volatile 关键字
- 1. 保证内存可见性
- 2. 禁止指令重排序
- 3. 不保证原子性
1. 保证内存可见性
内存可见性问题: 一个线程针对一个变量进行读取操作,另一个线程针对这个变量进行修改操作,
此时读到的值,不一定是修改后的值,即这个读线程没有感知到变量的变化。
volatile 修饰的变量, 能够保证 “内存可见性”.
代码在写入 volatile 修饰的变量的时候,
- 改变线程工作内存(寄存器)中volatile变量副本的值
- 将改变后的副本的值从工作内存刷新到主内存(内存)
代码在读取 volatile 修饰的变量的时候
- 从主内存(内存)中读取volatile变量的最新值到线程的工作内存(寄存器)中
- 从工作内存(寄存器)中读取volatile变量的副本
加上 volatile , 强制读写内存. 速度是慢了, 但是数据变的更准确了.
代码示例:
class SynchronizedBlockExample {
static class Counter {
// public volatile int flag = 0;
public int flag = 0;
}
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
while (counter.flag == 0) {
// do nothing
}
System.out.println("循环结束!");
});
Thread t2 = new Thread(() -> {
Scanner scanner = new Scanner(System.in);
System.out.println("输入一个整数:");
counter.flag = scanner.nextInt();
});
t1.start();
t2.start();
}
}
while 循环里面 counter.flag == 0, 里面有 两步操作,并且线程启动之后一直在快速循环判断:
- load,把内存中 flag 的值读到寄存器里面
- cmp,把寄存器里面的值和 0 比较大小
上述循环执行非常快,1s 执行百万次以上。
但是循环这么多次,在 t2 修改之前, load 很多次,发现值都一样
而 load 相对于 cmp 慢很多,load 是从内存中读取数据,cmp 是在寄存器里面进行比较,再加上多次 load 的结果都一样,
所以编译器就做了一个大胆的想法,不再真正的 load 了,既然都一样,好像没人改,那就不从 内存中读取了,直接从 寄存器里面读取。
所以当我们输入一个非零值时,由于编译器还是从寄存器里面读取,而不是读内存,所以线程 t1 无法立即感知到。
当你输入一个 非 0 值时,如果不加上 volatile , 线程 t1 无法及时感知到;
加上 volatile,线程 t1 被强制读取内存,能立马感知到 flag 被赋予 非 0 值,会立即退出循环。
归根结底:还是编译器进行优化是发生了误判,但是这个什么时候优化又比较 “玄学”, 可能多加上一行代码可能就不优化了,所以稳妥的方法还是该加 volatile 的地方都加上。
2. 禁止指令重排序
什么是代码重排序?
举个栗子:
一段代码是这样的:
1. 去前台取下 U 盘
2. 去教室写 10 分钟作业
3. 去前台取下快递
为了提高效率, JVM、CPU指令集会对其进行优化,比如,按 1->3->2的方式执行,也是没问题,可以少跑一次前台,提高效率。这种就叫做指令重排序。
编译器对于指令重排序的前提是 “保持逻辑不发生变化”.
这一点在单线程环境下比较容易判断, 但是在多线程环境下就没那么容易了,
多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代码的执行效果进行预测,
因此激进的重排序很容易导致优化后的逻辑和之前不等价.
