是搭配其他编程语言
但实际上我们需要关注的是 事务 背后的一些原理性质内容~
-
回滚是怎么做到的?
通过日志的方式,记录事务中的关键操作,这样的记录就是回滚的依据~,日志都是打印出来的内容在文件里
即使是主机掉电,也不影响(回滚用的日志已经在文件中了)
一旦重新启动主机,mysql也重新启动,就会发现回滚日志中有一些需要进行回滚的操作。于是就可以完成这里的回滚了
事务不仅仅是原子性特性,还有一些其他方面的特性(重点)
-
原子性 回滚的方式,保证这一系列操作,都能执行正确,或者恢复如初.
-
一致性 事务执行之前,和之后,数据都不能离谱~~
很多时候是要考数据库的约束以及一系列的检查机制来完成的
-
持久性
事务做出的修改,都是在硬盘上持久保存的.重启服务器,数据仍然是存在,事务执行的修改仍然是有效的 -
隔离性
数据库并发执行多个事务的时候,涉及到的问题~~
这里的并发执行非常常见:
因为
mysql是一个客户端服务器结构的程序.
一个服务器可以给多个客户端提供服务:
多个客户端都会让数据库执行事务~很有可能,客户端1提交的事务1,执行了一半,客户端2提交的事务2也过来了.
数据库服务器就需要同时处理这两个事务,这就是并发执行.
并发执行
并发程度越高,整体的效率就越高~~
如果我们希望数据库服务器执行效率高,就希望提高并发程度.但是提高了并发程度之后,可能会存在一些问题导致数据就出现一些"错误"的情况~~
隔离级别,就是在"数据正确”和"效率”之间做权衡~~
往往提升了效率,就会牺牲正确性;提升了正确性就会牺牲效率.…
那么在并发执行的时候,会出现以下问题:
-
脏读问题
一个实际生活中的场景,当一个家庭成员正在使用共享的购物清单应用程序时,另一个成员也同时尝试查看和修改该清单。假设成员A正在查看购物清单并准备添加一些物品,但在他完成之前,成员B开始操作,删除了清单中的一些物品。这会导致成员A看到的购物清单并没有更新,从而出现脏读的问题。
为了避免脏读,可以使用同步机制,如在访问购物清单时使用锁来确保只有一个人可以读取或修改它。这样一来,每个成员在操作购物清单之前都会先检查是否有其他人正在访问它,从而避免读取到过期或不一致的数据。
一个事务A正在写数据的过程中,另一个事务B读取了同一个数据
接下来事务A又修改了数据,导致B之前读到的数据,是一个无效的数据/过时的数据(也称为脏数据)这俩事务如果一个接一个的串行执行,没事.如果并发执行就容易出现脏读~~
那么解决脏读问题的方法,核心思路是,针对 写操作加锁。
用上面的例子来看就是,两个成员之间相互商量好,在成员A完成之前,成员B不要看A操作的页面,等A完成后,再操作。
但是之前A、B是完全并发执行的,操作加锁之后呢,并发程度就降低了~但是读取数据更靠谱了。
并发性降低了,隔离性提高了.效率降低了,数据准确性提高了.
-
不可重复读性
成员A首先查看购物清单,然后决定添加一个物品。然而,在他提交修改之前,成员B也尝试修改了购物清单,删除了其中一个物品。由于成员A还没有提交修改,他再次查看购物清单时,会发现购物清单和他最初查看时不一样了,出现了不可重复读的情况。
为了避免不可重复读,可以使用同步机制,如在访问购物清单时使用锁来确保只有一个人可以修改它。这样一来,当成员A重新查看购物清单时,他会看到一致的数据,不会出现不一致的情况。
并发执行事务过程中,如果事务A在内部多次读取同一个数据的时候,出现不同的情况,这种就是不可重复读.事务A在两次读的之间,有一个事务B修改了数据并提交了事务.
如果是两个事务,分两次读,结果不一样,这个能接受的~~
如果是一个事务内部的两次读,结果都不一样,就难以接受了~~刚才写加锁只是要求大家不要看我的屏幕,在我写的过程中不要读.但是没说你们读的时候我就不能继续写…
解决不可重复读,需要给 读操作加锁~~(也就是约定B读的时候,A也不能写),并发程度又进一步降低了,隔离性也进一步提高了.效率降低了,数据的准确性又提高了.
如果两个事务之间的影响越大,隔离性就越低,影响越小,隔离性就越高
-
幻读
当一个A正在使用共享的购物清单应用程序时,B也同时尝试修改该清单。成员A首先查看购物清单,并注意到当前有两个物品。然而,在他准备提交购买第一个物品之前,成员B也尝试向购物清单中添加了一个物品。当成员A再次查看购物清单时,他会发现购物清单中有三个物品,出现了幻读的情况。
为了避免幻读,可以使用同步机制,如在访问购物清单时使用锁来确保只有一个人可以修改它。这样,当成员A重新查看购物清单时,他会看到一致的数据,避免出现新添加的物品看起来像是“幻觉”一样出现的情况。
一个事务A执行过程中,两次的读取操作,数据内容虽然没改变,但是结果集变了.这种称为"幻读"。
结果集:表示查询结果的集合引入串行化的方式,解决幻读.保持绝对的串行执行事务,此时完全没有并发了.
串行化属于是一个釜底抽薪的操作.根本上解决了并发中涉及到的各个问题.
此时,并发程度最低(没并发),隔离性最高的.效率是最低的,数据是最准确的
古话说得好,人有悲欢离合,月有阴晴圆缺,如果我们想要效率,那么就会失去一定的正确性,反之也是如此。所以在不同的场景就会有不同的需求,mysql服务器也提供了“隔离级别”让我们针对隔离程度来进行设置来应付不同的需求场景~
MySQL提供了四种隔离级别:
分别对应到上述的的三个问题:
-
脏读
read uncommitted(读未提交)并发程度最高,速度最快,隔离性最低,准确性最低
-
不可重复读
read committed (读已提交)引入了写加锁,只能读写完之后提交版本,并发程度降低了,速度降低了,隔离性提高了,准确性页提高了
repeatable read(可重复读)引入了写加锁和读加锁.写的时候不能读,读的时候也不能写.并发程度又进一步降低了入速度降低了;隔离性提高了,准确性提高了
-
幻读
serializable (串行化)严格的按照串行的方式,一个一个的执行事务. 并发程度最低(没有并发),速度最低,隔离性最高,准确性最高
至此,MySQL的索引事务暂时就到此为止,接下来会介绍JDBC编程~