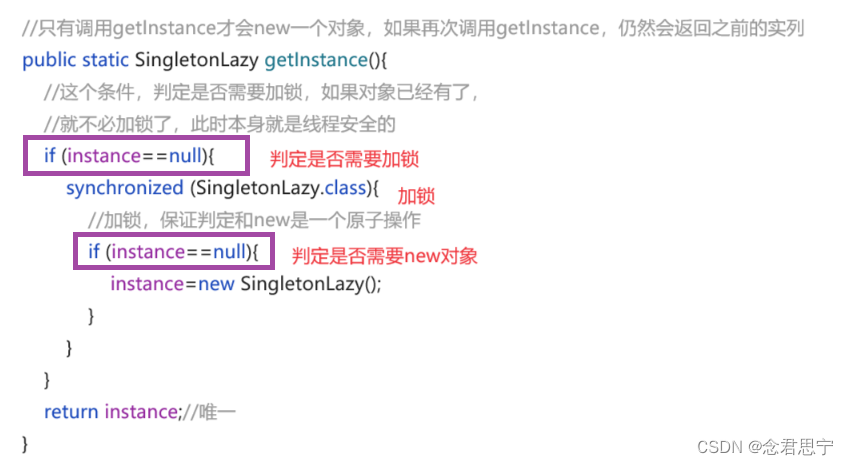
代码举例: 线程安全的单例模式:
class Singleton {
// 使用 volatile 防止指令重排序
private static volatile Singleton instance = null; // 使用 static, 该实例就是该类的唯一实例
// 私有化构造方法, 防止在类外创造实例
private Singleton(){}
public static Singleton getSingleton() {
// 判断是否需要加锁
if (instance == null) {
synchronized (Singleton.class) { // 针对类对象加锁, 保证所有线程都是针对同一个对象加锁
// 判断是否需要创建实例
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
对于上面这个代码, 就是一个单例模式, 只有一个 Singleton 实例, 并且只能通过 getSingleton 方法获得。
获得实例的步骤是:
- 判断实例是否为空,以此来决定是否要加锁。
- 因为 代码块里面是 先判断是否为空,再创建对象,这是两个步骤,所以要加锁。
- 实例为 null, 就创建实例。
- 返回实例。
其中创建实例 new Singleton() 又分为 三个步骤:
- 分配内存空间
- 对内存空间进行初始化
- 把内存空间的地址赋给引用
假如没有使用 volatile 关键字,编译器可能对此进行了优化,进行了指令重排序,那么有可能优化为 1 -> 3 -> 2 。
这样的话,当第一个线程 t1 要获取实例时,因为实例为null, 所以肯定会创建实例,但是可能编译器进行了优化,那么可能顺序就变成了 1 -> 3 -> 2
- 先开辟了一块空间
- 将空间地址赋值给引用
- 对空间初始化
当进行完第二步,把空间地址赋值给引用后,还没来得及初始化,此时另外一个线程 t2 来获取实例了, 进行判断时,发现 instance 不为空,那么就直接返回实例了
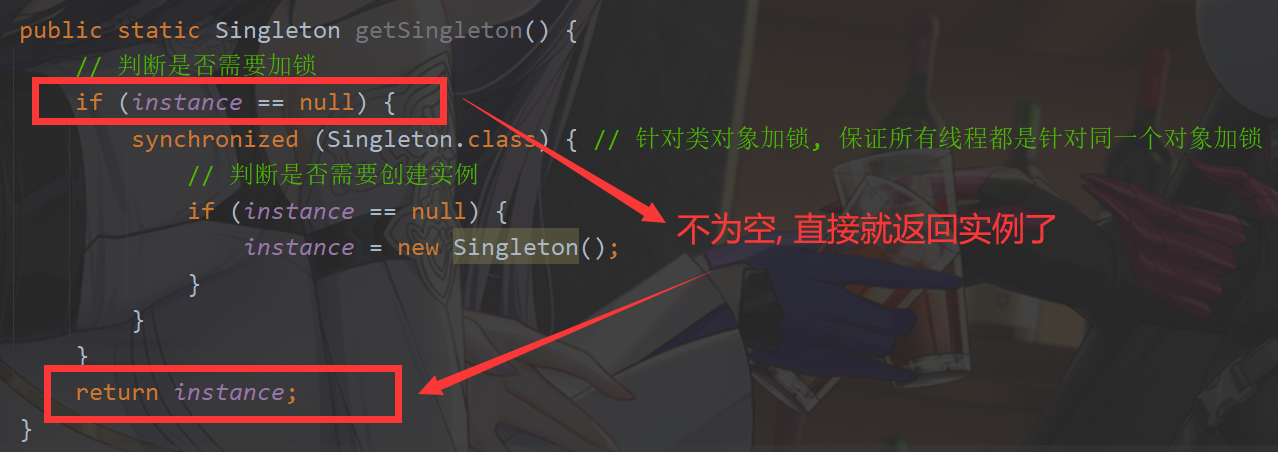
t2 拿到实例后,直接进行使用,那么就会报错了,因为虽然开辟了空间,但是 t1 还没来得及对空间进行初始化,所以访问的是非法的地址。
解决:
对 instance 对象加上 volatile 关键字,禁止指令重排序。
3. 不保证原子性
volatile 和 synchronized 有着本质的区别. synchronized 能够保证原子性和内存可见性; volatile 保证的是内存可见性以及禁止指令重排序。
class SynchronizedBlockExample {
static class Counter {
volatile public int count = 0;
void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
给 count 加上 volatile 关键字,最终 count 的值仍然无法保证是 100000。
但是使用 synchronized 的话就能保证原子性。使得代码执行结果符合预期。
class SynchronizedBlockExample {
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
好啦! 以上就是对 volatile 的讲解,希望能帮到你 !
评论区欢迎指正 !